本文前戏较多,务实的同学可以直接跳到文末的结论。
由「钢的琴」网友脑洞大开延伸出了吉的他二的胡琵的琶,以及后来许嵩的「苏格拉没有底」,是否可以再拓展一下,得到哥本不爱吃哈根,哈根爱达斯等剧情乱入的关系。
上面跟本文要讨论的主题有什么关系?
没关系。
缘起
有用户反馈内部MIS系统慢,页面加载耗时长。前端同学们开组会提及此事,如何解决慢的问题。
最致命的是:偶发!你不能准确知道它抽风的时间点,无法在想要追查问题的时候必现它。 这只是一方面,另外,慢的可能实在太多了,那么问题来了,是前端导致的还是后端的问题?
对慢的定义也有待商榷,多久算慢?如果这个页面加载大量数据耗时增加那我认为这是正常的。但这个时限超过了一个合理的自然值,就变得不那么正常了,比如四五十秒,一分多钟。
最奇葩的是,如此久的耗时居然不会报超时错误,而是拿到正确返回后将页面呈现了出来!
可能的原因
初步猜测
初步的猜测可能是后端迟迟未返回造成浏览器处于等待状态。这个猜测是很合乎逻辑的,至少能够很合理地解释Chrome Dev Tool 网络面板中我们看到的状态pending。 
但我们不能停留在猜测阶段,要用事实说话,数据才不会骗人。这也正是本文将要展开的。
下面是另外一些被提出来的可能性。
Angular
Angular首当其冲。为什么,因为这个问题出现在后台MIS系统中,且这些系统多用Angular开发。
Angular :怪我咯。
因为问题多出现在基于Angular的MIS系统中,并且Angular的性能一直是被诟病的,所以听到不少的声音将矛头指向Angular。这似乎没什么好庇护的。Angular在整个项目中的前端部分扮演了很重的角色。树大招风,理所当然。
这让我想起初次接触到这个问题时,那是在七月份,芙蓉的爱马仕平台用户反馈了慢的问题,报到前端,顺便看了下,一看Pending状态,觉得是后端未返回。只是情深缘浅当时也没有深入,同时洪堂大神负责去追查了。当时那个系统,很负责地说,没有用Angular。
所以这里可以为Angular正身,将其排除。
内部封装的commonResource库
内部对Angular原生的resource进行了封装,做了些数据的转换处理。既然上面Angular都被正身了,那么这里的怀疑也是站不住脚的。
Chrome插件
经查,网上好多呼声有说是Adblock等与网络有关的Chrome插件。可我不使用它已经很多年,那玩意儿太重,后来找到了算法更高级体量更轻便的µBlock。关键是后者也在我使用一段时间后放弃了,因为个人觉悟提高了(此处逼格开始膨胀),免费内容是需要广告支撑的,如果你不希望付费变成强制的话。所以现在一直是处于未开这类插件的状态。那么在未开广告屏蔽插件的情况下重现了问题,可以排除这类插件的影响了。
关于插件,此刻我的Chrome里唯一还会接管Chrome网络的便是代理插件SwitchSharp, 升级之后这货叫Switchy哦卖喝(与时俱进的我当然使用的是后者,此处逼格已经爆表)。
Chrome独家?
因为内部MIS只兼容了Chrome开发,所以不会有在除了Chrome之外的浏览器上使用的场景,并且其他浏览器上面追查问题也是很痛苦的事情。这里仅在火狐里进行了少量尝试,未复现。同时接到反馈,Safari里也未复现。但也不能肯定就只有Chrome存在问题。似乎这个对于问题的解决还不那么重要,所以先不管。
杀毒软件
后面会看到,在追查错误号ERR_CONNECTION_RESET时引出了杀毒软件可能会导致Chrome工作不正常的情况,但这个可能也在稍后被排除人。
并且,我厂使用Mac的同学并没有安装杀软,依然是可以复现的。
重现
第一件事情便是重现。虽然是偶发,为了尽可能保存现场,还是想要手动将它刷出来。天不灭我,经过良久尝试,该问题被复现。于是各种截图,保存请求数据。这个时候还没有开启chrome://net-internals/#events页面来捕获事件日志。
为以后引用方便,这里留下版本信息:
OS: Windows 7 Ultimate
Chrome:Version 39.0.2171.95 m
这是请求Pending时的请求信息: 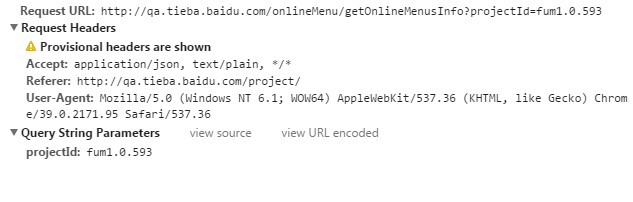
这是请求成功返回后: 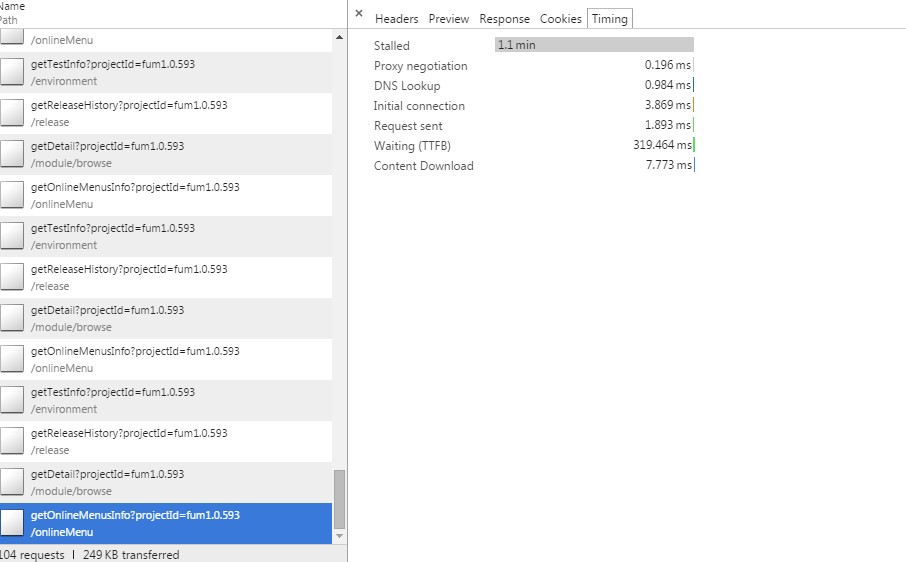
可以看到Stalled了1分多钟。神奇的是竟然不报超时错误而是成功返回了。
同时保存了请求头,响应头,还将本次问题请求保存成了CURL等。现场已经留下,感觉Bug不会存活太久了。
接下来就是对比正常请求跟这次异常请求的不同,一轮比较下来,未发现多少异常。
常态与变态的对比
请求头对比:
请求头的对比已丢失,但除了时间外,其余无差别。
响应头对比:
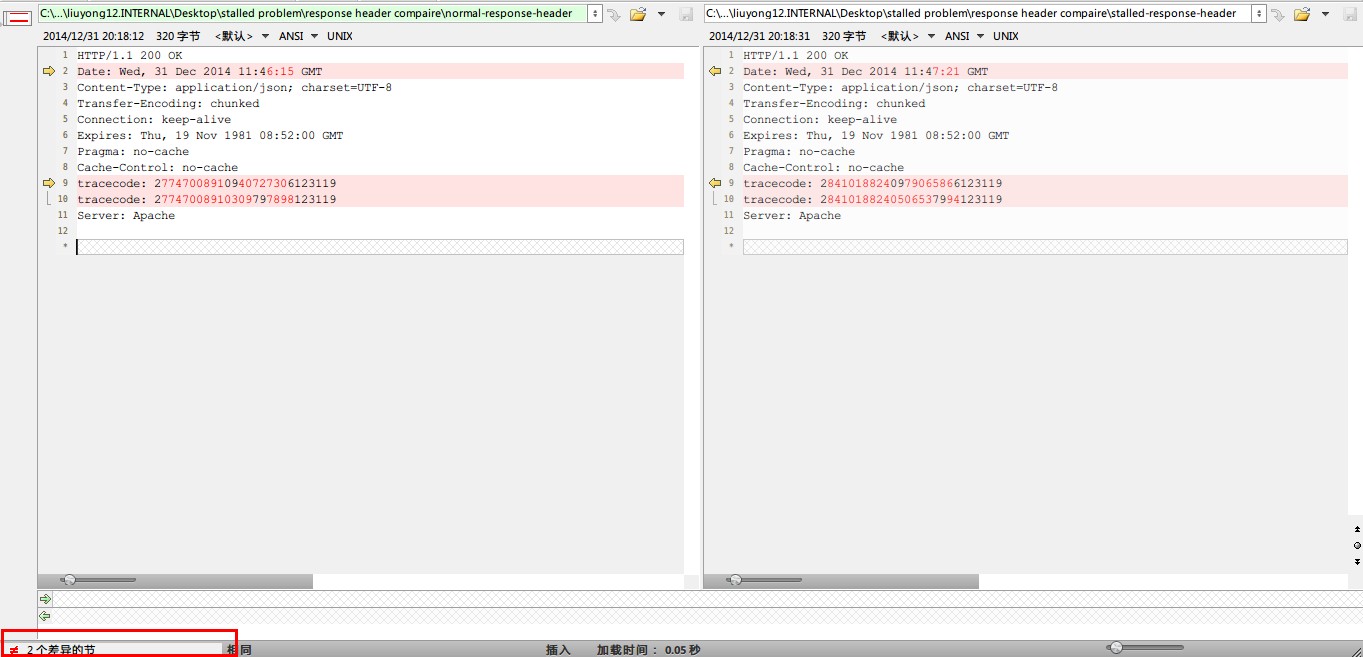
返回结果对比:
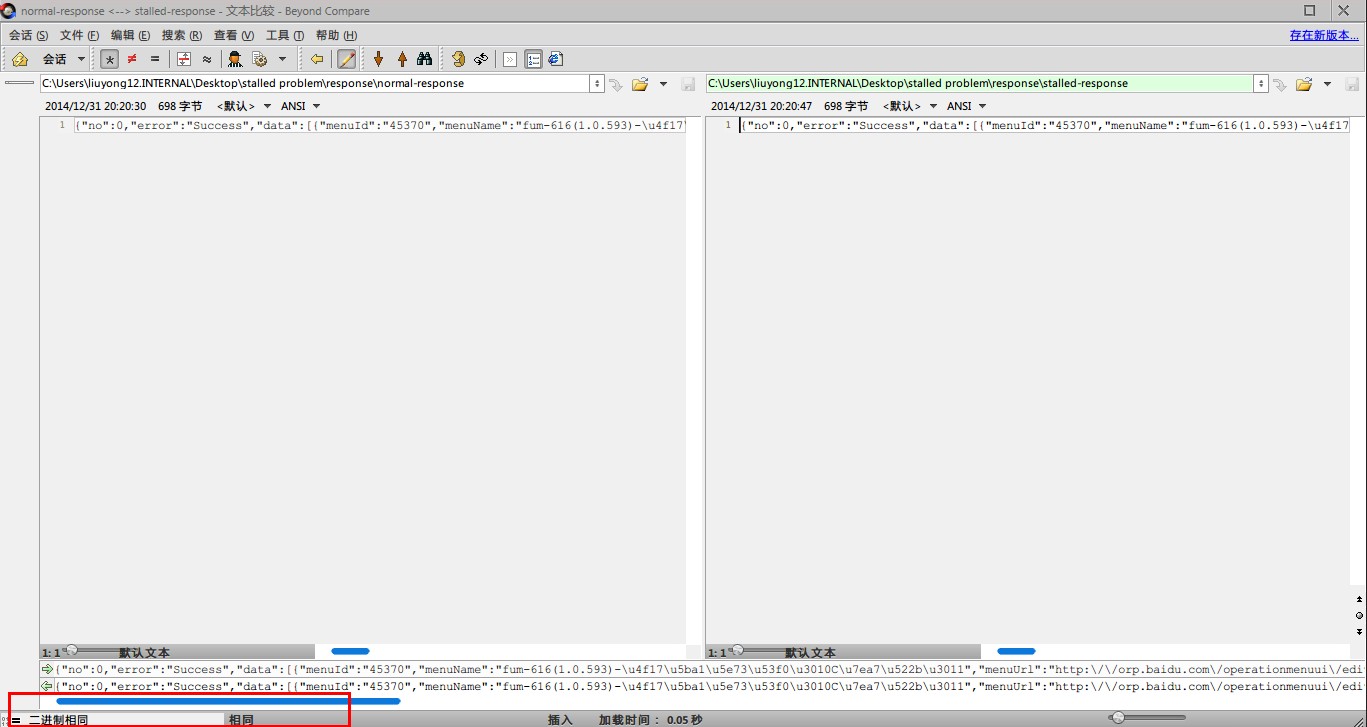
上面的对比意义不大,但还是要做的,万一发现有价值的情报了呢。
一次失败的尝试
解决问题时,习惯性地看有没有人已经碰过到类似问题,这样做的好处很明显: 如果有,站在巨人的肩上轻松地牛逼着; 如果没有,这是个机会。
于是信心满满地出发了,因为根据一条互联网准则,70%的问题已经有人解决过了,那些没有被解决的要么是现有技术达不到,要么是未被人发现。所以能够搜索出问题答案的概率还是蛮大的。
经过旷日持久的搜索,有价值的参考寥寥无几。可能是问题本身太过奇葩,遇到的人太少;也有可能问题过于晦涩,无法表述;抑或我搜索的关键词不够精准。 倒也不是说一个都没找到,但一般涉及网络日志的情况就无人问津了,无人问津了!
比如这个,一年多前被人问的,现在还没有一个回答。
还比如这个
Chrome stalls when making multiple requests to same resource?
是后来作为参考的,也是无人问津了……
甚至自己也去问了一个,依然无人问津问津……
神秘的CACHE LOCK
上面提到,Stackoverflow上找到一个问题,跟现在需要解决一有些类似点:
- 偶发,并不是必然出现的。这里我们的问题也是偶发,很难复现,需要反复刷。
- 也是请求被
Pending了很久,从请求的时间线来看,体现在Stalled上。
这一刻,有一种感觉大概是这样的:
伟大的意大利的左后卫!他继承了意大利的光荣的传统。法切蒂、卡布里尼、马尔蒂尼在这一刻灵魂附体!格罗索一个人他代表了意大利足球悠久的历史和传统,在这一刻他不是一个人在战斗,他不是一个人!
突然看到了希望。该提问到没有给出什么建设性的意见,但它后面的追加编辑却给出了答案。过程是查看Chrome的网络日志,在事件里面发现有一个超时错误:
t=33627 [st= 5] HTTP_CACHE_ADD_TO_ENTRY [dt=20001] –> net_error = -409 (ERR_CACHE_LOCK_TIMEOUT)
耗时20秒之久!而且写得非常明显是ERR_CACHE_LOCK_TIMEOUT。根据提问者贴出来的链接,了解到Chrome有一个缓存锁的机制。
具体源于一个今年6月分实现的一个补丁,加入了这么个机制,而这个机制的引入又源于2010年的一个issue。具体信息可以通过这个这里查看,下面引用如下。
Basically here is the situation:
The site author has a long-lived XHR being used to stream a slow response from the server. This XHR response is cachable (it is just really slow). They kick off the XHR asynchronously, and as data slowly arrives on it, update the progressive load of the webpage. Cool.
Now what happens if you try to load this page in multiple tabs of Chrome is: The first page starts to load just fine, but the second one does nothing. What has happened, is the background XHR of the first page load has acquired an exclusive lock to the cache entry, and the background XHR of the second page is stalled at “Waiting for cache…” trying to get a reader access to the cache entry.
Since the first request can takes minutes, this is a problem.
eroman 同学指出了这么一个事实:
浏览器对一个资源发起请求前,会先检查本地缓存,此时这个请求对该资源对应的缓存的读写是独占的。那么问题来了,试想一下,当我新开一个标签尝试访问同一个资源的时候,这次请求也会去读取这个缓存,假设之前那次请求很慢,耗时很久,那么后来这次请求因为无法获取对该缓存的操作权限就一直处于等待状态。这样很不科学。于是有人建议优化一下。也就是上面所描述的那样。
随着问题的提出,还出了两种可能的实现方案。
(a) [Flexible but complicated] Allow cache readers WHILE writing is in progress. This way the first request could still have exclusive access to the cache entry, but the second request could be streamed the results as they get written to the cache entry. The end result is the second page load would mirror the progress of the first one.
(a) [Naive but simpler] Have a timeout on how long we will block readers waiting for a cache entry before giving up and bypassing the cache.
我猜上面第二个(a)应该是(b)。简单说第一种优化方案更加复杂但科学。之前的请求对缓存仍然是独占的,但随着前一次请求不断对缓存进行更新,可以把已经更新的部分拿给后面的请求读取,这样就不会完全阻塞后面的请求了。
第二种方案则更加简单暴力。给后来的请求设定一个读取缓存超时的时限,如果超过了这个时限,我认为缓存不可用或者本地没有缓存,忽略这一步直接发请求。
于是Chromium的开发者们选择了后者简单的实现。也就是Issue 345643003: Http cache: Implement a timeout for the cache lock 这个提交里的实现。
这个提交的描述如下:
The cache has a single writer / multiple reader lock to avoid downloading the same resource n times. However, it is possible to block many tabs on the same resource, for instance behind an auth dialog.
This CL implements a 20 seconds timeout so that the scenario described in the bug results in multiple authentication dialogs (one per blocked tab) so the user can know what to do. It will also help with other cases when the single writer blocks for a long time.
The timeout is somewhat arbitrary but it should allow medium size resources to be downloaded before starting another request for the same item. The general solution of detecting progress and allow readers to start before the writer finishes should be implemented on another CL.
于是就产生了上面题主遇到的情况。
所以他的解决方法就很明朗了,对请求加个时间戳让其变得唯一,或者服务器响应头设置为无缓存。Both will work!
那么我们的问题也会是这样的么?我幻想由于某种未知的原因造成之前的请求不正常(虽然网络面板里没有数据证明这样的阻塞请求在问题请求之前存在),然后我们的MIS里打开页面时读取不到缓存,卡了,一会儿缓存好了,正常了,于是在等待了几十秒后请求成功发出去了。
似乎不太可能。因为恰好内部MIS系统的响应头里已经加了缓存控制了 Cache-Control: no-cache。
以下是一次问题请求的响应头:
HTTP/1.1 200 OK
Date: Wed, 31 Dec 2014 11:47:21 GMT
Content-Type: application/json; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Pragma: no-cache
Cache-Control: no-cache
tracecode: 28410188240979065866123119
tracecode: 28410188240506537994123119
Server: Apache
并且开多个标签也是无法进行有效重现的。
因此可以排除缓存的干扰。那么似乎这里的缓存锁并不是导致问题的原因,只能另寻他路。不得不说,高兴过后有点失望。
八卦时间
可喜的是,在细细口味了上面缓存机制引入的过程后,真是耐人寻味。这里不妨八卦一下。相信你也注意到了,上面提到,该缓存问题的提出是在2010年,确切地说是Jun 8, 2010。是的,2010年6月8日由eroman 同学提出。但最后针对该问题进行修复的代码提交却是在今年6月份,2014年6月24日,提交时间摆在那里我会乱说?
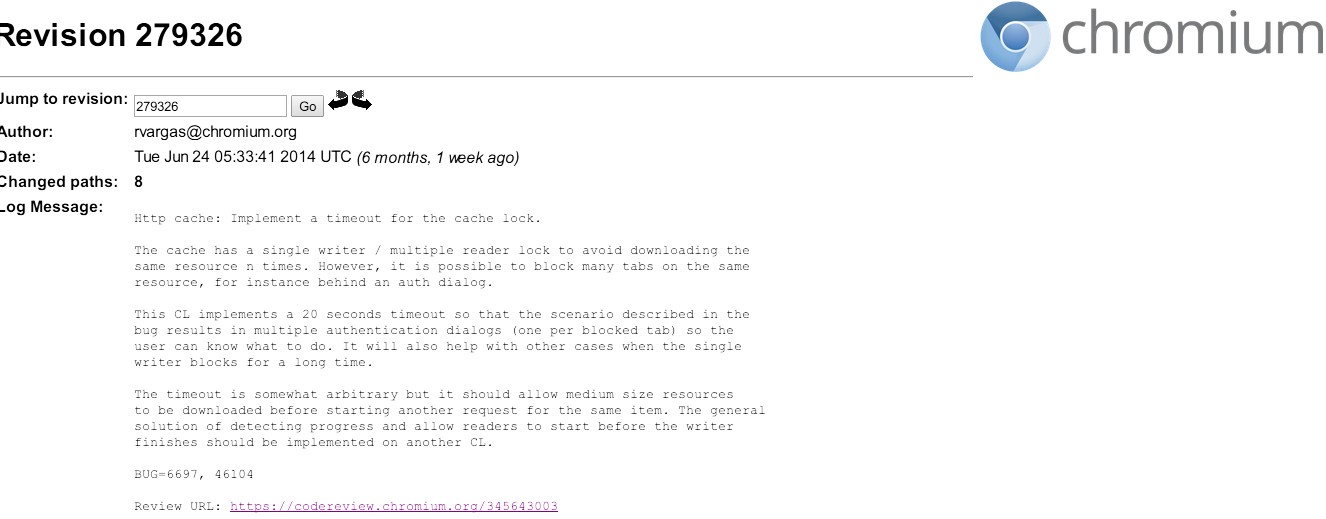
于是好奇为什么会拖了这么久,遂跟了一下该问题下面的回复看看发生了什么。简直惊呆了。
- 同月14号,有了首次对这个问题的回复,那是将该问题指派给了rvargas同学。
- 一个月过去了,也就是7月15号,rvargas同学指出了与该问题关联的另外一个issue「issue 6697」
- 接下来是8月5日,rvargas同学为该问题贴上了标签
-Mstone-7 Mstone-8 ,表明将会在里程碑7或者8里面进行修复。但在后面的10月7日,这个日程又被推到了-Mstone-8 Mstone-9 。
- 再接下来11月5日,有人表示以目前的速度及bug数量,还没有时间来修复它,重点在处理优先级为
p1的问题上。于是此问题又成功被顺延了,来到-mstone-9 Mstone-10 ,同时优级降为p2。Chromium人手也不够啊,看来。
- 时间来到12月9日,因为优先级为
p2的issue如果没有被标为开始状态的话又自动推到下一个里程碑了,于是顺利来到 -Mstone-10 MovedFrom-10 Mstone-11 。次年2月来到-Mstone-11 Mstone-12 。完成了一次跨年!
…………
- 上面省略N步。如此反复,最后一次被推到了
-Mstone-16 ,那是在2011年10月12日。
- 时间一晃来到2013年,这一年很平静,前面的几个月都没有人对此问题进行回复。直到11月27日,有人看不下去了,评论道:
This bug has been pushed to the next mstone forever…and is blocking more bugs (e.g https://code.google.com/p/chromium/issues/detail?id=31014)and use-cases same video in 2 tags on one page, and adaptive bit rate html5 video streaming whenever that will kick in. Any chance this will be prioritized?
由于这个bug的无限后延也阻塞了另外一些同类问题,看来是时候解决了。这不,最初的owner 当天就进行了回复:
ecently there was someone looking at giving it another try… I’d have to see if there was any progress there.
If not, I may try to fix it in Q1.
最后一句亮瞎。敢情这之前owner就没有想过要去真正解决似的,因为有其他人在看这个问题了,所以就没管了,如果Q1还没人解决的话,我会出手的!嗯,就是这个意思。
…………
最后,也就是上文提到的,2014年6月,还是rvargas同学对这个问题进行了修复,实现了对缓存读取20秒超时的控制。
该问题就是这样从2010来到2014的。我怀疑Chrome是如何成为版本帝的。
阶段总结
仅有的希望到此似乎都没有了。不过前面的努力也不是没有作何收获,至少我得到了以下有价值的信息:
- 谷歌的神坛光环不再那么耀眼,他们的产品也是有大堆Bug需要处理的
- Chrome 处理issue的效率,当然不排除这种大型项目bug数量跟人力完全不匹配的情况
- 受上面Stackoverflow问题的启发,接下来我将重点转移到了针对出问题请求的日志分析上,并且取得了突破
开始新的征程
虽然上面的努力没能定位到问题,但作为这次对解决这次问题的尝试,还是将它记录了下来,估且称作「旧的回忆」吧。
下面开始「新的征程」。

再次重现
这次受到上面的启发,开启chrome://net-internals/#events页面来捕获事件日志。看是否有错误或异常发生。
再次经过旷日持久的机械操作,重现了!这次,日志在手,天下我有。感觉Bug不会存活多久了。
Chrome Dev Tools 网络面板截图: 
由上面的截图看到,本次出问题的请求总耗时42.74秒。
问题请求的时间线信息截图: 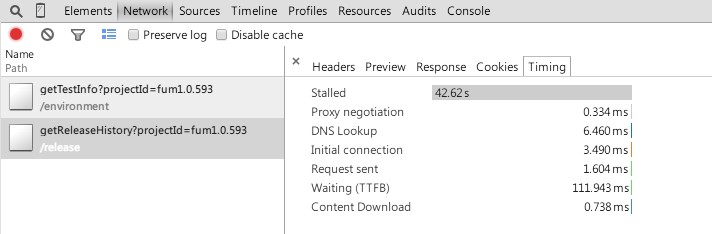
可以预见,通过捕获的日志完全可以看到Stalled那么久都发生了些什么鬼。
话不多说,切换到事件捕获页面,定位到出问题的请求,查看其详情。同时将该日志导出,永久保存!作为纪念,也方便以后再次导入查看。有兴趣的同学可以访问下方下载后进行导入,就可以清晰地查看到现场了,就好像你亲历了整个犯罪现场一样。
日志还原
- 下载该日志文件
- 在Chrome新开一个标签输入
chrome://net-internals/#events
- 切换到
Import,选择刚才下载的JSON文件进行导入
- 切换到
Events,定位到http://qa.tieba.baidu.com/release/getReleaseHistory?projectId=fum1.0.593 这个请求
此刻右边出现的便是该问题请求的详细日志。
日志解读
下面不妨把日志文件贴出来先:
193486: URL_REQUEST
http://qa.tieba.baidu.com/release/getReleaseHistory?projectId=fum1.0.593
Start Time: 2015-01-02 17:51:05.323
t= 1 [st= 0] +REQUEST_ALIVE [dt=42741]
t= 1 [st= 0] URL_REQUEST_DELEGATE [dt=0]
t= 1 [st= 0] +URL_REQUEST_START_JOB [dt=42740]
--> load_flags = 339804160 (BYPASS_DATA_REDUCTION_PROXY | MAYBE_USER_GESTURE | REPORT_RAW_HEADERS | VERIFY_EV_CERT)
--> method = "GET"
--> priority = "LOW"
--> url = "http://qa.tieba.baidu.com/release/getReleaseHistory?projectId=fum1.0.593"
t= 2 [st= 1] URL_REQUEST_DELEGATE [dt=0]
t= 2 [st= 1] HTTP_CACHE_GET_BACKEND [dt=0]
t= 2 [st= 1] HTTP_CACHE_OPEN_ENTRY [dt=0]
t= 2 [st= 1] HTTP_CACHE_ADD_TO_ENTRY [dt=0]
t= 2 [st= 1] HTTP_CACHE_READ_INFO [dt=0]
t= 2 [st= 1] URL_REQUEST_DELEGATE [dt=0]
t= 2 [st= 1] +HTTP_STREAM_REQUEST [dt=2]
t= 4 [st= 3] HTTP_STREAM_REQUEST_BOUND_TO_JOB
--> source_dependency = 193488 (HTTP_STREAM_JOB)
t= 4 [st= 3] -HTTP_STREAM_REQUEST
t= 4 [st= 3] +HTTP_TRANSACTION_SEND_REQUEST [dt=0]
t= 4 [st= 3] HTTP_TRANSACTION_SEND_REQUEST_HEADERS
--> GET /release/getReleaseHistory?projectId=fum1.0.593 HTTP/1.1
Host: qa.tieba.baidu.com
Connection: keep-alive
Accept: application/json, text/plain, */*
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36
Referer: http://qa.tieba.baidu.com/project/
Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8
Cookie: [268 bytes were stripped]
t= 4 [st= 3] -HTTP_TRANSACTION_SEND_REQUEST
t= 4 [st= 3] +HTTP_TRANSACTION_READ_HEADERS [dt=21301]
t= 4 [st= 3] HTTP_STREAM_PARSER_READ_HEADERS [dt=21301]
--> net_error = -101 (ERR_CONNECTION_RESET)
t=21305 [st=21304] HTTP_TRANSACTION_RESTART_AFTER_ERROR
--> net_error = -101 (ERR_CONNECTION_RESET)
t=21305 [st=21304] -HTTP_TRANSACTION_READ_HEADERS
t=21305 [st=21304] +HTTP_STREAM_REQUEST [dt=3]
t=21307 [st=21306] HTTP_STREAM_REQUEST_BOUND_TO_JOB
--> source_dependency = 193494 (HTTP_STREAM_JOB)
t=21308 [st=21307] -HTTP_STREAM_REQUEST
t=21308 [st=21307] +HTTP_TRANSACTION_SEND_REQUEST [dt=3]
t=21308 [st=21307] HTTP_TRANSACTION_SEND_REQUEST_HEADERS
--> GET /release/getReleaseHistory?projectId=fum1.0.593 HTTP/1.1
Host: qa.tieba.baidu.com
Connection: keep-alive
Accept: application/json, text/plain, */*
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36
Referer: http://qa.tieba.baidu.com/project/
Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8
Cookie: [268 bytes were stripped]
t=21311 [st=21310] -HTTP_TRANSACTION_SEND_REQUEST
t=21311 [st=21310] +HTTP_TRANSACTION_READ_HEADERS [dt=21304]
t=21311 [st=21310] HTTP_STREAM_PARSER_READ_HEADERS [dt=21304]
--> net_error = -101 (ERR_CONNECTION_RESET)
t=42615 [st=42614] HTTP_TRANSACTION_RESTART_AFTER_ERROR
--> net_error = -101 (ERR_CONNECTION_RESET)
t=42615 [st=42614] -HTTP_TRANSACTION_READ_HEADERS
t=42615 [st=42614] +HTTP_STREAM_REQUEST [dt=12]
t=42627 [st=42626] HTTP_STREAM_REQUEST_BOUND_TO_JOB
--> source_dependency = 193498 (HTTP_STREAM_JOB)
t=42627 [st=42626] -HTTP_STREAM_REQUEST
t=42627 [st=42626] +HTTP_TRANSACTION_SEND_REQUEST [dt=2]
t=42627 [st=42626] HTTP_TRANSACTION_SEND_REQUEST_HEADERS
--> GET /release/getReleaseHistory?projectId=fum1.0.593 HTTP/1.1
Host: qa.tieba.baidu.com
Connection: keep-alive
Accept: application/json, text/plain, */*
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36
Referer: http://qa.tieba.baidu.com/project/
Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8
Cookie: [268 bytes were stripped]
t=42629 [st=42628] -HTTP_TRANSACTION_SEND_REQUEST
t=42629 [st=42628] +HTTP_TRANSACTION_READ_HEADERS [dt=112]
t=42629 [st=42628] HTTP_STREAM_PARSER_READ_HEADERS [dt=112]
t=42741 [st=42740] HTTP_TRANSACTION_READ_RESPONSE_HEADERS
--> HTTP/1.1 200 OK
Date: Fri, 02 Jan 2015 09:51:48 GMT
Content-Type: application/json; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Cache-Control: no-cache
tracecode: 31079600320335034634010217
tracecode: 31079600320537995786010217
Server: Apache
t=42741 [st=42740] -HTTP_TRANSACTION_READ_HEADERS
t=42741 [st=42740] HTTP_CACHE_WRITE_INFO [dt=0]
t=42741 [st=42740] HTTP_CACHE_WRITE_DATA [dt=0]
t=42741 [st=42740] HTTP_CACHE_WRITE_INFO [dt=0]
t=42741 [st=42740] URL_REQUEST_DELEGATE [dt=0]
t=42741 [st=42740] -URL_REQUEST_START_JOB
t=42741 [st=42740] URL_REQUEST_DELEGATE [dt=0]
t=42741 [st=42740] HTTP_TRANSACTION_READ_BODY [dt=0]
t=42741 [st=42740] HTTP_CACHE_WRITE_DATA [dt=0]
t=42741 [st=42740] HTTP_TRANSACTION_READ_BODY [dt=0]
t=42741 [st=42740] HTTP_CACHE_WRITE_DATA [dt=0]
t=42742 [st=42741] -REQUEST_ALIVE
首先,日志显示的总耗时与上面网络面板截图的总耗时是吻合的,都是42.74秒,说明我们定位正确。
以下时间均以毫秒计
日志第一列为时间线,自请求发起时算。 第二列为每步操作所逝去的时间,时间差的概念,与第三列里面的dt不同,它会积累前面的耗时。 第三列为具体的事件,以及相应事件的耗时dt,此耗时为绝对耗时。
+号对应事件开始,-号对应事件结束,也就是说他们必然成对出现。住里是展开后更加详细的子事件。直到不能再细分。
如果说一开始接触到这个日志时手足无措的话,我们来看一下正常情况下的日志是怎样的,有对比才有发现。
以下随便摘取一次正常请求的日志,如下:
384462: URL_REQUEST
http://qa.tieba.baidu.com/release/getReleaseHistory?projectId=fum1.0.593
Start Time: 2015-01-03 20:23:54.698
t=1556 [st= 0] +REQUEST_ALIVE [dt=172]
t=1556 [st= 0] URL_REQUEST_DELEGATE [dt=0]
t=1556 [st= 0] +URL_REQUEST_START_JOB [dt=171]
--> load_flags = 335609856 (BYPASS_DATA_REDUCTION_PROXY | MAYBE_USER_GESTURE | VERIFY_EV_CERT)
--> method = "GET"
--> priority = "LOW"
--> url = "http://qa.tieba.baidu.com/release/getReleaseHistory?projectId=fum1.0.593"
t=1557 [st= 1] +URL_REQUEST_DELEGATE [dt=4]
t=1557 [st= 1] DELEGATE_INFO [dt=4]
--> delegate_info = "extension Tampermonkey"
t=1561 [st= 5] -URL_REQUEST_DELEGATE
t=1561 [st= 5] HTTP_CACHE_GET_BACKEND [dt=0]
t=1561 [st= 5] HTTP_CACHE_OPEN_ENTRY [dt=1]
--> net_error = -2 (ERR_FAILED)
t=1562 [st= 6] HTTP_CACHE_CREATE_ENTRY [dt=0]
t=1562 [st= 6] HTTP_CACHE_ADD_TO_ENTRY [dt=0]
t=1562 [st= 6] URL_REQUEST_DELEGATE [dt=0]
t=1562 [st= 6] +HTTP_STREAM_REQUEST [dt=2]
t=1564 [st= 8] HTTP_STREAM_REQUEST_BOUND_TO_JOB
--> source_dependency = 384467 (HTTP_STREAM_JOB)
t=1564 [st= 8] -HTTP_STREAM_REQUEST
t=1564 [st= 8] +HTTP_TRANSACTION_SEND_REQUEST [dt=1]
t=1564 [st= 8] HTTP_TRANSACTION_SEND_REQUEST_HEADERS
--> GET /release/getReleaseHistory?projectId=fum1.0.593 HTTP/1.1
Host: qa.tieba.baidu.com
Connection: keep-alive
Accept: application/json, text/plain, */*
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36
Referer: http://qa.tieba.baidu.com/project/
Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8
Cookie: [2642 bytes were stripped]
t=1565 [st= 9] -HTTP_TRANSACTION_SEND_REQUEST
t=1565 [st= 9] +HTTP_TRANSACTION_READ_HEADERS [dt=161]
t=1565 [st= 9] HTTP_STREAM_PARSER_READ_HEADERS [dt=160]
t=1725 [st=169] HTTP_TRANSACTION_READ_RESPONSE_HEADERS
--> HTTP/1.1 200 OK
Date: Sat, 03 Jan 2015 12:23:54 GMT
Content-Type: application/json; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Cache-Control: no-cache
tracecode: 14346880480340800522010320
tracecode: 14346880480253893130010320
Server: Apache
t=1726 [st=170] -HTTP_TRANSACTION_READ_HEADERS
t=1726 [st=170] HTTP_CACHE_WRITE_INFO [dt=0]
t=1726 [st=170] HTTP_CACHE_WRITE_DATA [dt=0]
t=1726 [st=170] HTTP_CACHE_WRITE_INFO [dt=0]
t=1726 [st=170] +URL_REQUEST_DELEGATE [dt=1]
t=1726 [st=170] DELEGATE_INFO [dt=1]
--> delegate_info = "extension Tampermonkey"
t=1727 [st=171] -URL_REQUEST_DELEGATE
t=1727 [st=171] -URL_REQUEST_START_JOB
t=1727 [st=171] URL_REQUEST_DELEGATE [dt=0]
t=1727 [st=171] HTTP_TRANSACTION_READ_BODY [dt=0]
t=1727 [st=171] HTTP_CACHE_WRITE_DATA [dt=1]
t=1728 [st=172] HTTP_TRANSACTION_READ_BODY [dt=0]
t=1728 [st=172] HTTP_CACHE_WRITE_DATA [dt=0]
t=1728 [st=172] -REQUEST_ALIVE
针对上面正常的请求,我们主要关注两部分,如下面的截图:
- 发送请求头 ` +HTTP_TRANSACTION_SEND_REQUEST [dt=1]`
- 读取响应头 ` +HTTP_TRANSACTION_READ_HEADERS [dt=161]`
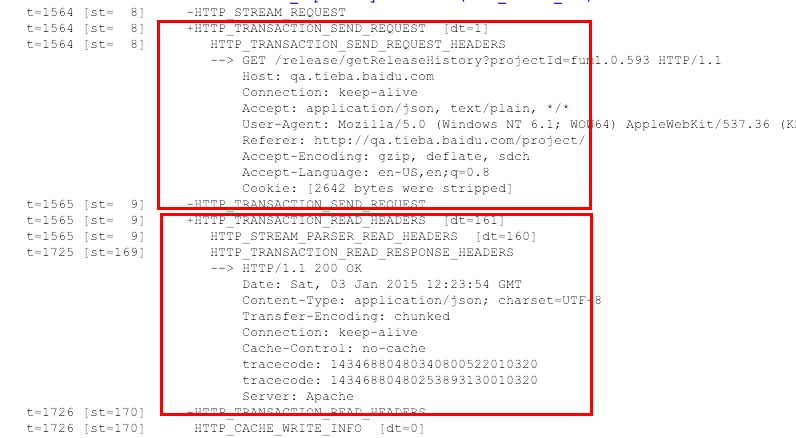
这是正常的情况下,没有什么问题。并且日志里可以清晰地看到发送的请求头是什么,然后解析出来的响应头是什么。这跟在网络面板看到的是一致的。
再回到出问题的请求日志上来,同样我们只关注这两部分。如下面的截图:
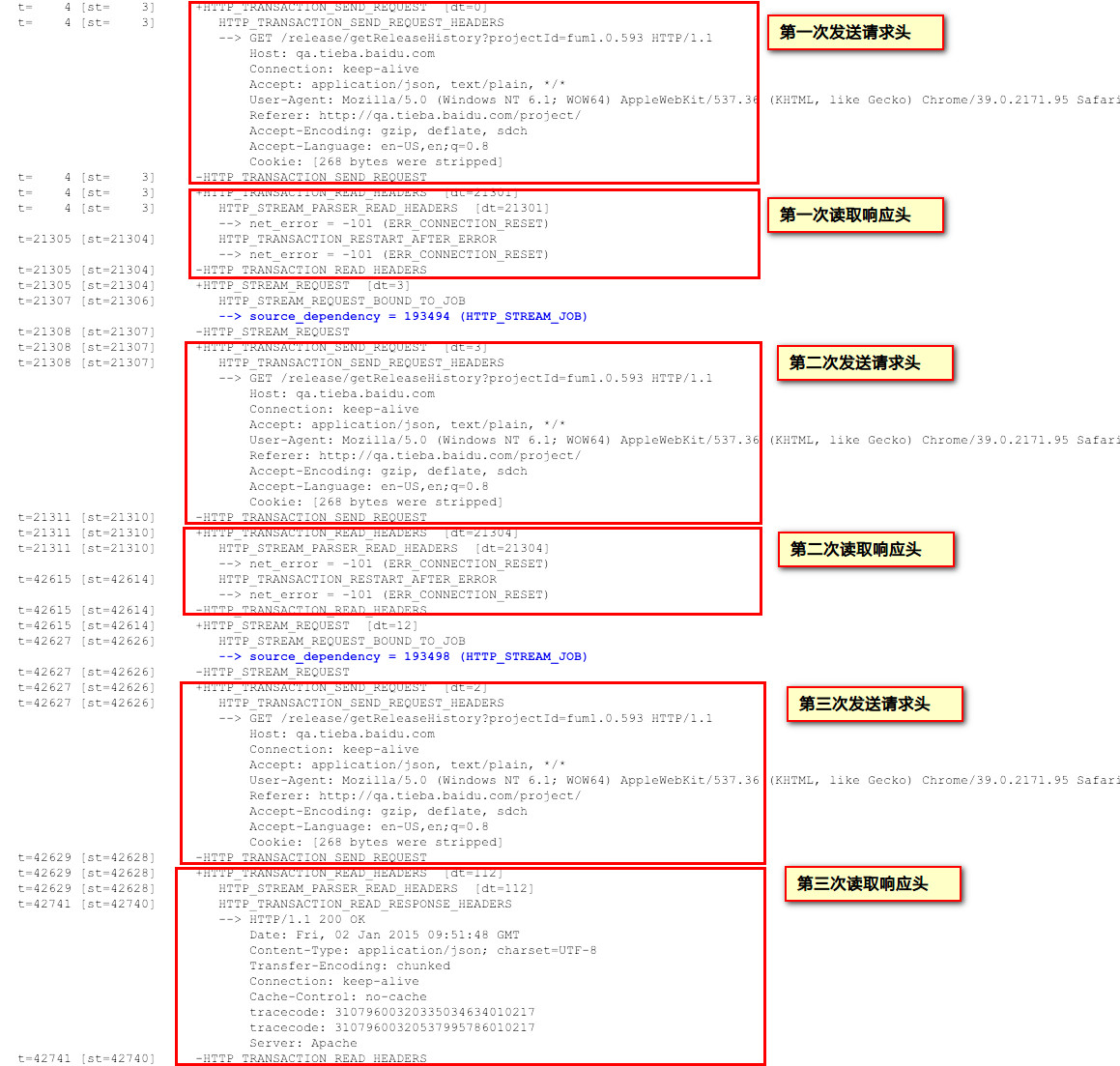
与正常相比,最后一次发送请求和读取响应头无异常,时间就多在了前面还有再次发送和请求的过程,细看时间都花在了以下两个事件中:
HTTP_STREAM_PARSER_READ_HEADERS [dt=21301]HTTP_STREAM_PARSER_READ_HEADERS [dt=21304]
该事件的名称已经自我解读,意思是解析读取的响应头。但问题是紧接着下面报错了,
--> net_error = -101 (ERR_CONNECTION_RESET)
读取响应头时发生了链接重置的错误,有理由认为本次链接是不成功的,没拿到正确的响应头,于是解析不成功。时间都花在了这里,足足21秒之久,两个21秒造就了上面看到的Stalled了42秒之久。
问题似乎已经很明朗了。链接被重置。
在第三次尝试的时候正常了,于是正确返回,我们才看到了被解析的响应头被展示在了下面。也就是说在出问题的时候要么响应头未拿到,要么响应头非法导致解析不成功。而原因就是链接被重置。
那么接下来的工作就是对ERR_CONNECTION_RESET这个错误的追查了。
官方关于 ERR_CONNECTION_RESET 错误的解释
未找到官方相应的资料,Chrome官网上唯一关于此错误的描述是在安装Chrome时出现Error 101。我估计文档的撰写人员没想到谁会这么蛋疼想要看这些生涩的东西,除了开发者。既然你都是开发者了,那为什么不去看Chromium的源码。
好吧,唯一的途径似乎只能从源码中寻找了。作为只精JS的前端人员,现在要从C,C++代码中找答案了。估计追完这个问题,我会尝试为Chromium贡献代码。
慢着,在这之前,还是搜到一些关于这个错误的信息的。但似乎都不怎么靠谱。
比如这里提到,是因为ISP网络问题,实在无太可能。还有这是神马居然一个硬件网站但提到了这个错误,并且怀疑是杀软导致Chrome出问题,但杀软已经在上文被我们排除了。
Chromium 源码
那么这个错误究竟是什么。能不能找到点靠谱的解释。当然能,让我们进入到Chromium的源码中去。
ERR_CONNECTION_RESET被唤起的地方
在Chromium的源码中搜索该常量名,确实出现很多结果。联系到我们查看日志发现问题的上下文,是在解析响应头报的。所以我们定位到http_stream_parser.cc文件,同时注意到有一个文件叫net_errors_win.cc,所以猜测他是定义所有错误常量用的,也顺便打开之。
经过观察src/net/base/net_errors_win.cc 其路径和代码得知其中多为系统级别的错误,似乎跟我们的问题不是很关联,忽略该文件。
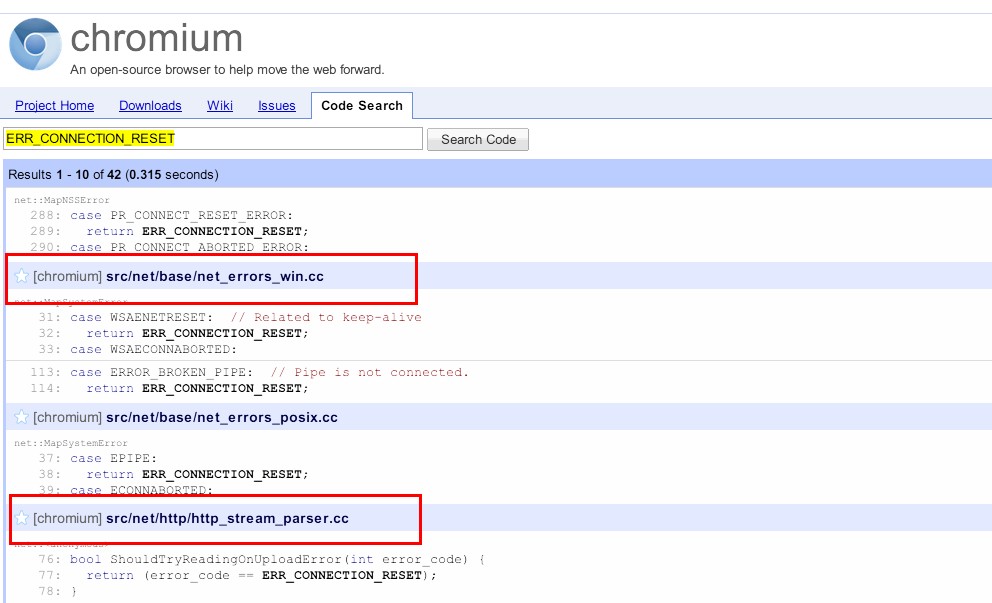
http_stream_parser.cc文件中,ERR_CONNECTION_RESET仅出现一次。这给我们定位带来了极大的便利。
[chromium]//src/net/base/net_errors_win.cc:
// Returns true if |error_code| is an error for which we give the server a
// chance to send a body containing error information, if the error was received
// while trying to upload a request body.
bool ShouldTryReadingOnUploadError(int error_code) {
return (error_code == ERR_CONNECTION_RESET);
}
这里定义了一个ShouldTryReadingOnUploadError 的方法,注释耐人寻味,这个时候,这样的情景,能否正确解读注释成为了比读懂代码更重要(这是我在看JS代码时永远无法体味到的感觉),下面尽可能对它进行理解:
在尝试发送一个请求体的时候,让服务器尝试发送一个带错误的响应体,如果我们接收到了该错误则返回true
我承认被上面的复杂从句打败!
那么我们来看这个方法被调用的场景。
现在我们点击上面的ShouldTryReadingOnUploadError方法,代码下方出现调用了该方法的地方,一共有两处。
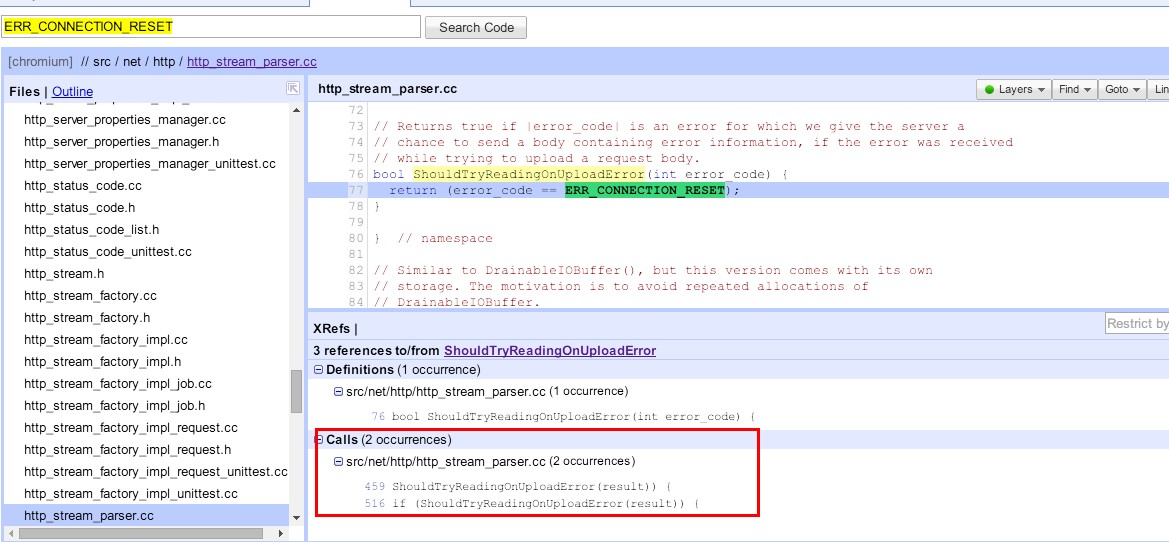
分别点击进行查看。
459行DoSendHeadersComplete方法里进行了调用:
int HttpStreamParser::DoSendHeadersComplete(int result) {
if (result < 0) {
// In the unlikely case that the headers and body were merged, all the
// the headers were sent, but not all of the body way, and |result| is
// an error that this should try reading after, stash the error for now and
// act like the request was successfully sent.
if (request_headers_->BytesConsumed() >= request_headers_length_ &&
ShouldTryReadingOnUploadError(result)) {
upload_error_ = result;
return OK;
}
return result;
}
虽然不太可能,但也不排除头部和请求体合并的情况,当所有头部发送完毕,请求体不一定,此时result便是需要稍后处理的一种错误,这里暂且先返回OK。
516行另一个DoSendBodyComplete方法里进行了调用:
int HttpStreamParser::DoSendBodyComplete(int result) {
if (result < 0) {
// If |result| is an error that this should try reading after, stash the
// error for now and act like the request was successfully sent.
if (ShouldTryReadingOnUploadError(result)) {
upload_error_ = result;
return OK;
}
return result;
}
跟上面类似,如果result出错,稍后处理,先返回正常
这也与我们在日志中看到的情况相符,在前面再次错误后,这次请求并没有终止结束,而是尝试到了第三次并且以成功结束的。
但不管怎样,从这两个方法,一个DoSendHeadersComplete, 另一个DoSendBodyComplete,身上能体现出请求确实已经发出去。
TCP RST
另外,在net_error_list.h这个文件的109行,可以准确找到我们在日志中得到的101号错误。它的定义如下:
// A connection was reset (corresponding to a TCP RST).
NET_ERROR(CONNECTION_RESET, -101)
从括号中的进一步解释可以知道,它代表TCP连接重置。
TCP
那么问题来了,什么是TCP连接重置?什么会引发TCP连接重置。从这篇文章中有比较详细的解答。
想要完全解释,本文似乎是不可能的了。但根据上面的文章,这里可以简单转述一下。
什么是TCP连接
它是一种协议。当网络上一个节点想与另一个节点通信时,双方需要选建立连接。而这个连接过程需要大家都懂的一种约定,TCP就是事先定好的一种约定,于是我们采用它吧,于是其中一个节点按照这个约定发起一建立连接的请求,另一节点收到后,根据该约定,便能读懂这个请求里各字段的意思:哦,丫这是想约我呢。
三次握手
继续上面的例子。A想与B通信,并且使用TCP。
首先A发起一个报文,其中包含自己的地址,想要连接的目标地址,自己用来连接的端口及目标机器的端口,etc.
B收到邀约,并且愿意付约。此刻B需要回传一个报文,告诉A我愿意跟你连接。
A收到B的肯定应答,到此A与B经历了三次通信或者说是握手,双方都没有异议,连接建立。
而连接断开的过程也颇为类似。双方中的一方比如说A先发起一个断开连接的报文FIN,B收到并确认,然后回传一个可以断开的报文FIN给A。此刻A收到并确认。此刻双方都确认后,连接可以安全断开,但还会保持一个等待断开的状态,大概持续4分钟,用于之前连接通路上未传输完成的数据进行善后。
什么是重置
上面提到了4分钟的等待时间,而重置RESET便是立即断开连接的手段。
发生重置的情况
到此重置的作用已然明了。也就是说,重置甚至算不上一个错误,它是TCP连接中的一种正常情况。但什么时候会发生重置,如何引起的。
上文列出了三种情况。
SMB Reset
简单举例来说,服务器提供了两个端口445,139进行服务,客户端同时去请求与这两个端口连接,服务器返回了两个端口可以被连接,此刻客户端择优选择一个进行连接,而重置另一个。
Ack, Reset
报文重置发生主要有以下情况:
- 服务器没有监听被请求的端口,无法建立连接
- 服务器此刻无法比如没有充裕的资源用来连接连接
TCP Reset due to no response
由于没有响应而被重置。当发起连接的一方连续发送6次请求未得到回应,此刻默认他们之间已经通过三次握手建立了连接并且通信有问题,发起的一方将连接重置。
Application Reset
除了上面的情况,找不到TCP内部自己发送的重置,则归为了这一类。程序内将连接重置。此种情况包含了所有你想得到想不到将连接断开的情况。有可能是程序内部逻辑重置的,所以不能完全认为此时发生了错误。
值得注意的是,上面列出的情况服务器的不确定性导致连接重置的可能性要合理些。Chrome 主动发起URL请求不太可能自己又重置掉,并且没有理由重置掉后又去重连。
进一步解读日志文件
上面Chromium源码部分的求证多少带有猜测成分。不妥。
因为没找到关于Chrome net-internal 日志的官方文档什么的,自身去解读始终是有局限的。不如提个ISSUE让Chromium开发人员来搭一把手吧。遂向Chromium提交ISSUE,请戳此查看,虽然我不认为现在遇到的这个问题跟Chrome有关并且属于Chrome的Bug,目的仅仅是看他们能否帮忙给出合理的日志解读来定位问题。
三天后(有点热泪盈眶),有同学回复,将日志所体现的问题诊断得似乎很有道理,可信。
1) We have a bunch of connections to qa.tieba.baidu.com, all were used successfully, and are now idle. 2) They all silently die for some reason, without us ever being informed. My guess is your personal router times out the connection, but this could also be your ISP, the destination server, or ever a real network outage (A short one) that prevents us from getting the connection closed message. 3) There’s a new request to qa.tieba.baidu.com. We try to reuse a socket. After 21 seconds, we get the server’s RST message (“I don’t have a connection to you.”). Since it was a stale socket, we’re aware this sometimes happens, so we just retry…And get the next idle socket in the list, which, after 21 seconds, gives us the same reset message. We try again, for the same reason. This time we don’t have another stale socket to try, so we use a fresh one. The request succeeds.
The real problem here is something is taking 21 seconds to send us the RST messages, despite the fact that a roundtrip to the server you’re talking to only takes about 100 milliseconds.
- 「之前有过很多成功的连接」,确实,因为出现加载缓慢的情况是偶发的,这之前有过很多正常的不卡的请求存在过。这里没有异议。
- 「他们都以未知的原因被断掉了」,因为不是正常地断开连接,所以客户端也就是浏览器不知道当前与服务器的TCP连接已经断开,傻傻地保留着与服务器连接的socket,注意,此时已经发生信息的不对等了,这是问题的根源。至于什么原因,给出了可能的原因:路由器认为连接超时将其断掉,同时不排除ISP(互联网服务提供商)的原因,服务器暂时的停运抽风等。不管怎样,客户端浏览器没有收到连接断开的信息。
- 在上面的基础上,我们去发起一次新的请求。此时浏览器希望重用之前的连接以节省资源,用之前的一个socket去发起连接。21秒后收到服务器返回的重置信息(意思是服务器告诉浏览器:我和你之间没有连接),没关系,上面提到,我们有很多可以重用的连接,于是浏览器重新从可用的连接里面又选择了一个去进行连接,不幸的是,同样的情况再次发生,21秒后收到服务器的重置信息。这体现在日志上就是第二次重试失败。到第三次,因为前面浏览器认为可以重用的连接现在都被正确地标为断开了,没有新的可用,于是这次浏览器发起了全新的请求,成功了!
总结出来,两个问题:
- 为什么之前成功的连接不正常的断开了?服务器配置或者网络原因?
- 是什么让浏览器21秒后才收到重置信息?服务器作出反应过慢还是网络原因?
另附注一下Chrome Dev Tool 中请求的时间线各阶段代表的意义。 以下内容扒自Chrome 开发者文档页,然后我将它本地化了一下下。
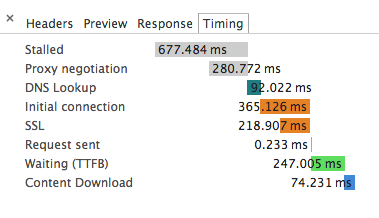
Stalled/Blocking
在请求能够被发出去前的等等时间。包含了用于处理代理的时间。另外,如果有已经建立好的连接,那么这个时间还包括等待已建立连接被复用的时间,这个遵循Chrome对同一源最大6个TCP连接的规则。
「拿我们的情况来说,上面出错所有的耗时也是算在了这部分里面。网络面板中显示的其余时间比如DNS查找,连接建立等都是属于最后那次成功请求的了」
Proxy Negotiation
处理代理的时间。
DNS Lookup
查找DNS的时间。页面上每个新的域都需要一次完整的寻路来完成DNS查找。
Initial Connection / Connecting
用于建立链接的时间,包括TCP握手及多次尝试握手,还有处理SSL。
SSL
完成SSL握手的时间。
Request Sent / Sending
发起请求的时间,通常小到可以忽略。
Waiting (TTFB)
等待响应的时间,具体来说是等待返回首个字节的时间。包含了与服务器之间一个来回响应的时间和等待首个字节被返回的时间。
Content Download / Downloading
用于下载响应的时间
结论
我相信很多同学是直接跳到这里来了的。事实上我给不出什么解决方案,但能排除前端代码引起问题的可能性。
具体来说,能够得到的结论有以下几点:
- 请求成功构造,失败情况下也可以看到正常的请求头被打印出来了的
- 可以肯定的是在与服务器建立连接时被Shut down了,参考上面关于连接重置的部分会更有意义一些
- 参考上面「进一步解读日志文件」部分,来自Chromium开发者的回复中对日志文件的解读更加合理些,浏览器与服务器的连接不正常断开是导致问题的根源,以至于影响了后面对连接的重用
- 21秒的等待仍然是个未知数,不知道有何不可抗拒的外力促使浏览器21秒后才收到服务器的重置信息。此处浏览器与服务器的失联原因有待查证
最后寄希望于RD同学跟进,协助排查服务器连接及后端代码的部分。FE同学会保持持续关注。
参考及引用
#1 Chrome stalls when making multiple requests to same resource?
#2 What does “pending” mean for request in Chrome Developer Window?
#3 Evaluating network performance / Resource network timing
#4 Provisional headers are shown
#5 “CAUTION: provisional headers are shown” in Chrome debugger
#6 Chrome 里的请求报错 “CAUTION: Provisional headers are shown” 是什么意思?
#7 Issue 345643003: Http cache: Implement a timeout for the cache lock
#8 Issue 46104: Pages can get blocked in “Waiting for Cache” for a very long time
#9 Providing Network Details for bug reports
#10 从FE的角度上再看输入url后都发生了什么
#11 ERR_CONNECTION_RESET 的Chromium 源码
#12 Chromium Network Stack
#13 Where do resets come from? (No, the stork does not bring them.)
#14 Issue 447463: Chrome-network: Long delay before RST message on stale sockets results in slow page loads)


 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发

 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发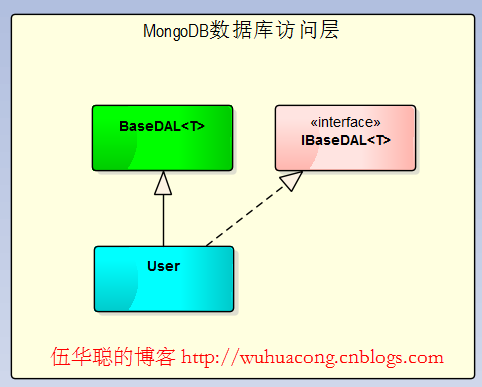

 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发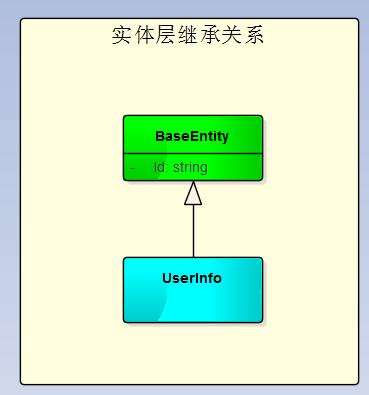


 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发