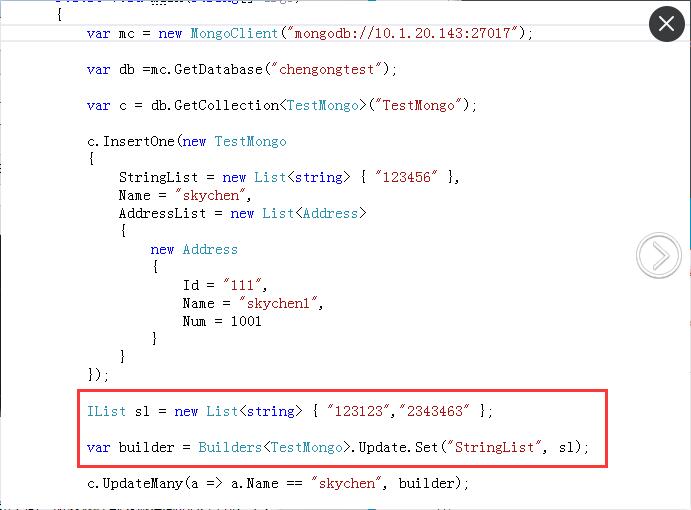
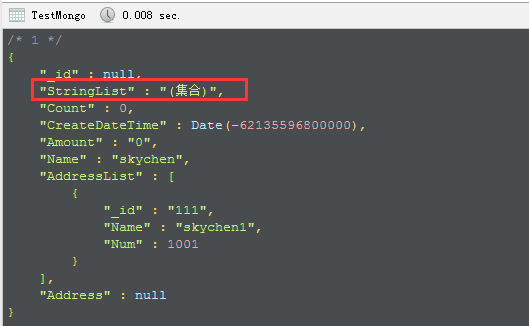
最近这些年,随着前端应用技术突飞猛进,产生了很多新的前端框架,当然也引入了数不胜数的前端技术概念,前端不在是早期Web Form的拖拉处理方式,也不再是Ajax+HTML那么简单,随着前端技术的发展,前端的JS越来越重要,也越来越复杂,而为了开发的方便,引入了很多可以对JS+CSS进行编译的框架,而在发布的时候按需编译处理,从而增强了整个前端的开发过程,这些前端的技术包括AngularJS、React、Vue等等,这些前端技术应用框架又囊括了很多相关的技术,包括了MVVM(Model-View-ViewModel)、ES6、Babel、dva、umi、less等技术或概念。前端技术越滚越大,范围也越来越广,大有日新月异的感觉。
1、前端技术的自我回顾和展望
记得在上大学时候,开始玩asp的年代,前端和后端糅合一起的困境;也曾记得WebForm开发的乐趣和无奈,快捷但是很丑很笨重;而现在还在继续做着Ajax + HTML的这种前端的处理,痛并快乐着。技术总是一步步的推进则,但是眼光一旦聚焦在某个技术范畴,日月如梭,抬头间很快就会发现世界又多了新的前端技术,从开始的犹豫和不确信的停留这段时间后,发现整个前端的世界也已经渐成格局,包括Angular、React、Vue等技术应用已经日趋成熟,而且拥有着庞大的拥趸群体,也有着丰富的资源可供学习和了解。
下面是Angular、React、Vue几个技术框架的一些介绍。
AngularJS诞生于2009年,由Misko Hevery 等人创建,后为Google所收购。是一款优秀的前端JS框架,已经被用于Google的多款产品当中。AngularJS有着诸多特性,最为核心的是:MVC(Model–view–controller)、模块化、自动化双向数据绑定、语义化标签、依赖注入等等。Angular开发在全球开发人员中广泛流行,并被谷歌,福布斯,WhatsApp,Instagram,healthcare.gov和许多财富500强公司等大型组织使用。
React 起源于 Facebook 的内部项目,因为该公司对市场上所有 JavaScript MVC 框架,都不满意,就决定自己写一套,用来架设 Instagram 的网站。做出来以后,发现这套东西很好用,就在2013年5月开源了。 由于 React 的设计思想极其独特,属于革命性创新,性能出众,代码逻辑却非常简单。所以,越来越多的人开始关注和使用,认为它可能是将来 Web 开发的主流工具。
Vue.js是讨论最多且发展最快的JavaScript框架之一。它由前谷歌员工Evan You创建,他在担任Google员工时曾在Angular工作过。您可以认为它是成功的,因为它能够使用HTML,CSS和JavaScript构建有吸引力的UI。
这些技术各有优点,很难片面的说明谁优谁劣,它们都各自有自己的生存土壤和大批的拥趸,而我开始选型做前端技术更新的时候,主要看中的是阿里巴巴的Ant-Design开发框架,这个它是使用了React的技术框架,因此也就自然而然的研究学习起React和Ant-Design来,虽然之前对前端的一些技术有所涉猎,但是真正等你想要进入Ant-Design的开发大门的时候,还是感觉自己像进入了一个前端技术的大观园,一个个新概念接踵而来,一种种代码的写法迎面冲击,教程看了几遍还是一头雾水,真的开始怀疑人生了,不过学习新技术还是需要很多平静的心态,调整好,一步一个脚印相信还是有所斩获的,偶尔看到阮一峰的大牛介绍在学习研究React的时候,也曾花了几个月的时候,虽然他的高度难以看齐,但是学习的韧劲和毅力,是值得我们学习的。学习新的东西,从技术角度,可以满足好奇心,提高技术水平;从职业角度,有利于求职和晋升,有利于参与潜力大的项目(摘自阮一峰笔记)。
2、React的技术学习
接触一些新的东西,就必然需要投入精力来学习掌握。对于学习Ant-Desin,虽然这个框架本身提供了很多教程介绍,但是我们一些技术点,还是需要更细节的学习,首推还是阮一峰的技术日志吧。
1、ECMAScript 6 入门
2、React 入门实例教程
3、Redux 入门教程(一):基本用法
4、Redux 入门教程(二):中间件与异步操作
5、Redux 入门教程(三):React-Redux 的用法
6、Redux 文档基础教程
7、DvaJS快速上手
下面有些内容在学习的时候,掌握的不是很好,摘录并作为一个回顾吧。
模块的 Import 和 Export
import 用于引入模块,export 用于导出模块。
// 引入全部
import dva from 'dva';
// 引入部分
import { connect } from 'dva';
import { Link, Route } from 'dva/router';
// 引入全部并作为 github 对象
import * as github from './services/github';
// 导出默认
export default App;
// 部分导出,需 import { App } from './file'; 引入
export class App extend Component {};
析构赋值
析构赋值让我们从 Object 或 Array 里取部分数据存为变量。
// 对象
const user = { name: 'guanguan', age: 2 };
const { name, age } = user;
console.log(`${name} : ${age}`); // guanguan : 2
// 数组
const arr = [1, 2];
const [foo, bar] = arr;
console.log(foo); // 1
我们也可以析构传入的函数参数。
const add = (state, { payload }) => {
return state.concat(payload);
};
//析构时还可以配 alias,让代码更具有语义
const add = (state, { payload: todo }) => {
return state.concat(todo);
};
对象展开运算符(Object Spread Operator)
//可用于组装数组。
const todos = ['Learn dva'];
[...todos, 'Learn antd']; // ['Learn dva', 'Learn antd']
//也可用于获取数组的部分项。
const arr = ['a', 'b', 'c'];
const [first, ...rest] = arr;
rest; // ['b', 'c']
// With ignore
const [first, , ...rest] = arr;
rest; // ['c']
//还可收集函数参数为数组。
function directions(first, ...rest) {
console.log(rest);
}
directions('a', 'b', 'c'); // ['b', 'c'];
//代替 apply。
function foo(x, y, z) {}
const args = [1,2,3];
// 下面两句效果相同
foo.apply(null, args);
foo(...args);
//对于 Object 而言,用于组合成新的 Object
const foo = {
a: 1,
b: 2,
};
const bar = {
b: 3,
c: 2,
};
const d = 4;
const ret = { ...foo, ...bar, d }; // { a:1, b:3, c:2, d:4 }
propTypes
JavaScript 是弱类型语言,所以请尽量声明 propTypes 对 props 进行校验,以减少不必要的问题。
function App(props) {
return <div>{props.name}</div>;
}
App.propTypes = {
name: React.PropTypes.string.isRequired,
};
内置的 prop type 有:
- PropTypes.array
- PropTypes.bool
- PropTypes.func
- PropTypes.number
- PropTypes.object
- PropTypes.string
DVA数据流向
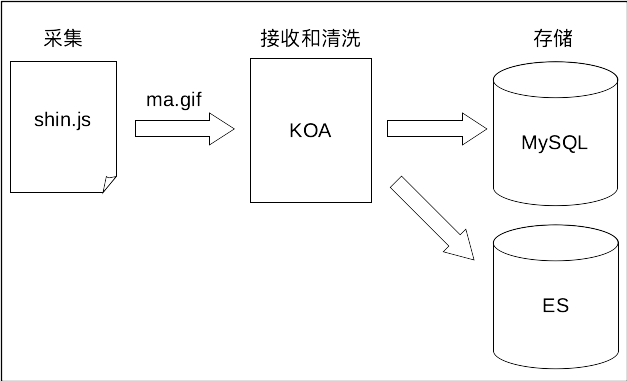
数据的改变发生通常是通过用户交互行为或者浏览器行为(如路由跳转等)触发的,当此类行为会改变数据的时候可以通过 dispatch 发起一个 action,如果是同步行为会直接通过 Reducers 改变 State ,如果是异步行为(副作用)会先触发 Effects 然后流向 Reducers 最终改变 State。
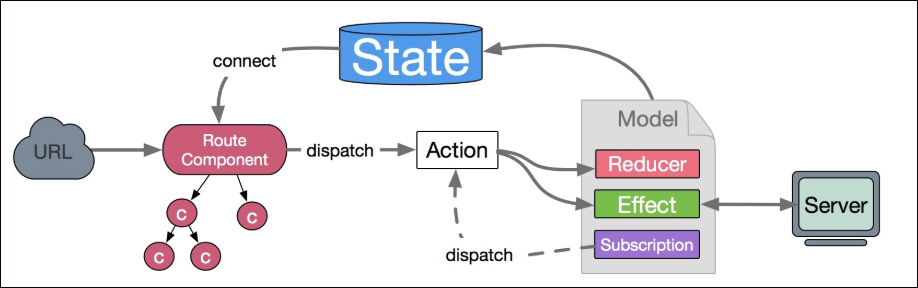
Reducer和effects
reducer 是一个函数,接受 state 和 action,返回老的或新的 state 。即:(state, action) => state
app.model({
namespace: 'todos',
state: [],
reducers: {
add(state, { payload: todo }) {
return state.concat(todo);
},
remove(state, { payload: id }) {
return state.filter(todo => todo.id !== id);
},
update(state, { payload: updatedTodo }) {
return state.map(todo => {
if (todo.id === updatedTodo.id) {
return { ...todo, ...updatedTodo };
} else {
return todo;
}
});
},
},
};
建议最多一层嵌套,以保持 state 的扁平化,深层嵌套会让 reducer 很难写和难以维护。
app.model({
namespace: 'app',
state: {
todos: [],
loading: false,
},
reducers: {
add(state, { payload: todo }) {
const todos = state.todos.concat(todo);
return { ...state, todos };
},
},
});
effects示例
app.model({
namespace: 'todos',
effects: {
*addRemote({ payload: todo }, { put, call }) {
yield call(addTodo, todo);
yield put({ type: 'add', payload: todo });
},
},
});
put用于触发 action,call用于调用异步逻辑,支持 promise。
异步请求
异步请求基于 whatwg-fetch,API 详见:https://github.com/github/fetch
GET 和 POST
import request from '../util/request';
// GET
request('/api/todos');
// POST
request('/api/todos', {
method: 'POST',
body: JSON.stringify({ a: 1 }),
});
统一错误处理
假如约定后台返回以下格式时,做统一的错误处理。
{
status: 'error',
message: '',
}
编辑 utils/request.js,加入以下中间件:
function parseErrorMessage({ data }) {
const { status, message } = data;
if (status === 'error') {
throw new Error(message);
}
return { data };
}
然后,这类错误就会走到 onError hook 里。
Subscription
subscriptions 是订阅,用于订阅一个数据源,然后根据需要 dispatch 相应的 action。数据源可以是当前的时间、服务器的 websocket 连接、keyboard 输入、geolocation 变化、history 路由变化等等。格式为 ({ dispatch, history }) => unsubscribe 。
异步数据初始化
比如:当用户进入 /users 页面时,触发 action users/fetch 加载用户数据。
app.model({
subscriptions: {
setup({ dispatch, history }) {
history.listen(({ pathname }) => {
if (pathname === '/users') {
dispatch({
type: 'users/fetch',
});
}
});
},
},
});
react dva 的 connect 与 @connect
connect的作用是将组件和models结合在一起。将models中的state绑定到组件的props中。并提供一些额外的功能,譬如dispatch
connect 的使用
connect 方法返回的也是一个 React 组件,通常称为容器组件。因为它是原始 UI 组件的容器,即在外面包了一层 State。
connect 方法传入的第一个参数是 mapStateToProps 函数,该函数需要返回一个对象,用于建立 State 到 Props 的映射关系。
简而言之,connect接收一个函数,返回一个函数。
第一个函数会注入全部的models,你需要返回一个新的对象,挑选该组件所需要的models。
export default connect(({ user, login, global = {}, loading }) => ({
currentUser: user.currentUser,
collapsed: global.collapsed,
fetchingNotices: loading.effects['global/fetchNotices'],
notices: global.notices
}))(BasicLayout);
// 简化版
export default connect(
({ user, login, global = {}, loading }) => {
return {
currentUser: user.currentUser,
collapsed: global.collapsed,
fetchingNotices: loading.effects['global/fetchNotices'],
notices: global.notices
}
}
)(BasicLayout);
@connect的使用
其实只是connect的装饰器、语法糖罢了。
// 将 model 和 component 串联起来
export default connect(({ user, login, global = {}, loading }) => ({
currentUser: user.currentUser,
collapsed: global.collapsed,
fetchingNotices: loading.effects['global/fetchNotices'],
notices: global.notices,
menuData: login.menuData,
redirectData: login.redirectData,
}))(BasicLayout);
// 改为这样(export 的不再是connect,而是class组件本身。),也是可以执行的,但要注意@connect必须放在export default class前面:
// 将 model 和 component 串联起来
@connect(({ user, login, global = {}, loading }) => ({
currentUser: user.currentUser,
collapsed: global.collapsed,
fetchingNotices: loading.effects['global/fetchNotices'],
notices: global.notices,
menuData: login.menuData,
redirectData: login.redirectData,
}))
export default class BasicLayout extends React.PureComponent {
// ...
}
export default connect(从 model 的 state 中获取数据)(要将数据绑定到哪个组件)
以上部分内容摘自 https://blog.csdn.net/zhangrui_web/article/details/79651812
2、Ant-Design的框架
这款基于React开发的UI框架,界面非常简洁美观,是阿里巴巴旗下蚂蚁金融服务集团(旗下拥有支付宝、余额宝等产品)所设计的一个前端UI组件库。目前支持了React, 并且有一个对Vue支持的测试版本。
学习和使用Ant-Design,我们可以使用VSCode来对项目代码进行维护和编辑,这样可以在Mac和Window环境同样的开发体验和操作模式,非常方便。
如果需要掌握Ant-Design框架,我们需要了解model,namespace,connect,dispatch,action,reducer ,effect这些概念。
DVA 的 model 对象有几个基本的属性介绍。
namespace:model 的命名空间,只能用字符串。一个大型应用可能包含多个 model,通过namespace区分。
state:当前 model 状态的初始值,表示当前状态。
reducers:用于处理同步操作,可以修改 state,由 action 触发。reducer 是一个纯函数,它接受当前的 state 及一个 action 对象。action 对象里面可以包含数据体(payload)作为入参,需要返回一个新的 state。
effects:用于处理异步操作(例如:与服务端交互)和业务逻辑,也是由 action 触发。但是,它不可以修改 state,要通过触发 action 调用 reducer 实现对 state 的间接操作。
action:action 就是一个普通 JavaScript 对象,是 reducers 及 effects 的触发器,形如{ type: 'add', payload: todo },通过 type 属性可以匹配到具体某个 reducer 或者 effect,payload 属性则是数据体,用于传送给 reducer 或 effect。
整体的数据流向见下图:
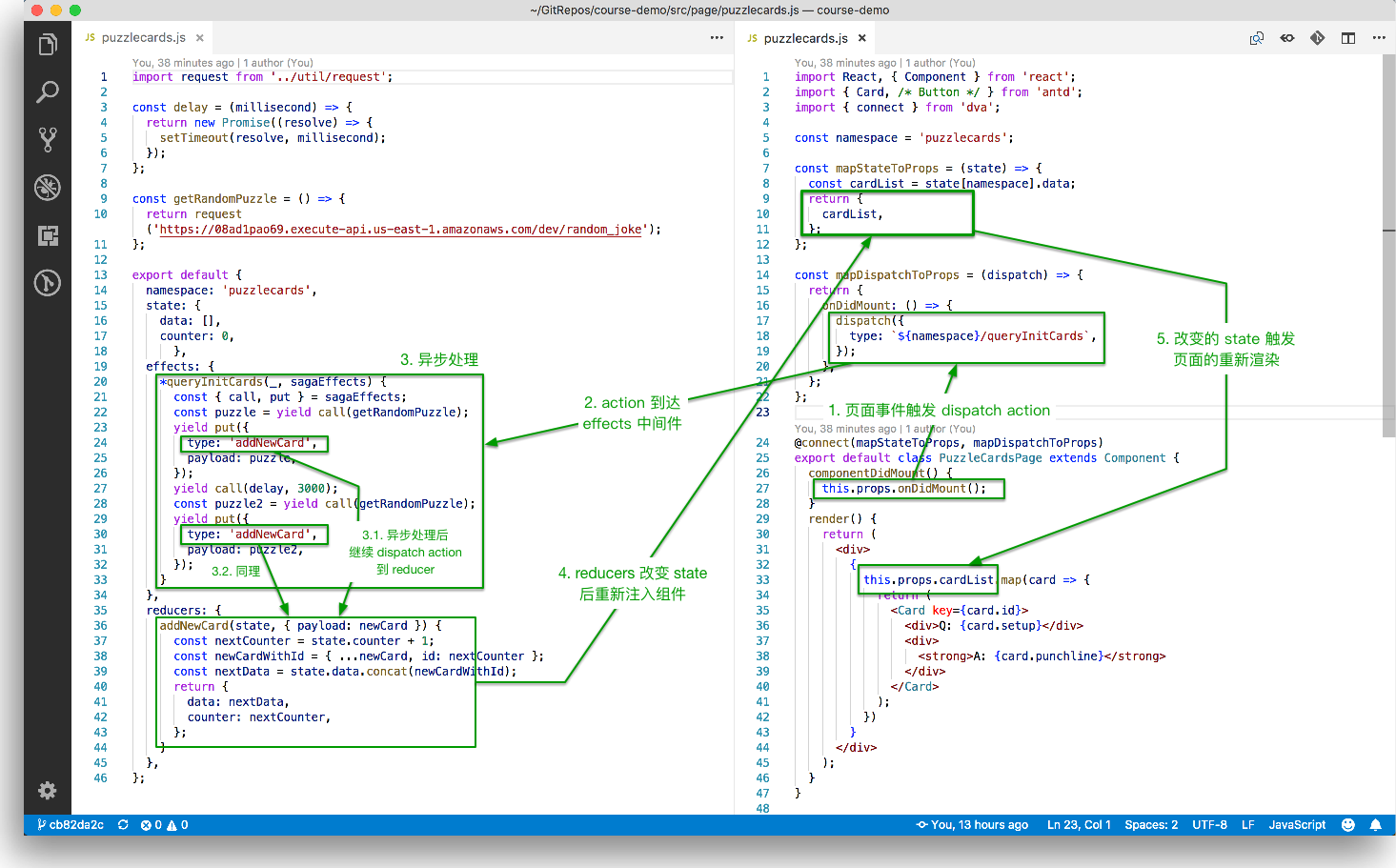
在Reducer里面,不要修改传入的 state。 使用 Object.assign() 新建了一个副本。不能这样使用 Object.assign(state, { visibilityFilter: action.filter }),因为它会改变第一个参数的值。你必须把第一个参数设置为空对象。
function todoApp(state = initialState, action) {
switch (action.type) {
case SET_VISIBILITY_FILTER:
return Object.assign({}, state, {
visibilityFilter: action.filter
})
default:
return state
}
}
或者使用使用对象展开运算符(Object Spread Operator)来处理,从而使用 { ...state, ...newState } 达到相同的目的。
reducers: {
save(state, action) {
return {
...state,
...action.payload,
};
},
},
在 default 情况下返回旧的 state。遇到未知的 action 时,一定要返回旧的 state。
每个 reducer 只负责管理全局 state 中它负责的一部分。每个 reducer 的 state 参数都不同,分别对应它管理的那部分 state 数据。
下面两种合成 reducer 方法完全等价:
const reducer = combineReducers({
a: doSomethingWithA,
b: processB,
c: c
})
function reducer(state = {}, action) {
return {
a: doSomethingWithA(state.a, action),
b: processB(state.b, action),
c: c(state.c, action)
}
}
dva封装了redux,减少很多重复代码比如action reducers 常量等,dva所有的redux操作是放在models目录下,通过namespace作为key,标识不同的模块state,可以给state设置初始数据。
reducers跟传统的react-redux写法一致,所有的操作放在reducers对象内
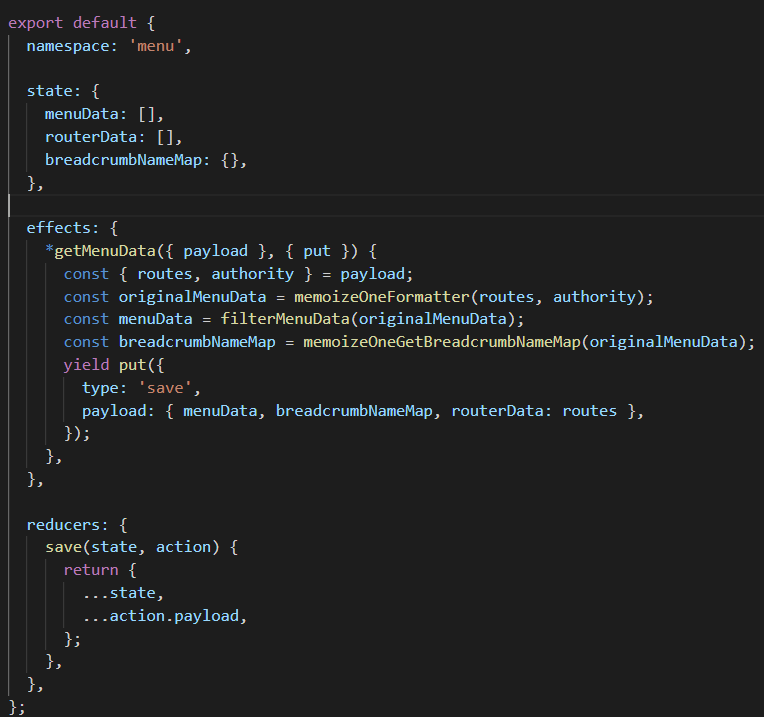
Effect 被称为副作用,在我们的应用中,最常见的就是异步操作,Effects 的最终流向是通过 Reducers 改变 State。
其中上面的effects里面,call, put其实是saga的写法,dva集成了saga,可以参考上图中的saga内容
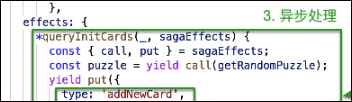
DVA 首先是一个基于 redux 和 redux-saga 的数据流方案,然后为了简化开发体验,DVA 还额外内置了 react-router 和 fetch,所以也可以理解为一个轻量级的应用框架。
DVA 是基于现有应用架构 (redux + react-router + redux-saga 等)的一层轻量封装,没有引入任何新概念,全部代码不到 100 行。
在Ant-Design的Pages/.umi目录里面,有一个initDva.js文件,就是用来统一批量处理 DVA 的引入的,如下所示。

在有 DVA 之前,我们通常会创建 sagas/products.js, reducers/products.js 和 actions/products.js,然后在这些文件之间来回切换。
有了 DVA 后,它最核心的是提供了 app.model 方法,用于把 reducer, initialState, action, saga 封装到一起,这样我们在书写代码的时候,把它主要内容,和加载分离出来。如果建立的Model比较多,每次开始的时候需要加入这一句好像也是挺麻烦的,如果可以自动把这个model批量加入,应该会更好吧,不过不知道是基于什么考量。




















 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
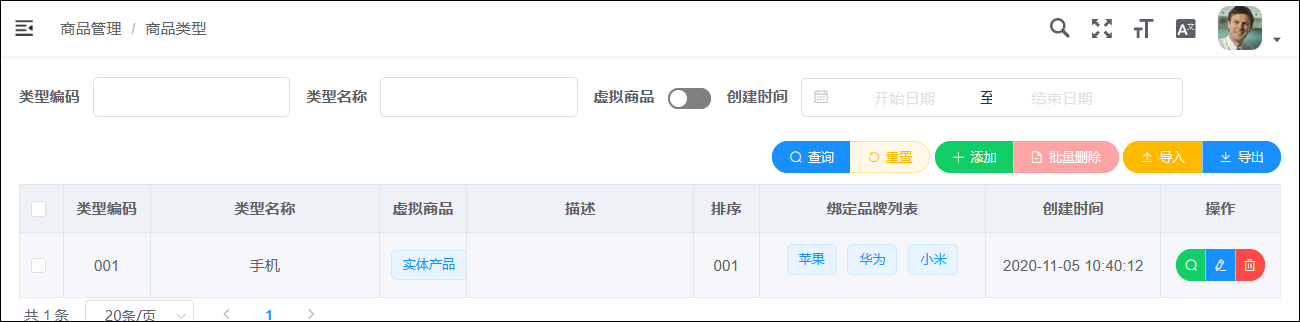
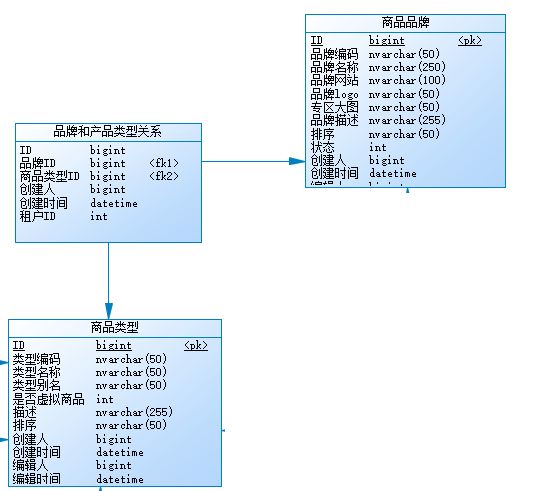
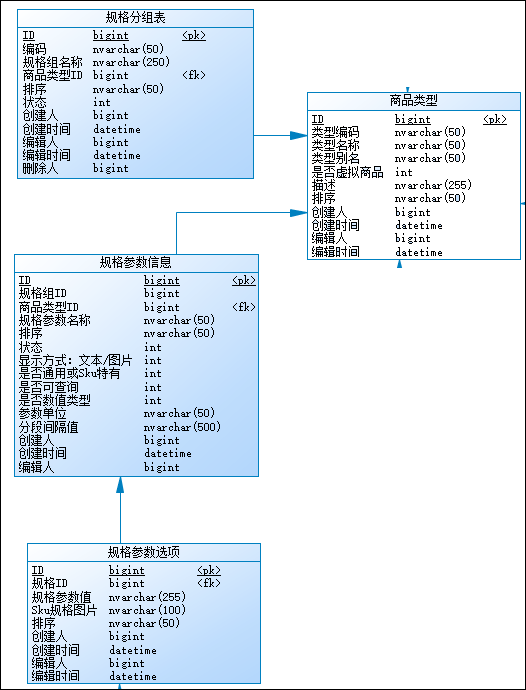
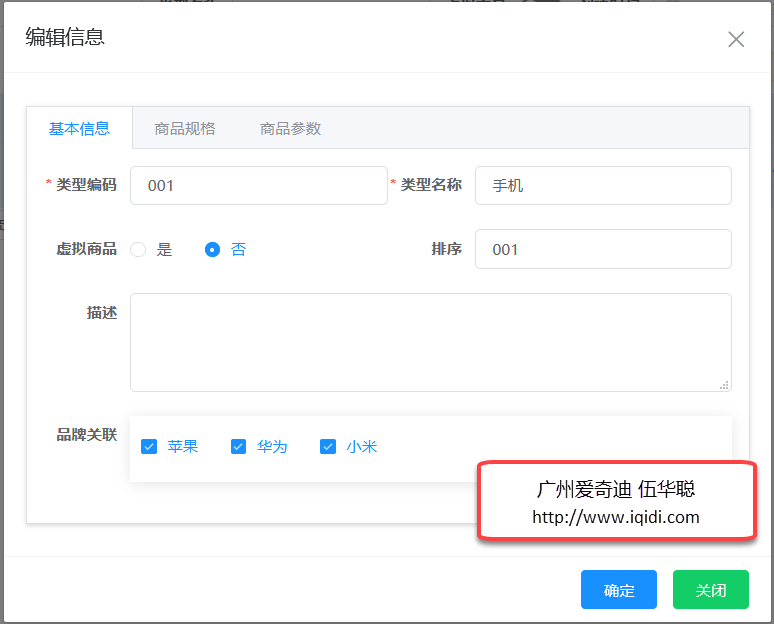

 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发