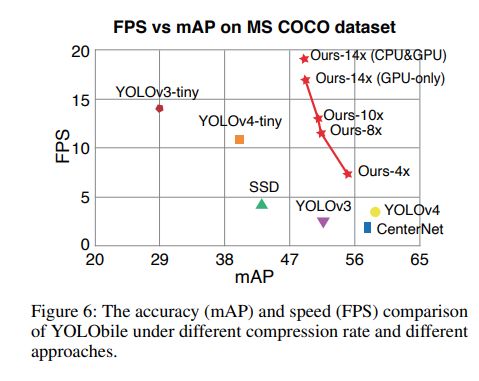
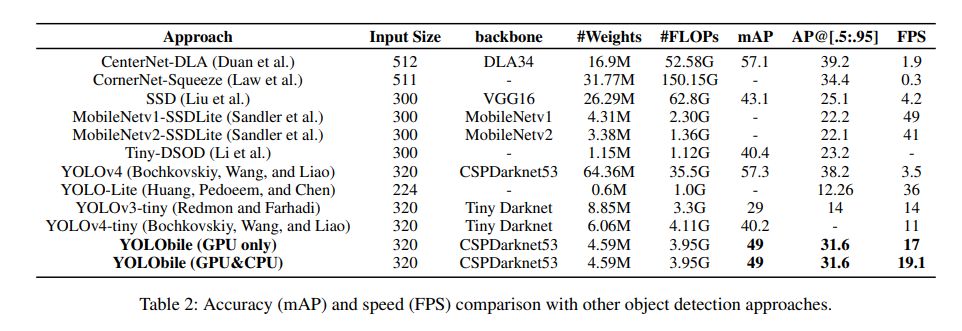
来源: layer.js源码分析_极客神殿-CSDN博客_layer源码解析
最近在看layer.js源码,从中得到了一些启发,对于一个框架的设计也有了一定的看法,现在对于这个框架的设计以及其他的问题来说明一下。
layer.js是一个专注于弹出层的框架,这个框架本身可以实现5种弹出层类型,其他的就不多说了,可以去看看它的官网,下面说一下它的主要组织形式:
- 首先,这个框架本身就是一个IIFE(立即执行函数表达式),保证了局部环境,避免了全局变量污染的问题
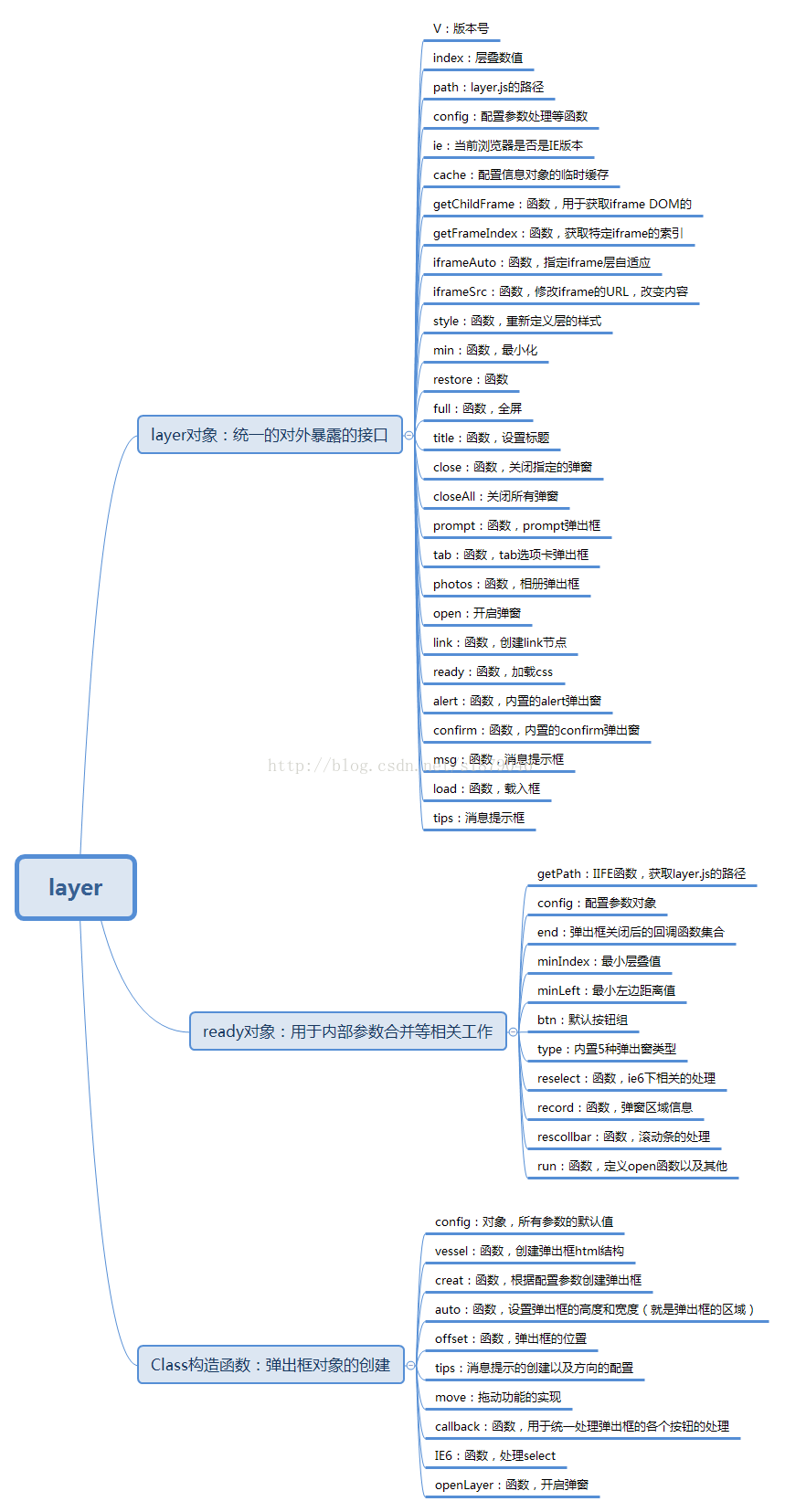
- 框架内部主要是三个对象构成,分别是Class构造函数、layer对象、ready对象
- 通过window来暴露对外api
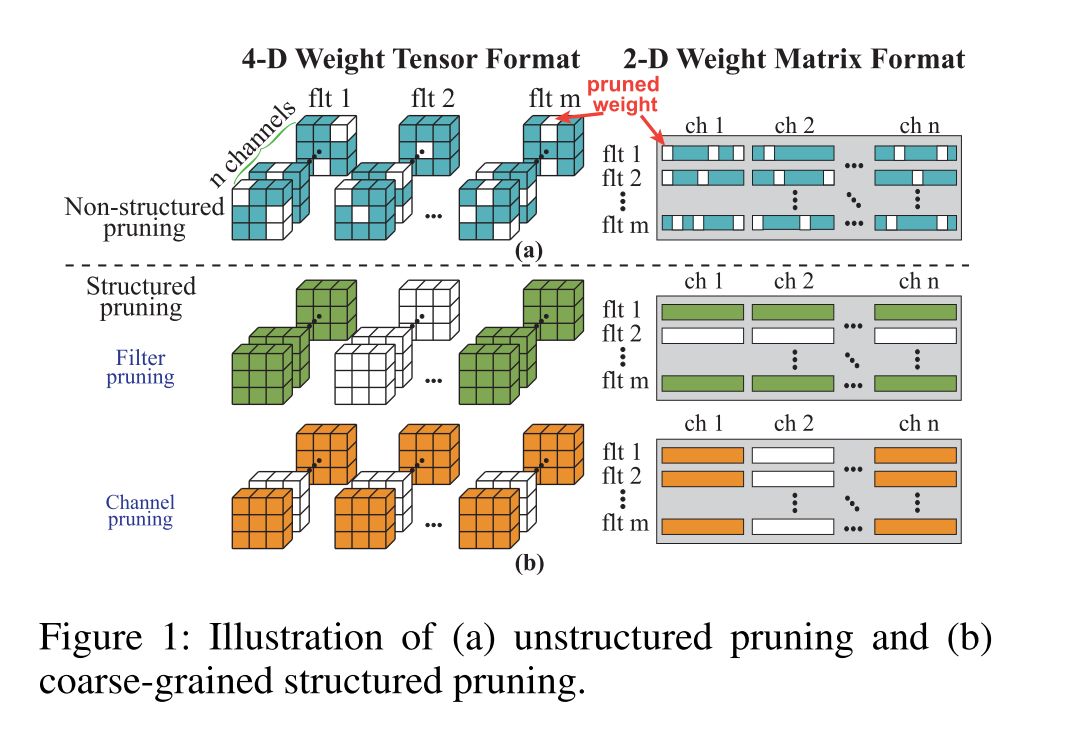
以前看过一点JQuery的源码,layer.js的框架结构和JQuery是相同形式,框架内部主要是这三个对象来组成,对于这三个对象上具体的方法以及属性我列举了下,如下图所示:
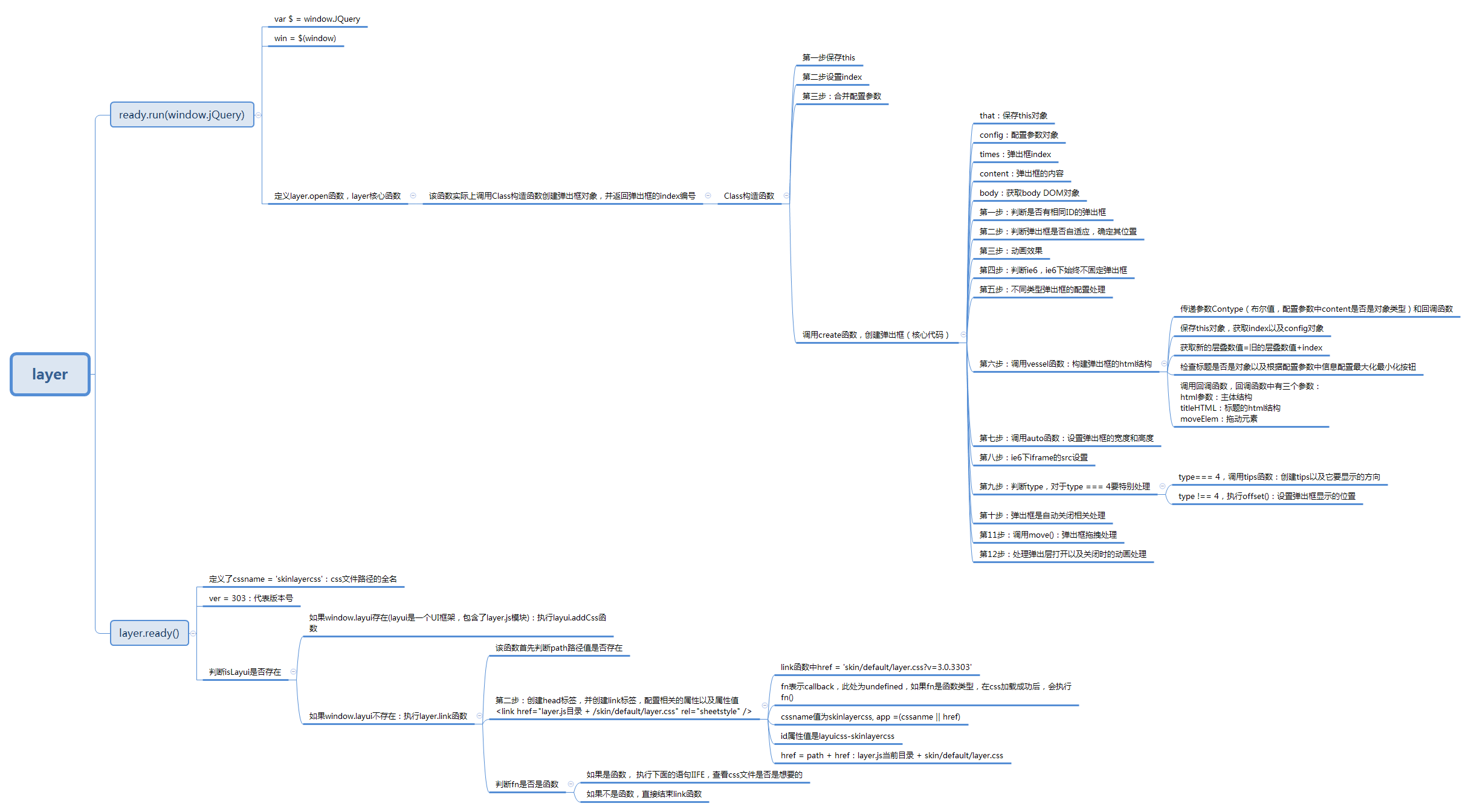
整个框架的结构组织以及脉络还是很清晰的,框架整体的代码量大概1300多行左右,我对这个框架运行的具体流程做了个较为详细的流程,具体流程如下:
/*!
@Title: Layui
@Description:经典模块化前端框架
@Site: www.layui.com
@Author: 贤心
@License:MIT
*/
;!function(win) {
"use strict";
var Lay = function() {
this.v = '1.0.9_rls'; //版本号
};
Lay.fn = Lay.prototype;
var doc = document,
config = Lay.fn.cache = {},
// 获取本js所在目录
getPath = function() {
var js = doc.scripts,
jsPath = js[js.length - 1].src;
return jsPath.substring(0, jsPath.lastIndexOf('/') + 1);
}(),
// 异常提示
error = function(msg) {
win.console && console.error && console.error('Layui hint: ' + msg);
},
// 检测opera环境
isOpera = typeof opera !== 'undefined' && opera.toString() === '[object Opera]',
// 内置模块
modules = {
layer : 'modules/layer', //弹层
laydate : 'modules/laydate', //日期
laypage : 'modules/laypage', //分页
laytpl : 'modules/laytpl', //模板引擎
layim : 'modules/layim', //web通讯
layedit : 'modules/layedit', //富文本编辑器
form : 'modules/form', //表单集
upload : 'modules/upload', //上传
tree : 'modules/tree', //树结构
table : 'modules/table', //富表格
element : 'modules/element', //常用元素操作
util : 'modules/util', //工具块
flow : 'modules/flow', //流加载
carousel : 'modules/carousel', //轮播
code : 'modules/code', //代码修饰器
jquery : 'modules/jquery', //DOM库(第三方)
mobile : 'modules/mobile', //移动大模块 | 若当前为开发目录,则为移动模块入口,否则为移动模块集合
'layui.all' : 'dest/layui.all' //PC模块合并版
};
config.modules = {}; //记录模块物理路径
config.status = {}; // 记录已注册的模块集。
config.timeout = 10; //符合规范的模块请求最长等待秒数
config.event = {}; //记录模块自定义事件
// 定义模块
Lay.fn.define = function(deps, callback) {
var that = this,
type = typeof deps === 'function',
mods = function() {
// 参数callback,可选,用于回调。
// 回调参数function,用于回调时,注册模块。
typeof callback === 'function' && callback(function(app, exports) {
// 回调参数function的参数app,必要,代表模块名。
// 回调参数function的参数exports,必要,代表模块的接口方法。
layui[app] = exports;
// config.status,记录已注册的模块集。
config.status[app] = true;
});
return this;
};
// 参数deps,代表依赖的模块集,可选。
type && (
callback = deps,
deps = []
);
// 相当于layui['layui.all'] || layui['layui.mobile']
// 模块名layui.all,代表所有模块。
// 模块名layui.mobile,代表手机版的所有模块。
// 如果已经加载所有模块,则直接执行回调。
if (layui['layui.all'] || (!layui['layui.all'] && layui['layui.mobile'])) {
return mods.call(that);
}
// 方法layui.use,动态加载所依赖的模块集deps。
that.use(deps, mods);
return that;
};
// 动态加载模块集
Lay.fn.use = function(apps, callback, exports) {
var that = this,
// config.dir,内置文件的基目录,默认值为layui.js的所在目录,需以斜杠结束。
dir = config.dir = config.dir ? config.dir : getPath;
var head = doc.getElementsByTagName('head')[0];
// 参数apps,必要,可以是字符串或数组。
apps = typeof apps === 'string' ? [ apps ] : apps;
// 参数apps中存在jquery时,如果页面已加载jQuery1.7+库,则直接使用该库。
if (window.jQuery && jQuery.fn.on) {
that.each(apps, function(index, item) {
if (item === 'jquery') {
apps.splice(index, 1);
}
});
layui.jquery = jQuery;
}
var item = apps[0],
timeout = 0;
// 参数exports,可选。
exports = exports || [];
// config.host,格式为“//.../”,默认值为config.dir中的主机,或当前页面的主机。
config.host = config.host || (dir.match(/\/\/([\s\S]+?)\//)/* 匹配“//.../” */ || [ '//' + location.host + '/' ])[0];
// apps.length === 0 || (layui['layui.all'] || layui['layui.mobile']) && modules[item]
// 参数apps,允许为空集。
// 如果需要加载的模块集为空集,则执行回调。
// 模块名layui.all,代表所有模块。
// 模块名layui.mobile,代表手机版的所有模块。
// modules,代表layui的内置模块集。
// 如果已经加载所有模块,并且当前模块是layui的内置模块,则当前模块不需要加载。
if (apps.length === 0
|| (layui['layui.all'] && modules[item])
|| (!layui['layui.all'] && layui['layui.mobile'] && modules[item])
) {
return onCallback(), that;
}
// 用于监听文件加载完毕
function onScriptLoad(e, url) {
var readyRegExp = navigator.platform === 'PLaySTATION 3' ? /^complete$/ : /^(complete|loaded)$/
if (e.type === 'load' || (readyRegExp.test((e.currentTarget || e.srcElement).readyState))) {
config.modules[item] = url;
head.removeChild(node);
// 轮询查看当前模块是否已注册,每0.025秒轮询一次,共论询config.timeout秒。
// config.timeout,文件加载超时,默认值为10秒。
(function poll() {
if (++timeout > config.timeout * 1000 / 4) {
return error(item + ' is not a valid module');
};
config.status[item] ? onCallback() : setTimeout(poll, 4);
}());
}
}
var node = doc.createElement('script'),
// config.base,代表扩展模块的JS文件目录,默认值为空串,需要以斜杠结束。
// modules,代表layui的内置模块集。
// layui.modules[name],代表模块name的相对路径(不包括后缀.js),默认值为name。
// 如果当前模块是内置模块,则相对路径相对于config.dir + "lay/"。
// 如果当前模块是扩展模块,则相对路径相对于config.base。
url = (modules[item] ? (dir + 'lay/') : (config.base || '')) + (that.modules[item] || item) + '.js';
node.async = true;
node.charset = 'utf-8';
node.src = url + function() {
// config.version=true时,使用config.v作为版本号,否则自己作为版本号,默认值不启用版本号。
// config.v,代表版本号,默认值为当前时间。
// config.version=true,config.v不设置时,使流览器不会加载缓存文件,而是重新加载。
var version = config.version === true ? (config.v || (new Date()).getTime()) : (config.version || '');
return version ? ('?v=' + version) : '';
}();
// config.modules[name],代表已加载,或正在加载中的模块name的相对路径(不包括后缀.js)。
if (!config.modules[item]) {
head.appendChild(node);
if (node.attachEvent && !(node.attachEvent.toString && node.attachEvent.toString().indexOf('[native code') < 0) && !isOpera) {
node.attachEvent('onreadystatechange', function(e) {
onScriptLoad(e, url);
});
} else {
node.addEventListener('load', function(e) {
onScriptLoad(e, url);
}, false);
}
} else {
// 轮询查看是否加载完毕,每0.025秒轮询一次,共论询config.timeout秒。
// config.timeout,文件加载超时,默认值为10秒。
(function poll() {
if (++timeout > config.timeout * 1000 / 4) {
return error(item + ' is not a valid module');
};
// config.status,记录已注册的模块集。
(typeof config.modules[item] === 'string' && config.status[item]) ? onCallback() : setTimeout(poll, 4);
}());
}
config.modules[item] = url;
//回调
function onCallback() {
// 参数exports,记录模块的接口。
exports.push(layui[item]);
// 加载下一个模块,如果没有下一个,则执行回调。
apps.length > 1 ? that.use(apps.slice(1), callback, exports) : (typeof callback === 'function' && callback.apply(layui, exports));
}
return that;
};
// 获取节点的style属性值
Lay.fn.getStyle = function(node, name) {
var style = node.currentStyle ? node.currentStyle : win.getComputedStyle(node, null);
return style[style.getPropertyValue ? 'getPropertyValue' : 'getAttribute'](name);
};
// 动态加载CSS
Lay.fn.link = function(href, fn, cssname) {
var that = this,
link = doc.createElement('link');
var head = doc.getElementsByTagName('head')[0];
// 参数fn,可选。
if (typeof fn === 'string')
cssname = fn;
// 参数cssname,用于标识CSS文件的ID,默认值为href。
var app = (cssname || href).replace(/\.|\//g, '');
var id = link.id = 'layuicss-' + app,
timeout = 0;
link.rel = 'stylesheet';
// config.debug=true时,使流览器不会加载缓存文件。
link.href = href + (config.debug ? '?v=' + new Date().getTime() : '');
link.media = 'all';
// 参数cssname,同一ID的CSS文件的只许加载一次。
if (!doc.getElementById(id)) {
head.appendChild(link);
}
// 参数fn,用于监听CSS加载完毕。
if (typeof fn !== 'function') return;
// 轮询查看是否加载完毕,每0.1秒轮询一次,共论询config.timeout秒。
(function poll() {
if (++timeout > config.timeout * 1000 / 100) {
return error(href + ' timeout');
};
parseInt(that.getStyle(doc.getElementById(id), 'width')) === 1989 ? function() {
fn();
}() : setTimeout(poll, 100);
}());
};
// css内部加载器
Lay.fn.addcss = function(firename, fn, cssname) {
// 全局配置dir,用于内置文件的基目录,默认值为layui.js所在的目录,需要以斜杠结束。
layui.link(config.dir + 'css/' + firename, fn, cssname);
};
// 图片预加载
Lay.fn.img = function(url, callback, error) {
var img = new Image();
img.src = url;
if (img.complete) {
return callback(img);
}
img.onload = function() {
img.onload = null;
callback(img);
};
img.onerror = function(e) {
img.onerror = null;
error(e);
};
};
// 全局配置
Lay.fn.config = function(options) {
options = options || {};
for (var key in options) {
config[key] = options[key];
}
return this;
};
// layui.modules[name],代表模块name的相对路径(不包括后缀.js),默认值为name。
Lay.fn.modules = function() {
var clone = {};
for (var o in modules) {
clone[o] = modules[o];
}
return clone;
}();
// 设置模块的相对路径(不含后缀.js)
Lay.fn.extend = function(options) {
var that = this;
options = options || {};
for (var o in options) {
// layui[name],如果存在,则表示模块name已注册。
// layui.modules[name],代表模块name的相对路径(不包括后缀.js),默认值为name。
// 已注册或已设置相对路径的模块集,不允许再设置相对路径。显然,内置模块的相对路径不允许更改。
if (that[o] || that.modules[o]) {
error('\u6A21\u5757\u540D ' + o + ' \u5DF2\u88AB\u5360\u7528');
} else {
that.modules[o] = options[o];
}
}
return that;
};
// 路由
Lay.fn.router = function(hash) {
var hashs = (hash || location.hash).replace(/^#/, '').split('/') || [];
var item,
param = {
dir : []
};
for (var i = 0; i < hashs.length; i++) {
item = hashs[i].split('=');
/^\w+=/.test(hashs[i]) ? function() {
if (item[0] !== 'dir') {
param[item[0]] = item[1];
}
}() : param.dir.push(hashs[i]);
item = null;
}
return param;
};
// 本地存储
Lay.fn.data = function(table, settings) {
table = table || 'layui';
if (!win.JSON || !win.JSON.parse) return;
//如果settings为null,则删除表
if (settings === null) {
return delete localStorage[table];
}
settings = typeof settings === 'object'
? settings
: {
key : settings
};
try {
var data = JSON.parse(localStorage[table]);
} catch (e) {
var data = {};
}
if (settings.value)
data[settings.key] = settings.value;
if (settings.remove)
delete data[settings.key];
localStorage[table] = JSON.stringify(data);
return settings.key ? data[settings.key] : data;
};
// 设备信息
Lay.fn.device = function(key) {
var agent = navigator.userAgent.toLowerCase();
//获取版本号
var getVersion = function(label) {
var exp = new RegExp(label + '/([^\\s\\_\\-]+)');
label = (agent.match(exp) || [])[1];
return label || false;
};
var result = {
os : function() { //底层操作系统
if (/windows/.test(agent)) {
return 'windows';
} else if (/linux/.test(agent)) {
return 'linux';
} else if (/iphone|ipod|ipad|ios/.test(agent)) {
return 'ios';
}
}(),
ie : function() { //ie版本
return (!!win.ActiveXObject || "ActiveXObject" in win) ? (
(agent.match(/msie\s(\d+)/) || [])[1] || '11' //由于ie11并没有msie的标识
) : false;
}(),
weixin : getVersion('micromessenger') //是否微信
};
//任意的key
if (key && !result[key]) {
result[key] = getVersion(key);
}
//移动设备
result.android = /android/.test(agent);
result.ios = result.os === 'ios';
return result;
};
// 提示
Lay.fn.hint = function() {
return {
error : error
}
};
// 遍历
Lay.fn.each = function(obj, fn) {
var that = this,
key;
if (typeof fn !== 'function') return that;
obj = obj || [];
if (obj.constructor === Object) {
for (key in obj) {
if (fn.call(obj[key], key, obj[key])) break;
}
} else {
for (key = 0; key < obj.length; key++) {
if (fn.call(obj[key], key, obj[key])) break;
}
}
return that;
};
// 阻止事件冒泡
Lay.fn.stope = function(e) {
e = e || win.event;
e.stopPropagation ? e.stopPropagation() : e.cancelBubble = true;
};
// 自定义模块事件
Lay.fn.onevent = function(modName, events, callback) {
if (typeof modName !== 'string'
|| typeof callback !== 'function') return this;
config.event[modName + '.' + events] = [ callback ];
//不再对多次事件监听做支持
/*
config.event[modName + '.' + events]
? config.event[modName + '.' + events].push(callback)
: config.event[modName + '.' + events] = [callback];
*/
return this;
};
// 执行自定义模块事件
Lay.fn.event = function(modName, events, params) {
var that = this,
result = null,
filter = events.match(/\(.*\)$/) || []; //提取事件过滤器
var set = (events = modName + '.' + events).replace(filter, ''); //获取事件本体名
var callback = function(_, item) {
var res = item && item.call(that, params);
res === false && result === null && (result = false);
};
layui.each(config.event[set], callback);
filter[0] && layui.each(config.event[events], callback); //执行过滤器中的事件
return result;
};
win.layui = new Lay();
}(window);