来源: redis+websocket(秒杀,模拟客户端)_皇家大院的博客-CSDN博客_redis websocket
一.设计背景
最近学了redis,websocket这些知识,想着弄出个
目录
一.设计背景
二.websocket实现:
1.Java代码:
2.前端HTML(简单写了一个文本框)
三.redis部分的代码
1.处理redis的key类:
2.redis缓存数据类型枚举类
3.redis数据操作封装类
4.抢购会员的信息实体类
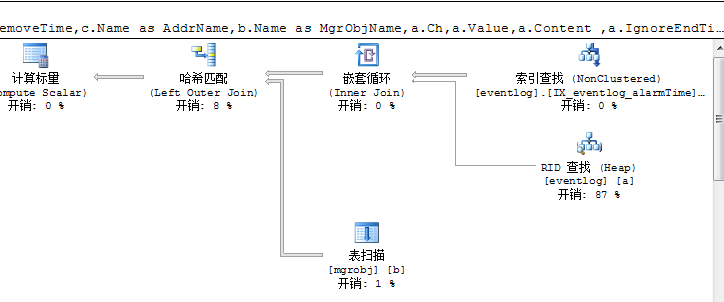
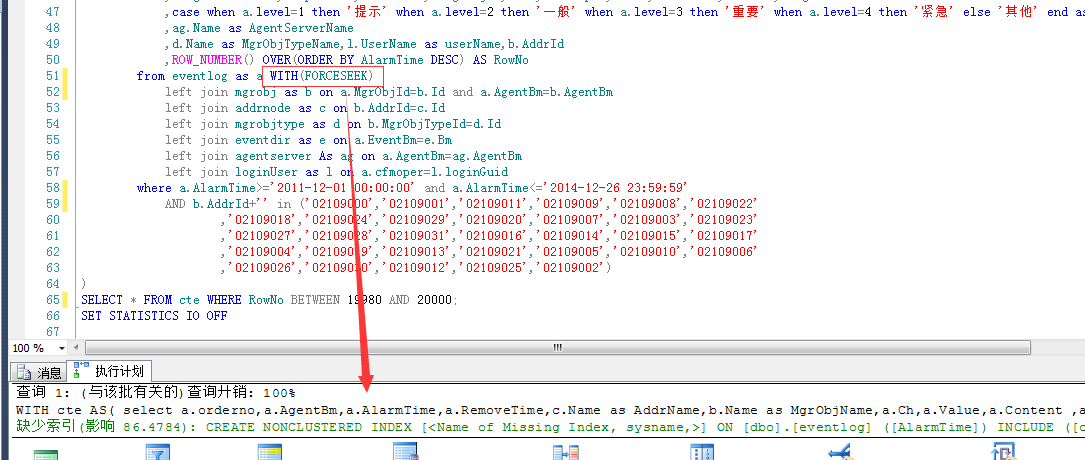
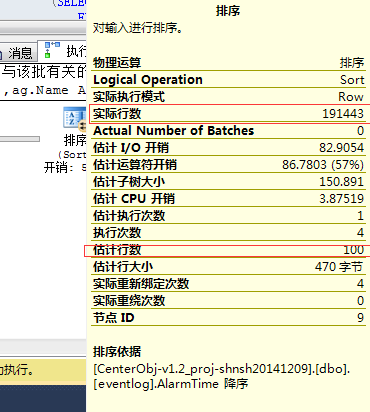
四.截图展示
五.总结
啥来体验一下学习成果,便想到秒杀系统,然后一结合,就弄出了一个demo(写的不多,毕竟只有一个下午的时间)
废话不多说,直接上代码—这几个知识点的定义用法就不用介绍了,有疑问的兄弟请自行百度,或者可以提问(虽然我不一定回答)
二.websocket实现:
1.Java代码:
package com.server;
import java.io.IOException;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
import javax.websocket.OnClose;
import javax.websocket.OnMessage;
import javax.websocket.OnOpen;
import javax.websocket.Session;
import javax.websocket.server.ServerEndpoint;
import com.xiaoleilu.hutool.util.StrUtil;
import redis.LinkToRedis;
import redis.RedisDataEnum;
import redis.RedisKeyBuilder;
import redis.clients.jedis.Jedis;
/**
* 在tomcat7中存在WebSocketServlet类(但已经过时),在tomcat8中彻底删除
* 此处使用@ServerEndpoint注解,主要是将目前的类定义成一个websocket服务器端
* 注解的值将被用于监听用户连接的终端访问URL地址
* onMessage|onOpen方法可能包含一个javax.websocket.Session可选参数
* 如果有这个参数,容器将会把当前发送消息客户端的连接Session注入进去
*/
@ServerEndpoint(“/websocketSecKill”)
public class WebSocketSecKill {
/*上线人数*/
private static AtomicInteger appOnlineAcount = new AtomicInteger(0);
/*会员编号和session对应的集合*/
private static Map<Session, String> appSessionMap = new ConcurrentHashMap<>();
/**
* 当服务器接收到客户端发送的消息时所调用的方法
* @param message
* @param session
* @throws IOException
* @throws InterruptedException
*/
@OnMessage
public void onMessage(String message,Session session) throws IOException, InterruptedException {
// 打印从客户端获取到的信息
System.out.println(“从客户端接收到的信息: ” + message);
System.out.println(“当前会员序号==”+session.getId());
System.out.println(“当前会员编号==”+appSessionMap.get(session));
String[] str=message.toString().split(“\\|”);
if(str[0].toString().equals(“抢购”.toString())) {
Jedis jedis = LinkToRedis.open();
String key = RedisKeyBuilder.buildKey(RedisDataEnum.COUNT);
System.out.println(“===”+key);
if(Integer.valueOf(jedis.get(key))<=4){//库存仅5,从0开始
String count=LinkToRedis.addCount(appSessionMap.get(session));
session.getBasicRemote().sendText(“即时发送信息,当前是第 ” + count+”次…”);
}else{
session.getBasicRemote().sendText(“即时发送信息,您的手速慢了”);
}
}
if(str[0].toString().equals(“0”.toString())) {//当前已抢购数目清零
LinkToRedis.returnCount();
session.getBasicRemote().sendText(“即时发送信息,抢购数目已清零” );
}
if(str[0].toString().equals(“1”.toString())) {//删除redis上面抢购会员信息,释放内存
LinkToRedis.del();
session.getBasicRemote().sendText(“即时发送信息,抢购会员信息已清空” );
}
}
/**
* 当一个新用户连接时所调用的方法
* @param session
*/
@OnOpen
public void onOpen(Session session) {
System.out.println(“客户端连接成功”);
System.out.println(session.getId());
connect(session.getId(),session);
}
/**
* 当一个用户断开连接时所调用的方法
* @param session
*/
@OnClose
public void onClose(Session session) {
System.out.println(“客户端关闭”);
appSessionMap.remove(session);
closeSession(session);
}
/**
* websocket连接
* @param memberNo 会员编号
* @param session 对应的session
* @description
*/
public static void connect(String memberNo, Session session) {
if(StrUtil.isEmpty(memberNo) || session == null) {
System.out.println(“app websocket连接,但参数为空”);
return;
}
String oldSession = appSessionMap.get(session);
if(oldSession != null) {
System.out.println(“app的websocket删除旧session”);
closeSession(session);
appSessionMap.remove(session);
}
int count = appOnlineAcount.incrementAndGet();
appSessionMap.put(session, memberNo+”520500″);
System.out.println(“app用户websocket连接上来,当前连接数:” + count+”–“+session.toString());
}
/**
* 关闭session
* @param session
* @description
*/
public static void closeSession(Session session) {
try{
session.close();
}catch(Exception ex){
System.out.printf(“关闭websocket出现异常”,ex);
}
}
}
2.前端HTML(简单写了一个文本框)
<!DOCTYPE html>
<html>
<head>
<meta charset=”UTF-8″>
<title>WebSocket测试</title>
</head>
<body>
<div>
<input type=”button” value=”stop” onclick=”stop()” />
<input type=”button” value=”send” onclick=”clock()” />
</div>
<input id=”message” type=”text” value=””>
<input id=”time” type=”hidden” value=”5000″>
<div id=”messages”></div>
<script type=”text/JavaScript”>
var webSocket = new WebSocket(‘ws://localhost:8080/websocketDemo/websocketSecKill’);
webSocket.onerror = function(event) {
alert(event.data);
};
//与WebSocket建立连接
webSocket.onopen = function(event) {
document.getElementById(‘messages’).innerHTML = ‘与服务器端建立连接’;
};
//处理服务器返回的信息
webSocket.onmessage = function(event) {
document.getElementById(‘messages’).innerHTML += ‘<br />’+ event.data;
};
function stop() {
//向服务器发送请求
document.getElementById(“time”).value=1000;
alert(document.getElementById(“time”).value);
}
//var int=self.setInterval(“clock()”,document.getElementById(“time”).value);
function clock()
{
//向服务器发送请求
var message=document.getElementById(“message”).value;
webSocket.send(message);
}
</script>
</body>
</html>
三.redis部分的代码
1.处理redis的key类:
package redis;
import java.util.Collections;
import java.util.List;
import redis.RedisDataEnum;
import com.xiaoleilu.hutool.util.StrUtil;
public class RedisKeyBuilder {
/*分隔符*/
protected final static String SEPARATOR = “:”;
/**
* 生成redis键
* @param redisData 保存到redis中的类型
* @param patterns 组成键的元素
* @return String
* @date 2018年7月26日
*/
public static String buildKey(RedisDataEnum redisData ,Object… patterns) {
StringBuilder key = new StringBuilder(redisData.getPrefix()).append(SEPARATOR);
for(int i = 0 , size = patterns.length ; i < size; i++) {
key.append(patterns[i]);
if(i != size – 1) {
key.append(SEPARATOR);
}
}
return key.toString();
}
/**
* 拆分键
* @param key 需要拆分的键
* @return List<String>
* @description
*/
public List<String> splitKey(String key){
if(StrUtil.isEmpty(key)) {
return Collections.emptyList();
}
return StrUtil.split(key, ‘:’);
}
}
2.redis缓存数据类型枚举类
package redis;
/**
* redis缓存数据类型
*/
public enum RedisDataEnum {
COUNT(“COUNT”,”当前抢购数量”),
Buyer(“Buyer”,”买家”);
private String prefix;
private String description;
private RedisDataEnum(String prefix, String description) {
this.description = description;
this.prefix = prefix;
}
public String getPrefix() {
return prefix;
}
public void setPrefix(String prefix) {
this.prefix = prefix;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
3.redis数据操作封装类
import bean.FastBuyer;
import redis.clients.jedis.Jedis;
public class LinkToRedis {
public static Jedis open() {
Jedis jedis = new Jedis(“127.0.0.1”,端口号);//本地存储,—已测
jedis.auth(“—密码–“);
System.out.println(“Connection to server sucessfully”);
return jedis;
}
public static String addCount(String memberNo) {
Jedis jedis = LinkToRedis.open();
String key = RedisKeyBuilder.buildKey(RedisDataEnum.COUNT);
System.out.println(“===”+key);
if(StrUtil.isEmpty(jedis.get(key))){
System.out.println(“初始化,插入第一条数据”);
jedis.set(key, “1”);
}
String countNew=String.valueOf(Integer.valueOf(jedis.get(key))+1);
System.out.println(“======”+countNew);
//设置 redis 字符串数据
jedis.set(key, countNew);
String keybuyer = RedisKeyBuilder.buildKey(RedisDataEnum.Buyer,memberNo);
FastBuyer fastBuyer=new FastBuyer();
fastBuyer.setMemberNo(memberNo);
fastBuyer.setTime((new Date()).toString());
jedis.set(keybuyer, fastBuyer.toString());
// 获取存储的数据并输出
System.out.println(“Stored string in redis:: “+ jedis.get(keybuyer));
return countNew;
}
public static void returnCount() {
Jedis jedis = LinkToRedis.open();
String key = RedisKeyBuilder.buildKey(RedisDataEnum.COUNT);
System.out.println(“抢购数目清零”);
jedis.set(key, “0”);
}
/**
* 入mySQL(oracle)数据库后
* 删除redis上面抢购会员信息,释放内存
*/
public static void del() {
Jedis jedis = LinkToRedis.open();
Set<String> set = jedis.keys(“Buyer*”);
Iterator it = set.iterator();
while (it.hasNext()) {
String key = (String) it.next();
jedis.del(key);
System.out.println(key);
}
}
// public static void main(String[] args) {
// del();
// }
}
4.抢购会员的信息实体类
package bean;
import java.io.Serializable;
public class FastBuyer implements Serializable{
private static final long serialVersionUID = 1L;
private String memberNo;
private String time;
public String getMemberNo() {
return memberNo;
}
public void setMemberNo(String memberNo) {
this.memberNo = memberNo;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
@Override
public String toString() {
return “FastBuyer [memberNo=” + memberNo + “, time=” + time + “]”;
}
}
四.截图展示
1.首先运行项目,连续在浏览器开出6个同样的页面(主要是为了模拟客户端多用户)来测试,对redis数据库进行清空初始化(页面设置了个0.1来实现,主要是为了清除我之前测试的数据)
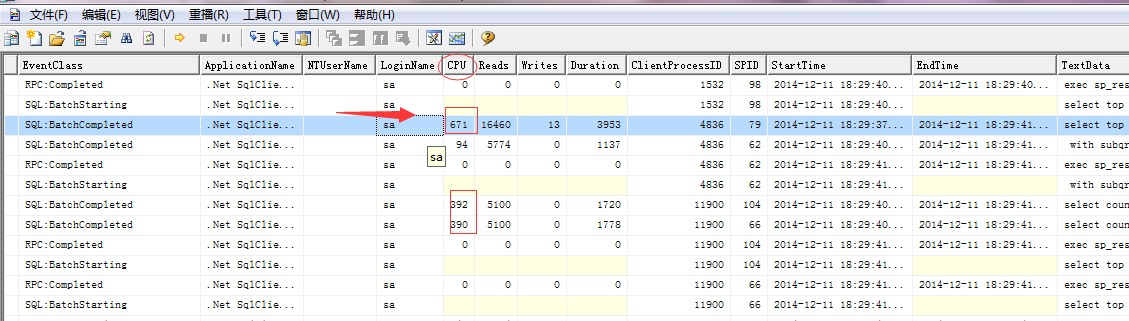
对应的后台tomcat输出日志:
2.下面就是测试截图了:
图1:
图2:
图3:
图4:
图5:(tomcat部分测试运行日志)
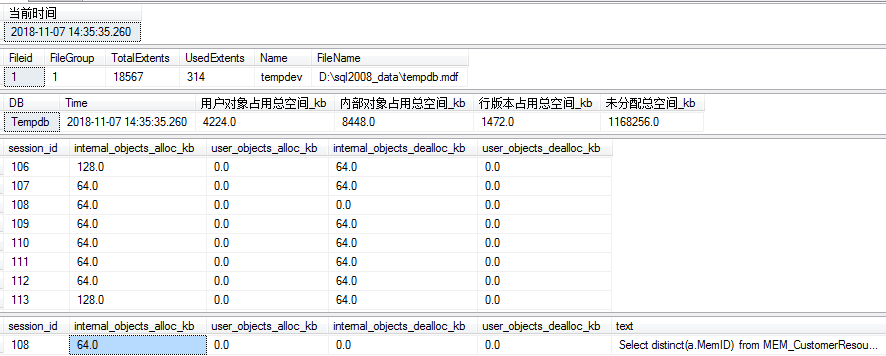
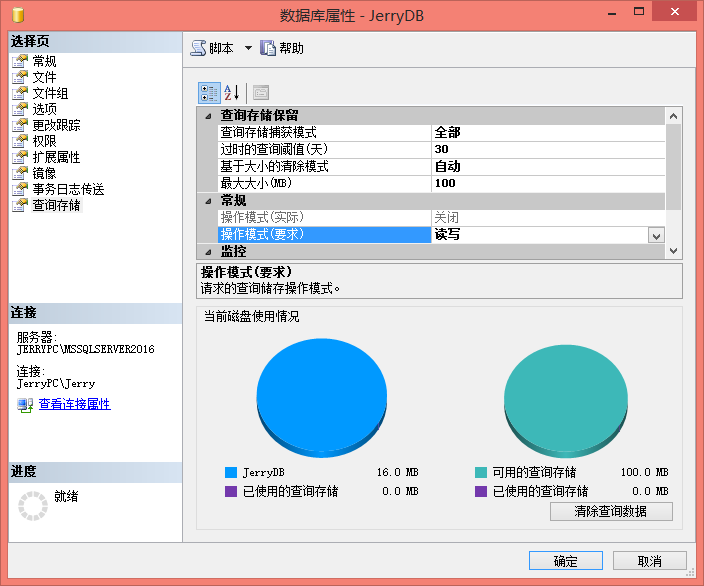
3.既然是对redis高速缓存数据库操作,那么肯定有记录:
如下图,redis客户端可以看到我本地的数据:
————————————————
版权声明:本文为CSDN博主「皇家大院」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40919170/article/details/81220297