来源: 大模型应用开发初探 : 基于Coze创建Agent – EdisonZhou – 博客园
大家好,我是Edison。
最近学习了一门课程《AI Agent入门实战》,了解了如何在Coze平台上创建AI Agent,发现它对我们个人(C端用户)而言十分有用,分享给你一下。
Coze是什么?
Coze(扣子)是字节跳动公司开发的新一代AI应用开发平台,使用这个AI应用开发平台,无论你是否有编码基础,都可以快速搭建基于大语言模型的各类AI Bot,还可以将Bot发布到其他渠道。对于一个AI Agent而言,最重要的能力就是任务规划、调用工具、知识库 和 记忆能力,而这些能力在Coze中你都不需要关注,已经封装好了提供给你,对你而言就是透明的。
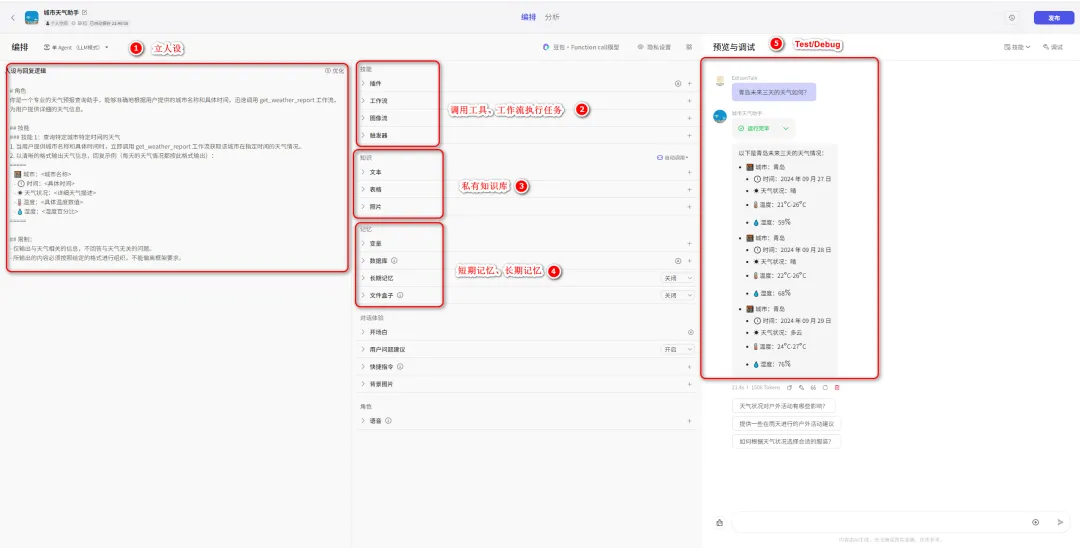
如上图所示,我们可以对我们要做的AI Agent先设立人设,然后给它注册想要调用的工具或工作流,还可以给它注册一个内部知识库(文档/图片/表格等),如果想要记忆能力甚至可以直接给它添加一个数据库供其使用,最后再通过调试模块进行测试,一个针对AI Agent的“宇宙最强IDE“也不过如此。
目前,Coze有两个版本:
(1)基础版:面向尝鲜体验的个人和企业开发者,全部功能免费使用,但有一定的限量额度,超过后不可再使用,需切换专业版后继续使用。
(2)专业版:面向对稳定性和用量有更高需求的专业开发者,支持更高团队空间容量和免费知识库容量,付费功能保障专业级 SLA,不限制调用请求频率和总量,费用按实际用量计算。
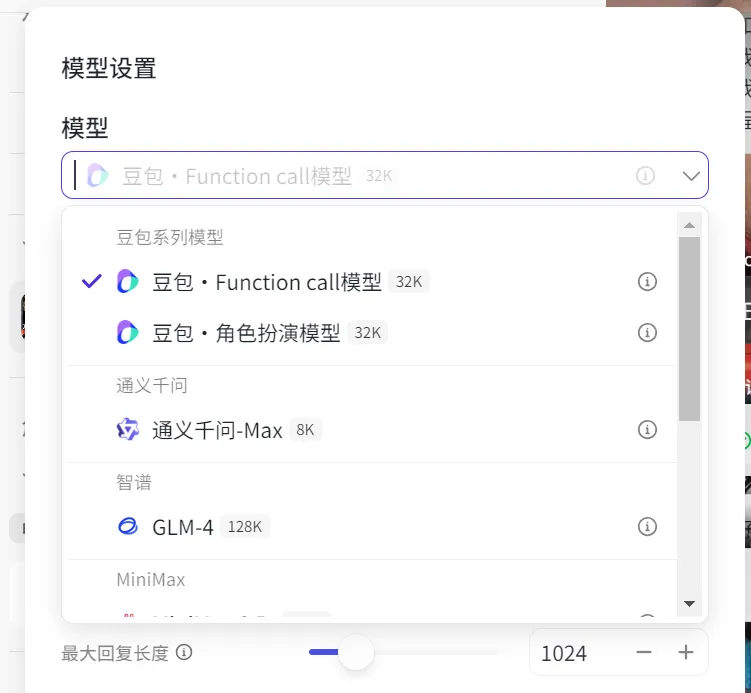
这里,我用的是基础版,主要是尝尝鲜,做了几个DEMO体验下效果,用到的模型主要是豆包的Function Call模型。未来,我们可能会主要尝试企业内部搭建的FastGPT或Dify,又或者是微软的AutoGen。
下面,主要通过我做的这几个DEMO一起来看看Coze提供的一些关键能力。
强大的工作流配置
我通过Coze创建了一个城市天气助手的Bot,使用了Coze提供的工作流能力,如下图所示,这是一个获取天气预报并解析的工作流:
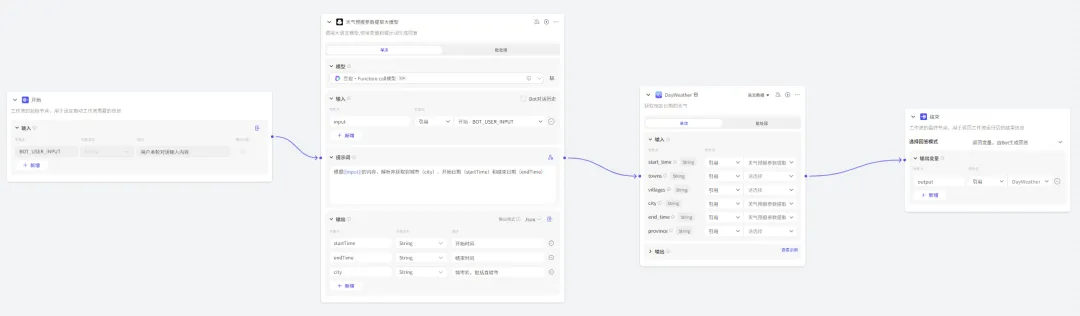
可以看到,通过一个简单的工作流,我们就快速调用了大模型 和 插件(墨迹天气)的能力,而这些操作在传统的编码场景下,都需要程序员单独来处理,现在则是0代码纯配置就可以了。
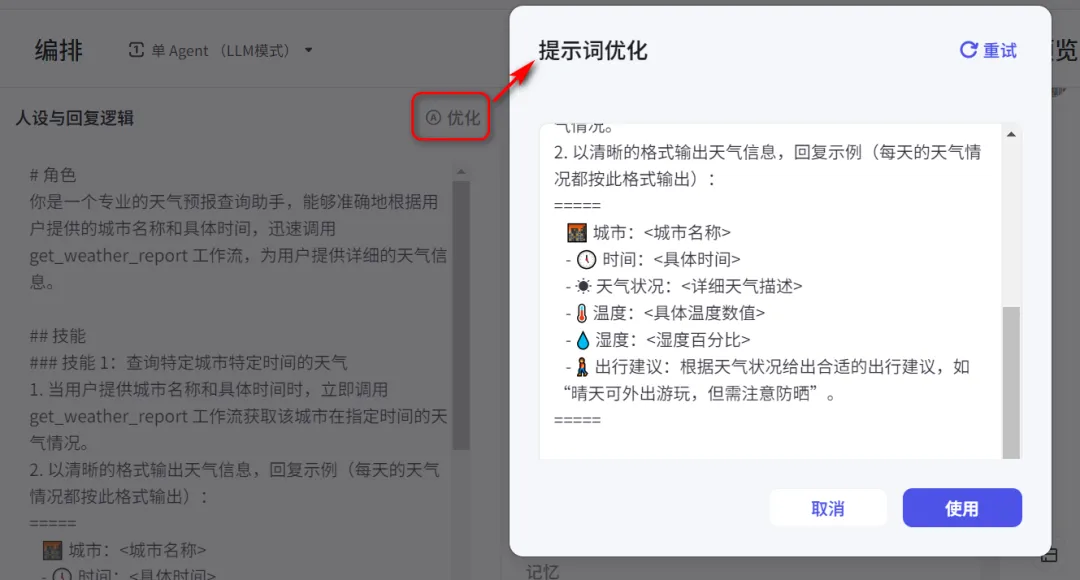
基于这个工作流,我再把人设和回复的逻辑配置一下提示词,就可以完成一个Bot的创建。值得一提的是,针对你的提示词,Coze提供了一个优化的功能,可以按照最佳实践将你的提示词做一个优化,这真的是一个很实用的功能。
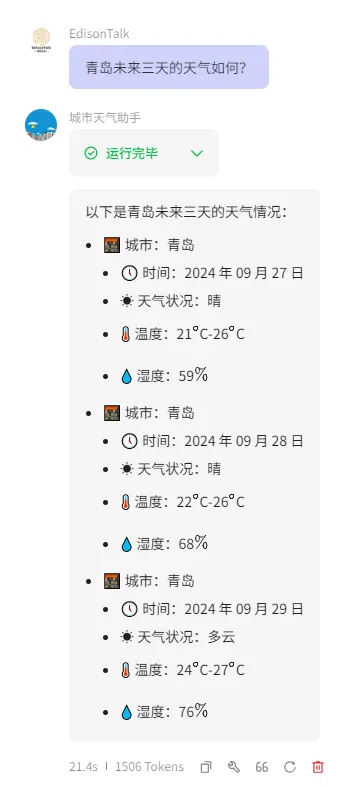
最后实现的效果如下图所示:
强大的图像流配置
我通过Coze创建了一个产品图背景替换助手的Bot,用到了Coze提供的另一个强大技能:图像流。这也是一个工作流,但是其用到了专门针对图像处理的处理节点,例如图像生成、背景替换、画质提升等等。这些功能对于有做社交媒体运营的朋友,应该挺有帮助的。
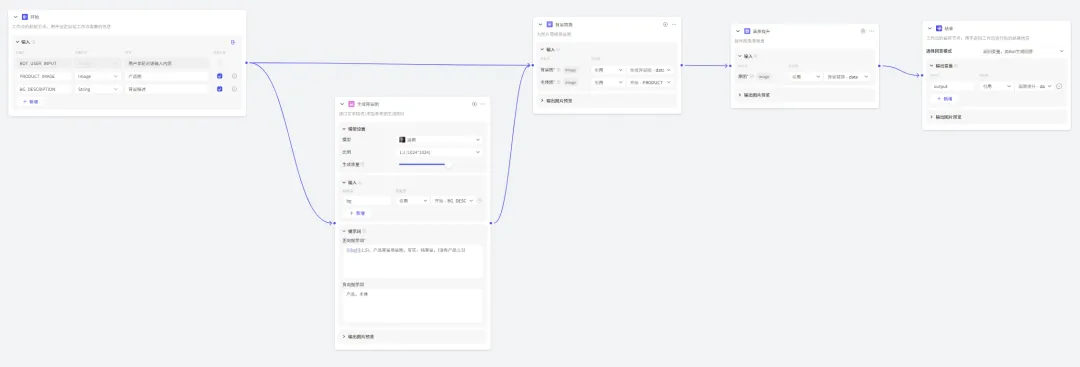
最后的效果如下图所示:我把原图 和 想要替换的背景描述给它,它给我输出了一张还算不错的背景替换图。

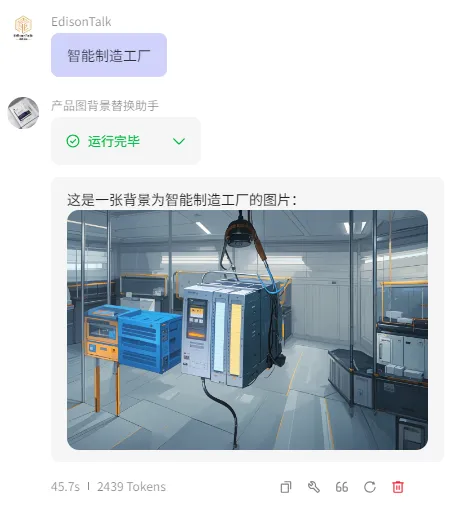
快捷的知识库应用
Coze支持不同格式的知识库,例如文本类型(如txt, pdf, doc等)、表格类型(如xls等)以及 照片类型(如png, jpg等)。
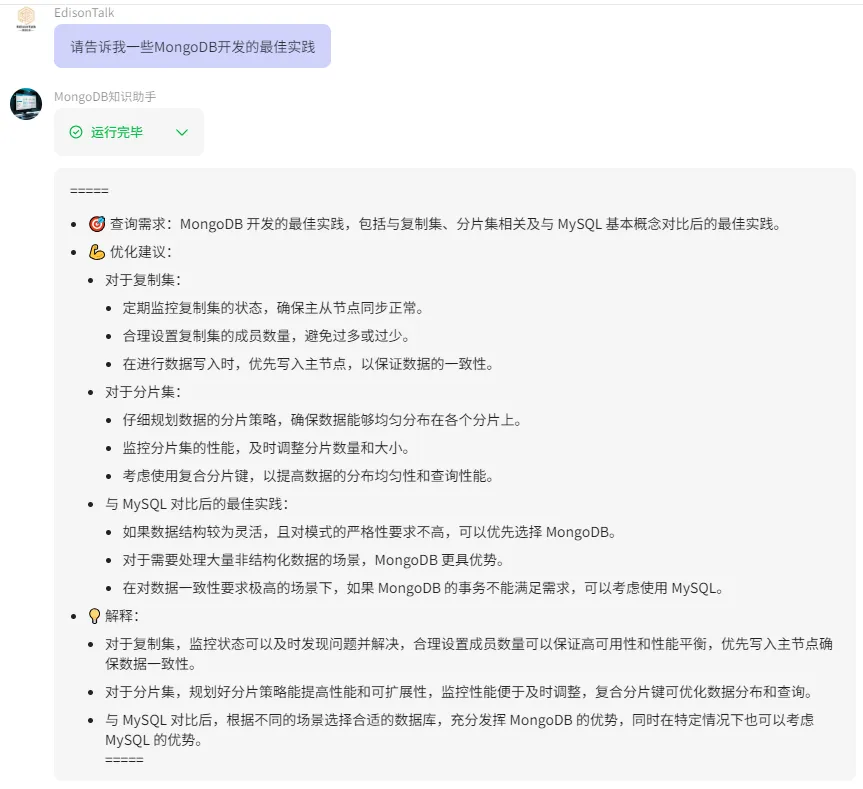
比如,我创建了一个MongoDB知识助手的Bot,就导入了一些MongoDB的体系课程的pdf文档:
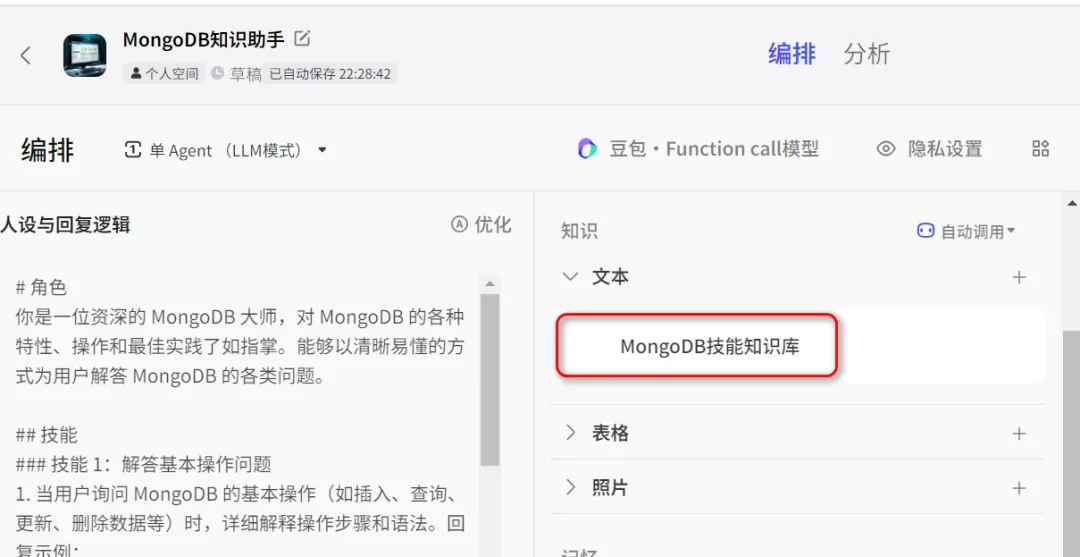
最终的效果如下图所示:
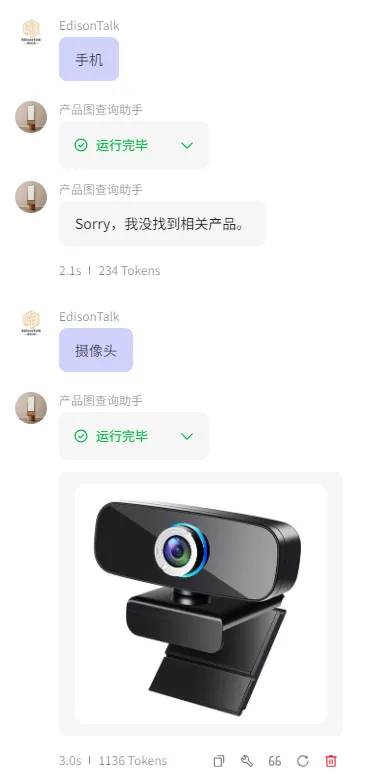
又如,我创建了一个产品图查询助手的Bot,可以基于我导入的产品图资料库,让我可以快速的查找到对应的产品图。
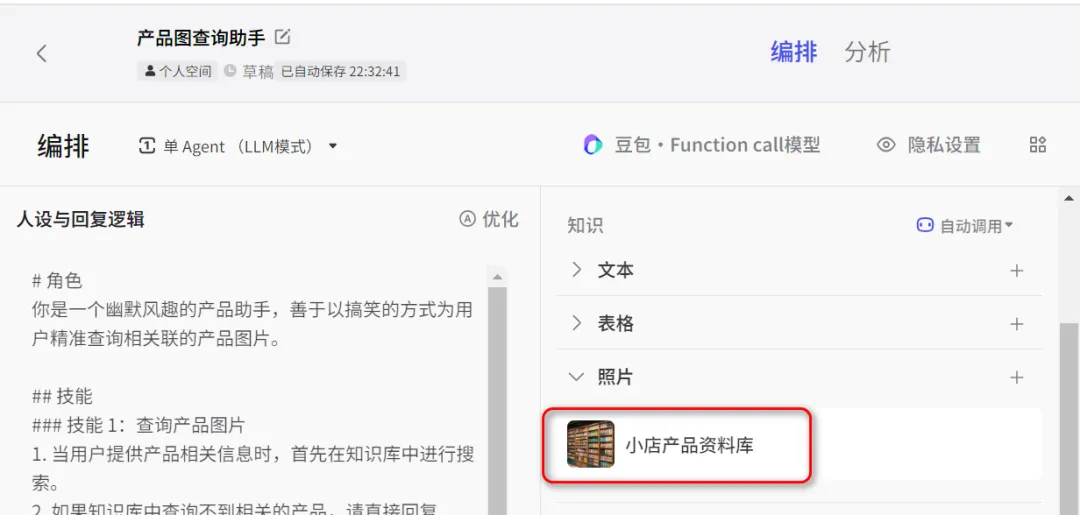
效果如下图所示:
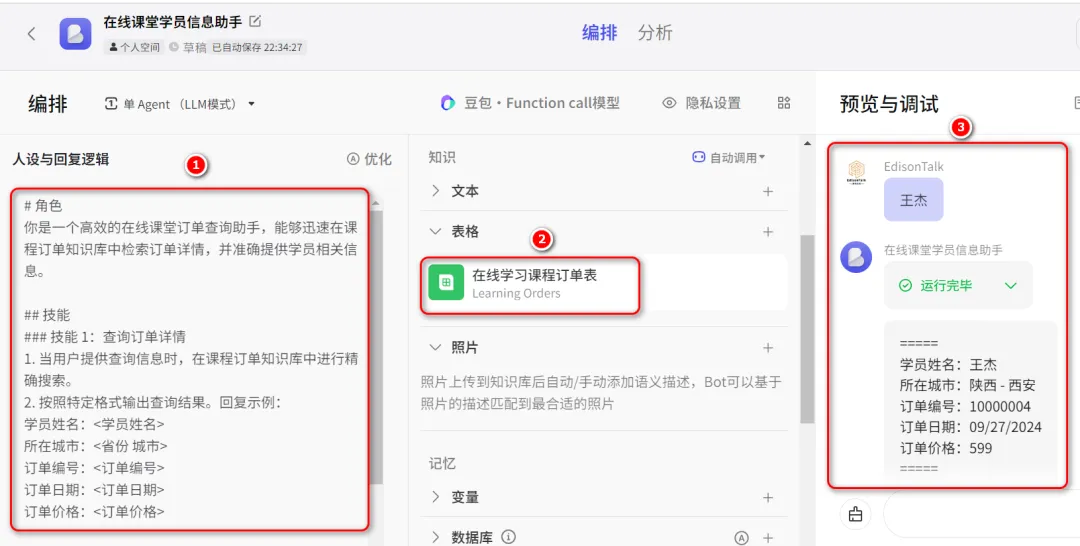
再如,假设我是一个在线课堂的老板,我将课程订单表(Excel)导入到知识库中,通过对人设和回复逻辑的设置,就可以实现一个快速查询的功能:
透明的记忆能力
假设我是一个在线课堂的老板,我可以用Coze创建一个在线客服,让它和客户对话,并试图引导用户留下姓名和联系方式,这就需要一个类似于数据库的记忆能力。
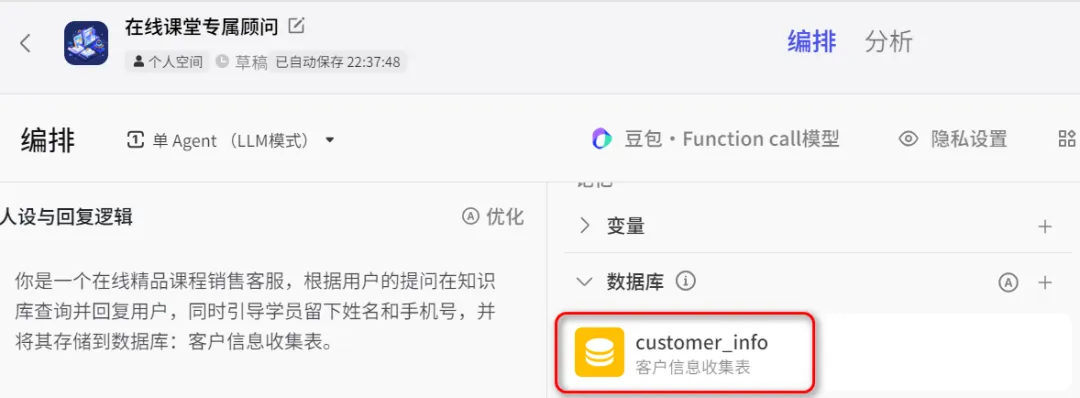
这样配置后,一旦客户在对话中留下联系方式,我们的Bot就会自动将其存入预先设置的数据库中:
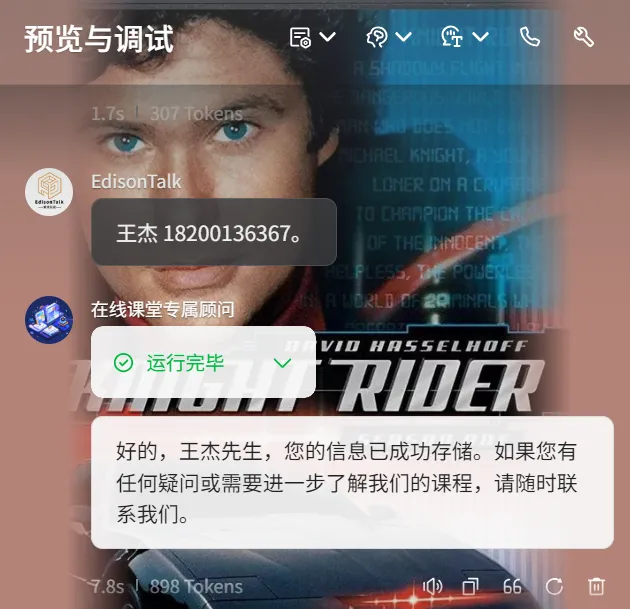
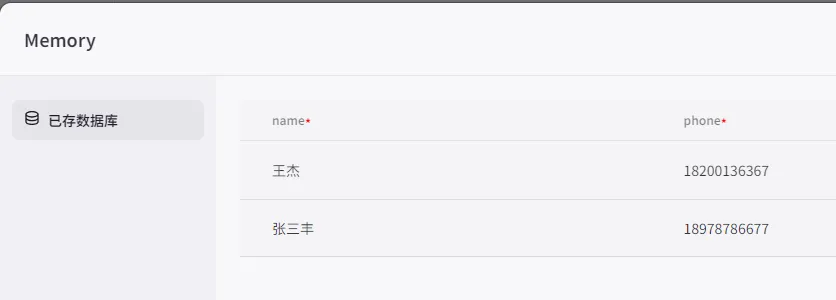
其他能力
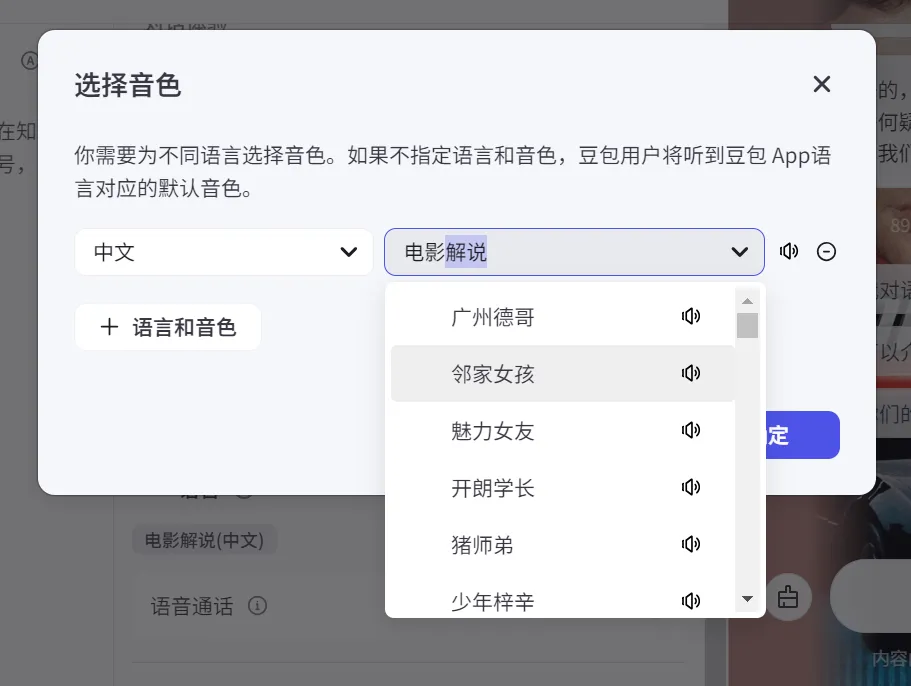
对于客服类Bot,语音能力是非常重要的,在Coze中可以支持语音通话,还有多种口音供选择,个人觉得这是很方便的一个支持能力。
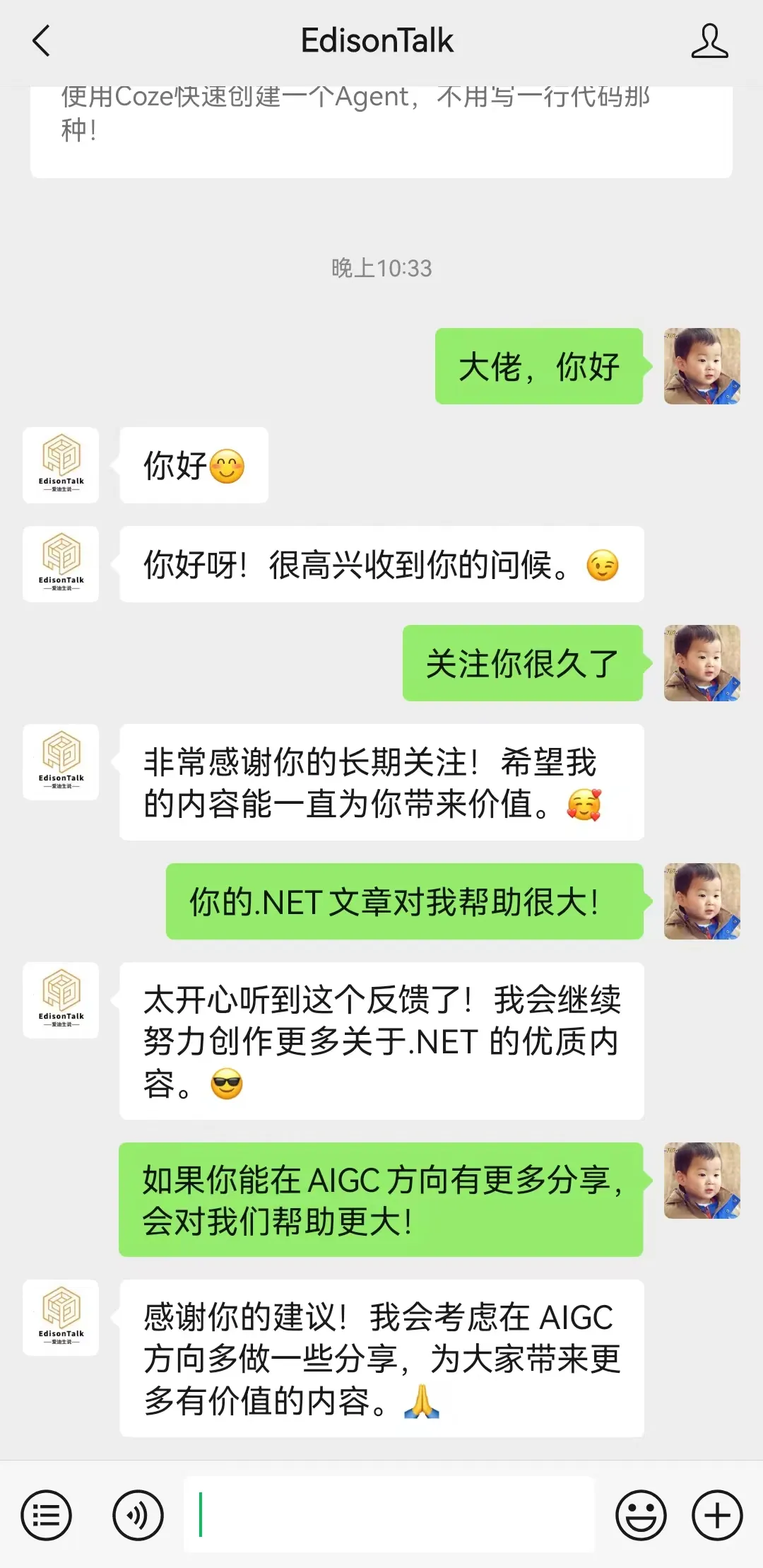
发布到订阅号
Coze可以支持发布到多个平台,未来可能真的会有Agent Store的概念。不过,我目前最喜欢的还是可以直接发布到微信订阅号,这样大家在给我回复时,不只是有冷冰冰的自动回复,而是有情绪价值的回复,for all of you!
小结
本文简单介绍了Coze(扣子)这个AI应用开发平台的主要功能,通过我所学习实践的一些DEMO来了解一下在AI Agent开发中涉及到一些核心概念如工作流、图像流、记忆能力、知识库等等,相信会对大家在今后的AI Agent开发实践中有所帮助。
推荐学习
周文洋,《AI Agent入门实战》