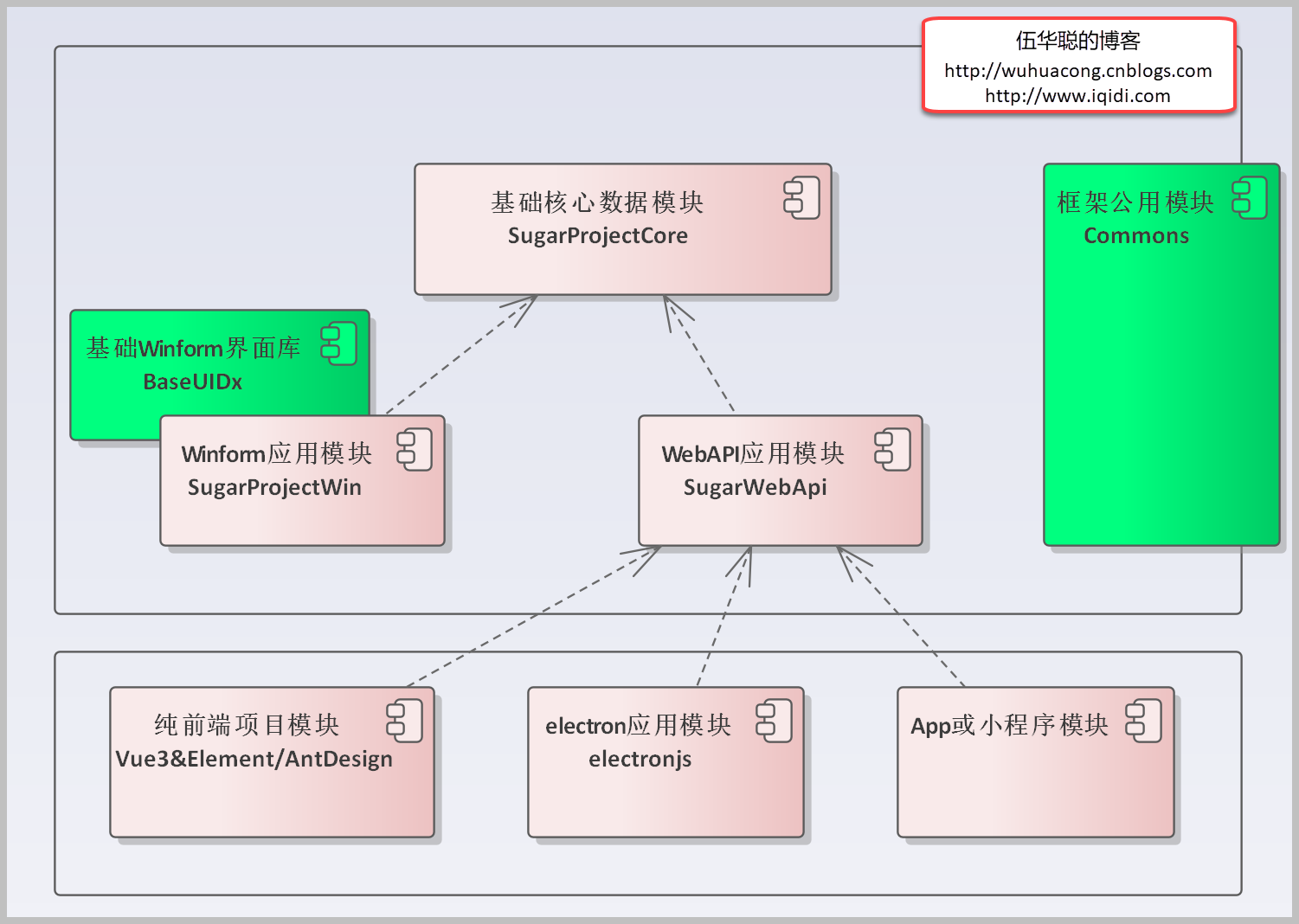
来源: 为什么数据库有时候不能定位阻塞(Blocker)源头的SQL语句 – 潇湘隐者 – 博客园
在SQL Server数据库或OACLE数据库当中,通常一个会话持有某个资源的锁,而另一个会话在请求这个资源,就会出现阻塞(blocking)。这是DBA经常会遇到的情况。当出现SQL语句的阻塞时,很多人想查看阻塞的源头(哪个SQL语句阻塞了哪个SQL),这样方便直观、简洁明了的定位问题。但是很多时候,很多场景,我们通过SQL语句并不能或者说不容易定位到阻塞者(Blocker)的SQL语句,当然我们可以很容易找到被阻塞的SQL语句,以及它在等待的锁资源。下面我们先分析一下SQL Server数据库的这类场景,然后分析一下ORACLE数据库的这类场景。如有不足的地方,敬请指出。
在SQL Server当中,我们先准备下面测试环境(测试用的表和数据)。
USE Test;
GO
CREATE TABLE Test
(
ID INT ,
NAME VARCHAR(12)
);
INSERT INTO Test
VALUES (1000, 'Kerry');
INSERT INTO Test
VALUES(1001, 'Jimmy');
场景1:我们构造这样一个简单的场景,例如如下:
在会话81中执行下面SQL语句
BEGIN TRAN
UPDATE Test SET NAME='Tina' WHERE ID=1000;
在会话72中执行下面SQL语句
SELECT * FROM TEST;
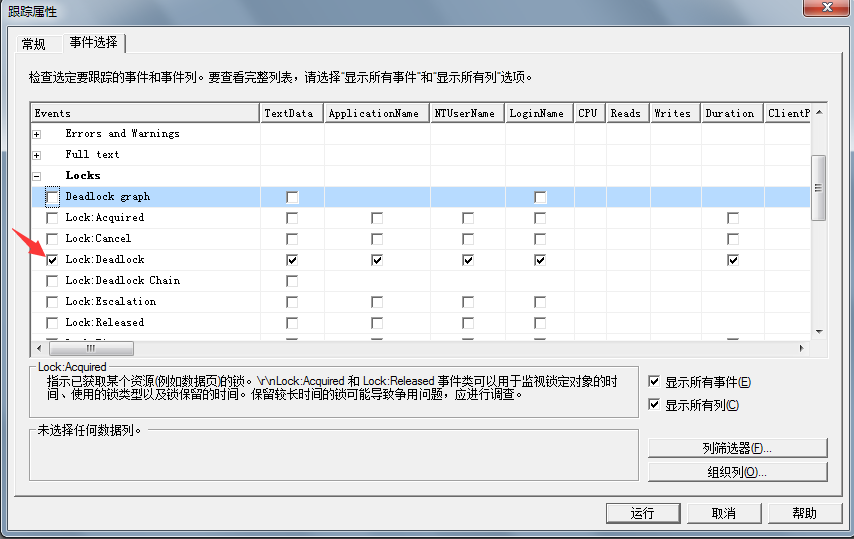
在另外一个会话窗口执行下面语句,查看阻塞(blocker)者和被阻塞者的SQL语句(这里能够定位到阻塞者(blocker)的SQL语句)。如下所示
SELECT wt.blocking_session_id AS BlockingSessesionId
,sp.program_name AS Blocking_ProgramName
,COALESCE(sp.LOGINAME, sp.nt_username) AS Blocking_HostName
,ec1.client_net_address AS ClientIpAddress
,db.name AS DatabaseName
,wt.wait_type AS WaitType
,ec1.connect_time AS BlockingStartTime
,wt.WAIT_DURATION_MS/1000 AS WaitDuration
,ec1.session_id AS BlockedSessionId
,h1.TEXT AS BlockedSQLText
,h2.TEXT AS BlockingSQLText
FROM sys.dm_tran_locks AS tl WITH(NOLOCK)
INNER JOIN sys.databases AS db WITH(NOLOCK)
ON db.database_id = tl.resource_database_id
INNER JOIN sys.dm_os_waiting_tasks AS wt WITH(NOLOCK)
ON tl.lock_owner_address = wt.resource_address
INNER JOIN sys.dm_exec_connections ec1 WITH(NOLOCK)
ON ec1.session_id = tl.request_session_id
INNER JOIN sys.dm_exec_connections ec2 WITH(NOLOCK)
ON ec2.session_id = wt.blocking_session_id
LEFT OUTER JOIN master.dbo.sysprocesses AS sp WITH(NOLOCK)
ON SP.spid = wt.blocking_session_id
CROSS APPLY sys.dm_exec_sql_text(ec1.most_recent_sql_handle) AS h1
CROSS APPLY sys.dm_exec_sql_text(ec2.most_recent_sql_handle) AS h2

但是这个场景是一个非常理想化的场景,实际场景中,可能会话81接下来会去执行其它SQL语句,它并不会一直停留在这个SQL语句上,例如,我们在会话81中执行SELECT GETDATE();这个SQL语句
BEGIN TRAN
UPDATE Test SET NAME='Tina' WHERE ID=1000;
SELECT GETDATE();

如上所示,此时查到的Blocker者的SQL语句为”SELECT GETDATE();”, 而这个SQL其实和被阻塞的SQL没有半毛关系。即使使用sp_WhoIsActive这样专业的SQL亦是如此。

当然我们可以查看其等待的锁对象信息,这也是我们所能追踪、捕获的。如下所示:
<Database name="Test">
<Locks>
<Lock request_mode="S" request_status="GRANT" request_count="1" />
</Locks>
<Objects>
<Object name="Test" schema_name="dbo">
<Locks>
<Lock resource_type="OBJECT" request_mode="IS" request_status="GRANT" request_count="1" />
<Lock resource_type="PAGE" page_type="*" request_mode="IS" request_status="GRANT" request_count="1" />
<Lock resource_type="RID" page_type="*" request_mode="S" request_status="WAIT" request_count="1" />
</Locks>
</Object>
</Objects>
</Database>

这种场景,如果只是某个会话发出的即席查询,那么你几乎已经很难捕获到阻塞的源头UPDATE Test SET NAME=’Tina’ WHERE ID=1000这个SQL语句了。除非你结合其它一些手段,逆向推断。
场景2:上面查找SQL阻塞的SQL语句,有时候只能定位到某一个存储过程或一大段即席查询SQL。
例如,下面一个构造的存储过程,一个用户正在一个会话当中执行它,
CREATE PROCEDURE PRC_TEST
AS
BEGIN
BEGIN TRAN TR1
UPDATE Test SET NAME='YourName' WHERE ID=1000;
SELECT * FROM sys.sysprocesses WHERE spid=@@SPID;
WAITFOR DELAY '00:00:20';
COMMIT TRAN TR1;
END
GO
另外一个用户在另外一个会话执行下面查询SQL语句
SELECT * FROM TEST;
查看阻塞的历史记录

你会看到捕获的是整个存储过程,当然这个测试案例很容易知道是那个SQL语句阻塞了,实际的存储过程可能业务很复杂,SQL语句也非常多,你想从一个存储过程里面找到阻塞者(Blocker)的SQL语句其实是非常麻烦的。需要你仔细甄别,当存储过程的业务逻辑复杂,SQL语句非常多时,这是一个头痛的事情。
其实遇到这些场景,我们大可不必一定要查看阻塞这(Blocker)的具体SQL,我们只需要查看被阻塞者,等待的锁对象资源的相关信息即可,你可以大致判断到底是一个什么类型的SQL导致了这类阻塞。
那么我们接下来看看ORACLE数据库场景吧。我们先准备一个测试环境(测试表和相关数据)
CREATE TABLE "TEST"."TEST"
( "ID" NUMBER,
"NAME" VARCHAR2(12)
);
INSERT INTO TEST
SELECT 1001, 'jimmy' FROM DUAL UNION ALL
SELECT 1002, 'Kerry' FROM DUAL;
COMMIT;
接下来我们在会话窗口一执行下面SQL:
[oracle@DB-Server ~]$ sqlplus test/test
SQL*Plus: Release 11.2.0.1.0 Production on Tue Aug 30 10:16:43 2016
Copyright (c) 1982, 2009, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> show user;
USER is "TEST"
SQL> UPDATE TEST SET NAME='KKK' WHERE ID =1001;
1 row updated.
SQL>
在另外一个会话窗口二执行下面SQL
[oracle@DB-Server ~]$ sqlplus test/test
SQL*Plus: Release 11.2.0.1.0 Production on Tue Aug 30 10:17:22 2016
Copyright (c) 1982, 2009, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> show user;
USER is "TEST"
SQL> UPDATE TEST SET NAME='Ken' WHERE ID =1001;
然后我们在第三个窗口执行下面SQL语句,查看阻塞和被阻塞的SQL语句
SELECT dba_objects.object_name,
locks_t.row#,
locks_t.blocked_secs,
locks_t.blocker_text,
locks_t.blocked_text,
locks_t.blocked_sql_text,
locks_t.blocking_sql_text
FROM (SELECT /*+ NO_MERGE */
blocking_lock_session.username||'@'||blocking_lock_session.machine||'(SID='||blocking_lock_session.sid||') ['||
blocking_lock_session.program||'/PID='||blocking_lock_session.process||']' as blocker_text,
blocked_lock_session.username||'@'||blocked_lock_session.machine|| '(SID='||blocked_lock_session.sid||') ['||
blocked_lock_session.program||'/PID='||blocked_lock_session.process||']' as blocked_text,
blocked_lock_session.row_wait_obj#,
blocked_lock_session.row_wait_file#,
blocked_lock_session.row_wait_block#,
blocked_lock_session.row_wait_row#,
DBMS_ROWID.ROWID_CREATE (1,
blocked_lock_session.row_wait_obj#,
blocked_lock_session.row_wait_file#,
blocked_lock_session.row_wait_block#,
blocked_lock_session.row_wait_row#) row#,
blocked_lock_session.seconds_in_wait blocked_secs,
blocked_sql.sql_text blocked_sql_text,
blocking_sql.sql_text blocking_sql_text
FROM v$lock blocking_lock,
v$session blocking_lock_session,
v$lock blocked_lock,
v$session blocked_lock_session,
v$sql blocked_sql,
v$sql blocking_sql
WHERE blocking_lock.block = 1
AND blocking_lock.id1 = blocked_lock.id1
AND blocking_lock.id2 = blocked_lock.id2
AND blocked_lock.request > 0
AND blocking_lock.sid = blocking_lock_session.sid
AND blocked_lock.sid = blocked_lock_session.sid
AND blocked_lock_session.sql_id = blocked_sql.sql_id
AND blocked_lock_session.sql_child_number = blocked_sql.child_number
AND blocking_lock_session.PREV_SQL_ADDR(+) =blocking_sql.ADDRESS
) locks_t,
dba_objects
WHERE locks_t.row_wait_obj# = dba_objects.object_id
ORDER BY locks_t.blocked_secs;

如果我们在会话窗口1,再执行一个语句,如下所示
SQL> show user;
USER is "TEST"
SQL> UPDATE TEST SET NAME='KKK' WHERE ID =1001;
1 row updated.
SQL> select * from dual;
D
-
X
此时捕获到的是select * from dual; 这个SQL跟被阻塞的SQL没有任何关系,当然如果你继续在会话窗口执行其它SQL语句,捕获的都是不相关的SQL语句,已经没有任何意义

出现这个问题,是因为当一个会话正在执行某个SQL语句,那么v$session视图中的SQL_ID记录的是正在执行SQL的SQL_ID,当会话空闲或执行其它SQL语句后,SQL_ID就会变化,PRE_SQL_ID记录上一个执行完的SQL的SQL_ID值,PREV_SQL_ADDR也是如此。如下英文所述 :
According to the Reference Manual entry for V$SESSION the SQL_ID column represents the current SQL statement being executed by a session. If the session is idle there is no current SQL statement. Also if a session performs an update then performs a query the SQL_ID would reflect the query and not the update which is the statement that is blocking. There is in fact no query that is guaranteed to find the blocking SQL. Unless the blocking statement is the current statement all you can find for sure I the blocking session
如果你不用SQL*Plus,使用PL/SQL Developer这个工具,你会看到BLOCKING_SQL_TEST永远都是begin sys.dbms_output.get_line(line => :line, status => :status); end; 这个是因为PL/SQL Developer在执行完SQL后,会调用其它SQL语句,当然SQL Developer不会有这样的问题。
所以综上述,想要找到阻塞的源头SQL语句,只用SQL查询,其实在很多场景是不太现实的,所以很多SQL语句都只给出阻塞者的会话信息或锁定对象信息。如下所示
会话ID为8的会话执行下面SQL
UPDATE TEST SET NAME='TEST' WHERE ID=1001;
会话ID为137的会话执行下面SQL
UPDATE TEST SET NAME='TES1' WHERE ID=1001;
然后我们使用get_locked_objects_rpt.sql查看被阻塞的SQL,以及锁定相关对象的信息(get_locked_objects_rpt.sql请参考get_locked_objects_rpt.sql)
SQL> @get_locked_objects_rpt.sql
Enter value for 1: 6
old 42: AND locks_t.blocked_secs > &1
new 42: AND locks_t.blocked_secs > 6
========= $Revision: 1.4 $ ($Date: 2013/09/16 13:15:22 $) ===========
Locked object : TEST
Locked row# : AAASEkAAEAAAADVAAA
Blocked for : 19 seconds
Blocker info. : TEST@GFG1\GET253194(SID=8) [plsqldev.exe/PID=17988:14616]
Blocked info. : TEST@get253194(SID=137) [SQL Developer/PID=17780]
Blocked SQL : UPDATE TEST SET NAME='TES1' WHERE ID=1001
Found 1 blocked session(s).
Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
[oracle@DB-Server ~]$

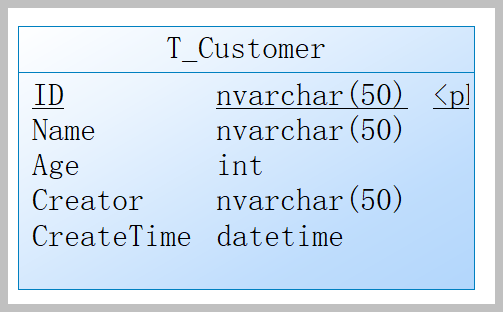
然后我通过上面的Locked Object知道被锁定的对象为Test表的ROWID为AAASRCAAEAAAADVAAA的记录,如下所示


 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发

 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发