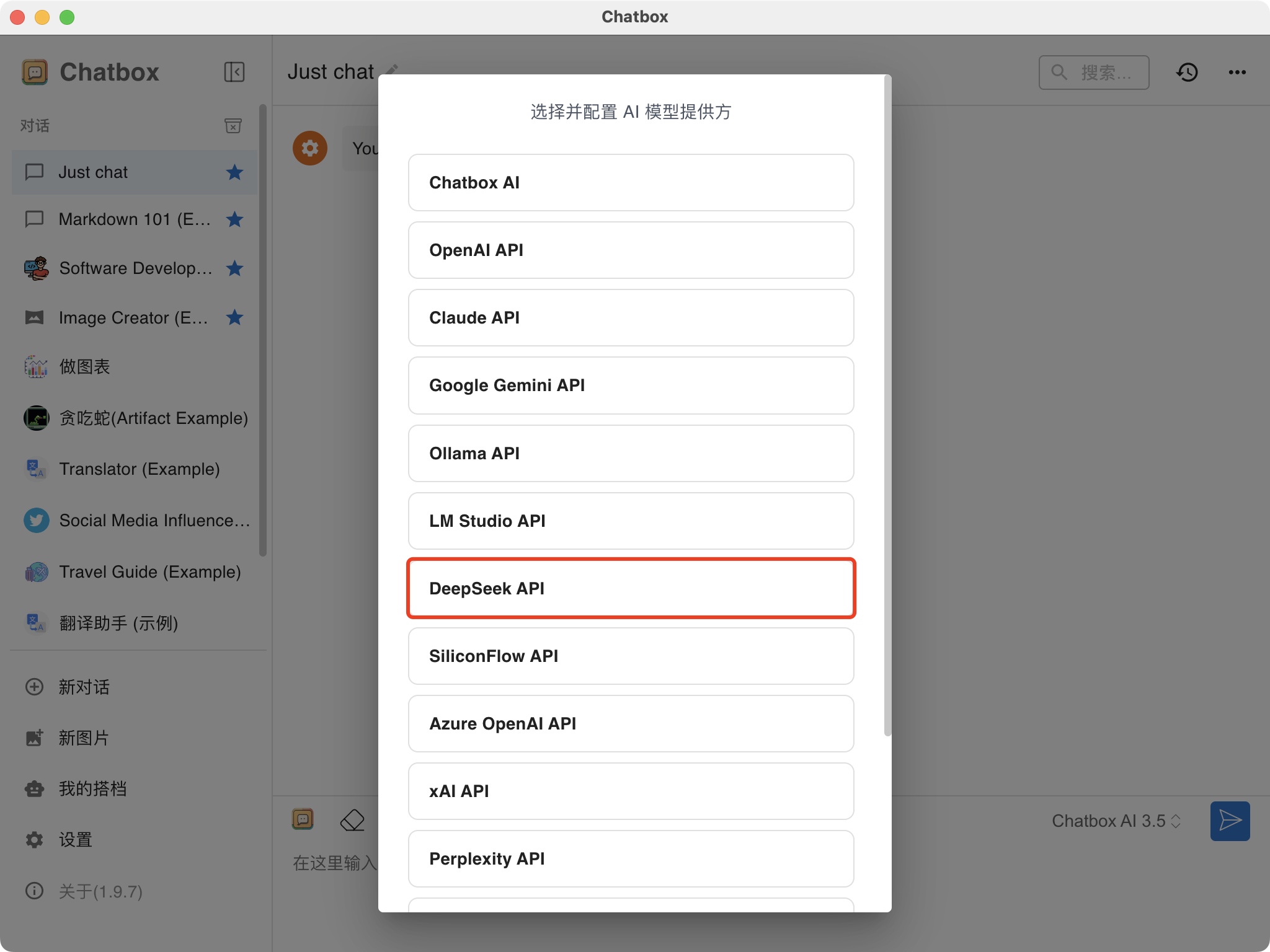
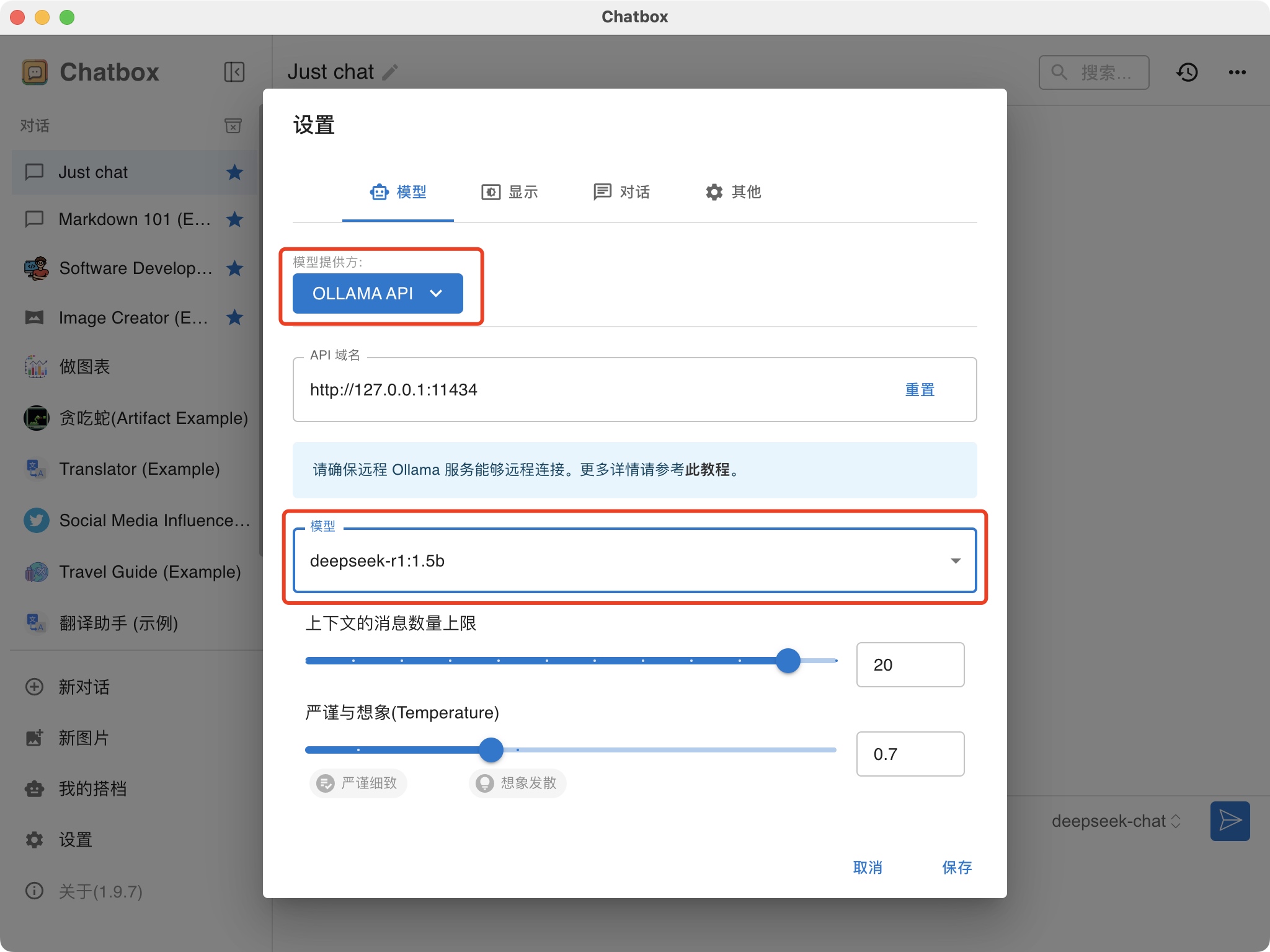
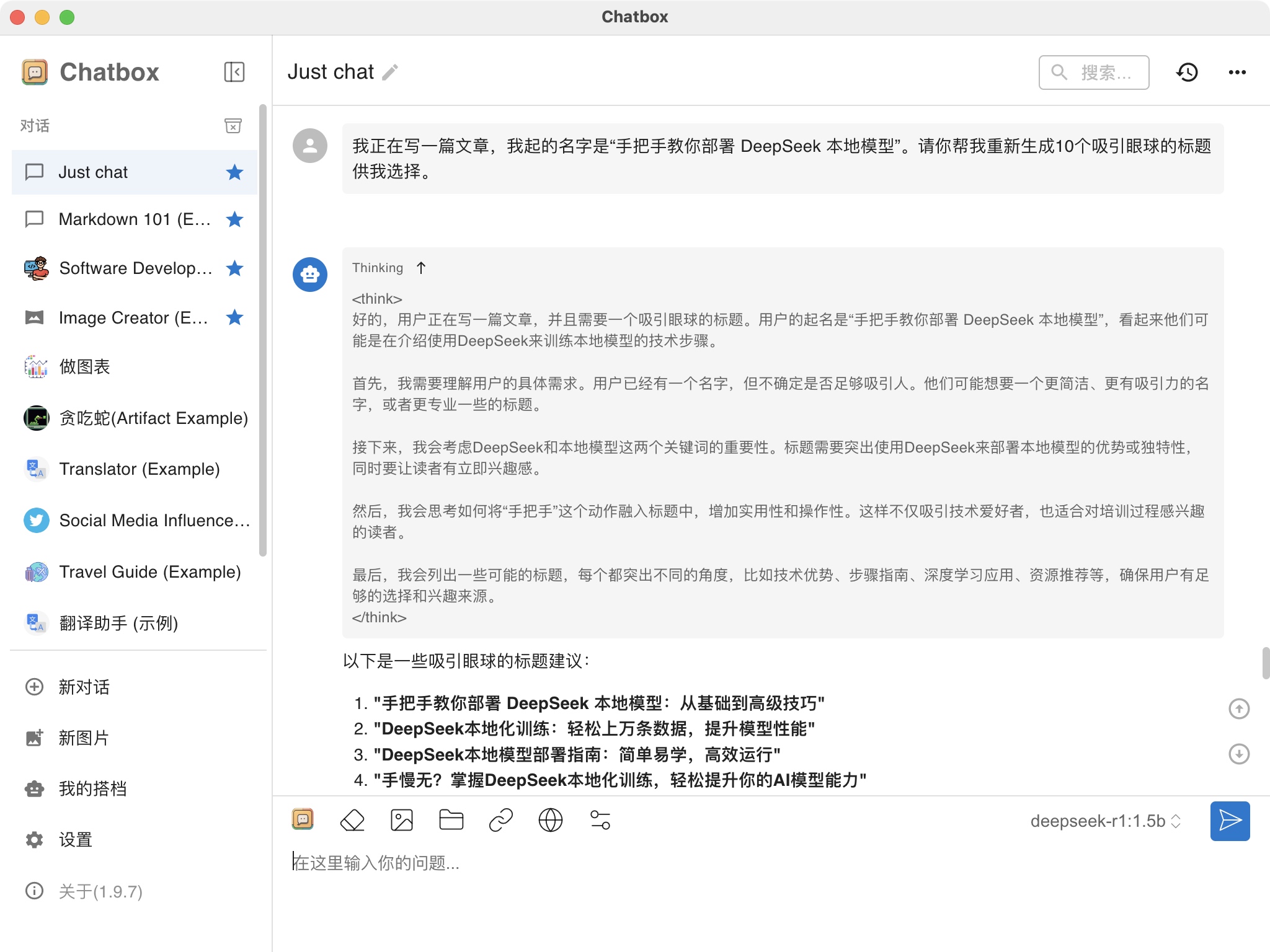
来源: 办公新利器:DeepSeek+Word,让你的工作更高效_deepseek接入word-CSDN博客\
DeepSeek与Word的梦幻联动,将为你开启高效办公的新篇章!熟悉的Word界面中,只需轻点鼠标,就能召唤出强大的DeepSeek,让它为你快速检索信息、精准翻译文本、智能生成内容…… 告别在不同软件间来回切换的繁琐,告别低效的信息获取方式,让办公效率飞起来!
1.效果演示
按照文本教程完成操作后,Word的选项卡中将会出现DeepSeek的生成图标,选中文本并点击生成,即可实现模型回复!例如,我们想要将一段中文文本翻译成英文:
接下来我将详细介绍,如何实现DeepSeek与Word的结合。
2.获取API key
API key的获取教程可以参照我之前的之一篇文章,在获取API key之后,回到这里。
PyCharm接入DeepSeek实现AI编程-CSDN博客
https://blog.csdn.net/qq_63708623/article/details/145370942?spm=1001.2014.3001.5501
3.配置Word
3.1 开发者工具的配置
新建一个Word文档,点击 文件 -> 选项 -> 自定义功能区,勾选“开发者工具”。
点击 信任中心 -> 信任中心设置,选择“启用所有宏”与“信任对VBA……”。
接下来点击确定,我们发现选项卡中出现了“开发者工具”,点击开发者工具,点击Visual Basic,将会弹出一个窗口。
3.2 复制代码
我们点击新窗口中的插入,点击模块。
点击后将会弹出一个编辑器,我们把如下代码复制到编辑区中。注意不要忘记替换你自己的API key。
Function CallDeepSeekAPI(api_key As String, inputText As String) As String
Dim API As String
Dim SendTxt As String
Dim Http As Object
Dim status_code As Integer
Dim response As String
API = “https://api.deepseek.com/chat/completions”
SendTxt = “{“”model””: “”deepseek-chat””, “”messages””: [{“”role””:””system””, “”content””:””You are a Word assistant””}, {“”role””:””user””, “”content””:””” & inputText & “””}], “”stream””: false}”
Set Http = CreateObject(“MSXML2.XMLHTTP”)
With Http
.Open “POST”, API, False
.setRequestHeader “Content-Type”, “application/json”
.setRequestHeader “Authorization”, “Bearer ” & api_key
.send SendTxt
status_code = .Status
response = .responseText
End With
‘ 弹出窗口显示 API 响应(调试用)
‘ MsgBox “API Response: ” & response, vbInformation, “Debug Info”
If status_code = 200 Then
CallDeepSeekAPI = response
Else
CallDeepSeekAPI = “Error: ” & status_code & ” – ” & response
End If
Set Http = Nothing
End Function
Sub DeepSeekV3()
Dim api_key As String
Dim inputText As String
Dim response As String
Dim regex As Object
Dim matches As Object
Dim originalSelection As Object
api_key = “替换为你的api key”
If api_key = “” Then
MsgBox “Please enter the API key.”
Exit Sub
ElseIf Selection.Type <> wdSelectionNormal Then
MsgBox “Please select text.”
Exit Sub
End If
‘ 保存原始选中的文本
Set originalSelection = Selection.Range.Duplicate
inputText = Replace(Replace(Replace(Replace(Replace(Selection.text, “\”, “\\”), vbCrLf, “”), vbCr, “”), vbLf, “”), Chr(34), “\”””)
response = CallDeepSeekAPI(api_key, inputText)
If Left(response, 5) <> “Error” Then
Set regex = CreateObject(“VBScript.RegExp”)
With regex
.Global = True
.MultiLine = True
.IgnoreCase = False
.Pattern = “””content””:””(.*?)”””
End With
Set matches = regex.Execute(response)
If matches.Count > 0 Then
response = matches(0).SubMatches(0)
response = Replace(Replace(response, “”””, Chr(34)), “”””, Chr(34))
‘ 取消选中原始文本
Selection.Collapse Direction:=wdCollapseEnd
‘ 将内容插入到选中文字的下一行
Selection.TypeParagraph ‘ 插入新行
Selection.TypeText text:=response
‘ 将光标移回原来选中文本的末尾
originalSelection.Select
Else
MsgBox “Failed to parse API response.”, vbExclamation
End If
Else
MsgBox response, vbCritical
End If
End Sub
完成后,可直接关闭弹窗。
3.3 添加新组
点击 文件 -> 选项 -> 自定义功能区,右键开发工具,点击添加新组。
在添加的新建组点击右键,点击重命名。将其命名为DeepSeek,并选择心仪的图标,最后点击确定。
首先选择DeepSeek(自定义),选择左侧的命令为“宏”,找到我们添加的DeepSeekV3,选中后点击添加。
随后,选中添加的命令,右键点击重命名,选择开始符号作为图标,并重命名为“生成”。
最后点击确定。
至此,Word成功接入DeepSeek大模型。
4.效果测试
选中文字,点击生成,就可以直接将选中的文本发送给大模型,大模型将会按照你选中的文本,做出响应。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_63708623/article/details/145418457