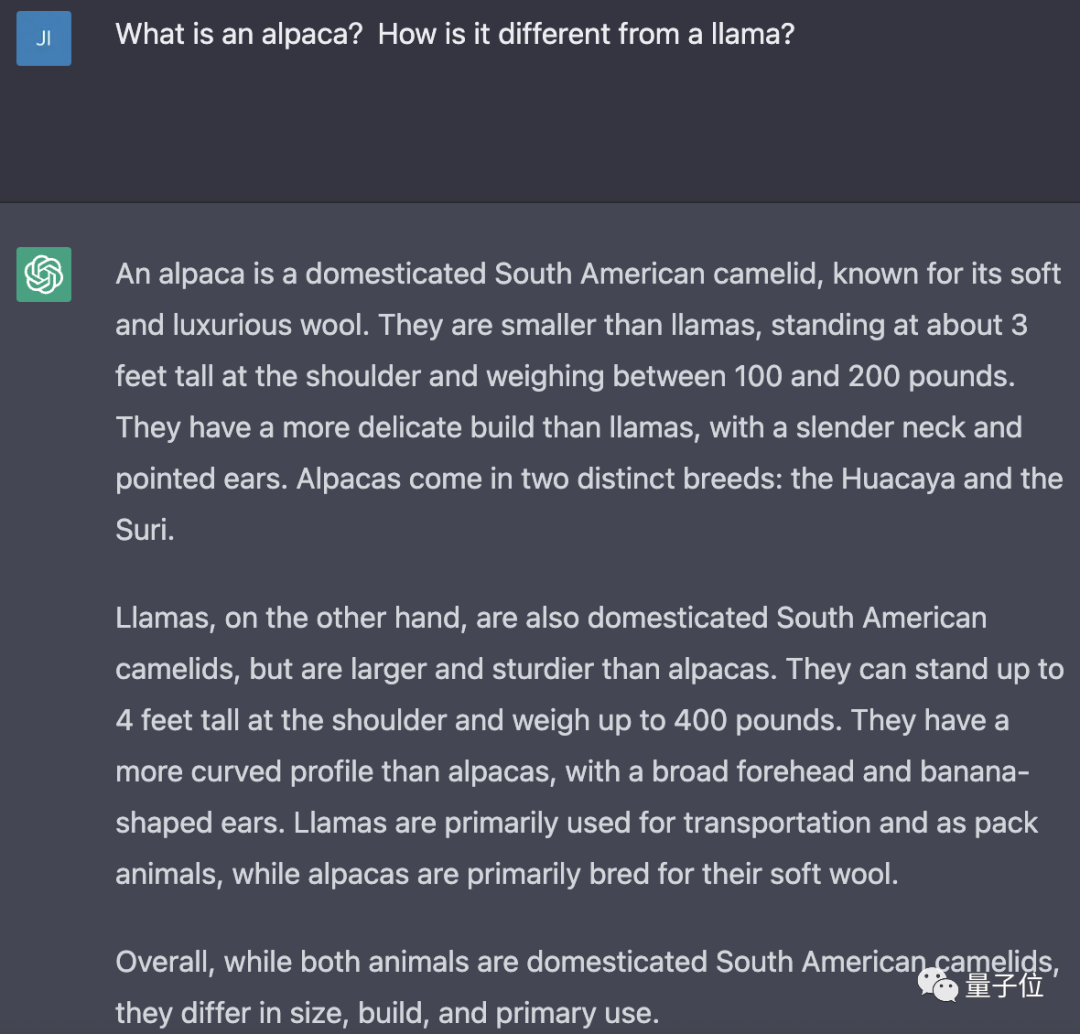
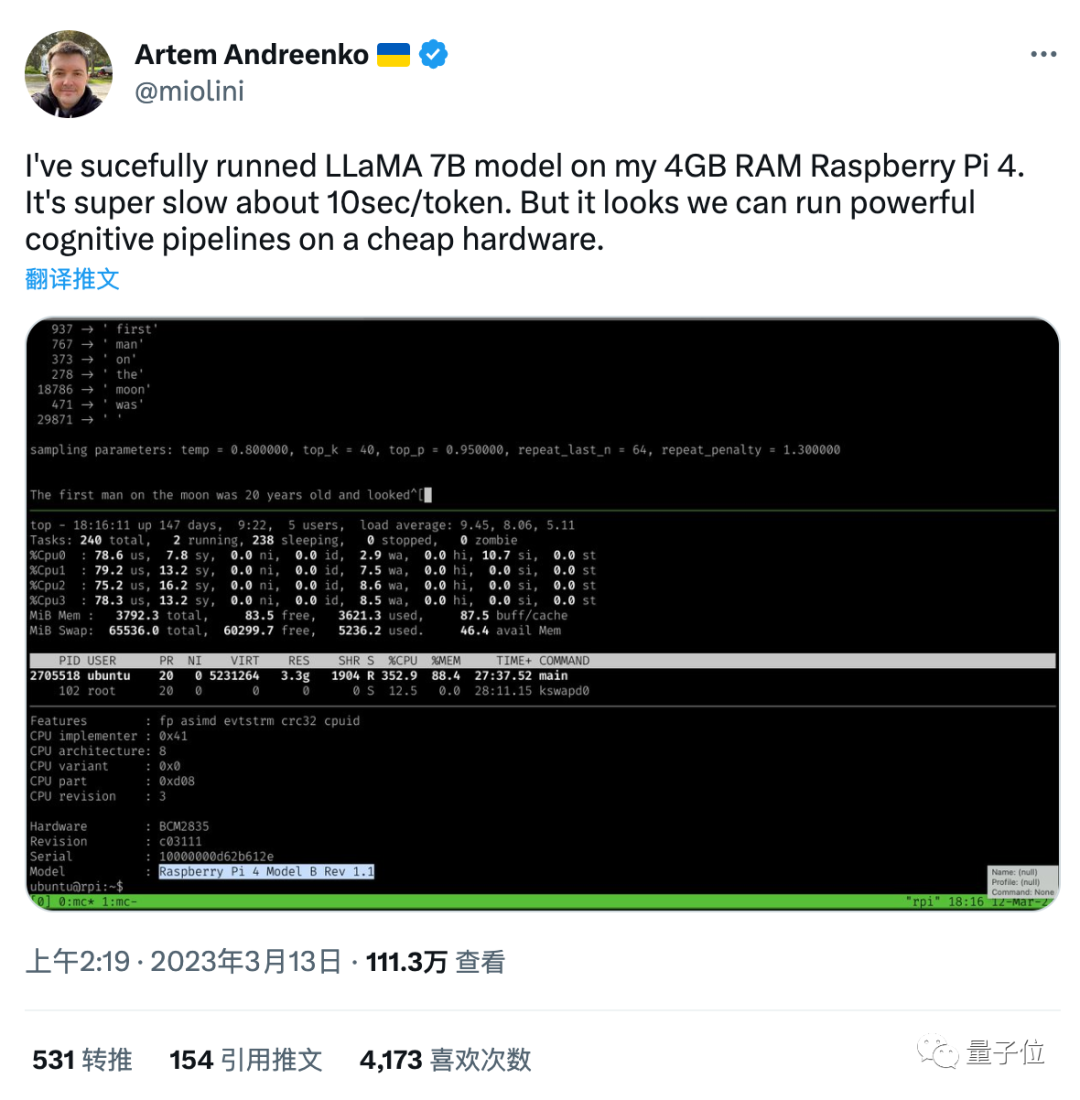
来源: Vue 响应式原理模拟以及最小版本的 Vue的模拟 – 编程大世界
在模拟最小的vue之前,先复习一下,发布订阅模式和观察者模式
对两种模式有了了解之后,对Vue2.0和Vue3.0的数据响应式核心原理
1.Vue2.0和Vue3.0的数据响应式核心原理
(1). Vue2.0是采用Object.defineProperty的方式,对数据进行get,set方法设置的, 具体可以详见Object.defineProperty的介绍
浏览器兼容 IE8 以上(不兼容 IE8)
<script> // 模拟 Vue 中的 data 选项 let data = { msg: 'hello' } // 模拟 Vue 的实例 let vm = {} // 数据劫持:当访问或者设置 vm 中的成员的时候,做一些干预操作 Object.defineProperty(vm, 'msg', { // 可枚举(可遍历) enumerable: true, // 可配置(可以使用 delete 删除,可以通过 defineProperty 重新定义) configurable: true, // 当获取值的时候执行 get () { console.log('get: ', data.msg) return data.msg }, // 当设置值的时候执行 set (newValue) { console.log('set: ', newValue) if (newValue === data.msg) { return } data.msg = newValue // 数据更改,更新 DOM 的值 document.querySelector('#app').textContent = data.msg } }) // 测试 vm.msg = 'Hello World' console.log(vm.msg) </script>
如果,vm里的属性是对象如何处理,可以,对其遍历,在进行Object.defineProperty
<script> // 模拟 Vue 中的 data 选项 let data = { msg: 'hello', count: 10, person: {name: 'zhangsan'} } // 模拟 Vue 的实例 let vm = {} proxyData(data) function proxyData(data) { // 遍历 data 对象的所有属性 Object.keys(data).forEach(key => { // 把 data 中的属性,转换成 vm 的 setter/setter Object.defineProperty(vm, key, { enumerable: true, configurable: true, get () { console.log('get: ', key, data[key]) return data[key] }, set (newValue) { console.log('set: ', key, newValue) if (newValue === data[key]) { return } data[key] = newValue // 数据更改,更新 DOM 的值 document.querySelector('#app').textContent = data[key] } }) }) } // 测试 vm.msg = 'Hello World' console.log(vm.msg) </script>
(2). Vue3.x是采用proxy代理的方式实现, 直接监听对象,而非属性。ES 6中新增,IE 不支持,性能由浏览器优化,具体可以详见MDN – Proxy
<script> // 模拟 Vue 中的 data 选项 let data = { msg: 'hello', count: 0 } // 模拟 Vue 实例 let vm = new Proxy(data, { // 执行代理行为的函数 // 当访问 vm 的成员会执行 get (target, key) { console.log('get, key: ', key, target[key]) return target[key] }, // 当设置 vm 的成员会执行 set (target, key, newValue) { console.log('set, key: ', key, newValue) if (target[key] === newValue) { return } target[key] = newValue document.querySelector('#app').textContent = target[key] } }) // 测试 vm.msg = 'Hello World' console.log(vm.msg) </script>
2.Vue 响应式原理模拟
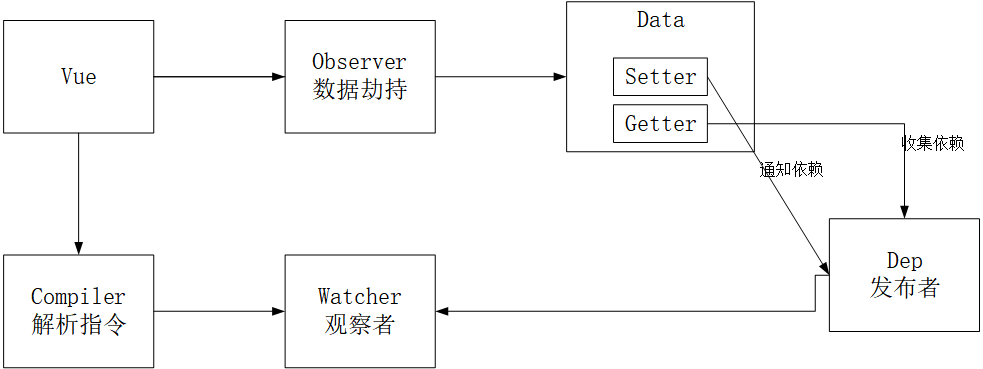
看图,整体分析
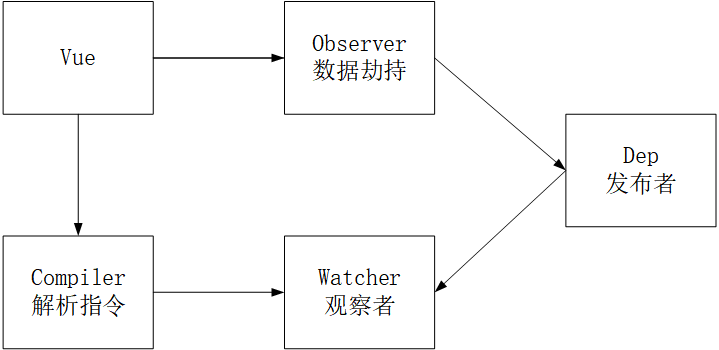
Vue
- 把 data 中的成员注入到 Vue 实例,并且把 data 中的成员转成 getter/setter
Observer
- 能够对数据对象的所有属性进行监听,如有变动可拿到最新值并通知 Dep
Compiler
- 解析每个元素中的指令/插值表达式,并替换成相应的数据
Dep
- 添加观察者(watcher),当数据变化通知所有观察者
Watcher
- 数据变化更新视图
(1) Vue
功能
- 负责接收初始化的参数(选项)
- 负责把 data 中的属性注入到 Vue 实例,转换成 getter/setter
- 负责调用 observer 监听 data 中所有属性的变化
- 负责调用 compiler 解析指令/插值表达式
class Vue { constructor (options) { //1.通过属性保存选项的数据 this.$options = options || {} this.$el = typeof options.el === 'string' ? document.querySelector(options.el) : options.el this.$data = options.data || {} //2.把data中的成员转换成getter和setter方法,注入到vue实例中 this._proxyData(this.$data) //3.调用observer对象,监听数据变化 new Observer(this.$data) //4.调用compiler对象, 解析指令和差值表达式 new Compiler(this) } _proxyData (data) { //遍历data中的所有属性 Object.keys(data).forEach( key => { //把data的属性注入到vue实例中 Object.defineProperty(this, key, { enumerable: true, configurable: true, get () { return data[key] }, set (newValue) { if (newValue === data[key]) { return } data[key] = newValue } }) }) } }
(2)Observer
功能
- 负责把 data 选项中的属性转换成响应式数据
- data 中的某个属性也是对象,把该属性转换成响应式数据
- 数据变化发送通知
class Observer { constructor (data) { this.walk(data) } //1. walk (data) { //1.判断data是不是对象 if (!data || typeof data !== 'object') { return } //遍历data对象里的所有属性 Object.keys(data).forEach( key => { this.definedReactive(data, key, data[key]) }) } definedReactive (obj, key, value) { let that = this //负责收集依赖(观察者), 并发送通知 let dep = new Dep() this.walk(value)//如果data里的属性是对象,对象里面的属性也得是响应式的,所以得判断一下 Object.defineProperty (obj, key, { enumerable: true, configurable: true, get () { //收集依赖 Dep.target && dep.addSubs(Dep.target) return value // return obj[key]//这么写会引起堆栈溢出 }, set (newValue) { if (newValue === value) { return } value = newValue that.walk(newValue)//如果赋值为对象,对象里面的属性得是响应式数据 //数据变换 ,发送通知给watcher的update ,在渲染视图里的数据 dep.notify() } }) } }
(3).Compiler
功能
- 负责编译模板,解析指令/插值表达式
- 负责页面的首次渲染
- 当数据变化后重新渲染视图
class Compiler { constructor (vm) {//传个vue实例 this.el = vm.$el this.vm = vm this.compile(this.el) } //编译模板, 处理文本节点和元素节点 compile (el) { let childNodes = el.childNodes //获取子节点 伪数组 console.dir(el.childNodes) Array.from(childNodes).forEach( node => { if (this.isTextNode(node)) { //是文本节点 this.compileText(node) } else if (this.isElementNode(node)) {//是元素节点 this.compileElement(node) } if (node.childNodes && node.childNodes.length) { //子节点里面还有节点,递归遍历获取 this.compile(node) } }) } //编译元素节点, 处理指令 compileElement (node) { //console.log(node.attributes) Array.from(node.attributes).forEach( attr => { //判断是不是指令 let attrName = attr.name //<div v-text="msg"></div> 里的v-text if (this.isDirective(attrName)) { //v-text --> text attrName = attrName.substr(2) let key = attr.value //<div v-text="msg"></div> 里的msg this.update(node , key, attrName) } }) } update (node, key, attrName) { let updateFn = this[attrName + 'Updater'] updateFn && updateFn.call(this, node, this.vm[key], key)//call方法改变this指向 } //处理v-text 命令 textUpdater (node, value, key) { node.textContent = value new Watcher(this.vm, key, (newValue) => { node.textContent = newValue }) } //v-model modelUpdater (node, value, key) { node.value = value new Watcher(this.vm, key, (newValue) => { node.value = newValue }) //双向绑定,视图改变,数据也会更新 node.addEventListener('input', () => { this.vm[key] = node.value }) } //编译文本节点,处理差值表达式 compileText (node) { //console.dir(node) // {{ msg }} let reg = /\{\{(.+?)\}\}/ let value = node.textContent //里面的内容, 也可以是nodeValue if (reg.test(value)) { let key = RegExp.$1.trim() //匹配到的第一个 node.textContent = value.replace(reg, this.vm[key]) //创建watcher对象, 当数据改变更新视图 new Watcher(this.vm, key, (newValue) => { node.textContent = newValue }) } } //判断元素属性是否是指令 isDirective (attrName) { return attrName.startsWith('v-') } //判断节点是否是文本节点 isTextNode (node) { return node.nodeType === 3 } //判断节点是否是元素节点 isElementNode (node) { return node.nodeType === 1 } }
(4).Dep(Dependency)
功能
- 收集依赖,添加观察者(watcher)
- 通知所有观察者
class Dep { constructor () { //收集观察者 this.subs = [] } //添加观察者 addSubs (watcher) { if (watcher && watcher.update) { this.subs.push(watcher) } } //数据变换,就调watcher的update方法 notify () { this.subs.forEach(watcher => { watcher.update() }); } }
(5).Watcher
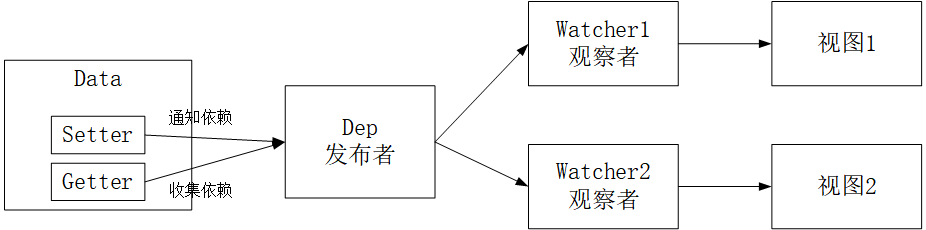
功能
- 当数据变化触发依赖, dep 通知所有的 Watcher 实例更新视图
- 自身实例化的时候往 dep 对象中添加自己
class Watcher { constructor (vm, key, callback) { this.vm = vm //data中的属性名 this.key = key this.callback = callback //将watcher对象记录在Dep的静态属性target Dep.target = this //触发get方法,触发get里的addsubs方法,添加watcher this.oldValue = vm[key] Dep.target = null } //当数据变化的时候,更新视图 update () { let newValue = this.vm[this.key] if (this.oldValue === newValue) { return } this.callback(newValue) } }
总结:
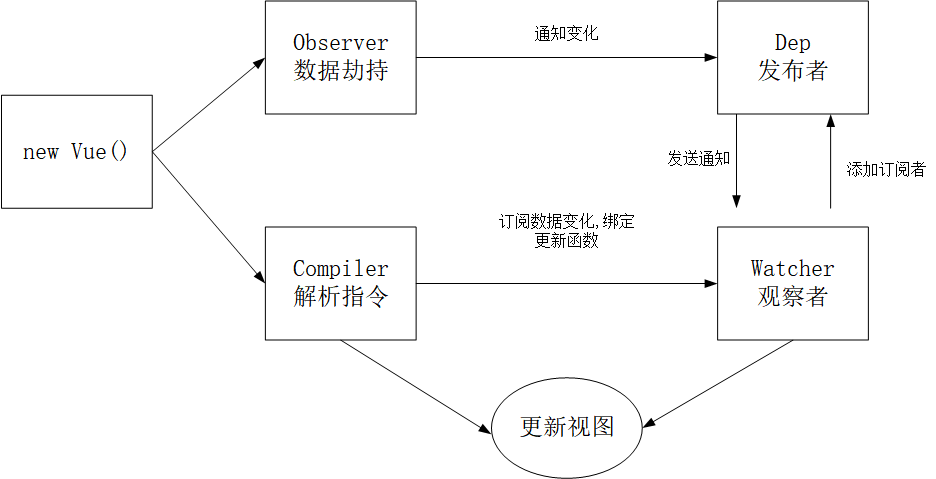
Vue
- 记录传入的选项,设置 $data/$el
- 把 data 的成员注入到 Vue 实例
- 负责调用 Observer 实现数据响应式处理(数据劫持)
- 负责调用 Compiler 编译指令/插值表达式等
Observer
- 数据劫持
- 负责把 data 中的成员转换成 getter/setter
- 负责把多层属性转换成 getter/setter
- 如果给属性赋值为新对象,把新对象的成员设置为 getter/setter
- 添加 Dep 和 Watcher 的依赖关系
- 数据变化发送通知
Compiler
- 负责编译模板,解析指令/插值表达式
- 负责页面的首次渲染过程
- 当数据变化后重新渲染
Dep
- 收集依赖,添加订阅者(watcher)
- 通知所有订阅者
Watcher
- 自身实例化的时候往dep对象中添加自己
- 当数据变化dep通知所有的 Watcher 实例更新视图