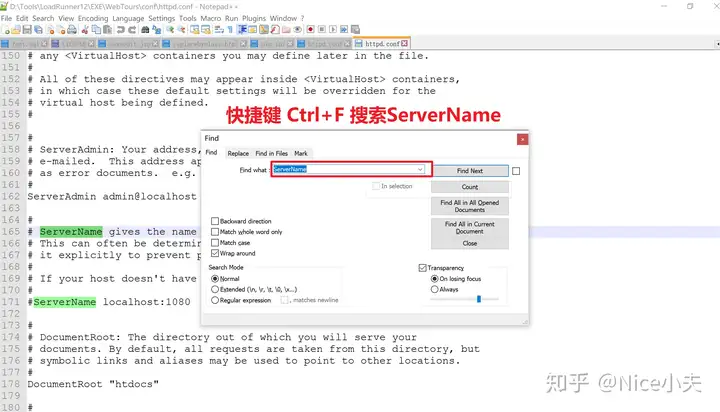
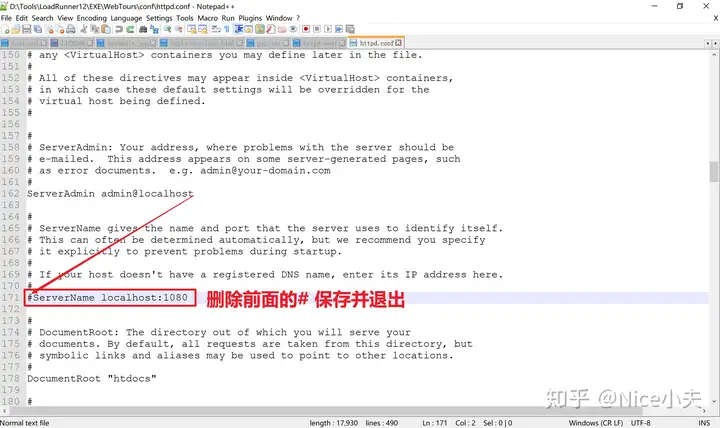
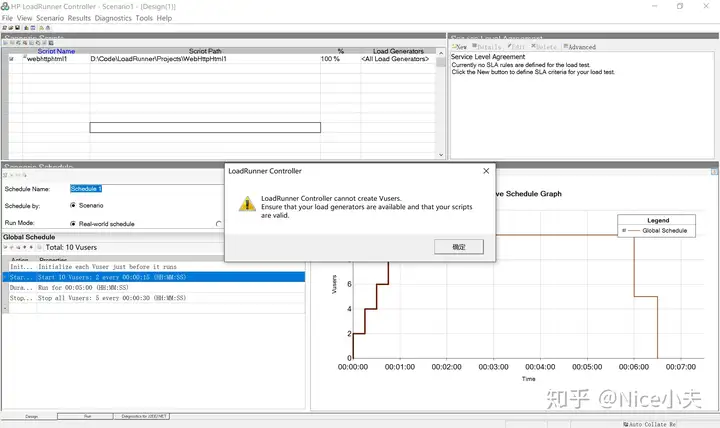
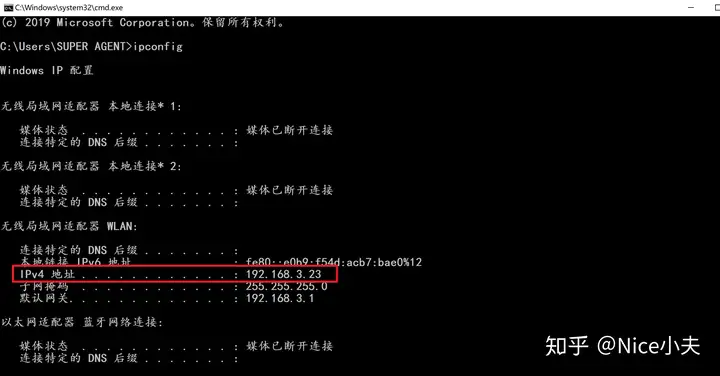
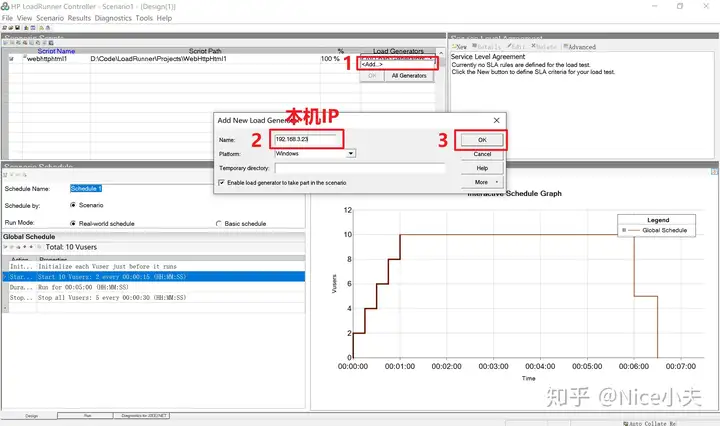
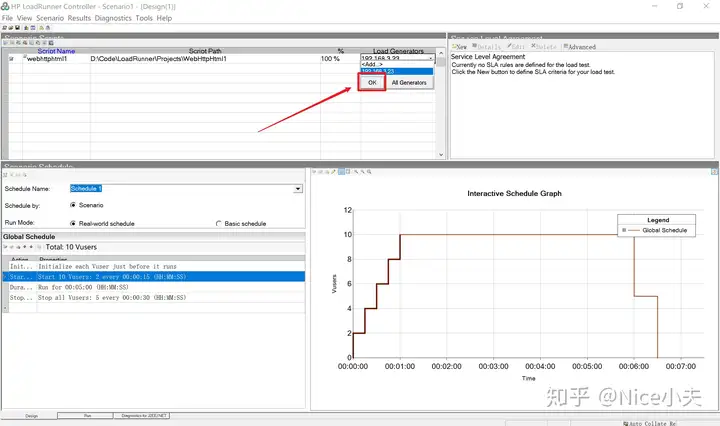
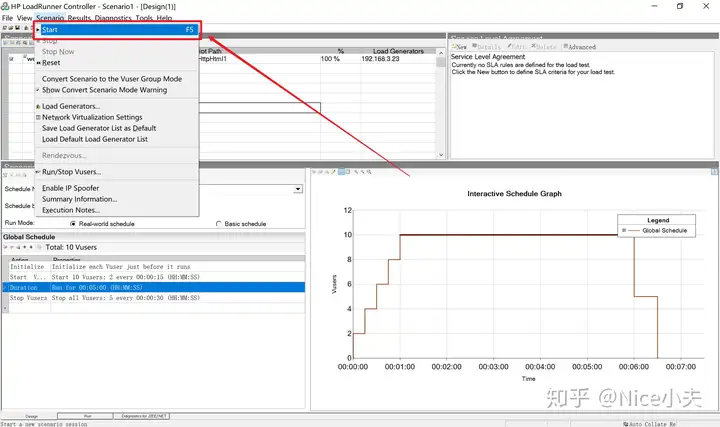
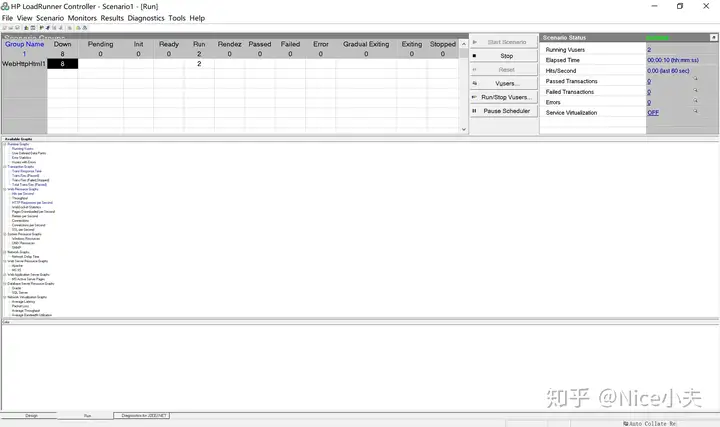
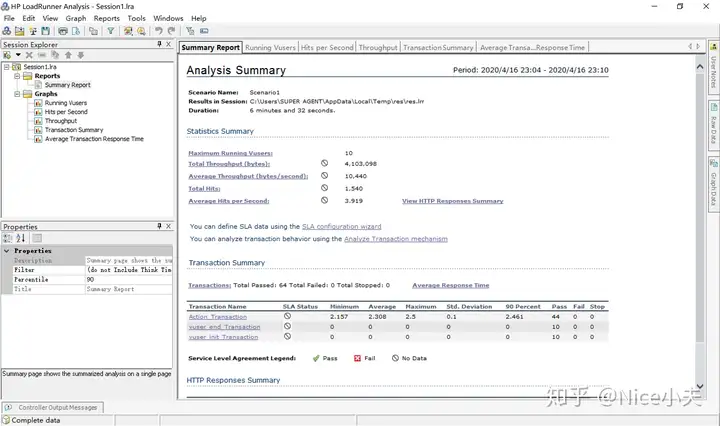
来源: Dapper 分页,万能公共分页,使用sql高效率分页_橙-极纪元的博客-CSDN博客
用户表实体类 UserInfoModel
public class UserInfoModel
{
public int Id{set;get;}
public int ClassId{set;get;}
public string Name{set;get;}
public int sex{set;get;}
}
分页模型
/*分页计算
当前显示数据=每页行数x(当前页数-1)
skip()跳过多少条,take()查询多少条
list.Skip(page.pageSize * (page.pageIndex – 1)).Take(page.pageSize).AsQueryable().ToList();
*/
/// <summary>
/// 分页信息
/// </summary>
public class PageInfo
{
/// <summary>
/// 每页行数(每页数据量):默认每页10条
/// </summary>
public int pageSize { get; set; } = 10;
/// <summary>
/// 当前页:默认第1页
/// </summary>
public int pageIndex { get; set; } = 1;
/// <summary>
/// 总记录数:默认0条
/// </summary>
public int count { get; set; } = 0;
/// <summary>
/// 总页数
/// </summary>
public int pageCount
{
get
{
if (count > 0)
{
return count % this.pageSize == 0 ? count / this.pageSize : count / this.pageSize + 1;
}
else
{
return 0;
}
}
}
}
数据库基类
using Dapper;
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.SQLClient;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace User.Dal
{
public class BaseDapper
{
/// <summary>
/// 数据库连接字符串
/// </summary>
protected static string connStr = System.Configuration.ConfigurationManager.ConnectionStrings[“DbContext”].ConnectionString;
/// <summary>
/// 公共分页
/// </summary>
/// <typeparam name=”T”>返回类型</typeparam>
/// <param name=”model”>SQL条件</param>
/// <param name=”total”>结果集总数</param>
/// <param name=”param”>参数</param>
/// <returns></returns>
public static IEnumerable<T> GetPageList<T>(SQLSelectPageModel model,out int total,object param = null)
{
#region 分页算法
int skip = 1;//从第几条开始
int take = model.pageIndex * model.pageSize;//到第几条结束
if (model.pageIndex > 0)
{
skip = ((model.pageIndex – 1) * model.pageSize)+1;
}
#endregion
StringBuilder sqlStr = new StringBuilder();
sqlStr.Append($”SELECT COUNT(1) FROM {model.tableName} where {model.where};”);
sqlStr.Append($@”SELECT {model.files}FROM
(SELECT ROW_NUMBER() OVER(ORDER BY {model.orderby}) AS RowNum,{model.files} FROM {model.tableName} WHERE {model.where}) AS result
WHERE RowNum >= {skip} AND RowNum <= {take} ORDER BY {model.orderby}”);
using (SqlConnection conn = new SqlConnection(connStr))
{
//获取多个结果集
Dapper.SqlMapper.GridReader res = conn.QueryMultiple(sqlStr.ToString(), param: param, commandType: CommandType.Text);
//注意:如果存储过程首先查出是Type,其次是Product,那么你在执行下面代码的时候顺序必须和存储过程查询顺序一致
//read方法获取Type和Product
total = res.ReadFirst<int>();
IEnumerable<T> list = res.Read<T>();
return list;
//total = reader.ReadFirst<int>();
//return reader.Read<T>();
}
}
}
/// <summary>
/// sql 分页模型
/// </summary>
public class SQLSelectPageModel
{
/// <summary>
/// 查询的“列”
/// </summary>
public string files { set; get; }
/// <summary>
/// 表名 (可以跟join)
/// </summary>
public string tableName { set; get; }
/// <summary>
/// 条件
/// </summary>
public string where { set; get; }
/// <summary>
/// 排序 条件
/// </summary>
public string orderby { set; get; }
/// <summary>
/// 当前页
/// </summary>
public int pageIndex { set; get; }
/// <summary>
/// 当前页显示条数
/// </summary>
public int pageSize { set; get; }
}
}
子类调用
方式一 【推荐】
public class UserInfoDAL
{
/// <summary>
/// 根据分类ID获取信息列表
/// </summary>
/// <param name=”ClassId”>分类ID</param>
/// <param name=”sex”>性别 0 全部,1男,2女</param>
/// <param name=”pageInfo”>分页信息</param>
/// <returns></returns>
public static List<UserInfoModel> GetBaseInfoList(UserInfoModel UModel, PageInfo pageInfo)
{
List<UserInfoModel> result = new List<UserInfoModel>();
try
{
//1.SQL参数
SQLSelectPageModel sQLSelectPage = new SQLSelectPageModel() {
files=”*”,
tableName= “UserInfo”,
where= “ClassId=@ClassId”,
orderby= “Id desc”,
pageIndex= pageInfo.pageIndex,
pageSize= pageInfo.pageSize
};
//2.拼装条件 和参数
StringBuilder whereSB = new StringBuilder();
if (UModel.sex == 1 || UModel.sex == 2)
{
whereSB.Append(” and sex = @sex “);
}
sQLSelectPage.where = sQLSelectPage.where + whereSB.ToString();
//3.调用 基类 公共分页
var res = GetPageList<UserInfoModel>(sQLSelectPage, out int totalCount, UModel).ToList();
pageInfo.count = totalCount;
return res;
}
catch (Exception e)
{
return result;
}
}
}
方式二
public class UserInfoDAL
{
/// <summary>
/// 根据分类ID获取信息列表
/// </summary>
/// <param name=”ClassId”>分类ID</param>
/// <param name=”sex”>性别 0 全部,1男,2女</param>
/// <param name=”pageInfo”>分页信息</param>
/// <returns></returns>
public static List<UserInfoModel> GetBaseInfoList(int ClassId, int sex, PageInfo pageInfo)
{
List<UserInfoModel> result = new List<UserInfoModel>();
try
{
//1.SQL参数
SQLSelectPageModel sQLSelectPage = new SQLSelectPageModel() {
files=”*”,
tableName= “UserInfo”,
where= “ClassId=@ClassId”,
orderby= “Id desc”,
pageIndex= pageInfo.pageIndex,
pageSize= pageInfo.pageSize
};
//2.拼装条件 和参数
var param = new object();
if (sex == 1 || sex == 2)
{
sQLSelectPage.where = sQLSelectPage.where + ” and sex = @sex”;
param = new { ClassId = ClassId, sex = sex };
}
else
{
param = new {ClassId = ClassId};
}
//3.调用 基类 公共分页
var res = GetPageList<UserInfoModel>(sQLSelectPage, out int totalCount, param).ToList();
pageInfo.count = totalCount;
return res;
}
catch (Exception e)
{
}
return result;
}
}
————————————————
版权声明:本文为CSDN博主「橙-极纪元」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cplvfx/article/details/120204281