来源: layui table中select显示优化 – &执念 – 博客园
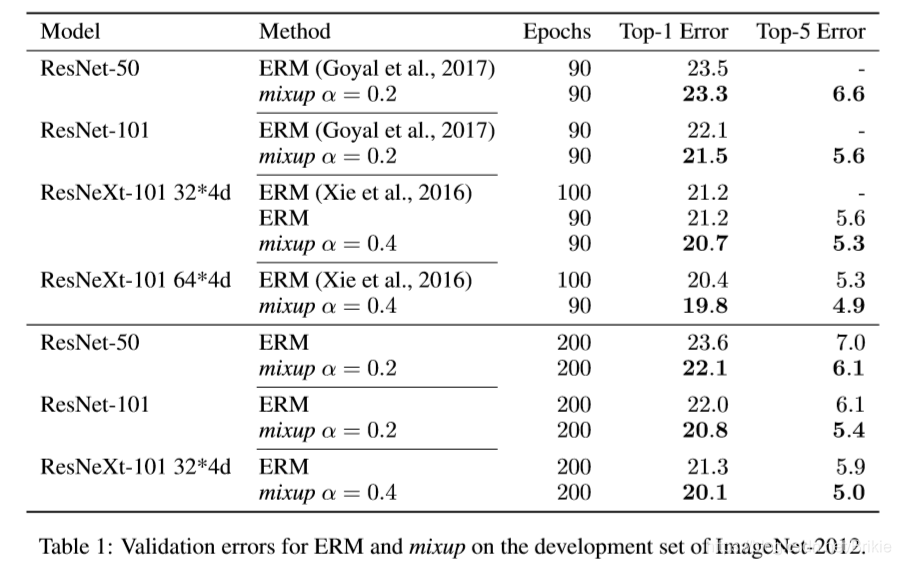
项目中经常用到table和select的情况,每次都会遇到select显示不全或者隐藏的问题,今天记录下解决方案:
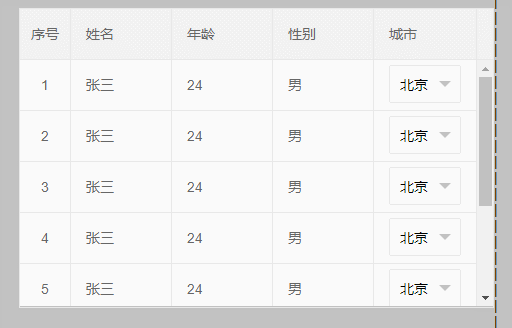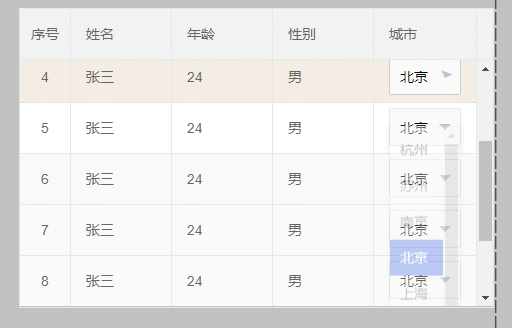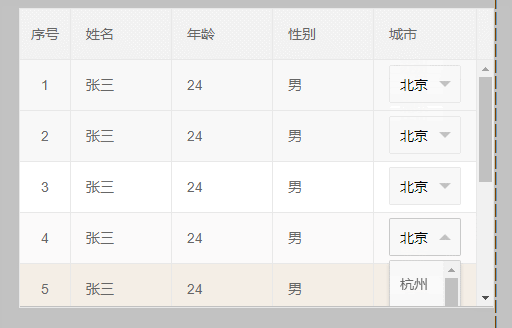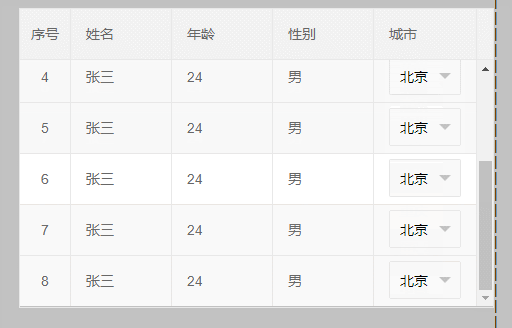
初始化表格后:select 无法正常显示,如下:
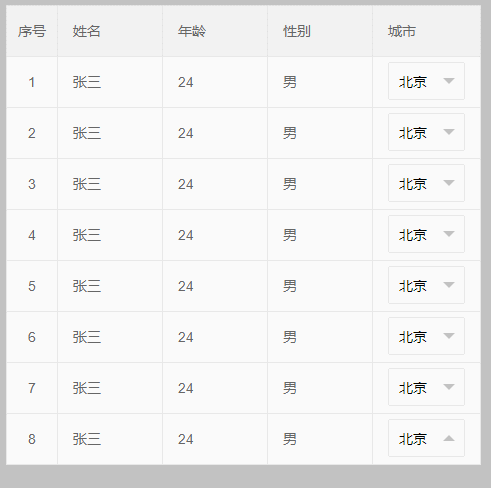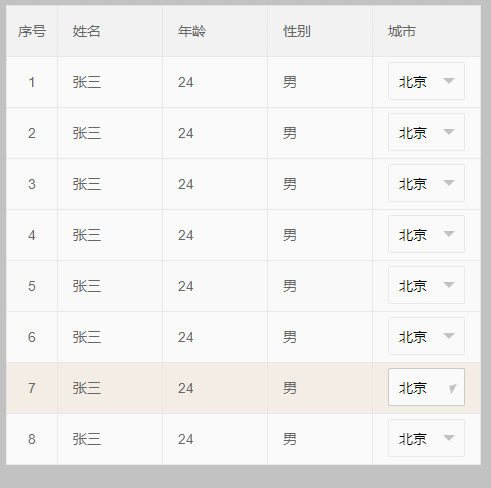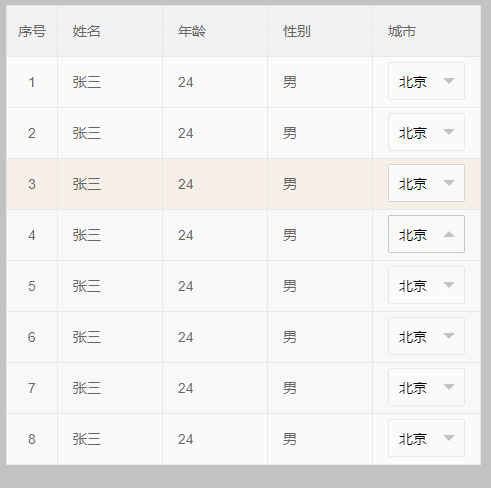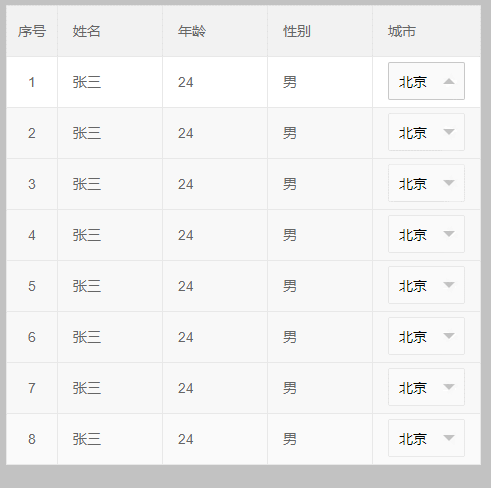
1、我们增加一行样式:
.layui-table-cell {
overflow: visible;
}
效果如下:虽然select功能可以使用了 但是还是很别扭 那么我们继续优化;
2、继续追加样式:
.layui-table-box , .layui-table-body {
overflow: visible;
}
效果如下 :这种解决办法,适用于table不定高的情况;
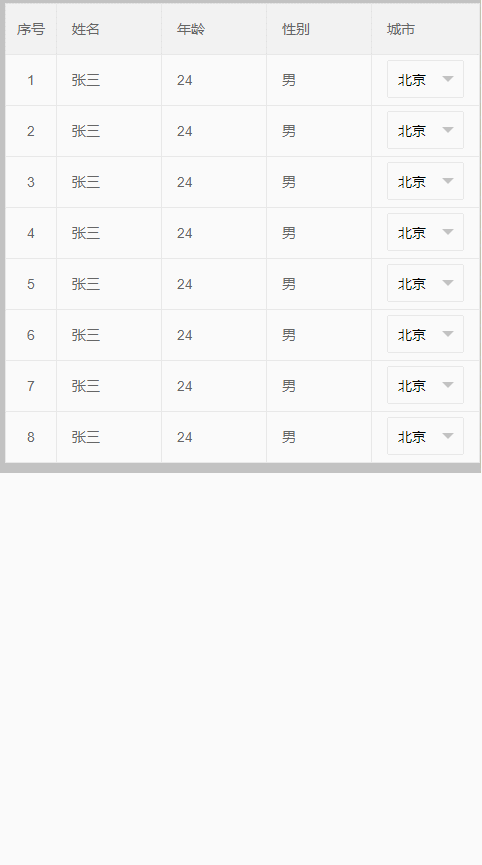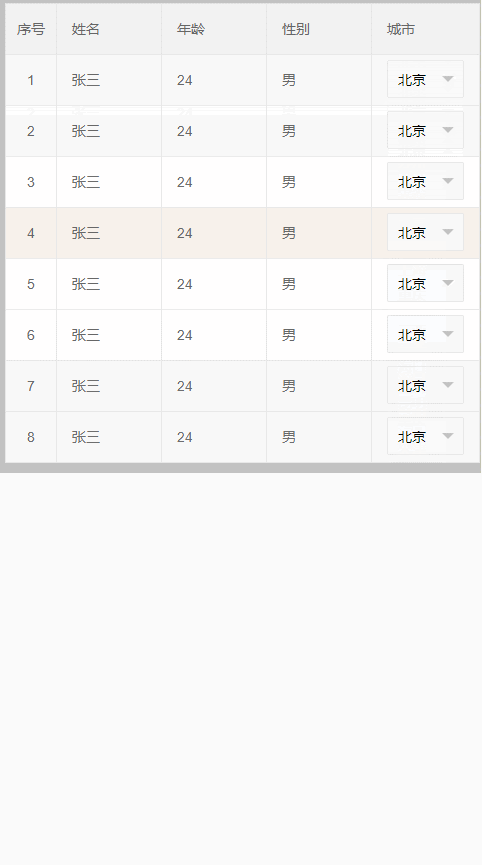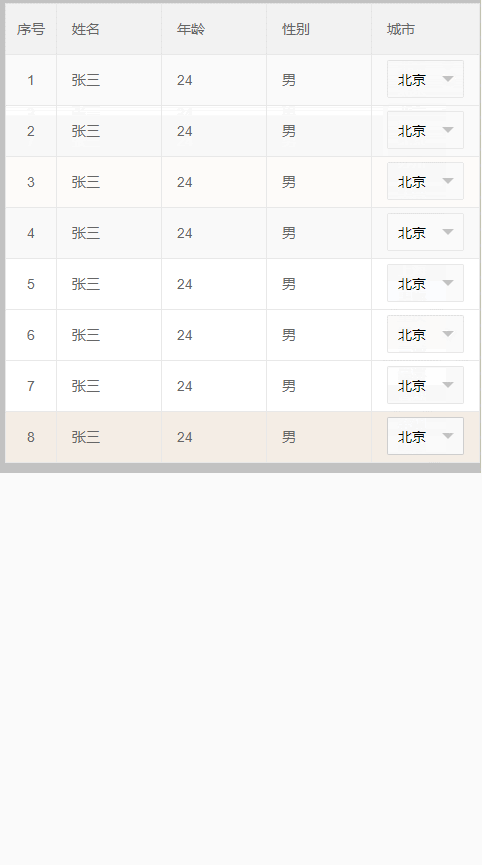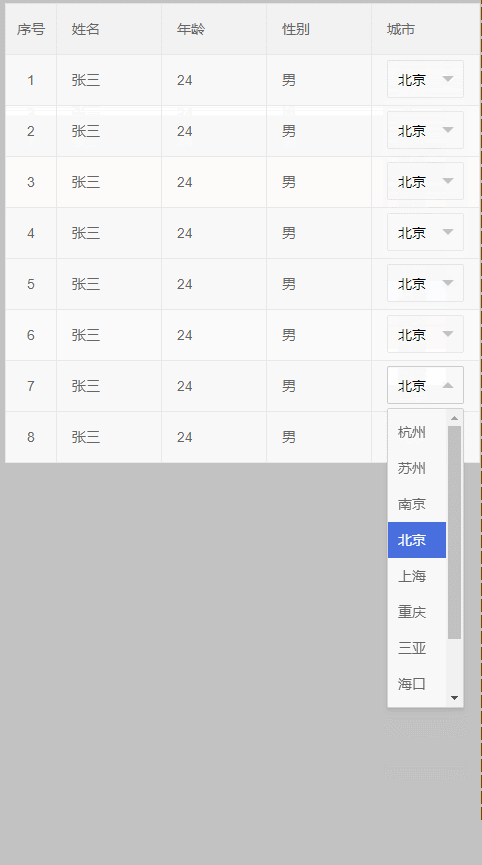
3、如果table是固定高度 需要内部滚动呢,单纯的设置overflow: visible;效果如下:
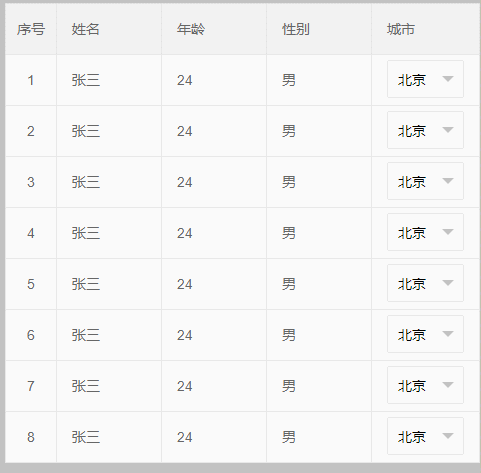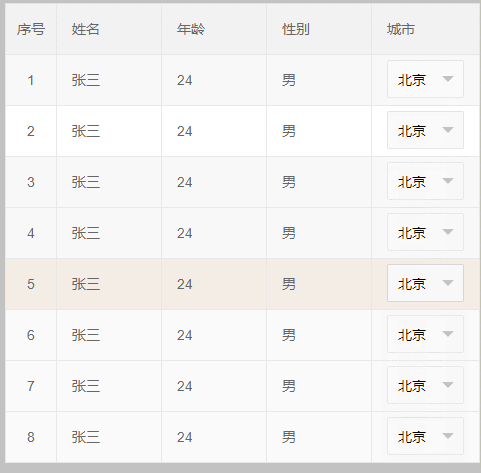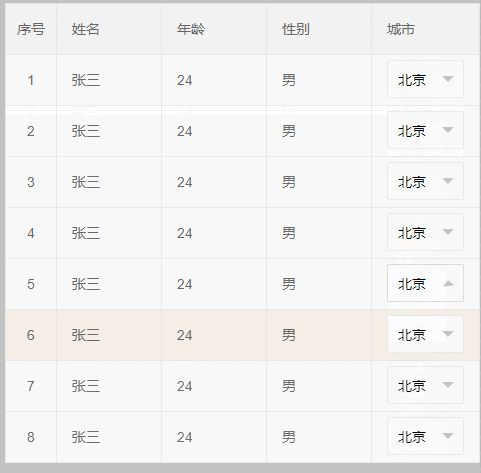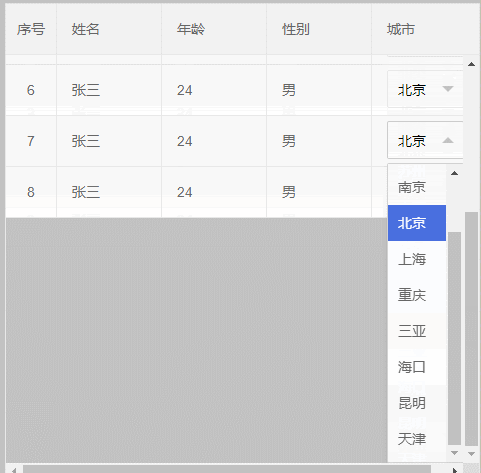
4、最后来个终极解决办法,效果如下:
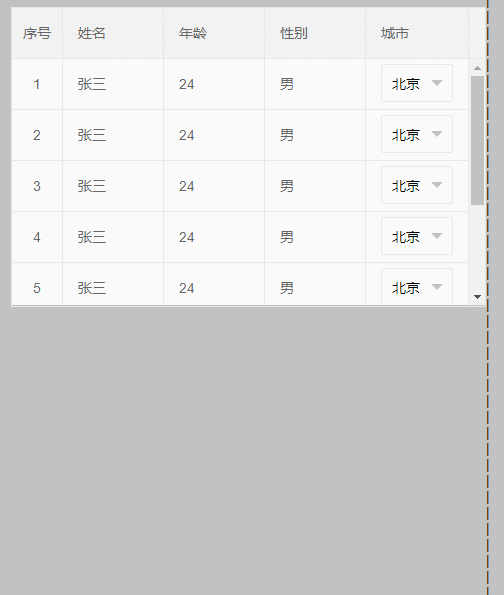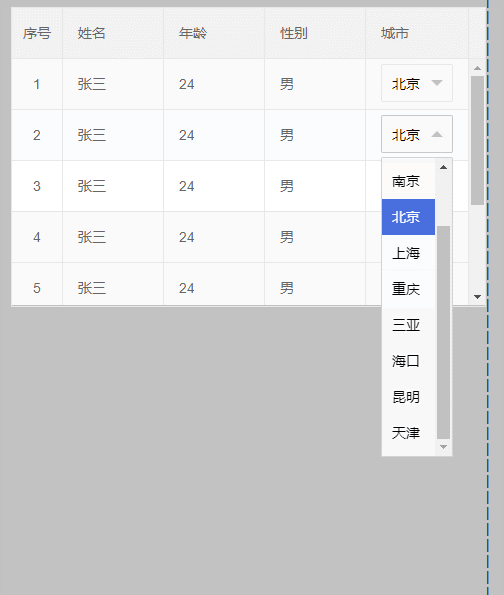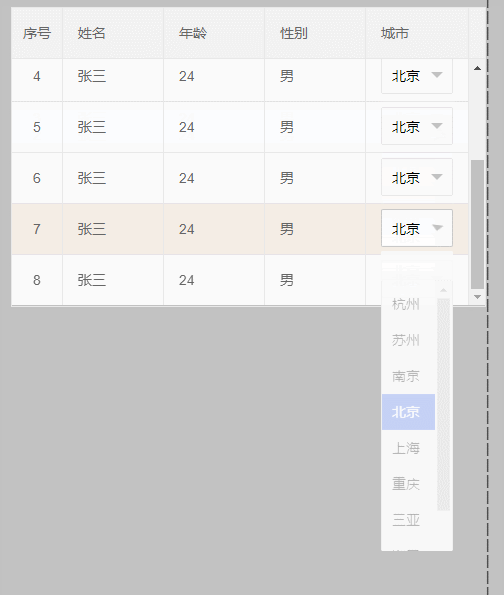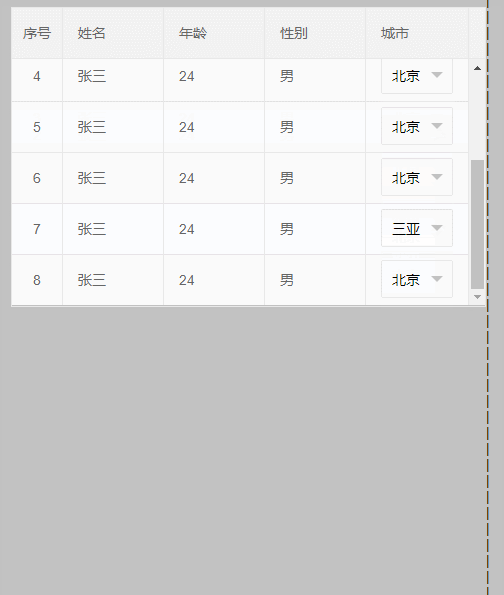
代码:
主要引入了 optimizeSelectOption 插件,稍后上源码。

layui.config({
base: "./layui/lay/my-modules/"
}).extend({
optimizeSelectOption: "optimizeSelectOption/optimizeSelectOption",//引入js
}).use(['layer','element', 'table','form','optimizeSelectOption'], function(){
var $ = layui.$, layer = layui.layer, form = layui.form, table = layui.table, element = layui.element;
var pathTemp = layui.cache.modules['optimizeSelectOption'] || '';
var filePath = pathTemp.substr(0, pathTemp.lastIndexOf('/'));
// 引入css
layui.link(filePath + '/optimizeSelectOption.css');
});
optimizeSelectOption .js
/*!
@Title: optimizeSelectOption
@Description:优化select在layer和表格中显示的问题
@Site:
@Author: 岁月小偷
@License:MIT
*/
;!function (factory) {
'use strict';
var modelName = 'optimizeSelectOption';
if (!window.top.layui) {
// 顶层引入layui是使用该组件的最低要求
console.warn('使用插件:' + modelName + '页面顶层窗口必须引入layui');
layui.define(['form'], function (exports) {
exports(modelName, {msg: '使用插件:' + modelName + '页面顶层窗口必须引入layui'});
});
} else {
// 利用的是顶层的top去弹出,所以用top的layui去use layer确保顶层
window.top.layui.use('layer', function () {
layui.define(['form'], function (exports) { //layui加载
exports(modelName, factory(modelName));
});
});
}
}(function (modelName) {
var version = '0.2.0';
var $ = layui.$;
var form = layui.form;
var layer = layui.layer;
var filePath = layui.cache.modules.optimizeSelectOption
.substr(0, layui.cache.modules.optimizeSelectOption.lastIndexOf('/'));
// 引入tablePlug.css
layui.link(filePath + '/optimizeSelectOption.css?v' + version);
var selectors = [
'.layui-table-view', // layui的表格中
'.layui-layer-content', // 用type:1 弹出的layer中
'.select_option_to_layer' // 任意其他的位置
];
// 记录弹窗的index的变量
window.top.layer._indexTemp = window.top.layer._indexTemp || {};
if (!form.render.plugFlag) {
// 只要未改造过的才需要改造一下
// 保留一下原始的form.render
var formRender = form.render;
form.render = function (type, filter, jqObj) {
var that = this;
var retObj;
// if (jqObj && jqObj.length) {
if (jqObj) {
layui.each(jqObj, function (index, elem) {
elem = $(elem);
var elemP = elem.parent();
var formFlag = elemP.hasClass('layui-form');
var filterTemp = elemP.attr('lay-filter');
// mark一下当前的
formFlag ? '' : elemP.addClass('layui-form');
filterTemp ? '' : elemP.attr('lay-filter', 'tablePlug_form_filter_temp_' + new Date().getTime() + '_' + Math.floor(Math.random() * 100000));
// 将焦点集中到要渲染的这个的容器上
retObj = formRender.call(that, type, elemP.attr('lay-filter'));
// 恢复现场
formFlag ? '' : elemP.removeClass('layui-form');
filterTemp ? '' : elemP.attr('lay-filter', null);
});
} else {
retObj = formRender.call(that, type, filter);
}
return retObj;
};
form.render.plugFlag = true;
}
// 关闭弹出的选项
var close = function () {
window.top.layer.close(window.top.layer._indexTemp[modelName]);
};
// 获得某个节点的位置 offsetTop: 是否获得相对top window的位移
function getPosition(elem, _window, offsetTop) {
_window = _window || window;
elem = elem.length ? elem.get(0) : elem;
var offsetTemp = {};
if (offsetTop && _window.top !== _window.self) {
var frameElem = _window.frames.frameElement;
offsetTemp = getPosition(frameElem, _window.parent, offsetTop);
}
var offset = elem.getBoundingClientRect();
return {
top: offset.top + (offsetTemp.top||0),
left: offset.left + (offsetTemp.left||0)
};
}
var config = {};
// 针对某个组件的效果优化注册方法
var render = function (name, options) {
var that = this;
if (config.name) {
console.warn('针对', name, '的显示优化已经存在,请不要重复渲染!');
return that;
}
// 优化select的选项在某些场景下的显示问题
$(document).on('click'
, selectors.map(function (value) {
// return value + ' .layui-select-title,' + value + ' .xm-select-title';
return value + ' ' + options.triggerElem;
}).join(',')
, function (event) {
layui.stope(event);
close();
var triggerElem = $(this);
var titleElem = triggerElem;
var dlElem = typeof options.dlElem === 'function' ? options.dlElem(triggerElem) : titleElem.next();
// var selectElem = titleElem.parent().prev();
var selectElem = titleElem.parent().prev();
var selectupFlag = titleElem.parent().hasClass('layui-form-selectup');
function getDlPosition() {
var titleElemPosition = getPosition(titleElem, window, true);
var topTemp = titleElemPosition.top;
var leftTemp = titleElemPosition.left;
if (selectupFlag) {
topTemp = topTemp - dlElem.outerHeight() + titleElem.outerHeight() - parseFloat(dlElem.css('bottom'));
} else {
topTemp += parseFloat(dlElem.css('top'));
}
if (topTemp + dlElem.outerHeight() > window.top.innerHeight && !selectupFlag) {
// 出现原始的form表单判断向下弹出,但是最终弹出超出窗口下边界的情形的处理
selectupFlag = true;
topTemp -= (dlElem.outerHeight() + (2 * parseFloat(dlElem.css('top')) - titleElem.outerHeight()));
}
return {
top: topTemp,
left: leftTemp
};
}
var dlPosition = getDlPosition();
titleElem.css({backgroundColor: 'transparent'});
window.top.layer._indexTemp[modelName] = window.top.layer.open({
type: 1,
title: false,
closeBtn: 0,
shade: 0,
anim: -1,
fixed: titleElem.closest('.layui-layer-content').length || window.top !== window.self,
isOutAnim: false,
// offset: [topTemp + 'px', leftTemp + 'px'],
offset: [dlPosition.top + 'px', dlPosition.left + 'px'],
// area: [dlElem.outerWidth() + 'px', dlElem.outerHeight() + 'px'],
area: dlElem.outerWidth() + 'px',
content: '<div class="layui-unselect layui-form-select layui-form-selected"></div>',
skin: 'layui-option-layer',
success: function (layero, index) {
dlElem.css({
top: 0,
position: 'relative'
}).appendTo(layero.find('.layui-layer-content').css({overflow: 'hidden'}).find('.layui-form-selected'));
layero.width(titleElem.width());
// 原本的做法在ie下获得的是auto其他的浏览器却是确定的值,目前简单处理,先自行计算出来,后面再调优
var bottom_computed = window.top.innerHeight - layero.outerHeight() - parseFloat(layero.css('top'));
selectupFlag && (layero.css({top: 'auto', bottom: bottom_computed + 'px'}));
// 调用各自的success回调
typeof options.success === 'function' && options.success.call(this, index, layero);
// 通用的事件处理
layero.on('mousedown', function (event) {
layui.stope(event);
});
setTimeout(function () {
// 延迟500毫秒添加事件处理,应对ie浏览器下某一些特定场景下点击select出来option的时候回有一个容器滚动导致直接关闭选项的问题
// 不包含selectors的选择器的节点
titleElem.parentsUntil(selectors.join(',')).one('scroll', function (event) {
// 用window.top.layer去弹出的选项在其title所在的容器滚动的时候都关闭
close();
});
// 单独给选择器的节点加上
titleElem.parents(selectors.join(',')).one('scroll', function (event) {
// 用window.top.layer去弹出的选项在其title所在的容器滚动的时候都关闭
close();
});
var windowTemp = window;
do {
var $Temp = windowTemp.$ || windowTemp.layui.$;
if ($Temp) {
// 点击document的时候触发
$Temp(windowTemp.document).one('click', function (event) {
close();
});
$Temp(windowTemp.document).one('mousedown', function (event) {
close();
});
// 窗口resize的时候关掉表格中的下拉
$Temp(windowTemp).one('resize', function (event) {
close();
});
// 监听滚动在必要的时候关掉select的选项弹出(主要是在多级的父子页面的时候)
$Temp(windowTemp.document).one('scroll', function () {
if (top !== self && parent.parent) {
// 多级嵌套的窗口就直接关掉了
close();
}
});
}
} while (windowTemp.self !== windowTemp.top ? windowTemp = windowTemp.parent : false);
}, 500);
},
end: function () {
typeof options.end === 'function' && options.end.call(this, selectElem);
}
});
});
};
// 内置初始化layui的select的效果,目前还不够晚上不提供给外部注册一些其他有类似问题的组件的处理
render('layuiSelect', {
triggerElem: 'div:not(.layui-select-disabled)>.layui-select-title', // 触发的选择器
success: function (index, layero) {
// layui 的select是单选点击一个的时候就关闭layer
layero.find('dl dd').click(function () {
close();
});
},
end: function (selectElem) {
form.render('select', null, selectElem);
}
});
return {
version: version,
getPosition: getPosition,
close: close
// render: render // 不完善,暂不对外提供
};
});
optimizeSelectOption .css
.layui-layer-content div.layui-form-select>div.layui-select-title+ dl,
.select_option_to_layer div.layui-form-select>div.layui-select-title+ dl
{
visibility: hidden;
}
.layui-layer.layui-option-layer {
mso-border-shadow: no;
box-shadow: none;
}
最后 奉上一个很棒的demo:https://sun_zoro.gitee.io/layuitableplug/testTableCheckboxDisabled?v0.1.9