前言
我们在日常开发中对Excel的操作可能会比较频繁,好多功能都会涉及到Excel的操作。在.Net Core中大家可能使用Npoi比较多,这款软件功能也十分强大,而且接近原始编程。但是直接使用Npoi大部分时候我们可能都会自己封装一下,毕竟根据二八原则,我们百分之八十的场景可能都是进行简单的导入导出操作,这里就引出我们的主角Npoi。
NPOI简介
NPOI是指构建在POI 3.x版本之上的一个程序,NPOI可以在没有安装Office的情况下对Word或Excel文档进行读写操作。NPOI是一个开源的C#读写Excel、WORD等微软OLE2组件文档的项目。
一、安装相对应的程序包
在 .Net Core 中使用NPOI首先必须先安装NPOI;如下图所示:
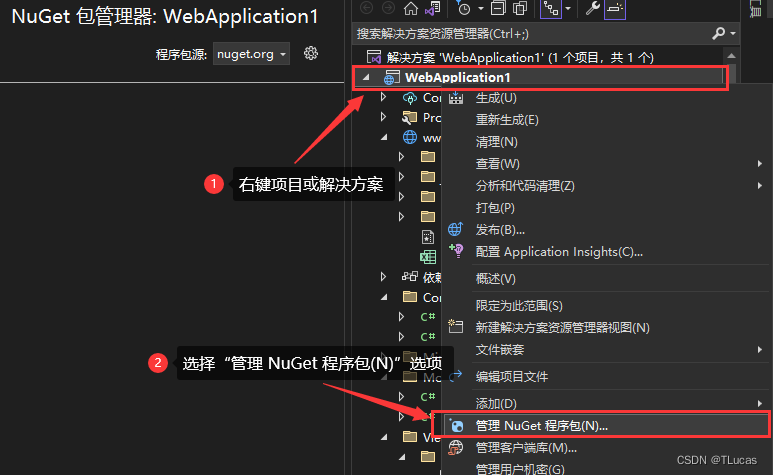
1.1、在 “管理NuGet程序包” 中的浏览搜索:“NPOI”

点击安装以上两个即可,安装完成之后最好重新编译一下项目以防出错。
二、新建Excel帮助类
在项目中新建“ExcelHelper”类;此类用于封装导入导出以及其他配置方法。代码如下:
using System;
using System.Collections.Generic;
using System.Data;
using System.IO;
using NPOI;
using System.Text;
using NPOI.HSSF.UserModel;
using NPOI.XSSF.UserModel;
using NPOI.SS.Formula.Eval;
using NPOI.SS.UserModel;
using NPOI.SS.Util;
using System.Text.RegularExpressions;
using System.Reflection;
using System.Collections;
using NPOI.HSSF.Util;
namespace WebApplication1
{
public static class ExcelHelper
{
public static SortedList ListColumnsName;
#region 从DataTable导出到excel文件中,支持xls和xlsx格式
#region 导出为xls文件内部方法
static MemoryStream ExportDT(string strFileName, DataTable dtSource, string strHeaderText, Dictionary<string, string> dir, int sheetnum)
{
IWorkbook workbook = new HSSFWorkbook();
using (Stream writefile = new FileStream(strFileName, FileMode.OpenOrCreate, FileAccess.Read))
{
if (writefile.Length > 0 && sheetnum > 0)
{
workbook = WorkbookFactory.Create(writefile);
}
}
ISheet sheet = null;
ICellStyle dateStyle = workbook.CreateCellStyle();
IDataFormat format = workbook.CreateDataFormat();
dateStyle.DataFormat = format.GetFormat("yyyy-mm-dd");
int[] arrColWidth = new int[dtSource.Columns.Count];
foreach (DataColumn item in dtSource.Columns)
{
arrColWidth[item.Ordinal] = Encoding.GetEncoding(936).GetBytes(Convert.ToString(item.ColumnName)).Length;
}
for (int i = 0; i < dtSource.Rows.Count; i++)
{
for (int j = 0; j < dtSource.Columns.Count; j++)
{
int intTemp = Encoding.GetEncoding(936).GetBytes(Convert.ToString(dtSource.Rows[i][j])).Length;
if (intTemp > arrColWidth[j])
{
arrColWidth[j] = intTemp;
}
}
}
int rowIndex = 0;
foreach (DataRow row in dtSource.Rows)
{
#region 新建表,填充表头,填充列头,样式
if (rowIndex == 0)
{
string sheetName = strHeaderText + (sheetnum == 0 ? "" : sheetnum.ToString());
if (workbook.GetSheetIndex(sheetName) >= 0)
{
workbook.RemoveSheetAt(workbook.GetSheetIndex(sheetName));
}
sheet = workbook.CreateSheet(sheetName);
#region 表头及样式
{
sheet.AddMergedRegion(new CellRangeAddress(0, 0, 0, dtSource.Columns.Count - 1));
IRow headerRow = sheet.CreateRow(0);
headerRow.HeightInPoints = 25;
headerRow.CreateCell(0).SetCellValue(strHeaderText);
ICellStyle headStyle = workbook.CreateCellStyle();
headStyle.Alignment = HorizontalAlignment.Center;
IFont font = workbook.CreateFont();
font.FontHeightInPoints = 20;
font.Boldweight = 700;
headStyle.SetFont(font);
headerRow.GetCell(0).CellStyle = headStyle;
rowIndex = 1;
}
#endregion
#region 列头及样式
if (rowIndex == 1)
{
IRow headerRow = sheet.CreateRow(1);
ICellStyle headStyle = workbook.CreateCellStyle();
headStyle.Alignment = HorizontalAlignment.Center;
IFont font = workbook.CreateFont();
font.FontHeightInPoints = 10;
font.Boldweight = 700;
headStyle.SetFont(font);
foreach (DataColumn column in dtSource.Columns)
{
headerRow.CreateCell(column.Ordinal).SetCellValue(dir[column.ColumnName]);
headerRow.GetCell(column.Ordinal).CellStyle = headStyle;
sheet.SetColumnWidth(column.Ordinal, (arrColWidth[column.Ordinal] + 1) * 256 * 2);
}
rowIndex = 2;
}
#endregion
}
#endregion
#region 填充内容
IRow dataRow = sheet.CreateRow(rowIndex);
foreach (DataColumn column in dtSource.Columns)
{
NPOI.SS.UserModel.ICell newCell = dataRow.CreateCell(column.Ordinal);
string drValue = row[column].ToString();
switch (column.DataType.ToString())
{
case "System.String":
double result;
if (isNumeric(drValue, out result))
{
double.TryParse(drValue, out result);
newCell.SetCellValue(result);
break;
}
else
{
newCell.SetCellValue(drValue);
break;
}
case "System.DateTime":
DateTime dateV;
DateTime.TryParse(drValue, out dateV);
newCell.SetCellValue(dateV);
newCell.CellStyle = dateStyle;
break;
case "System.Boolean":
bool boolV = false;
bool.TryParse(drValue, out boolV);
newCell.SetCellValue(boolV);
break;
case "System.Int16":
case "System.Int32":
case "System.Int64":
case "System.Byte":
int intV = 0;
int.TryParse(drValue, out intV);
newCell.SetCellValue(intV);
break;
case "System.Decimal":
case "System.Double":
double doubV = 0;
double.TryParse(drValue, out doubV);
newCell.SetCellValue(doubV);
break;
case "System.DBNull":
newCell.SetCellValue("");
break;
default:
newCell.SetCellValue(drValue.ToString());
break;
}
}
#endregion
rowIndex++;
}
using (MemoryStream ms = new MemoryStream())
{
workbook.Write(ms, true);
ms.Flush();
ms.Position = 0;
return ms;
}
}
#endregion
#region 导出为xlsx文件内部方法
static void ExportDTI(DataTable dtSource, string strHeaderText, FileStream fs, MemoryStream readfs, Dictionary<string, string> dir, int sheetnum)
{
IWorkbook workbook = new XSSFWorkbook();
if (readfs.Length > 0 && sheetnum > 0)
{
workbook = WorkbookFactory.Create(readfs);
}
ISheet sheet = null;
ICellStyle dateStyle = workbook.CreateCellStyle();
IDataFormat format = workbook.CreateDataFormat();
dateStyle.DataFormat = format.GetFormat("yyyy-mm-dd");
int[] arrColWidth = new int[dtSource.Columns.Count];
foreach (DataColumn item in dtSource.Columns)
{
arrColWidth[item.Ordinal] = Encoding.GetEncoding(936).GetBytes(Convert.ToString(item.ColumnName)).Length;
}
for (int i = 0; i < dtSource.Rows.Count; i++)
{
for (int j = 0; j < dtSource.Columns.Count; j++)
{
int intTemp = Encoding.GetEncoding(936).GetBytes(Convert.ToString(dtSource.Rows[i][j])).Length;
if (intTemp > arrColWidth[j])
{
arrColWidth[j] = intTemp;
}
}
}
int rowIndex = 0;
foreach (DataRow row in dtSource.Rows)
{
#region 新建表,填充表头,填充列头,样式
if (rowIndex == 0)
{
#region 表头及样式
{
string sheetName = strHeaderText + (sheetnum == 0 ? "" : sheetnum.ToString());
if (workbook.GetSheetIndex(sheetName) >= 0)
{
workbook.RemoveSheetAt(workbook.GetSheetIndex(sheetName));
}
sheet = workbook.CreateSheet(sheetName);
sheet.AddMergedRegion(new CellRangeAddress(0, 0, 0, dtSource.Columns.Count - 1));
IRow headerRow = sheet.CreateRow(0);
headerRow.HeightInPoints = 25;
headerRow.CreateCell(0).SetCellValue(strHeaderText);
ICellStyle headStyle = workbook.CreateCellStyle();
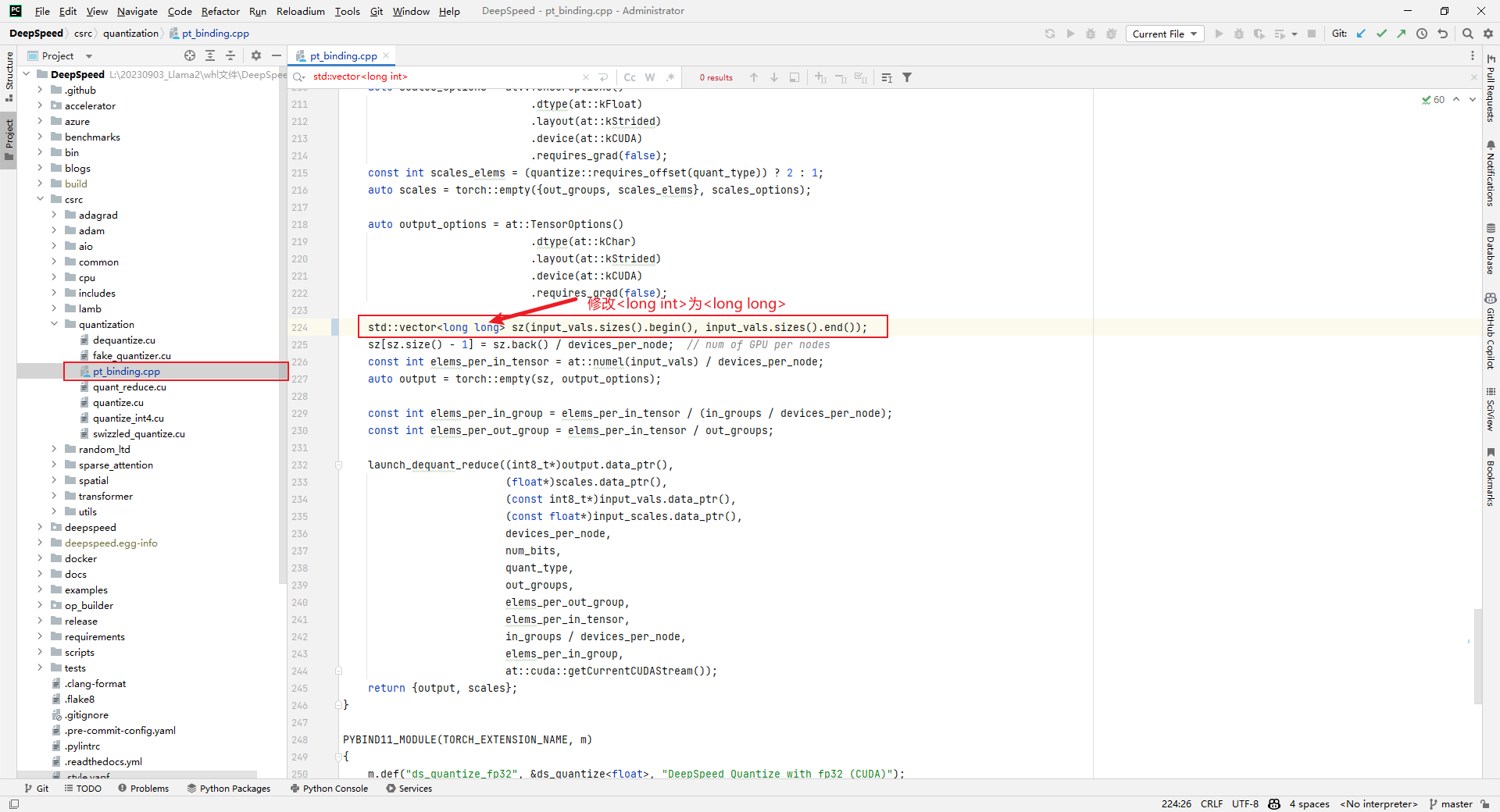
headStyle.Alignment = HorizontalAlignment.Center;
IFont font = workbook.CreateFont();
font.FontHeightInPoints = 20;
font.Boldweight = 700;
headStyle.SetFont(font);
headerRow.GetCell(0).CellStyle = headStyle;
}
#endregion
#region 列头及样式
{
IRow headerRow = sheet.CreateRow(1);
ICellStyle headStyle = workbook.CreateCellStyle();
headStyle.Alignment = HorizontalAlignment.Center;
IFont font = workbook.CreateFont();
font.FontHeightInPoints = 10;
font.Boldweight = 700;
headStyle.SetFont(font);
foreach (DataColumn column in dtSource.Columns)
{
headerRow.CreateCell(column.Ordinal).SetCellValue(dir[column.ColumnName]);
headerRow.GetCell(column.Ordinal).CellStyle = headStyle;
sheet.SetColumnWidth(column.Ordinal, (arrColWidth[column.Ordinal] + 1) * 256 * 2);
}
}
#endregion
rowIndex = 2;
}
#endregion
#region 填充内容
IRow dataRow = sheet.CreateRow(rowIndex);
foreach (DataColumn column in dtSource.Columns)
{
NPOI.SS.UserModel.ICell newCell = dataRow.CreateCell(column.Ordinal);
string drValue = row[column].ToString();
switch (column.DataType.ToString())
{
case "System.String":
double result;
if (isNumeric(drValue, out result))
{
double.TryParse(drValue, out result);
newCell.SetCellValue(result);
break;
}
else
{
newCell.SetCellValue(drValue);
break;
}
case "System.DateTime":
DateTime dateV;
DateTime.TryParse(drValue, out dateV);
newCell.SetCellValue(dateV);
newCell.CellStyle = dateStyle;
break;
case "System.Boolean":
bool boolV = false;
bool.TryParse(drValue, out boolV);
newCell.SetCellValue(boolV);
break;
case "System.Int16":
case "System.Int32":
case "System.Int64":
case "System.Byte":
int intV = 0;
int.TryParse(drValue, out intV);
newCell.SetCellValue(intV);
break;
case "System.Decimal":
case "System.Double":
double doubV = 0;
double.TryParse(drValue, out doubV);
newCell.SetCellValue(doubV);
break;
case "System.DBNull":
newCell.SetCellValue("");
break;
default:
newCell.SetCellValue(drValue.ToString());
break;
}
}
#endregion
rowIndex++;
}
workbook.Write(fs,true);
fs.Close();
}
#endregion
#region 导出excel表格
public static void ExportDTtoExcel(DataTable dtSource, string strHeaderText, string strFileName, Dictionary<string, string> dir, bool isNew, int sheetRow = 50000)
{
int currentSheetCount = GetSheetNumber(strFileName);
if (sheetRow <= 0)
{
sheetRow = dtSource.Rows.Count;
}
string[] temp = strFileName.Split('.');
string fileExtens = temp[temp.Length - 1];
int sheetCount = (int)Math.Ceiling((double)dtSource.Rows.Count / sheetRow);
if (temp[temp.Length - 1] == "xls" && dtSource.Columns.Count < 256 && sheetRow < 65536)
{
if (isNew)
{
currentSheetCount = 0;
}
for (int i = currentSheetCount; i < currentSheetCount + sheetCount; i++)
{
DataTable pageDataTable = dtSource.Clone();
int hasRowCount = dtSource.Rows.Count - sheetRow * (i - currentSheetCount) < sheetRow ? dtSource.Rows.Count - sheetRow * (i - currentSheetCount) : sheetRow;
for (int j = 0; j < hasRowCount; j++)
{
pageDataTable.ImportRow(dtSource.Rows[(i - currentSheetCount) * sheetRow + j]);
}
using (MemoryStream ms = ExportDT(strFileName, pageDataTable, strHeaderText, dir, i))
{
using (FileStream fs = new FileStream(strFileName, FileMode.Create, FileAccess.Write))
{
byte[] data = ms.ToArray();
fs.Write(data, 0, data.Length);
fs.Flush();
}
}
}
}
else
{
if (temp[temp.Length - 1] == "xls")
strFileName = strFileName + "x";
if (isNew)
{
currentSheetCount = 0;
}
for (int i = currentSheetCount; i < currentSheetCount + sheetCount; i++)
{
DataTable pageDataTable = dtSource.Clone();
int hasRowCount = dtSource.Rows.Count - sheetRow * (i - currentSheetCount) < sheetRow ? dtSource.Rows.Count - sheetRow * (i - currentSheetCount) : sheetRow;
for (int j = 0; j < hasRowCount; j++)
{
pageDataTable.ImportRow(dtSource.Rows[(i - currentSheetCount) * sheetRow + j]);
}
FileStream readfs = new FileStream(strFileName, FileMode.OpenOrCreate, FileAccess.Read);
MemoryStream readfsm = new MemoryStream();
readfs.CopyTo(readfsm);
readfs.Close();
using (FileStream writefs = new FileStream(strFileName, FileMode.Create, FileAccess.Write))
{
ExportDTI(pageDataTable, strHeaderText, writefs, readfsm, dir, i);
}
readfsm.Close();
}
}
}
public static XSSFWorkbook ExportExcel(DataTable dtSource, Dictionary<string, string> dir)
{
XSSFWorkbook excelWorkbook = new XSSFWorkbook();
int columnsCount = dir.Count;
if (columnsCount > 0)
{
ListColumnsName = new SortedList(new NoSort());
foreach (KeyValuePair<string,string> item in dir)
{
ListColumnsName.Add(item.Key, item.Value);
}
if (ListColumnsName == null || ListColumnsName.Count == 0)
{
throw (new Exception("请对ListColumnsName设置要导出的列明!"));
}
else
{
excelWorkbook = InsertRow(dtSource);
}
}
else
{
throw (new Exception("请对ListColumnsName设置要导出的列明!"));
}
return excelWorkbook;
}
#endregion
private static XSSFWorkbook CreateExcelFile()
{
XSSFWorkbook xssfworkbook = new XSSFWorkbook();
#region 文件属性信息
{
POIXMLProperties props = xssfworkbook.GetProperties();
props.CoreProperties.Creator = "Joy";
props.CoreProperties.Title = "";
props.CoreProperties.Description = "";
props.CoreProperties.Category = "";
props.CoreProperties.Subject = "";
props.CoreProperties.Created = DateTime.Now;
props.CoreProperties.Modified = DateTime.Now;
props.CoreProperties.SetCreated(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss"));
props.CoreProperties.LastModifiedByUser = "Joy";
props.CoreProperties.SetModified(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss"));
}
#endregion
return xssfworkbook;
}
private static void CreateHeader(XSSFSheet excelSheet, XSSFWorkbook excelWorkbook, XSSFCellStyle cellStyle)
{
int cellIndex = 0;
foreach (System.Collections.DictionaryEntry de in ListColumnsName)
{
XSSFRow newRow = (XSSFRow)excelSheet.CreateRow(0);
XSSFCellStyle? headTopStyle = CreateStyle(excelWorkbook, cellStyle,HorizontalAlignment.Center, VerticalAlignment.Center, 18, true, true, "宋体", true, false, false, true, FillPattern.SolidForeground, HSSFColor.Grey25Percent.Index, HSSFColor.Black.Index,FontUnderlineType.None, FontSuperScript.None, false);
XSSFCell newCell = (XSSFCell)newRow.CreateCell(cellIndex);
newCell.SetCellValue(de.Value.ToString());
newCell.CellStyle = headTopStyle;
cellIndex++;
}
}
private static XSSFWorkbook InsertRow(DataTable dtSource)
{
XSSFWorkbook excelWorkbook = CreateExcelFile();
int rowCount = 0;
int sheetCount = 1;
XSSFSheet newsheet = null;
newsheet = (XSSFSheet)excelWorkbook.CreateSheet("Sheet" + sheetCount);
XSSFCellStyle headCellStyle = (XSSFCellStyle)excelWorkbook.CreateCellStyle();
CreateHeader(newsheet, excelWorkbook, headCellStyle);
foreach (DataRow dr in dtSource.Rows)
{
rowCount++;
if (rowCount == 10000)
{
rowCount = 1;
sheetCount++;
newsheet = (XSSFSheet)excelWorkbook.CreateSheet("Sheet" + sheetCount);
CreateHeader(newsheet, excelWorkbook, headCellStyle);
}
XSSFRow newRow = (XSSFRow)newsheet.CreateRow(rowCount);
XSSFCellStyle cellStyle = (XSSFCellStyle)excelWorkbook.CreateCellStyle();
XSSFCellStyle? style = CreateStyle(excelWorkbook, cellStyle, HorizontalAlignment.Center, VerticalAlignment.Center, 14, true, false);
InsertCell(dtSource, dr, newRow, style, excelWorkbook);
}
return excelWorkbook;
}
private static void InsertCell(DataTable dtSource, DataRow drSource, XSSFRow currentExcelRow, XSSFCellStyle cellStyle, XSSFWorkbook excelWorkBook)
{
for (int cellIndex = 0; cellIndex < ListColumnsName.Count; cellIndex++)
{
string columnsName = ListColumnsName.GetKey(cellIndex).ToString();
XSSFCell newCell = null;
System.Type rowType = drSource[columnsName].GetType();
string drValue = drSource[columnsName].ToString().Trim();
switch (rowType.ToString())
{
case "System.String":
drValue = drValue.Replace("&", "&");
drValue = drValue.Replace(">", ">");
drValue = drValue.Replace("<", "<");
newCell = (XSSFCell)currentExcelRow.CreateCell(cellIndex);
newCell.SetCellValue(drValue);
newCell.CellStyle = cellStyle;
break;
case "System.DateTime":
DateTime dateV;
DateTime.TryParse(drValue, out dateV);
newCell = (XSSFCell)currentExcelRow.CreateCell(cellIndex);
newCell.SetCellValue(dateV);
newCell.CellStyle = cellStyle;
break;
case "System.Boolean":
bool boolV = false;
bool.TryParse(drValue, out boolV);
newCell = (XSSFCell)currentExcelRow.CreateCell(cellIndex);
newCell.SetCellValue(boolV);
newCell.CellStyle = cellStyle;
break;
case "System.Int16":
case "System.Int32":
case "System.Int64":
case "System.Byte":
int intV = 0;
int.TryParse(drValue, out intV);
newCell = (XSSFCell)currentExcelRow.CreateCell(cellIndex);
newCell.SetCellValue(intV.ToString());
newCell.CellStyle = cellStyle;
break;
case "System.Decimal":
case "System.Double":
double doubV = 0;
double.TryParse(drValue, out doubV);
newCell = (XSSFCell)currentExcelRow.CreateCell(cellIndex);
newCell.SetCellValue(doubV);
newCell.CellStyle = cellStyle;
break;
case "System.DBNull":
newCell = (XSSFCell)currentExcelRow.CreateCell(cellIndex);
newCell.SetCellValue("");
newCell.CellStyle = cellStyle;
break;
default:
throw (new Exception(rowType.ToString() + ":类型数据无法处理!"));
}
}
}
public static XSSFCellStyle CreateStyle(XSSFWorkbook workbook, XSSFCellStyle cellStyle, HorizontalAlignment hAlignment, VerticalAlignment vAlignment, short fontHeightInPoints, bool isAddBorder, bool boldWeight, string fontName = "宋体", bool isAddBorderColor = true, bool isItalic = false, bool isLineFeed = true, bool isAddCellBackground = false, FillPattern fillPattern = FillPattern.NoFill, short cellBackgroundColor = HSSFColor.Yellow.Index, short fontColor = HSSFColor.Black.Index, FontUnderlineType underlineStyle =
FontUnderlineType.None, FontSuperScript typeOffset = FontSuperScript.None, bool isStrikeout = false,string dataFormat="yyyy-MM-dd HH:mm:ss")
{
cellStyle.Alignment = hAlignment;
cellStyle.VerticalAlignment = vAlignment;
cellStyle.WrapText = isLineFeed;
XSSFDataFormat format = (XSSFDataFormat)workbook.CreateDataFormat();
cellStyle.DataFormat = format.GetFormat(dataFormat);
if (isAddCellBackground)
{
cellStyle.FillForegroundColor = cellBackgroundColor;
cellStyle.FillPattern = fillPattern;
}
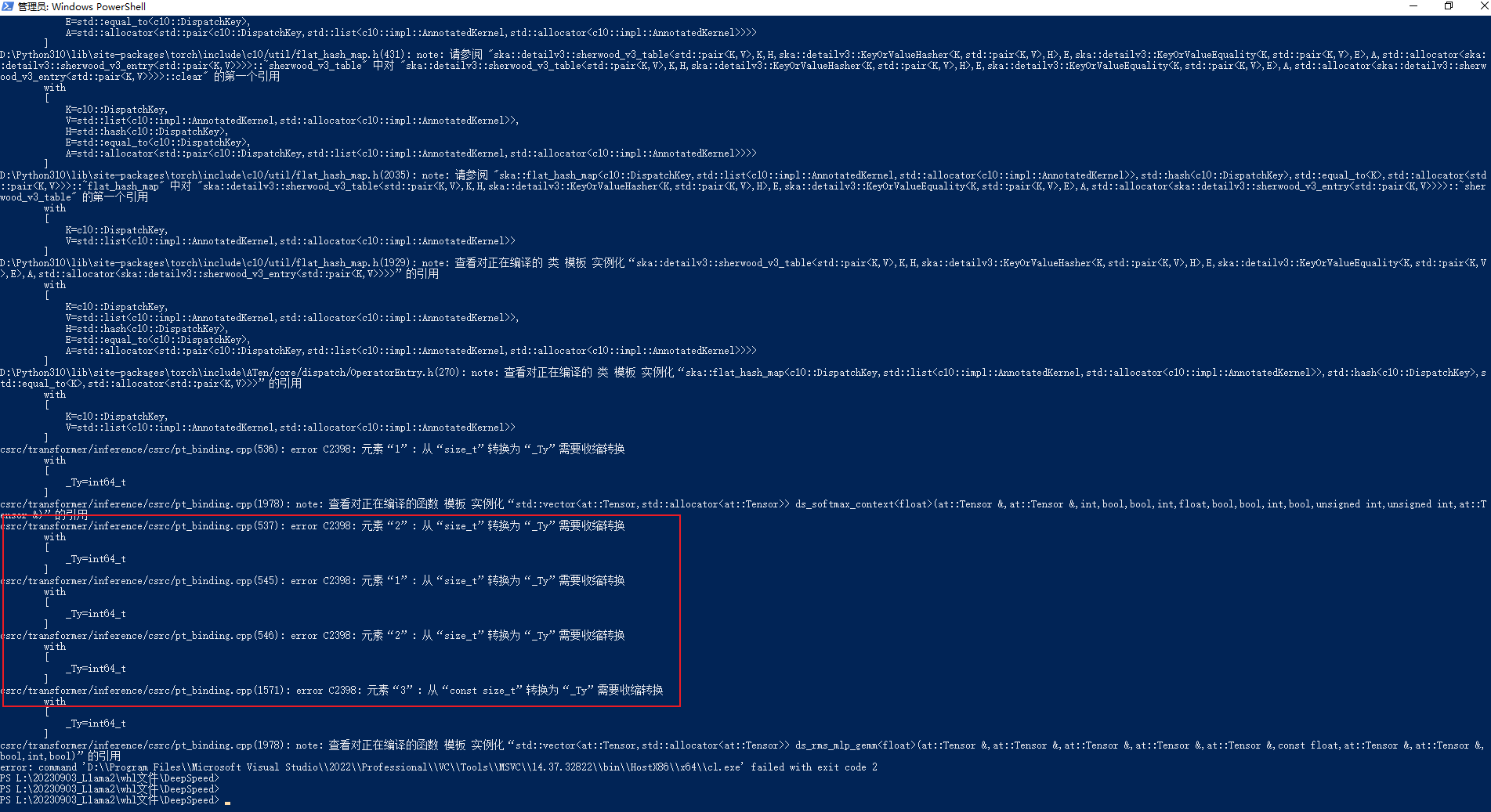
else
{
cellStyle.FillForegroundColor = HSSFColor.White.Index;
}
if (isAddBorder)
{
cellStyle.BorderBottom = BorderStyle.Thin;
cellStyle.BorderRight = BorderStyle.Thin;
cellStyle.BorderTop = BorderStyle.Thin;
cellStyle.BorderLeft = BorderStyle.Thin;
}
if (isAddBorderColor)
{
cellStyle.TopBorderColor = XSSFFont.DEFAULT_FONT_COLOR;
cellStyle.RightBorderColor = XSSFFont.DEFAULT_FONT_COLOR;
cellStyle.BottomBorderColor = XSSFFont.DEFAULT_FONT_COLOR;
cellStyle.LeftBorderColor = XSSFFont.DEFAULT_FONT_COLOR;
}
var cellStyleFont = (XSSFFont)workbook.CreateFont();
cellStyleFont.IsBold = boldWeight;
cellStyleFont.FontHeightInPoints = fontHeightInPoints;
cellStyleFont.FontName = fontName;
cellStyleFont.Color = fontColor;
cellStyleFont.IsItalic = isItalic;
cellStyleFont.Underline = underlineStyle;
cellStyleFont.TypeOffset = typeOffset;
cellStyleFont.IsStrikeout = isStrikeout;
cellStyle.SetFont(cellStyleFont);
return cellStyle;
}
#endregion
#region 从excel文件中将数据导出到List<T>对象集合
static DataTable ImportDt(ISheet sheet, int HeaderRowIndex, Dictionary<string, string> dir)
{
DataTable table = new DataTable();
IRow headerRow;
int cellCount;
try
{
if (HeaderRowIndex < 0)
{
headerRow = sheet.GetRow(0);
cellCount = headerRow.LastCellNum;
for (int i = headerRow.FirstCellNum; i <= cellCount; i++)
{
DataColumn column = new DataColumn(Convert.ToString(i));
table.Columns.Add(column);
}
}
else
{
headerRow = sheet.GetRow(HeaderRowIndex);
cellCount = headerRow.LastCellNum;
for (int i = headerRow.FirstCellNum; i <cellCount; i++)
{
if (headerRow.GetCell(i) == null)
{
if (table.Columns.IndexOf(Convert.ToString(i)) > 0)
{
DataColumn column = new DataColumn(Convert.ToString("重复列名" + i));
table.Columns.Add(column);
}
else
{
DataColumn column = new DataColumn(Convert.ToString(i));
table.Columns.Add(column);
}
}
else if (table.Columns.IndexOf(headerRow.GetCell(i).ToString()) > 0)
{
DataColumn column = new DataColumn(Convert.ToString("重复列名" + i));
table.Columns.Add(column);
}
else
{
string aaa = headerRow.GetCell(i).ToString();
string colName = dir.Where(s => s.Value == headerRow.GetCell(i).ToString()).First().Key;
DataColumn column = new DataColumn(colName);
table.Columns.Add(column);
}
}
}
int rowCount = sheet.LastRowNum;
for (int i = (HeaderRowIndex + 1); i <= sheet.LastRowNum; i++)
{
try
{
IRow row;
if (sheet.GetRow(i) == null)
{
row = sheet.CreateRow(i);
}
else
{
row = sheet.GetRow(i);
}
DataRow dataRow = table.NewRow();
for (int j = row.FirstCellNum; j <= cellCount; j++)
{
try
{
if (row.GetCell(j) != null)
{
switch (row.GetCell(j).CellType)
{
case CellType.String:
string str = row.GetCell(j).StringCellValue;
if (str != null && str.Length > 0)
{
dataRow[j] = str.ToString();
}
else
{
dataRow[j] = default(string);
}
break;
case CellType.Numeric:
if (DateUtil.IsCellDateFormatted(row.GetCell(j)))
{
dataRow[j] = DateTime.FromOADate(row.GetCell(j).NumericCellValue);
}
else
{
dataRow[j] = Convert.ToDouble(row.GetCell(j).NumericCellValue);
}
break;
case CellType.Boolean:
dataRow[j] = Convert.ToString(row.GetCell(j).BooleanCellValue);
break;
case CellType.Error:
dataRow[j] = ErrorEval.GetText(row.GetCell(j).ErrorCellValue);
break;
case CellType.Formula:
switch (row.GetCell(j).CachedFormulaResultType)
{
case CellType.String:
string strFORMULA = row.GetCell(j).StringCellValue;
if (strFORMULA != null && strFORMULA.Length > 0)
{
dataRow[j] = strFORMULA.ToString();
}
else
{
dataRow[j] = null;
}
break;
case CellType.Numeric:
dataRow[j] = Convert.ToString(row.GetCell(j).NumericCellValue);
break;
case CellType.Boolean:
dataRow[j] = Convert.ToString(row.GetCell(j).BooleanCellValue);
break;
case CellType.Error:
dataRow[j] = ErrorEval.GetText(row.GetCell(j).ErrorCellValue);
break;
default:
dataRow[j] = "";
break;
}
break;
default:
dataRow[j] = "";
break;
}
}
}
catch (Exception exception)
{
}
}
table.Rows.Add(dataRow);
}
catch (Exception exception)
{
}
}
}
catch (Exception exception)
{
}
return table;
}
public static List<TResult> DataTableToList<TResult>(this DataTable dt) where TResult : class, new()
{
List<PropertyInfo> prlist = new List<PropertyInfo>();
Type t = typeof(TResult);
Array.ForEach<PropertyInfo>(t.GetProperties(), p => { if (dt.Columns.IndexOf(p.Name) != -1) prlist.Add(p); });
List<TResult> oblist = new List<TResult>();
foreach (DataRow row in dt.Rows)
{
TResult ob = new TResult();
prlist.ForEach(p => { if (row[p.Name] != DBNull.Value) p.SetValue(ob, row[p.Name], null); });
oblist.Add(ob);
}
return oblist;
}
private static List<T> DataTableToList<T>(DataTable dt, bool isStoreDB = true)
{
List<T> list = new List<T>();
Type type = typeof(T);
PropertyInfo[] pArray = type.GetProperties();
foreach (DataRow row in dt.Rows)
{
T entity = Activator.CreateInstance<T>();
foreach (PropertyInfo p in pArray)
{
if (!dt.Columns.Contains(p.Name) || row[p.Name] == null || row[p.Name] == DBNull.Value)
{
continue;
}
if (isStoreDB && p.PropertyType == typeof(DateTime) && Convert.ToDateTime(row[p.Name]) < Convert.ToDateTime("1753-01-01"))
{
continue;
}
try
{
var obj = Convert.ChangeType(row[p.Name], p.PropertyType);
p.SetValue(entity, obj, null);
}
catch (Exception)
{
}
}
list.Add(entity);
}
return list;
}
private static List<T> DataTable2List<T>(DataTable dt)
{
if (dt == null || dt.Rows.Count <= 0)
{
return null;
}
IList<T> list = new List<T>();
PropertyInfo[] tMembersAll = typeof(T).GetProperties();
for (int i = 0; i < dt.Rows.Count; i++)
{
T t = Activator.CreateInstance<T>();
for (int j = 0; j < dt.Columns.Count; j++)
{
foreach (PropertyInfo tMember in tMembersAll)
{
if (dt.Columns[j].ColumnName.ToUpper().Equals(tMember.Name.ToUpper()))
{
if (dt.Rows[i][j] != DBNull.Value)
{
tMember.SetValue(t, Convert.ToString(dt.Rows[i][j]), null);
}
else
{
tMember.SetValue(t, null, null);
}
break;
}
}
}
list.Add(t);
}
dt.Dispose();
return list.ToList();
}
public static List<T> ImportExceltoDt<T>(string strFileName, Dictionary<string, string> dir, string SheetName, int HeaderRowIndex = 0)
{
DataTable table = new DataTable();
using (FileStream file = new FileStream(strFileName, FileMode.Open, FileAccess.Read))
{
if (file.Length > 0)
{
IWorkbook wb = WorkbookFactory.Create(file);
ISheet isheet = wb.GetSheet(SheetName);
table = ImportDt(isheet, HeaderRowIndex, dir);
isheet = null;
}
}
List<T> results = DataTableToList<T>(table);
table.Dispose();
return results;
}
public static List<T> ImportExceltoDt<T>(string strFileName, Dictionary<string, string> dir, int HeaderRowIndex = 0, int SheetIndex = 0)
{
DataTable table = new DataTable();
using (FileStream file = new FileStream(strFileName, FileMode.Open, FileAccess.Read))
{
if (file.Length > 0)
{
IWorkbook wb = WorkbookFactory.Create(file);
ISheet isheet = wb.GetSheetAt(SheetIndex);
table = ImportDt(isheet, HeaderRowIndex, dir);
isheet = null;
}
}
List<T> results = DataTableToList<T>(table);
table.Dispose();
return results;
}
#endregion
public static int GetSheetNumber(string outputFile)
{
int number = 0;
using (FileStream readfile = new FileStream(outputFile, FileMode.OpenOrCreate, FileAccess.Read))
{
if (readfile.Length > 0)
{
IWorkbook wb = WorkbookFactory.Create(readfile);
number = wb.NumberOfSheets;
}
}
return number;
}
public static bool isNumeric(String message, out double result)
{
Regex rex = new Regex(@"^[-]?\d+[.]?\d*$");
result = -1;
if (rex.IsMatch(message))
{
result = double.Parse(message);
return true;
}
else
return false;
}
public static bool HasData(Stream excelFileStream)
{
using (excelFileStream)
{
IWorkbook workBook = new HSSFWorkbook(excelFileStream);
if (workBook.NumberOfSheets > 0)
{
ISheet sheet = workBook.GetSheetAt(0);
return sheet.PhysicalNumberOfRows > 0;
}
}
return false;
}
}
public class NoSort : IComparer
{
public int Compare(object x, object y)
{
return -1;
}
}
}
三、调用
3.1、增加一个“keywords”模型类,用作导出
public class keywords
{
[Column("姓名")]
public string IllegalKeywords { get; set; }
}
3.2、添加一个控制器
3.3、编写导入导出的控制器代码
3.3.1、重写“Close”函数
在导出时,为了防止MemoryStream无法关闭从而报错,所以我们继承MemoryStream;代码如下:
namespace WebApplication1
{
public class NpoiMemoryStream : MemoryStream
{
public NpoiMemoryStream()
{
AllowClose = true;
}
public bool AllowClose { get; set; }
public override void Close()
{
if (AllowClose)
base.Close();
}
}
}
3.3.2、添加控制器代码
private IHostingEnvironment _hostingEnv;
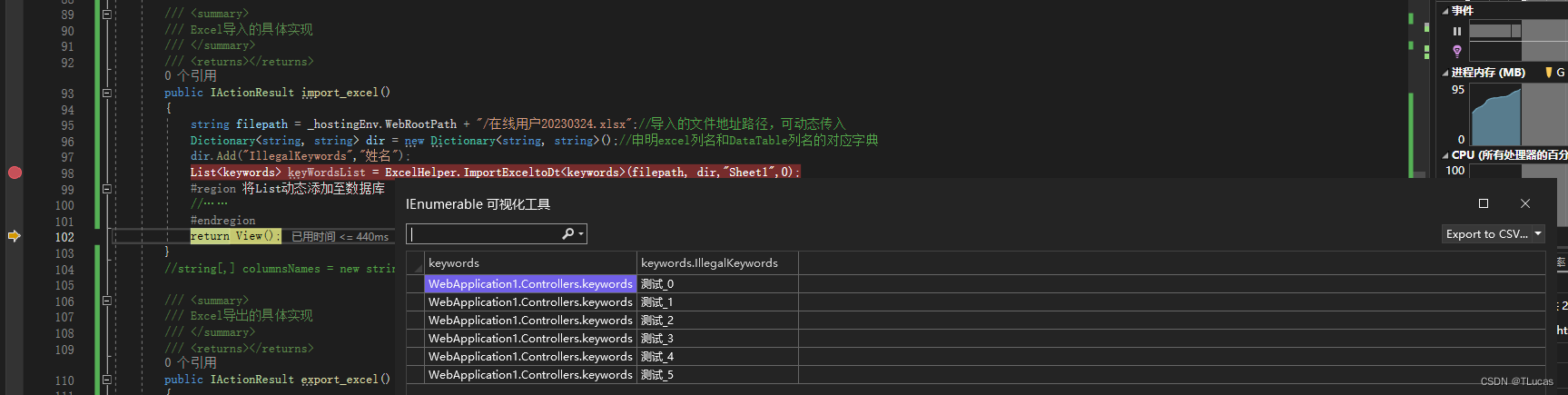
public IActionResult import_excel()
{
string filepath = _hostingEnv.WebRootPath + "/在线用户20230324.xlsx";
Dictionary<string, string> dir = new Dictionary<string, string>();
dir.Add("IllegalKeywords","姓名");
List<keywords> keyWordsList = ExcelHelper.ImportExceltoDt<keywords>(filepath, dir,"Sheet1",0);
#region 将List动态添加至数据库
#endregion
return Json(new { code = 200, msg = "导入成功" });
}
public IActionResult export_excel()
{
#region 添加测试数据
List<keywords> keys = new List<keywords>();
for (int i = 0; i < 6; i++)
{
keywords keyword = new keywords();
keyword.IllegalKeywords = "测试_" + i;
keys.Add(keyword);
}
#endregion
#region 实例化DataTable并进行赋值
DataTable dt = new DataTable();
dt = listToDataTable(keys);
#endregion
string filename = DateTime.Now.ToString("在线用户yyyyMMdd") + ".xlsx";
Dictionary<string, string> dir = new Dictionary<string, string>();
dir.Add("IllegalKeywords", "姓名");
XSSFWorkbook book= ExcelHelper.ExportExcel(dt, dir);
dt.Dispose();
NpoiMemoryStream ms = new NpoiMemoryStream();
ms.AllowClose = false;
book.Write(ms, true);
ms.Flush();
ms.Position = 0;
ms.Seek(0, SeekOrigin.Begin);
ms.AllowClose = true;
book.Dispose();
return File(ms, "application/vnd.ms-excel", Path.GetFileName(filename));
}
3.3.3、Excel导出效果
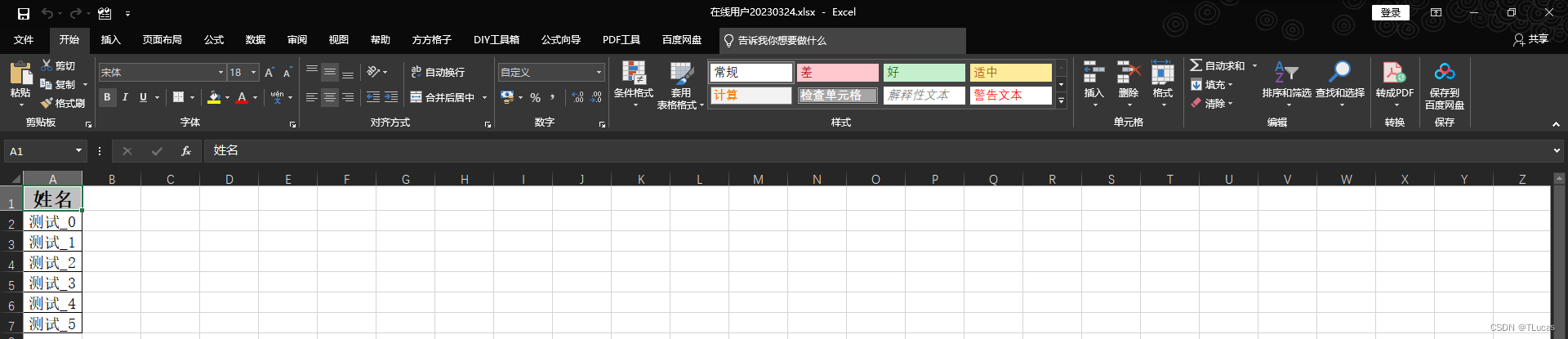
3.3.4、Excel导入效果
导入后的List再根据需求调用添加方法实现数据的添加