来源: 产品代码都给你看了,可别再说不会DDD(五):请求处理流程 | 码如云文档中心
这是一个讲解DDD落地的文章系列,作者是《实现领域驱动设计》的译者滕云。本文章系列以一个真实的并已成功上线的软件项目——码如云(https://www.mryqr.com)为例,系统性地讲解DDD在落地实施过程中的各种典型实践,以及在面临实际业务场景时的诸多取舍。

本系列包含以下文章:
案例项目介绍 #
既然DDD是“领域”驱动,那么我们便不能抛开业务而只讲技术,为此让我们先从业务上了解一下贯穿本文章系列的案例项目 —— 码如云(不是马云,也不是码云)。如你已经在本系列的其他文章中了解过该案例,可跳过。
码如云是一个基于二维码的一物一码管理平台,可以为每一件“物品”生成一个二维码,并以该二维码为入口展开对“物品”的相关操作,典型的应用场景包括固定资产管理、设备巡检以及物品标签等。
在使用码如云时,首先需要创建一个应用(App),一个应用包含了多个页面(Page),也可称为表单,一个页面又可以包含多个控件(Control),比如单选框控件。应用创建好后,可在应用下创建多个实例(QR)用于表示被管理的对象(比如机器设备)。每个实例均对应一个二维码,手机扫码便可对实例进行相应操作,比如查看实例相关信息或者填写页面表单等,对表单的一次填写称为提交(Submission);更多概念请参考码如云术语。
在技术上,码如云是一个无代码平台,包含了表单引擎、审批流程和数据报表等多个功能模块。码如云全程采用DDD完成开发,其后端技术栈主要有Java、Spring Boot和MongoDB等。
码如云的源代码是开源的,可以通过以下方式访问:
请求处理流程 #
在上一篇代码工程结构中,我们从宏观层面讲到了DDD项目的目录结构,但并未触及到实际的代码。在本文中,我们将深入到代码中,逐一讲解DDD中对各种请求类型的典型处理流程。
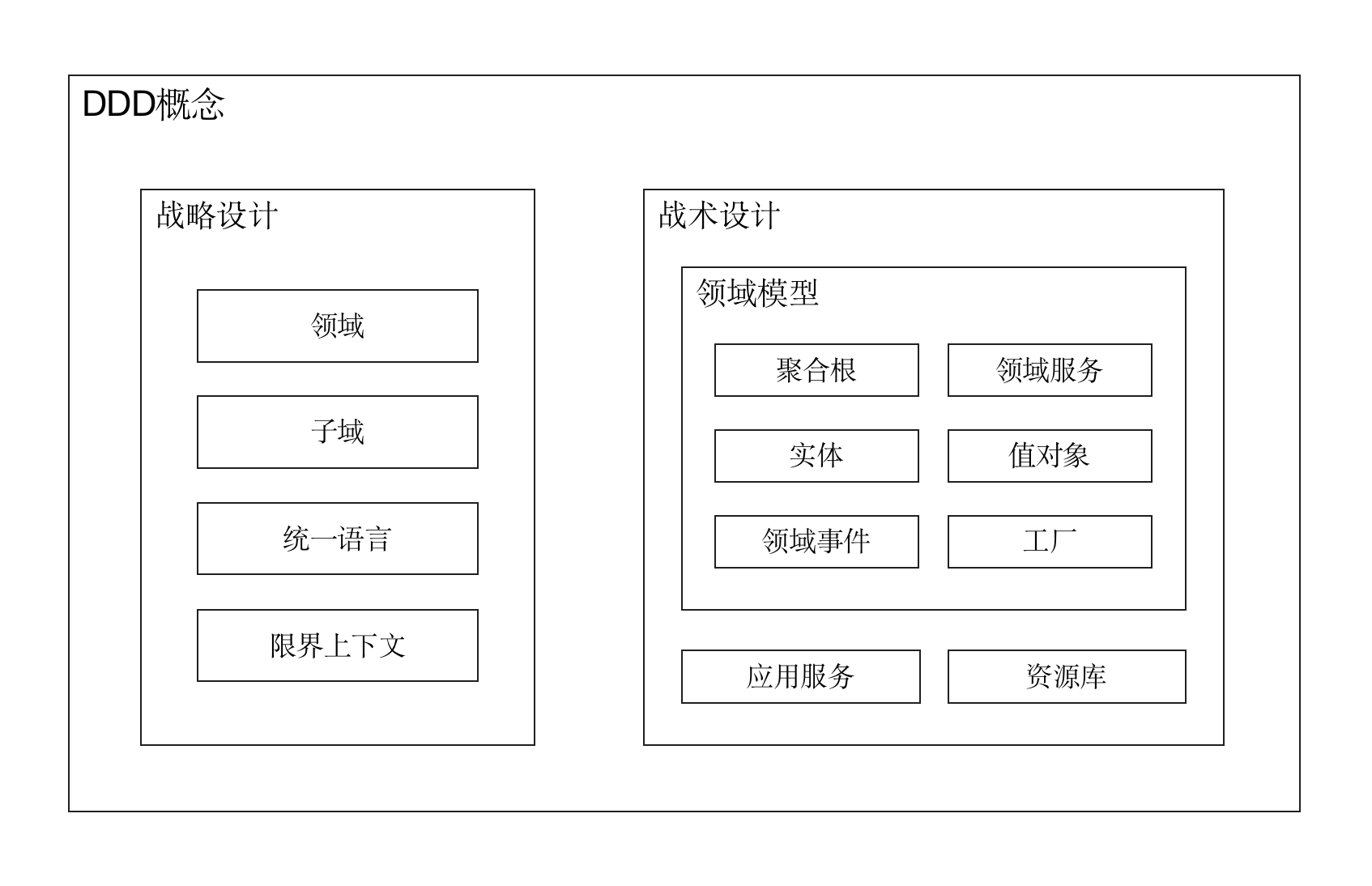
在本系列的DDD概念大白话我们提到,DDD中的所有组件都是围绕着聚合根展开的,其中有些本身即是聚合根的一部分,比如实体和值对象;有些是聚合根的客户,比如应用服务;有些则是对聚合根的辅助或补充,比如领域服务和工厂。反观当下流行的各种软件架构,无论是分层架构、六边形架构还是整洁架构,它们都有一个共同点,即在架构中心都有一个核心存在,这个核心正是领域模型,而DDD的聚合根则存在于领域模型之中。
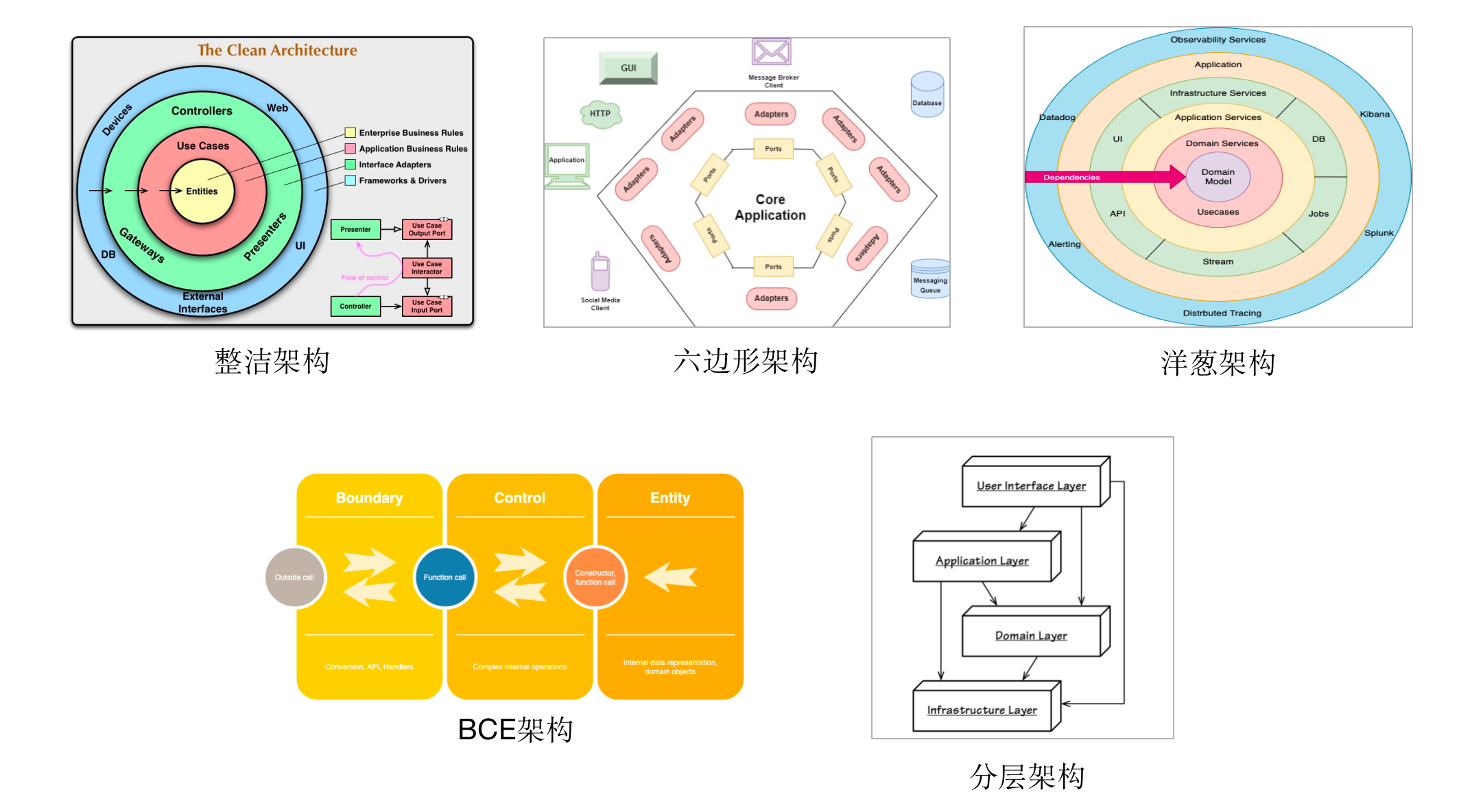
不难看出,既然每种架构中都有为领域模型预留的位置,这也意味着DDD可采用任何一种软件架构。事实也的确如此,DDD并不要求采用哪种特定架构,如果你真要说DDD项目应该采用某种架构的话,那么应该“以领域模型为中心的软件架构”。
如果我们把软件系统当做一个黑盒的话,其外界是各种形态的客户端,比如浏览器,手机APP或者第三方调用方等,盒子内部则是我们精心构建的领域模型。不过,领域模型是不能直接被外界访问的,主要原因有以下两点:
- 客户端的演进和领域模型的演进是不同步的,比如网页端所需要展示的信息量比手机端更多,但是他们所使用的领域模型却是相同的,因此在建模时我们通常会将领域模型和客户端解耦开来,以利于各自的建模和演进
- 软件除了处理领域模型这种业务复杂度之外,还需要处理技术复杂度,以及业务和技术的衔接复杂度,比如有些请求通过HTTP协议完成,而有些则通过RPC完成,因此除了领域模型,我们还需要适配各种形式的外部客户端
接下来,让我们来看看DDD项目是如何衔接外部请求和内部领域模型的。既然聚合根是领域模型中的一等公民,那么按照对聚合根的操作类型不同,DDD项目中主要存在以下4种类型的请求:
- 聚合根创建流程
- 聚合根更新流程
- 聚合根删除流程
- 查询流程
咋一看,你可能会说这不就是CRUD么?本质上这的确是CRUD,但是这里的CRUD可不是仅仅操作数据库那么简单,你如果阅览过本系列的上一篇代码工程结构的话,便知道在码如云中领域模型的代码量占比远远高出数据库访问相关的代码量。
本文主要讲解DDD对请求的处理流程,并不讲解聚合根本身的设计和实现,而是假设聚合根(以及领域模型中的工厂和领域服务等)已经实现就位了,关于聚合根本身的讲解请参考本系列的聚合根与资源库一文。此外,为了突出重点,本文只着重讲解请求处理流程的主干,而忽略与之关系不大的其他细节,比如我们将忽略应用服务中的事务处理和权限管理等功能,为此读者可参考应用服务与领域服务。
聚合根创建流程 #
聚合根的创建通常通过工厂类完成,请求流经路线为:控制器(Controller) -> 应用服务(Application Service) -> 工厂(Factory) -> 资源库(Repository)。
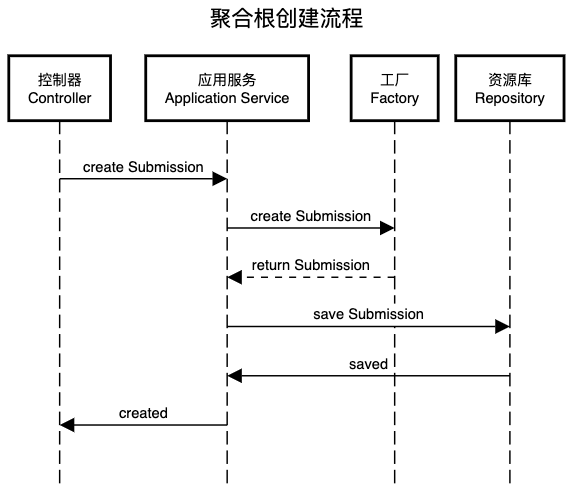
在码如云中,当用户提交表单后,系统后台将创建一份提交(Submission),这里的Submission便是一个聚合根对象。在整个“创建Submission”的处理流程中,请求先通过HTTP协议到达Spring MVC中的Controller:
//SubmissionController
@PostMapping
@ResponseStatus(CREATED)
public ReturnId newSubmission(@RequestBody @Valid NewSubmissionCommand command,
@AuthenticationPrincipal User user) {
String submissionId = submissionCommandService.newSubmission(command, user);
return returnId(submissionId);
}
Controller的作用只是为了衔接技术和业务,因此其逻辑应该相对简单,在本例中,SubmissionController的newSubmission()方法仅仅将请求代理给应用服务SubmissionCommandService即完成了其自身的使命。这里的NewSubmissionCommand表示命令对象,用于携带请求数据,比如对于“创建Submission”来说,NewSubmissionCommand对象中至少应该包含表单的提交内容等数据。命令对象是外部客户端传入的数据,因此需要将其与领域模型解耦,也即命令对象不能进入到领域模型的内部,其所能到达的最后一站是应用服务。
处理流程的下一站是应用服务,应用服务是整个领域模型的门面,无论什么类型的客户端,只要业务用例相同,那么所调用的应用服务的方法也应相同,也即应用服务和技术设施也是解耦的。
//SubmissionCommandService
@Transactional
public String newSubmission(NewSubmissionCommand command, User user) {
AppedQr appedQr = qrRepository.appedQrById(command.getQrId());
App app = appedQr.getApp();
QR qr = appedQr.getQr();
Page page = app.pageById(command.getPageId());
SubmissionPermissions permissions = permissionChecker.permissionsFor(user, appedQr);
permissions.checkPermissions(app.requiredPermission(), page.requiredPermission());
Set<Answer> answers = command.getAnswers();
Submission submission = submissionFactory.createNewSubmission(
answers,
qr,
page,
app,
permissions.getPermissions(),
command.getReferenceData(),
user
);
submissionRepository.houseKeepSave(submission, app);
log.info("Created submission[{}].", submission.getId());
return submission.getId();
}
源码出处:com/mryqr/core/submission/command/SubmissionCommandService.java
在以上的SubmissionCommandService应用服务中,首先做权限检查,然后调用工厂SubmissionFactory.createNewSubmission()完成Submission的创建,最后调用资源库SubmissionRepository.houseKeepSave()将新建的Submission持久化到数据库中。从中可见,应用服务主要用于协调各方以完成一个业务用例,其本身并不包含业务逻辑,业务逻辑在工厂中完成。
//SubmissionFactory
public Submission createNewSubmission(Set<Answer> answers,
QR qr,
Page page,
App app,
Set<Permission> permissions,
String referenceData,
User user) {
if (page.isOncePerInstanceSubmitType()) {
submissionRepository.lastInstanceSubmission(qr.getId(), page.getId())
.ifPresent(submission -> {
throw new MryException(SUBMISSION_ALREADY_EXISTS_FOR_INSTANCE,
"当前页面不支持重复提交,请尝试更新已有表单。",
mapOf("qrId", qr.getId(),
"pageId", page.getId()));
});
}
//...此处忽略更多业务逻辑
//只有需要登录的页面才记录user
User finalUser = page.requireLogin() ? user : ANONYMOUS_USER;
Map<String, Answer> checkedAnswers = submissionDomainService.checkAnswers(answers,
qr,
page,
app,
permissions);
return new Submission(checkedAnswers,
page.getId(),
qr, app,
referenceData,
finalUser);
}
源码出处:com/mryqr/core/submission/domain/SubmissionFactory.java
虽然工厂用于创建聚合根,但并不是直接调用聚合根的构造函数那么简单,从SubmissionFactory.createNewSubmission()可以看出,在创建Submission之前,需要根据表单类型检查是否可以创建新的Submission,而这正是业务逻辑的一部分。因此,工厂也属于领域模型的一部分,本质上工厂可以认为是一种特殊形式的领域服务。
请求流程的最后,应用服务调用资源库submissionRepository.houseKeepSave()完成对新建Submission的持久化。更多关于资源库的内容,请参考聚合根与资源库一文。
聚合根更新流程 #
对聚合根的更新流程通常可以通过“经典三部曲”完成:
- 调用资源库获得聚合根
- 调用聚合根上的业务方法,完成对聚合根的更新
- 再次调用资源库保存聚合根
此时的请求流经路线为:控制器(Controller) -> 应用服务(Application Service) -> 资源库(Repository) -> 聚合根(Aggregate Root)。
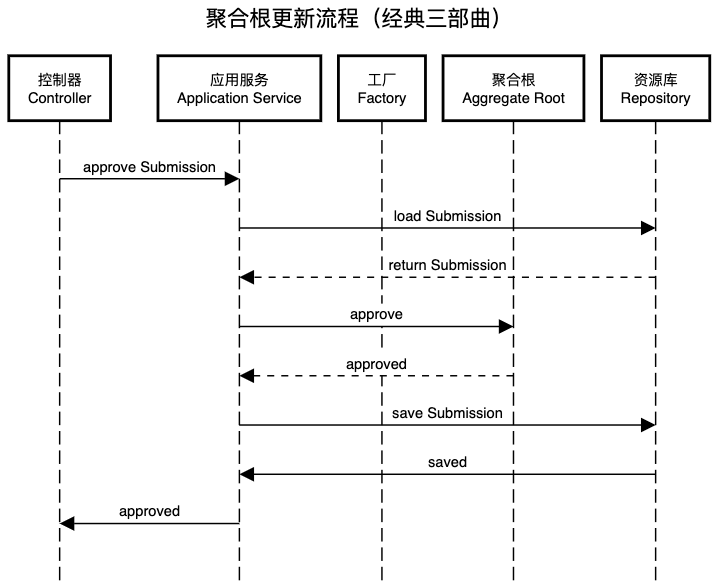
在码如云中,当表单开启了审批功能过后,管理员可对Submission进行审批操作,本质上则是在更新Submission。在“审批Submission”的过程中,请求依然是首先到达Controller:
//SubmissionController
@ResponseStatus(CREATED)
@PostMapping(value = "/{submissionId}/approval")
public ReturnId approveSubmission(@PathVariable("submissionId") @SubmissionId @NotBlank String submissionId,
@RequestBody @Valid ApproveSubmissionCommand command,
@AuthenticationPrincipal User user) {
submissionCommandService.approveSubmission(submissionId, command, user);
return returnId(submissionId);
}
与“创建聚合根”相似,SubmissionController直接将请求代理给应用服务SubmissionCommandService.approveSubmission():
//SubmissionCommandService
@Transactional
public void approveSubmission(String submissionId,
ApproveSubmissionCommand command,
User user) {
Submission submission = submissionRepository.byIdAndCheckTenantShip(submissionId, user);
App app = appRepository.cachedById(submission.getAppId());
Page page = app.pageById(submission.getPageId());
SubmissionPermissions permissions = permissionChecker.permissionsFor(user,
app,
submission.getGroupId());
permissions.checkCanApproveSubmission(submission, page, app);
submission.approve(command.isPassed(),
command.getNote(),
page,
user);
submissionRepository.houseKeepSave(submission, app);
log.info("Approved submission[{}].", submissionId);
}
源码出处:com/mryqr/core/submission/command/SubmissionCommandService.java
应用服务SubmissionCommandService先通过资源库SubmissionRepository的byIdAndCheckTenantShip()方法获取到需要操作的Submission,然后进行权限检查,再调用Submission.approve()方法完成对Submission的更新,最后调用资源库SubmissionRepository的houseKeepSave()方法将更新后的Submission保存到数据库。这里的重点在于:需要保证所有的业务逻辑均放在Submission.approve()中:
//Submission
public void approve(boolean passed,
String note,
Page page,
User user) {
if (isApproved()) {
throw new MryException(SUBMISSION_ALREADY_APPROVED,
"无法完成审批,先前已经完成审批。",
"submissionId", this.getId());
}
this.approval = SubmissionApproval.builder()
.passed(passed)
.note(note)
.approvedAt(now())
.approvedBy(user.getMemberId())
.build();
raiseEvent(new SubmissionApprovedEvent(this.getId(),
this.getQrId(),
this.getAppId(),
this.getPageId(),
this.approval,
user));
addOpsLog(passed ?
"审批" + page.approvalPassText() :
"审批" + page.approvalNotPassText(), user);
}
可以看到,Submission.approve()先检查Submission是否已经被审批过了,如果尚未审批才继续审批操作,审批过程还会发出“提交已审批”(SubmissionApprovedEvent)领域事件(更多关于领域事件的内容,请参考本系列的领域事件一文)。Submission.approve()中的代码量虽然不多,但是却体现了核心的业务逻辑:“已经完成审批的提交不能再次审批”。
当然,并不是所有的业务用例都适合“经典三部曲”,有时聚合根自身无法完成所有的业务逻辑,此时我们则需要借助领域服务(Domain Service)来完成请求的处理。比如,常见的使用领域服务的场景是需要进行跨聚合查询的时候。此时的请求流经路线则为:控制器(Controller) -> 应用服务(Application Service) -> 资源库(Repository) -> 聚合根(Aggregate Root) ->领域服务(Domain Service)。
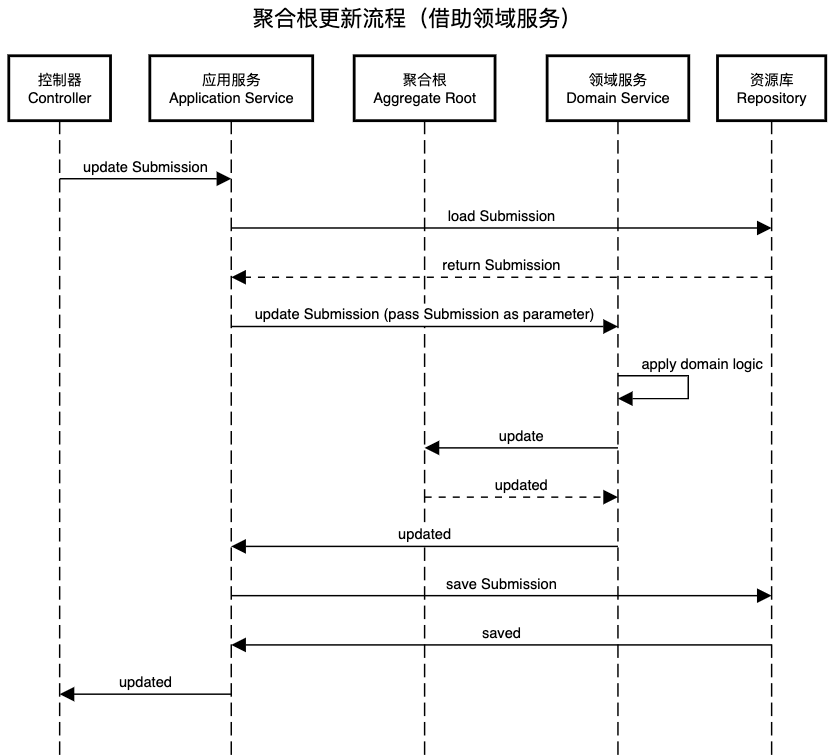
在码如云中,管理员可以对既有的Submission进行编辑更新,但是由于更新时可能涉及到检查手机号或者邮箱等控件填值的唯一性,因此在更新时需要跨Submission进行查询,此时光靠Submission自身便无法完成了,为此我们可以创建领域服务SubmissionDomainService用于跨Submission操作:
//SubmissionCommandService
@Transactional
public void updateSubmission(String submissionId,
UpdateSubmissionCommand command,
User user) {
Submission submission = submissionRepository.byIdAndCheckTenantShip(submissionId, user);
AppedQr appedQr = qrRepository.appedQrById(submission.getQrId());
App app = appedQr.getApp();
QR qr = appedQr.getQr();
Page page = app.pageById(submission.getPageId());
SubmissionPermissions permissions = submissionPermissionChecker.permissionsFor(user,
app,
submission.getGroupId());
permissions.checkCanUpdateSubmission(submission, page, app);
submissionDomainService.updateSubmission(submission,
app,
page,
qr,
command.getAnswers(),
permissions.getPermissions(),
user
);
submissionRepository.houseKeepSave(submission, app);
log.info("Updated submission[{}].", submissionId);
}
源码出处:com/mryqr/core/submission/command/SubmissionCommandService.java
在本例中,应用服务SubmissionCommandService并未直接调用聚合根Submission中的方法,而是将Submission作为参数传入了领域服务SubmissionDomainService的updateSubmission()方法中,在SubmissionDomainService完成了对Submission的更新后,SubmissionCommandService再调用SubmissionRepository.houseKeepSave()方法将Submission保存到数据库中。SubmissionDomainService.updateSubmission()实现如下:
//SubmissionDomainService
public void updateSubmission(Submission submission,
App app,
Page page,
QR qr,
Set<Answer> answers,
Set<Permission> permissions,
User user) {
Map<String, Answer> checkedAnswers = checkAnswers(answers,
qr,
page,
app,
submission.getId(),
permissions);
Set<String> submittedControlIds = answers.stream()
.map(Answer::getControlId)
.collect(toImmutableSet());
submission.update(submittedControlIds, checkedAnswers, user);
}
源码出处:com/mryqr/core/submission/domain/answer/SubmissionDomainService.java
可以看到,SubmissionDomainService.updateSubmission()首先调用业务方法checkAnswers()对表单内容进行检查(其中便包含上文提到的对手机号或邮箱的重复性检查),再调用Submission.update()以完成对Submission的更新,相当于SubmissionDomainService对Submission做了业务上的加工。
这里,领域服务SubmissionDomainService的职责范围仅包含对聚合根Submission的更新,并不负责持久化Submission,持久化的职责依然在应用服务SubmissionCommandService上。这种方式的好处在于:(1)与“经典三部曲”保持一致,将所有持久化操作均集中到应用服务中,不至于过于分散;(2)使领域服务的职责尽量单一。
聚合根删除流程 #
聚合根删除流程相对简单,此时的请求流经路线为:控制器(Controller) -> 应用服务(Application Service) -> 资源库(Application Service) -> 聚合根(Aggregate Root) 。
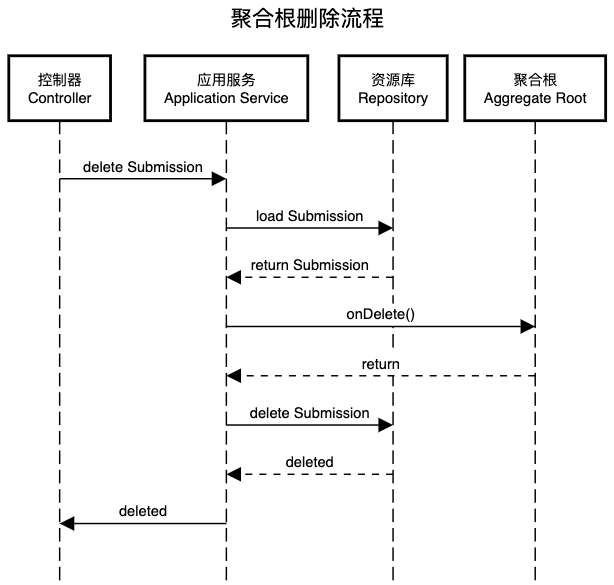
删除请求首先到达Controller:
//SubmissionController
@DeleteMapping(value = "/{submissionId}")
public ReturnId deleteSubmission(@PathVariable("submissionId") @SubmissionId @NotBlank String submissionId,
@AuthenticationPrincipal User user) {
submissionCommandService.deleteSubmission(submissionId, user);
return returnId(submissionId);
}
Controller将请求进一步代理给应用服务SubmissionCommandService:
//SubmissionCommandService
@Transactional
public void deleteSubmission(String submissionId, User user) {
Submission submission = submissionRepository.byIdAndCheckTenantShip(submissionId, user);
Group group = groupRepository.cachedById(submission.getGroupId());
managePermissionChecker.checkCanManageGroup(user, group);
submission.onDelete(user);
submissionRepository.delete(submission);
log.info("Deleted submission[{}].", submissionId);
}
源码出处:com/mryqr/core/submission/command/SubmissionCommandService.java
应用服务SubmissionCommandService通过SubmissionRepository加载出需要删除的Submission后,再调用Submission.onDelete()以完成删除前的一些操作,在本例中onDelete()将发出“提交已删除”(SubmissionDeletedEvent)领域事件:
//Submission
public void onDelete(User user) {
raiseEvent(new SubmissionDeletedEvent(this.getId(),
this.getQrId(),
this.getAppId(),
this.getPageId(),
user));
}
最后,应用服务SubmissionCommandService调用SubmissionRepository.delete()完成对聚合根的删除操作。
查询流程 #
在本系列的CQRS一文中,我们将专门讲到在DDD中如何做查询操作。
总结 #
在本文中,我们分别对聚合根的新建、更新和删除的典型请求处理流程做了详细介绍。在这些流程中,我们以聚合根为中心,围绕之形成了恰如其分的软件架构。在下一篇聚合根与资源库中,我们将对聚合根本身的设计与实现做详细讲解。