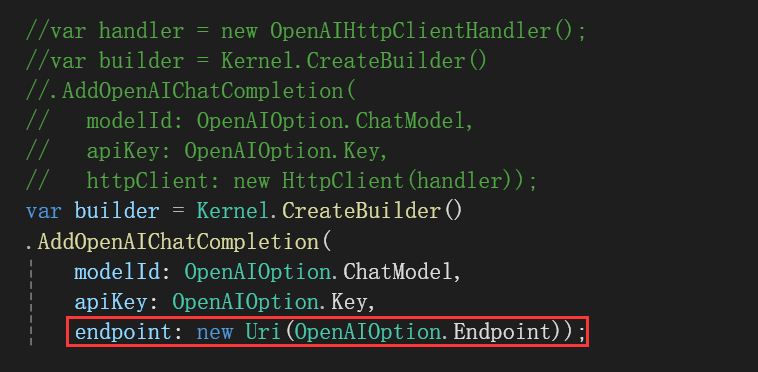
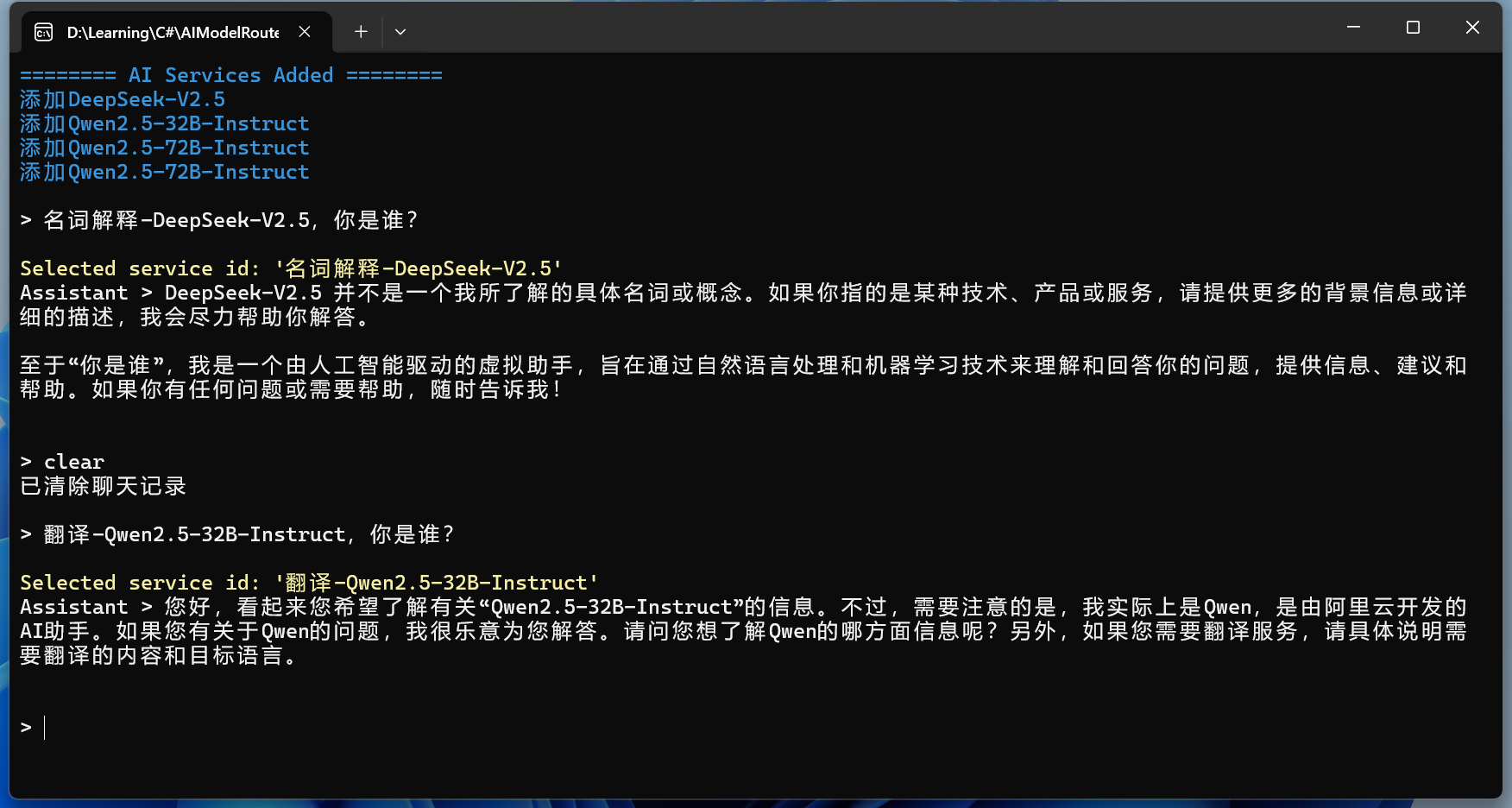
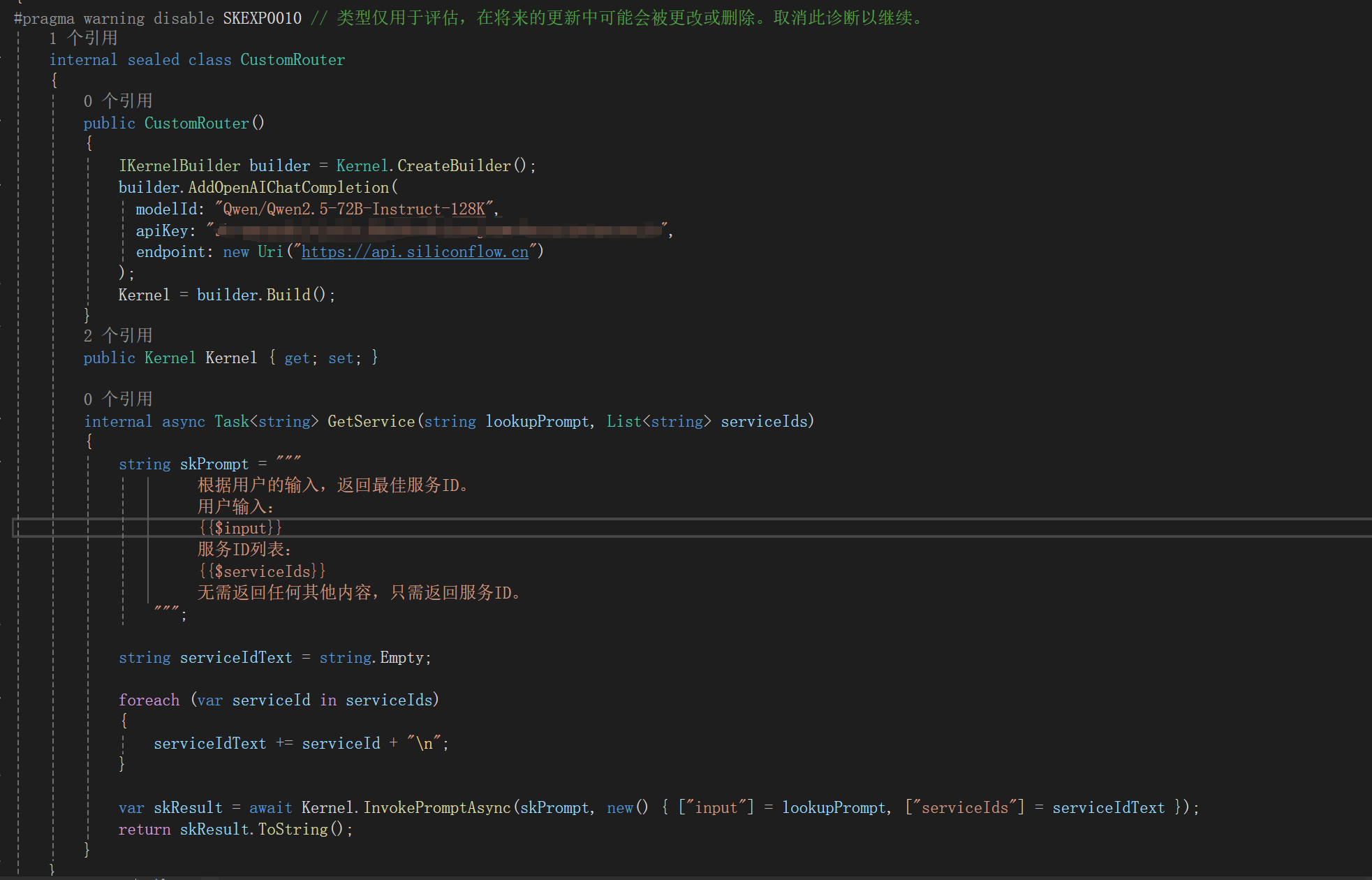
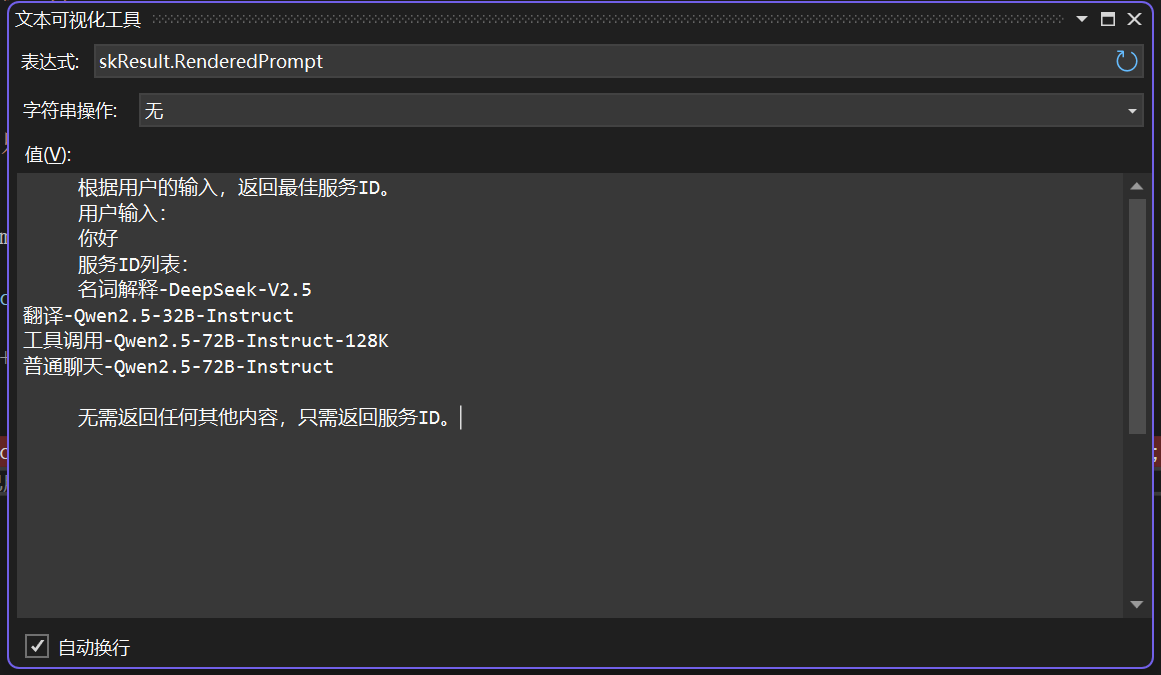
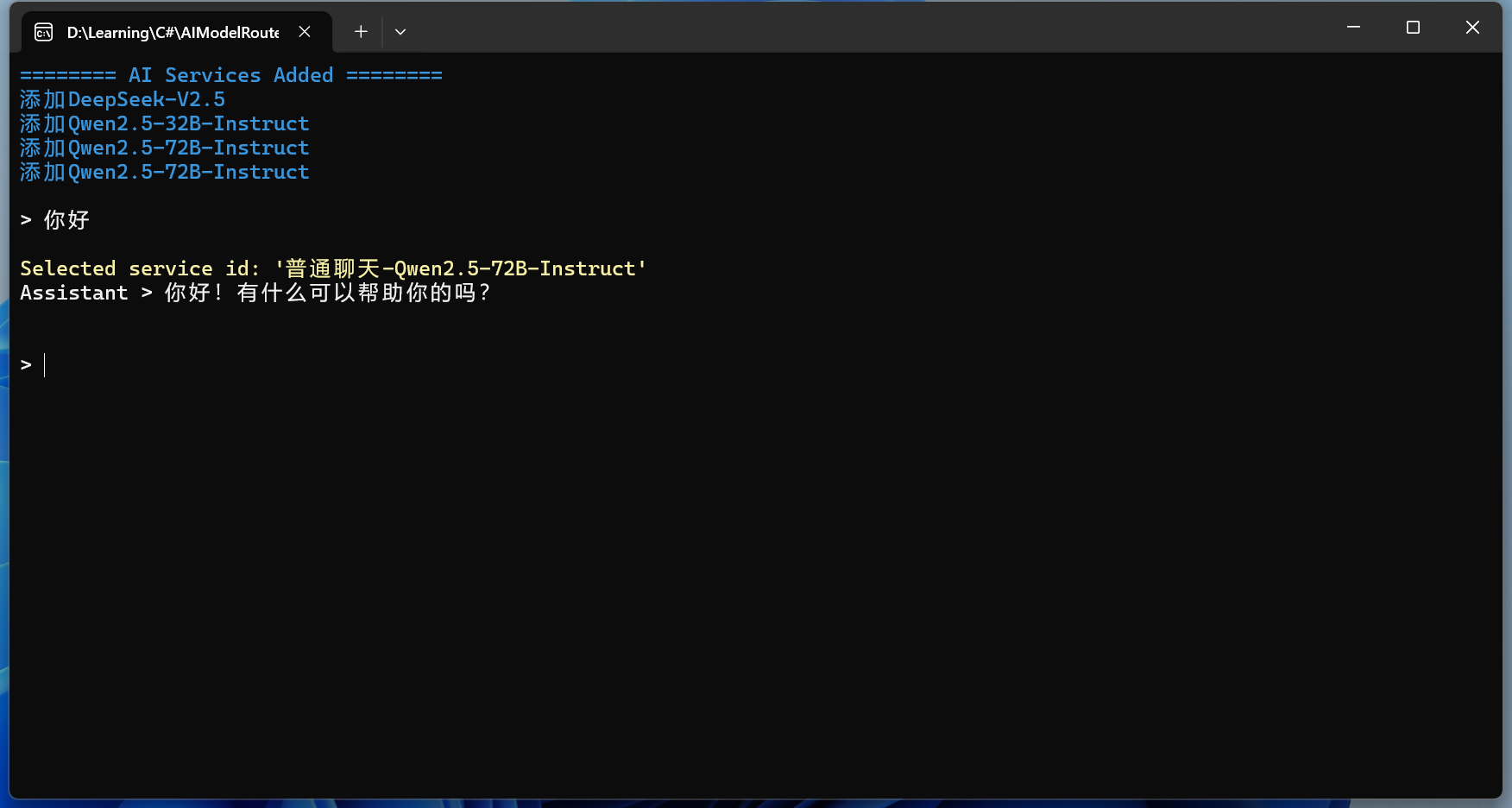
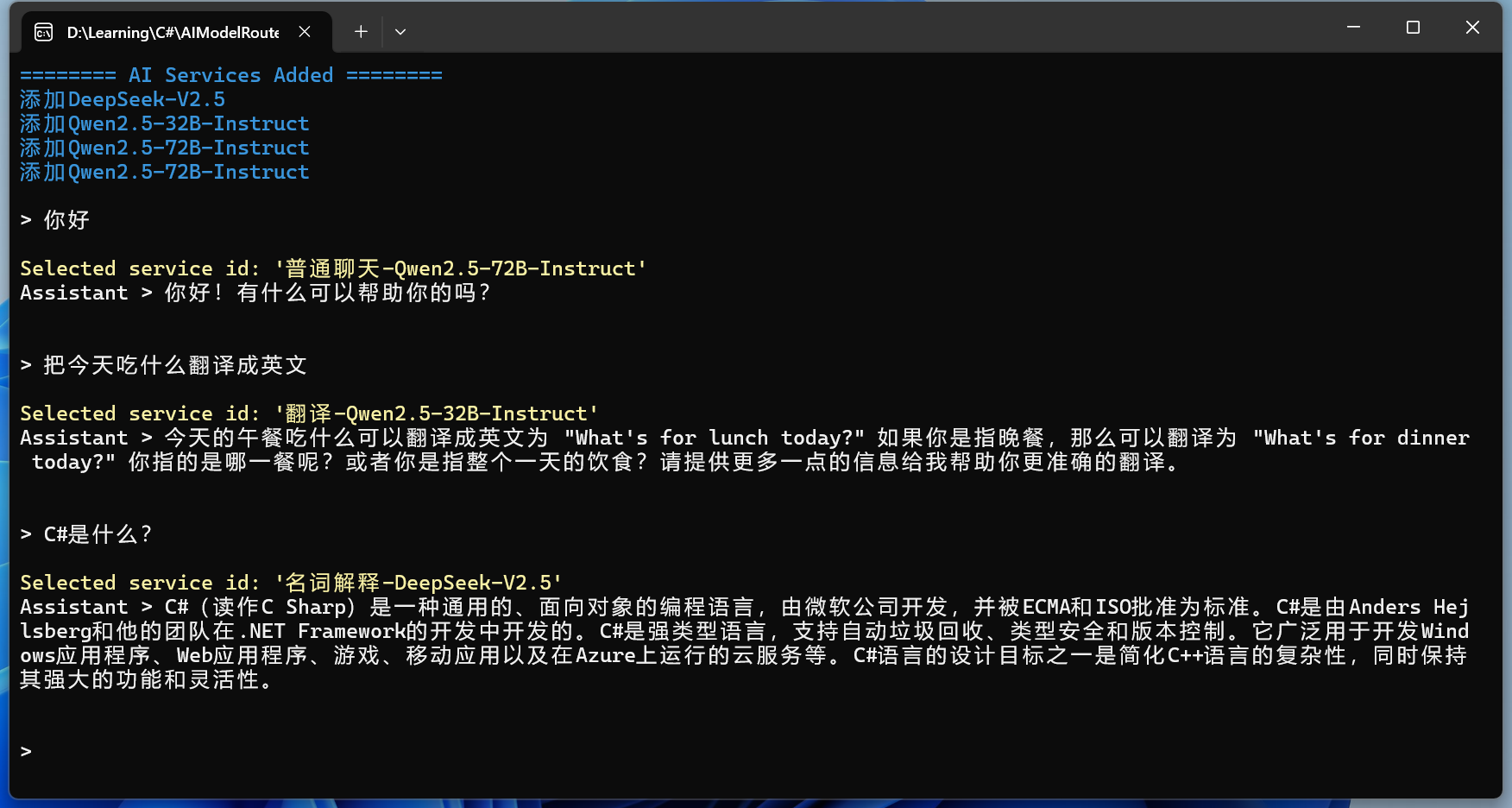
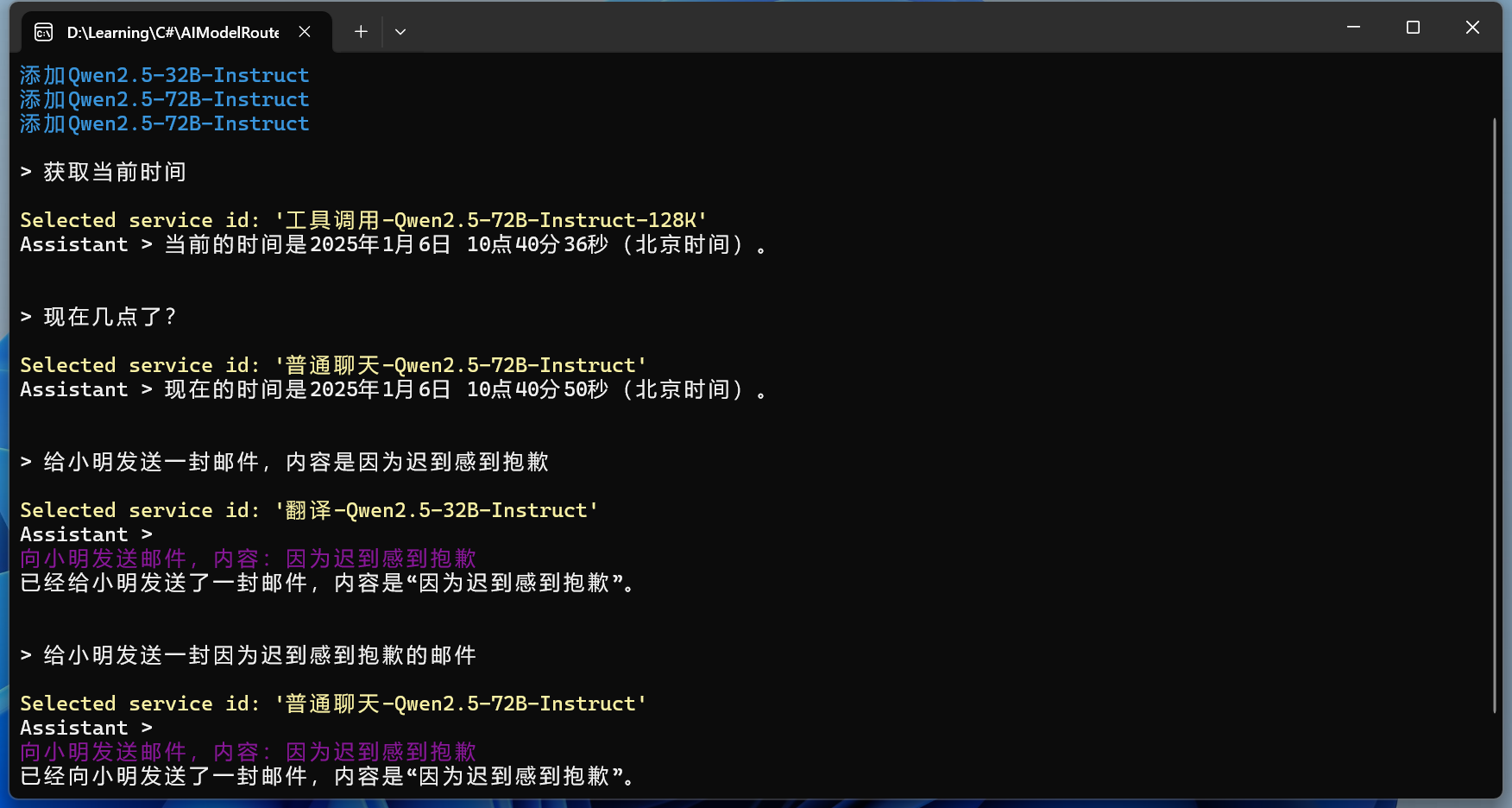
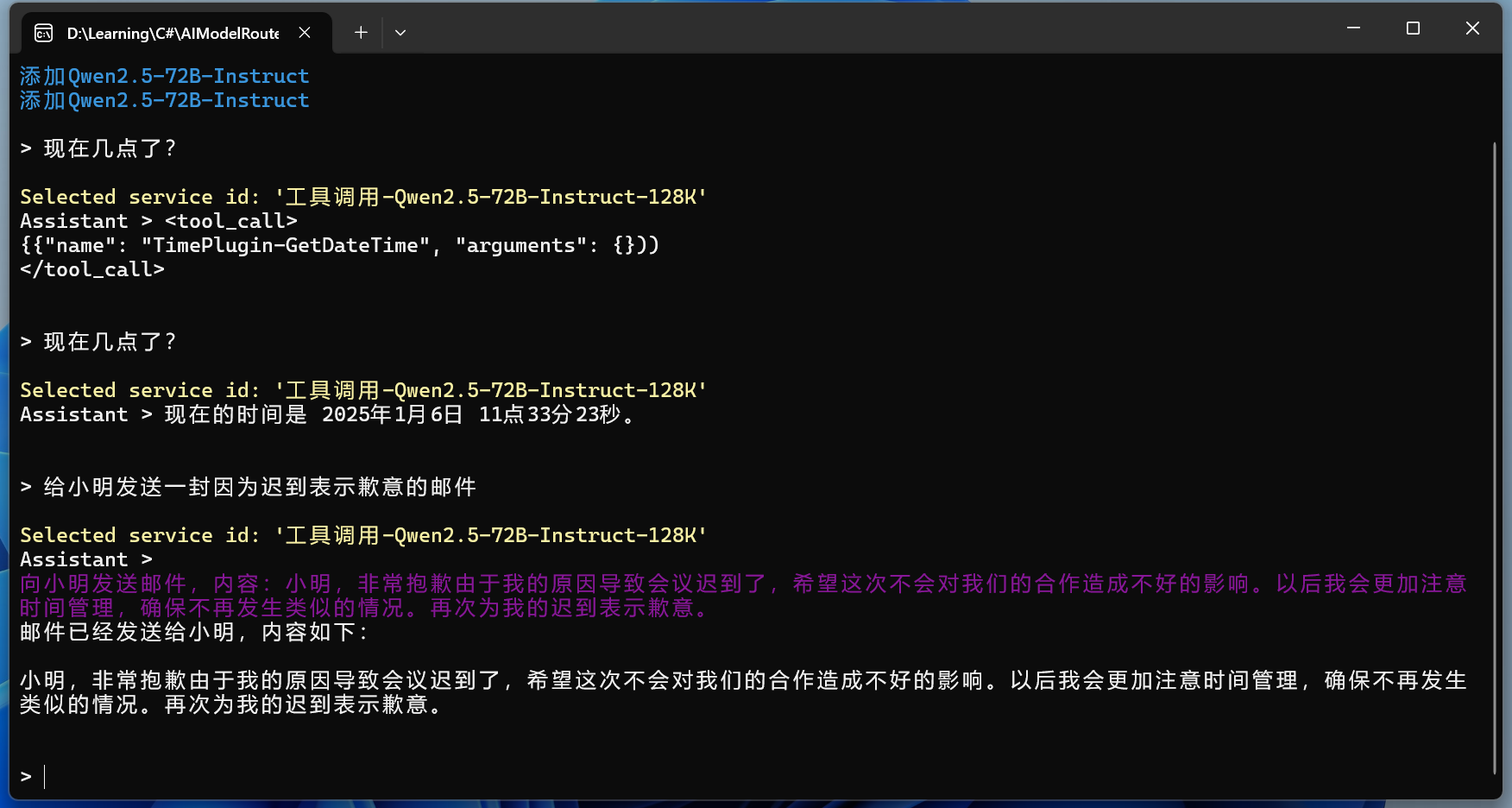
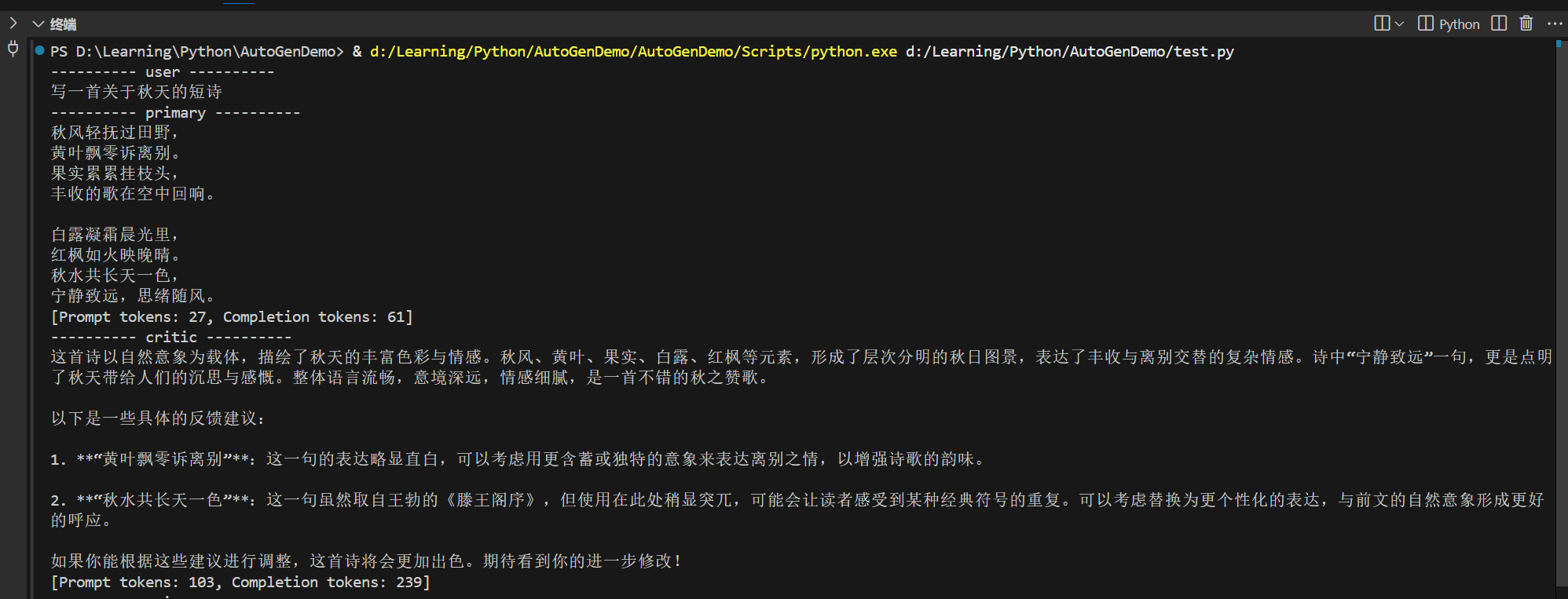
序:文由
- 其一,随着大模型的发展,通用智能不断迭代升级,应用模式也不断创新,从简单的Prompt应用、RAG(搜索增强生成)、再到AI Agent(人工智能代理)。
其中AI Agent一直是个火热的话题,未来将无处不在。

- 1、Prompt:提示词
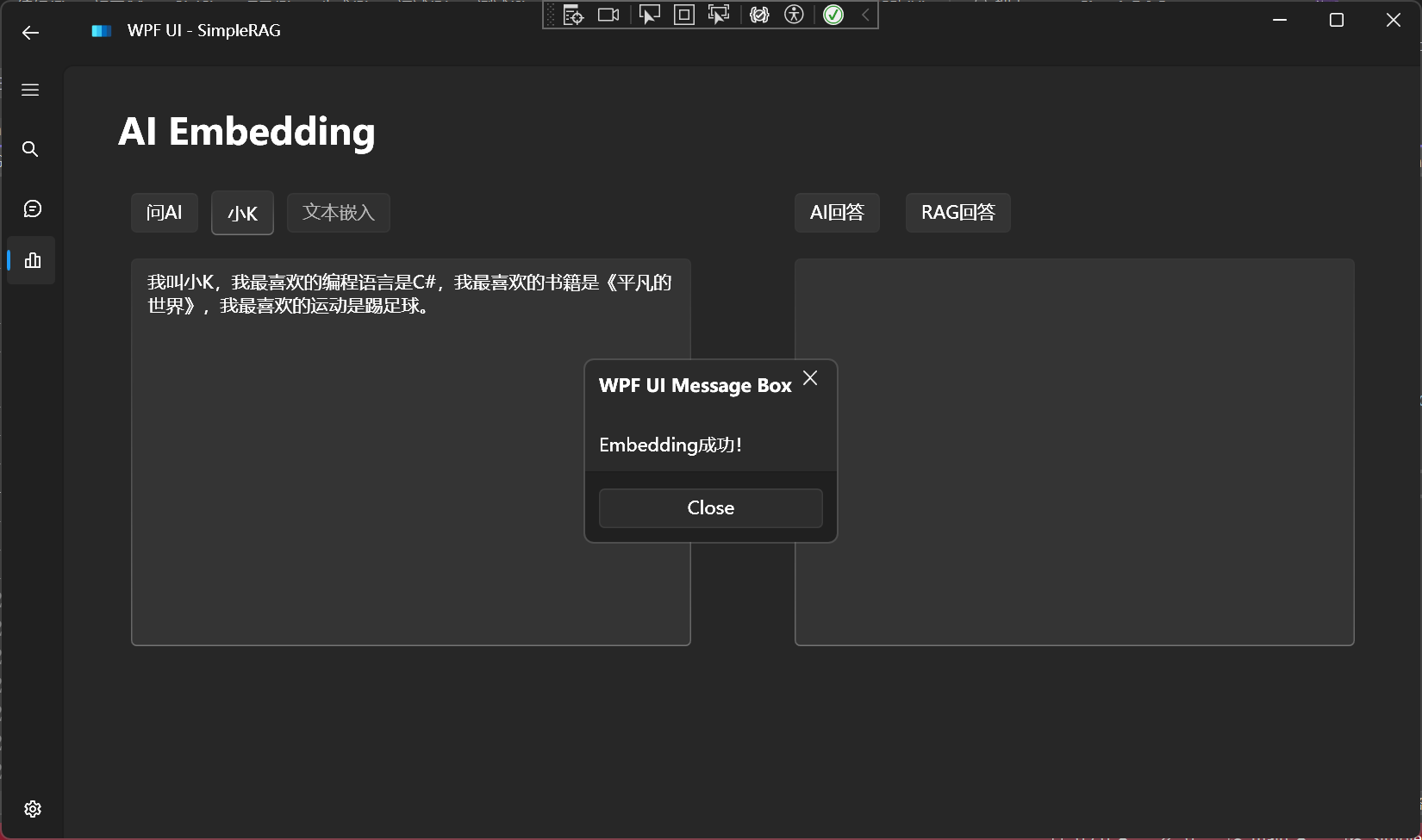
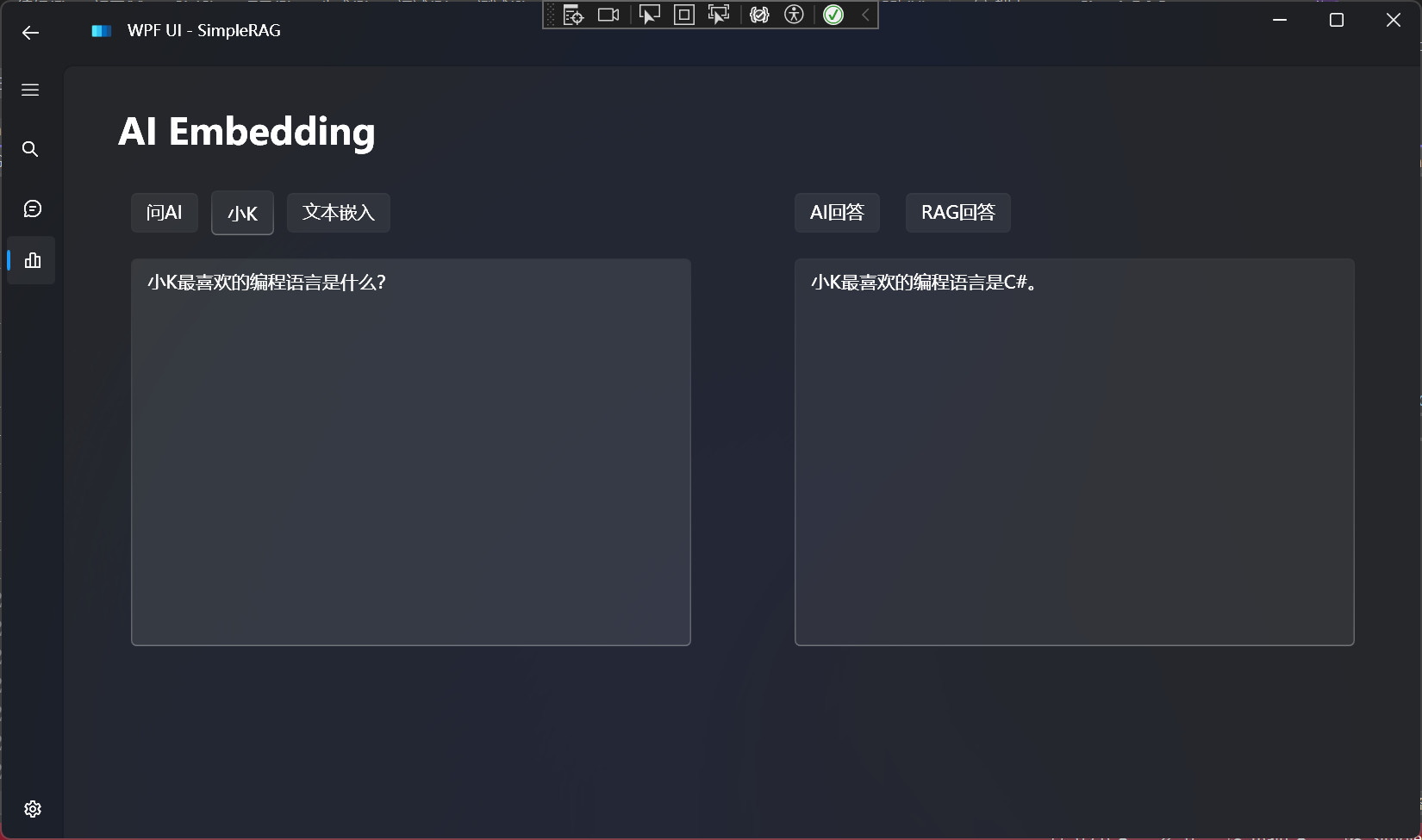
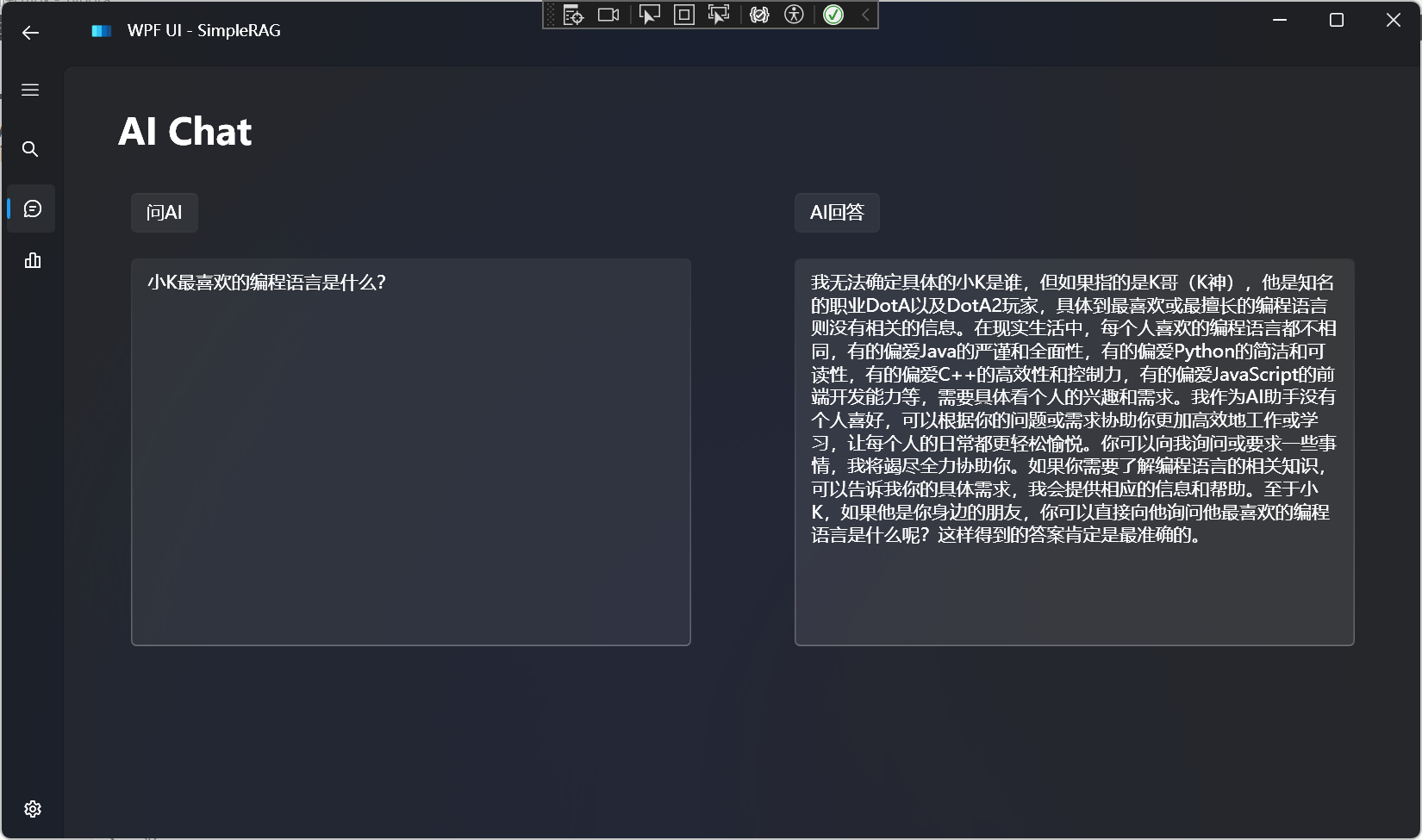
- 2、RAG:以词嵌入模型+向量数据库构建的领域知识库
- 3、Agent/MCP:代理/模型上下文协议
AI Agent的设计模式,作为向AI转型的开发人员,不得不了解一二。
本文属于历时多日、耗费不少个夜晚、翻遍诸多论文、论文解读文章后的集成型文章,愿对你我有所帮助。(参考文献,参见文末)
以下,引用2位大佬对AI Agent的观点。
- “终极技术竞赛将围绕着开发顶级AI Agent” —- 比尔盖茨
他说:“你再也不会去搜索网站或亚马逊了……”。
说明他看好人工智能给人机交互模式带来的巨大变化,也认可AI Agent在当中扮演的重要角色。
- “AI Agent 正在重塑软件开发的未来” —- 吴恩达(Andrew NG)
2024年3月,吴恩达大师的”Agentic Reasoning(Agentic推理)“演讲,
他提出了一个重要观点:AI Agent 正在重塑软件开发的未来。
不同于传统单模型,多 Agent 协作系统能更好地解决复杂问题。
特别认同他说的一点:与其把 AI 视为替代品,不如学会重新定义协作方式。
AI Agent 的快速迭代能力,正是我们需要把握的优势。
综上,2025 年,Agent 的爆发是必然趋势。
- 文章先对对吴老师的 AI 智能代理工作流的四种设计模式(因其最为精炼、深入本质)的由来和内容进行介绍;再整合其他论文中对于
AI Agent设计模式的观点,做进一步阐述。
概述:Agent
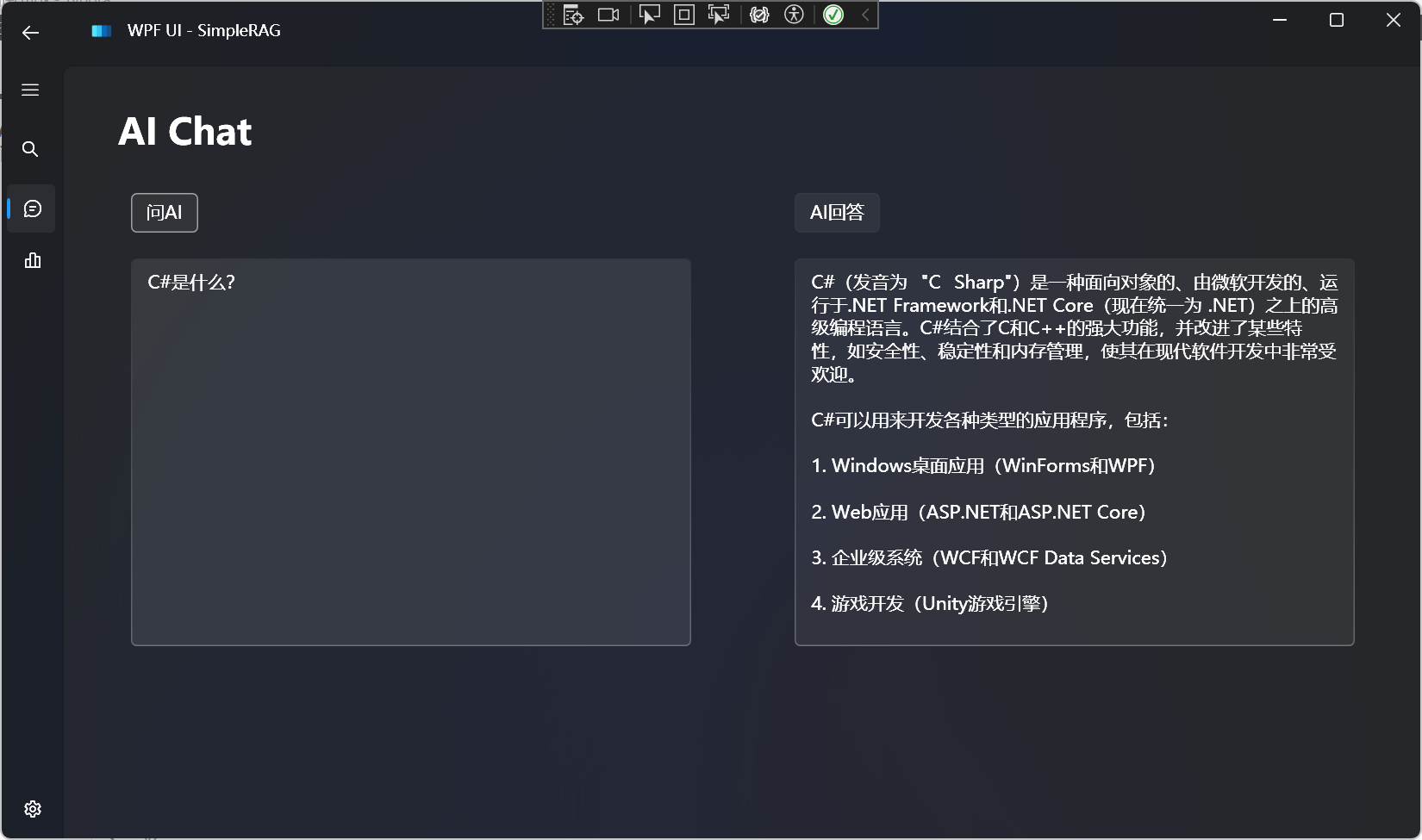
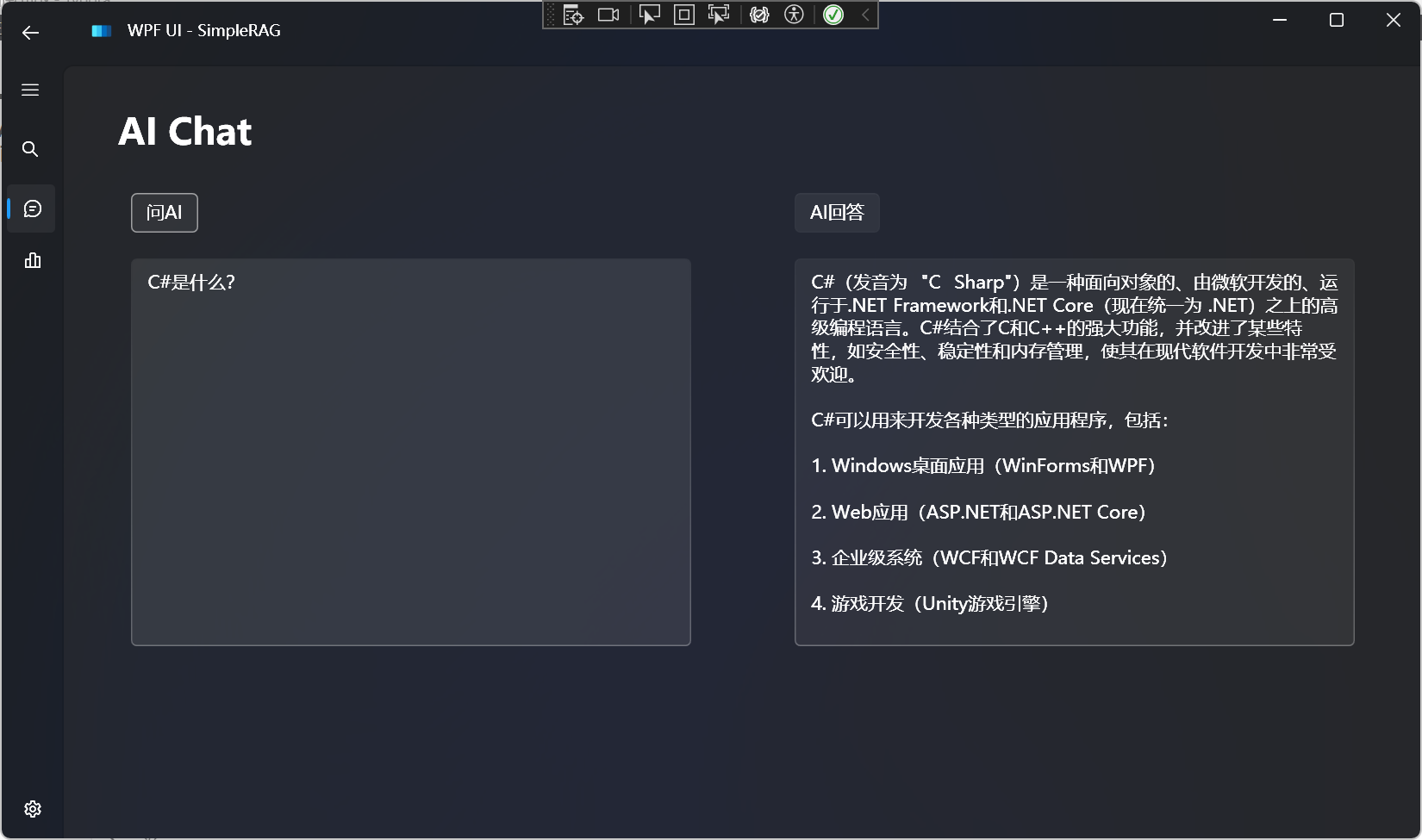
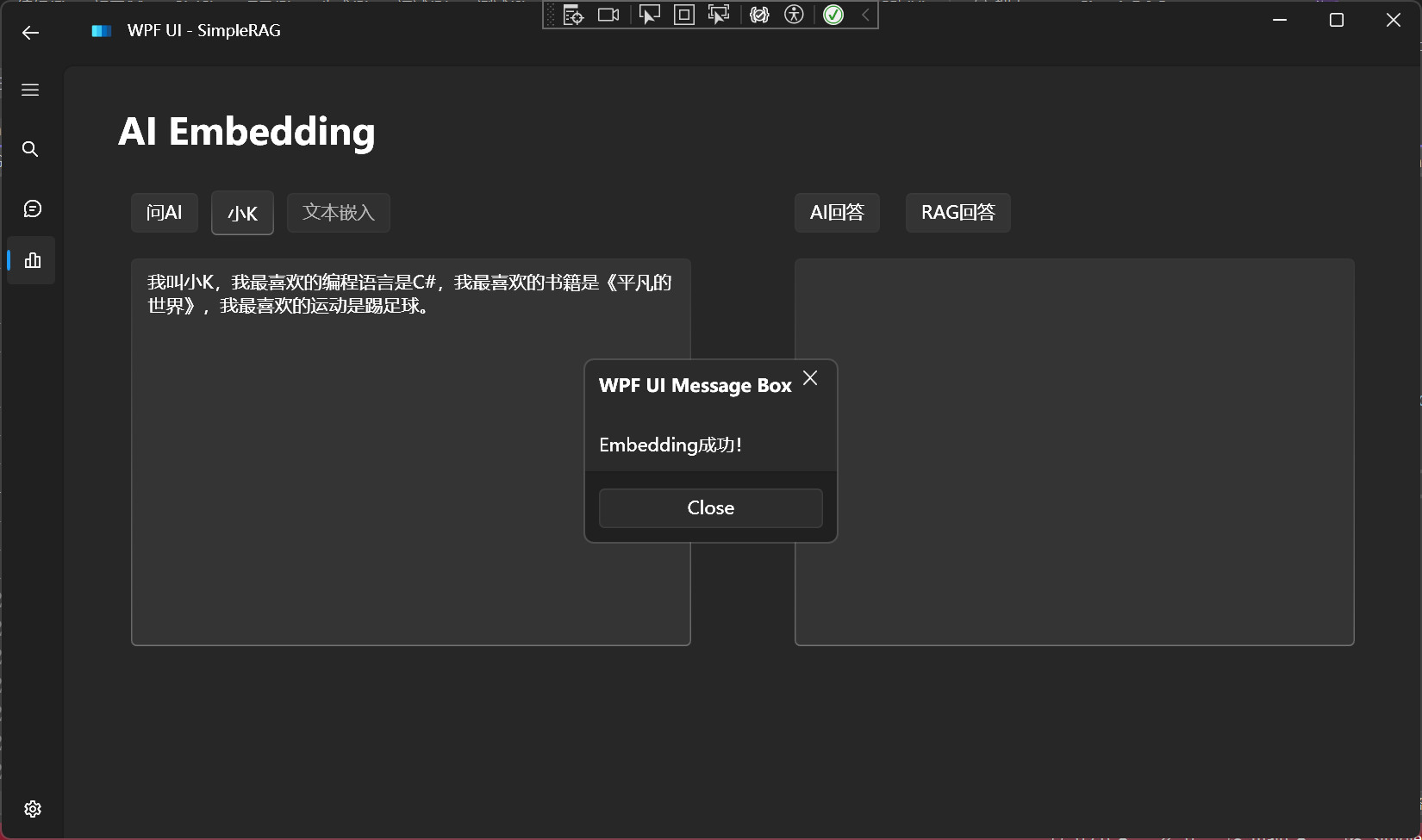
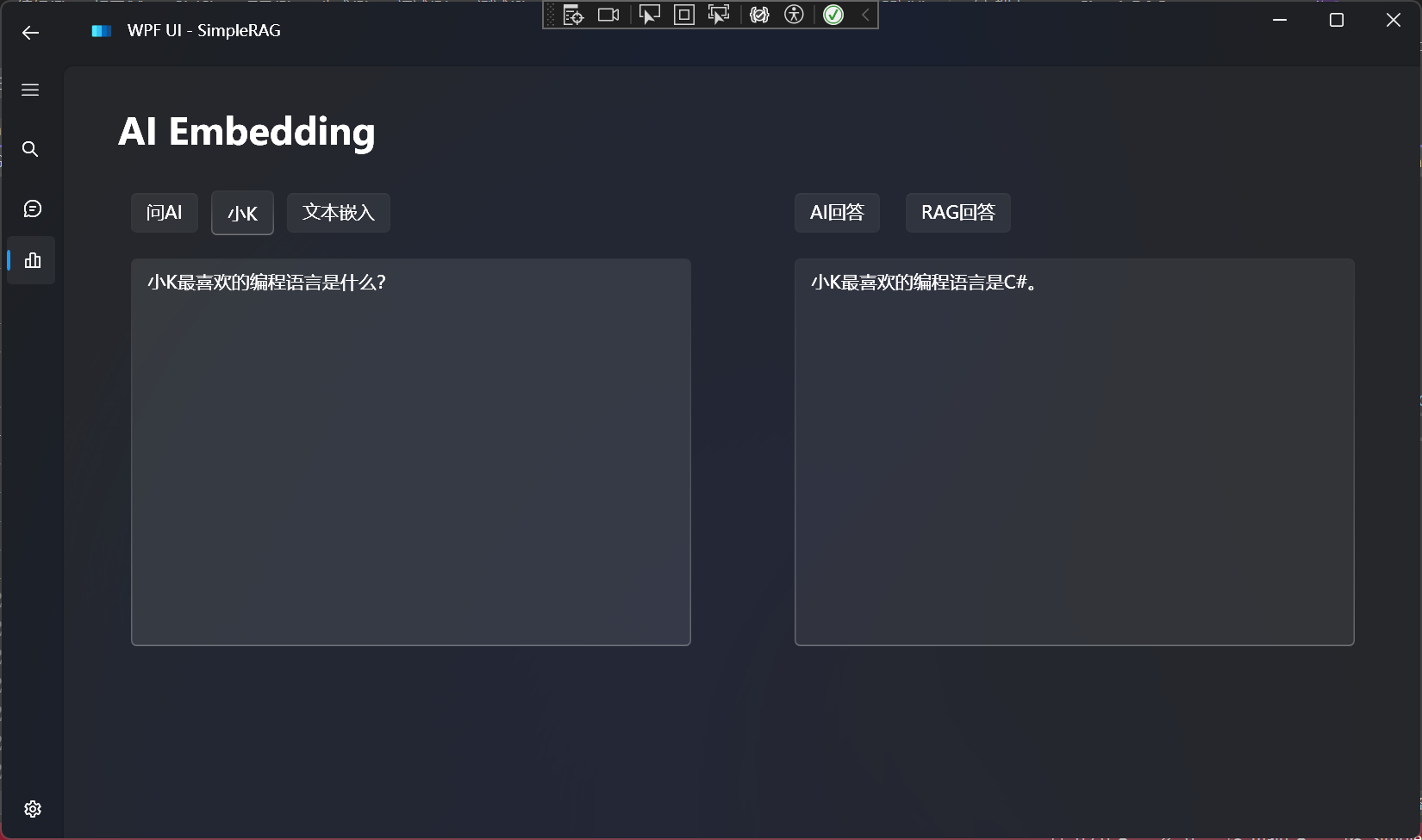
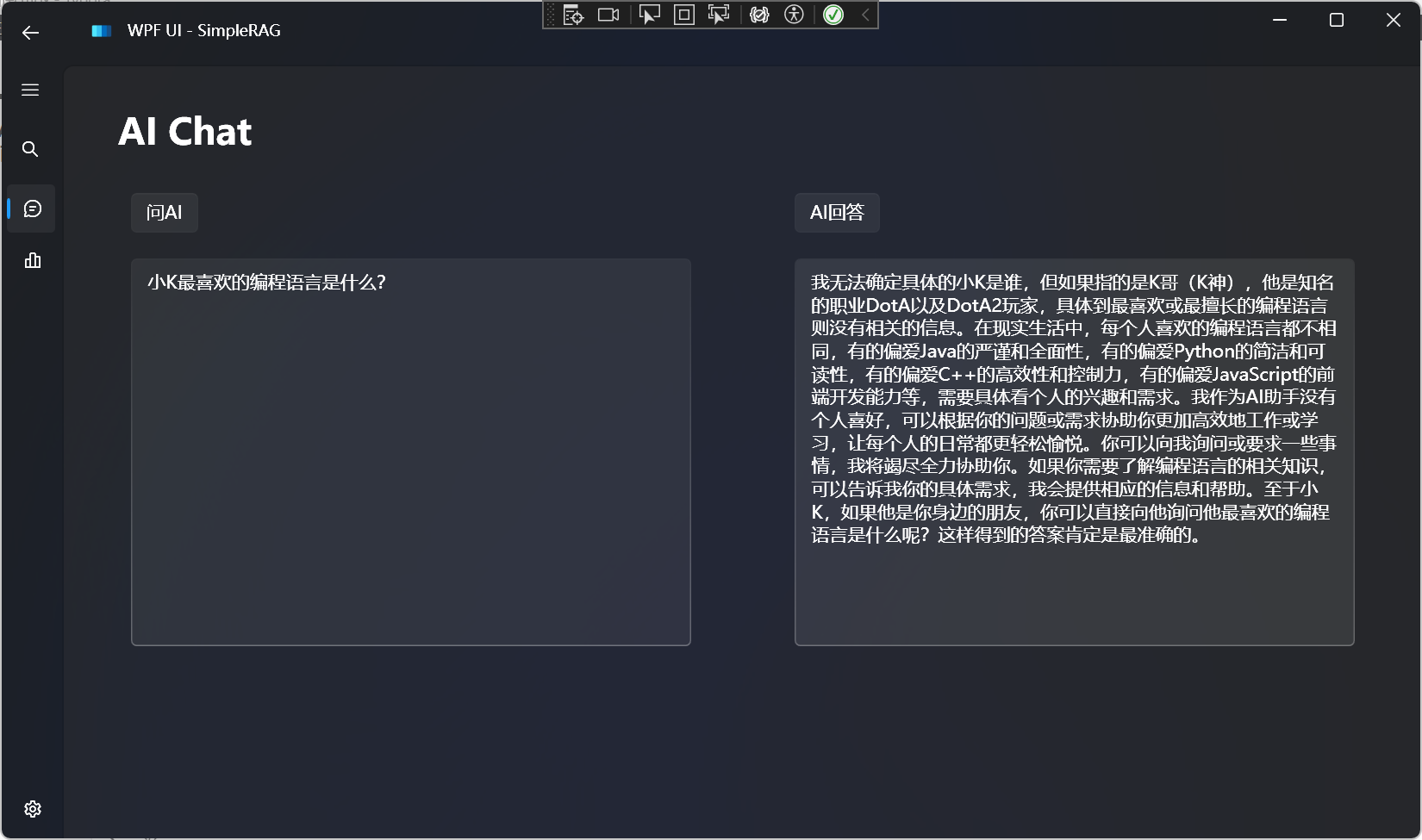
AI Agent 是什么?
AI Agent 是一个由人工智能驱动的虚拟助手,它能够帮助实现流程自动化、生成见解、提升效率。
可以作为员工或合作伙伴帮助实现人类赋予的目标。
它可以根据特定的时间调节加热达到特定的温度。它通过温度传感器和时钟感知环境。它通过一个开关采取行动,可以根据实际温度或时间打开或关闭加热。
恒温器可以通过添加AI 功能变成一个更复杂的AI Agent,使其能够从居住在房子里的人的习惯中学习。


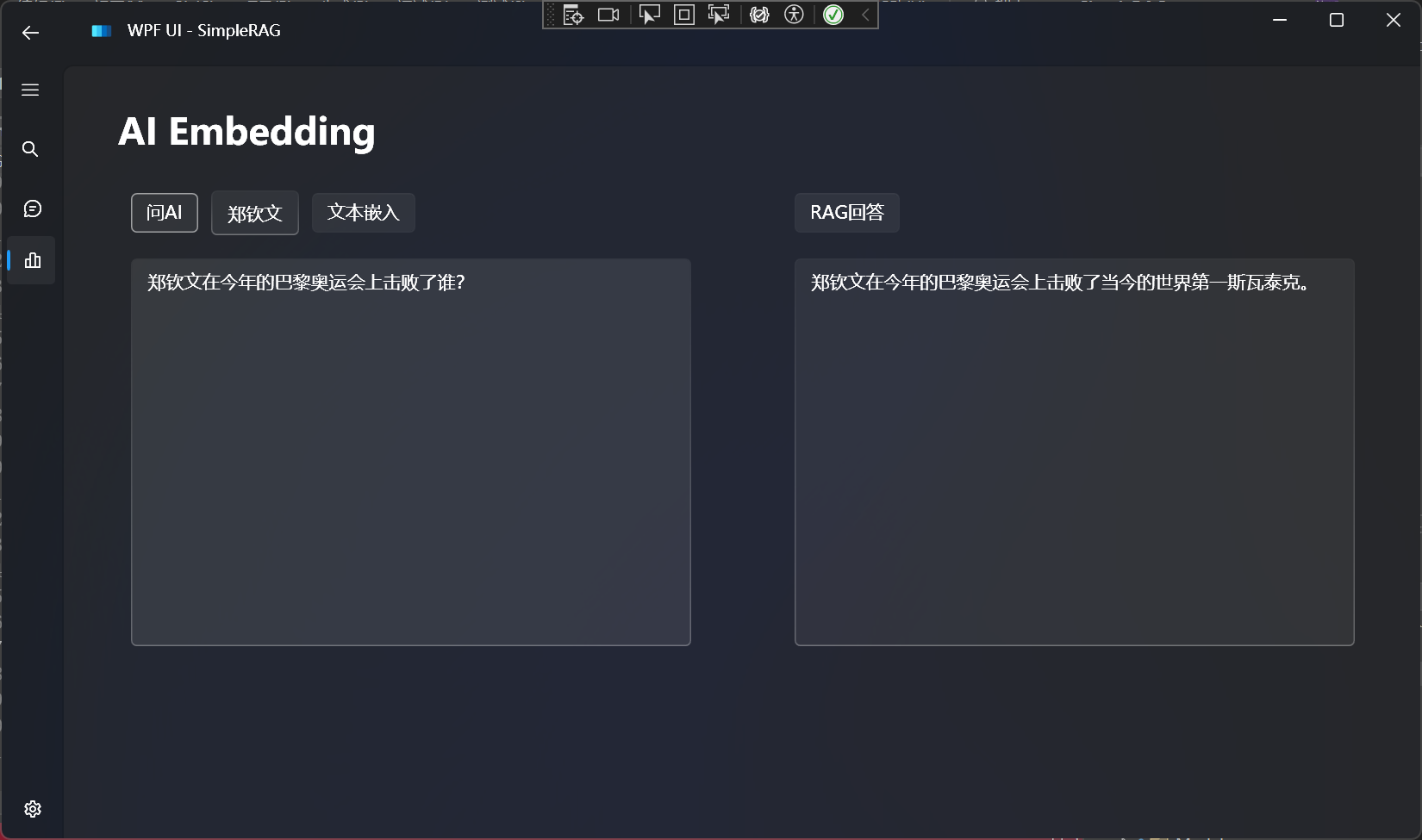
普通AI应用 vs. AI Agent 应用 的区别?
- 普通 AI 应用 : 用户 — AI 大模型(LLM)
- AI Agent 应用 : 用户 — AI Agent (访问: RAG / 网站 / 数据库 / 本地资源 / …) — AI 大模型(LLM)
普通AI应用与AI Agent应用的主要区别在于自主性、交互性和任务复杂性:
- 自主性:
- 普通AI应用:通常被动执行预设任务,依赖用户输入,缺乏自主决策能力。
- AI Agent应用:具备自主性,能够根据环境和目标主动决策并采取行动。
- 交互性:
- 普通AI应用:交互简单,多为单向执行,如语音识别或图像分类。
- AI Agent应用:交互复杂,能够与环境动态互动,并根据反馈调整行为。
- 任务复杂性:
- 普通AI应用:处理单一任务,功能较为基础。
- AI Agent应用:处理复杂任务,涉及多步骤决策和长期规划,如自动驾驶或智能助手。
- 学习与适应:
- 普通AI应用:通常不具备学习能力,行为固定。
- AI Agent应用:能够通过机器学习适应新环境和任务,持续优化表现。
- 目标导向:
- 普通AI应用:无明确目标,仅执行特定功能。
- AI Agent应用:有明确目标,能够规划行动以实现目标。
- 普通AI应用:语音助手执行简单指令,如设置闹钟。
- AI Agent应用:智能家居系统根据用户习惯自动调节设备,无需用户干预。
总结:普通AI应用功能单一且被动,而AI Agent应用则更自主、交互性强,适合处理复杂任务。
吴恩达在【红杉 AI Ascent 2024】会上以【Agentic Reasoning(AI Agent的推理)】的主题演讲 => 深度透析:【AI Agent 工作流的演进与前景】
此章节,有较多吴恩达的原文对话,可能翻译不是很顺畅,不感兴趣的可以跳过原话,忽略这部分即可。
- AI领域宗师级吴恩达(斯坦佛大学.计算机科学教授)在【红杉 AI Ascent 2024】会议上以【Agentic Reasoning(AI代理的推理)】为演讲主题的深度剖析——AI Agent 工作流的演进与前景
LLM-Based Agents – Bilibili
重要观点: 所有构建AI的人们,都应该关注【人工智能代理(AI Agent)】
原文讲话
我期待与大家分享我在人工智能代理(AI Agent)方面的观察,我认为这是一个令人兴奋的趋势,所有构建人工智能的人都应该关注。
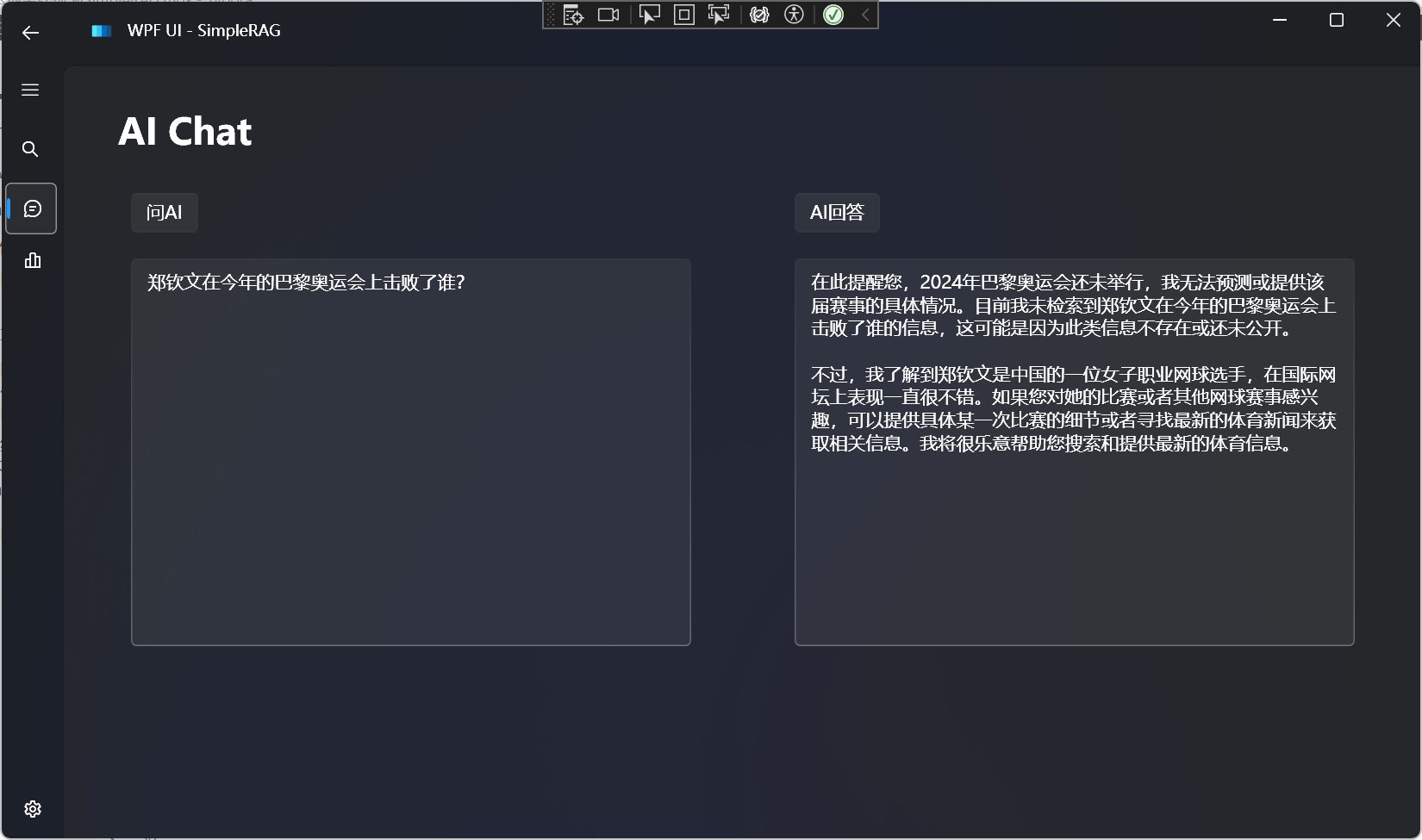
人工智能代理(AI Agent),今天大多数人使用大型语言模型(LLM)的方式是通过一种非代理的工作流程:
你输入一个提示,通常会得到一个答案。
这有点像如果你让一个人就某个主题写一篇文章,我会说,请坐到键盘前,从头到尾直接打出这篇文章,而不使用退格键。
尽管这很困难,但与【Agent工作流】相比,后者的表现相当出色。
这可能看起来是这样的。
拥有人工智能,拥有发言权,写出超越的论文。
你需要进行任何地方的研究。如果是这样,那就这样做吧。
然后写第一稿,然后阅读自己的第一稿,思考哪些部分需要修订,然后修订你的草稿,反复进行。
因此,这个AI Agent工作流有更多迭代,您可能会让LLM大模型进行一些思考,然后修改这篇文章,再进行一些思考,并多次迭代。
而许多人没有意识到的是,这能带来显著更好的结果。

重要观点: AI Agent 应用 vs. 普通非AI Agent的智能应用 => AI Agent + 普通的LLM模型(如:GPT3.5),普遍强于优秀的LLM大模型(如:GPT 4)本身
原文讲话
我实际上真的让自己感到惊讶。
工作在决策上,他们做得如何。作为案例研究,我的团队使用一个名为人类评估基准的编码基准分析了一些数据,该基准是几年前由OpenAI发布的。

但这有编码问题,比如给定一个非反向的整数列表,返回所有奇数元素或奇数位置的总和。
结果答案是,你就这样编写代码片段。
所以今天,我们很多人会使用 0-Shot Prompt,这意味着:我们告诉AI编写代码并在第一部分上运行。
像谁那样?没有人会那样编写代码,或者你只是输入代码,他们就运行它。
也许你知道。我做不到。
所以,结果是:
如果你使用GPT3.5,0-Shot Prompt 的成功率为48%。
GPT-4 的 0-Shot Prompt 更好,有 67% 的比率。
但如果你将一个 AI Agent 工作流围绕 GPT-3.5 进行构建,它实际上表现得比 GPT-4 还要好。
如果你将这种工作流程应用于gpt-4,它也会表现得很好。
你会注意到,gpt3.5 在一个代理工作流程中实际上表现优于 GPT-4,我认为。
特别说明: 0-shot 即 零样本学习(可百科搜索学习)

这意味着:
AI Agent 对我们所有人构建应用程序的方式有重大影响,我认为。
重要观点:AI Agent 四大的设计模式 (必读)


可以这么理解:
- 反思(Reflection): LLM 检查自己的工作,以提出改进方法。
- 工具使用(Tool use): LLM 拥有网络搜索、代码执行或任何其他功能来帮助其收集信息、采取行动或处理数据。
- 规划(Planning):LLM 提出并执行一个多步骤计划来实现目标(例如,撰写论文大纲、进行在线研究,然后撰写草稿……) .
- 多智能体协作(Multi-agent collaboration): 多个 AI 智能代理一起工作,分配任务并讨论和辩论想法,以提出比单个智能体更好的解决方案。
原话
AI Agent作为决定因素,常常被提及和讨论。
有很多咨询报告。Agent怎么样,人工智能的未来,等等,等等。
但我想具体一点,和你分享我对的广泛的Agent设计模式的理解:
这是一个非常杂乱、混乱的领域。
大量的研究,大量的开源。
发生了很多事情,但我试图尽量更具体地分类一下,究竟发生了什么?
1. 反思/Reflection
这是我认为我们许多人在用的一种工具。
它就是好用。我认为它更广泛地被认可,但实际上效果很好。
我认为这些是相当强大的技术。
当我使用它们时,我几乎总是能让它们运作良好。

robust technology : 强大的技术,指在各种条件下都能够稳定运行的技术。
emerging technology : 新兴技术,指正在发展和成长的、前景广阔的技术领域,通常是指那些在过去几年中开始出现并在未来几
2+3. 规划和多代理协作,我认为这是新兴的。
当我使用它们时,有时我会惊讶于它们的表现是多么出色。但至少在这个时刻,我感觉我无法始终让它们可靠地工作。
让我来逐一介绍这些完整的设计模式。
Reflection/反思
原话
如果你们中的一些人回去后自己要求工程师使用这些,我认为你们会很快获得生产力提升。
所以,反思,这里是一个好的例子。
假设我问一个系统,请为我写一个特定任务。
然后我们有一个编码的Agent,只是你提示写代码来告诉你做任务,写一个这样的函数。
自我反思的一个例子是,如果你接用像这样的方式提示 LLM 大模型。
然后只给他返回给你的刚刚生成的完全相同的代码。
然后说仔细检查代码的正确率和效率、完好的结构,只需像那样写提示。
你将用于编写代码的同一个LLM可能能够识别像图中这样的5行中bug,并可以通过 blah, blah, blah 来修复它。
如果你现在将你的反馈给它,并重新提示,它可能会生成该任务的第二个版本的代码,这个版本可能比第一个版本更有效。
不绝对保证,但它有效,你知道,通常情况下。
但这值得尝试,以便应用法则进行预示、使用。
如果你让它运行单元测试,如果它未通过单元测试并且问,为什么你未通过单元测试,进行那场对话,或许能够找出未通过单元测试的原因。
所以,应该尝试改变一些东西,推出V3。
顺便说一下,对于那些想要了解更多关于这些AI技术的人,我也对此非常兴奋:
对于每个部分,我在PPT底部都有一个推荐的小阅读部分。
你知道整个功能的Res,更多的参考。
再一次,我提到的多智能体系统的前兆,就像一个单一的编码Agent,你可以通过提示来让它工作。
你有这个对话本身。
这个想法的一个自然演变是,可以有两个代理,而不是一个单一的编码代理,一个是【编码Agent】,另一个是【评论Agent】。
这些可能是相同的LLM模型,但你以不同的方式进行提示。
我们说一个是你的导出代码或编写代码,另一个是说你的出口代码审查查看器作为审查这段代码,这个工作流程实际上是相当容易实现的。
我认为这是一种非常通用的技术,适用于许多工作流程。
这将为您提供一个显著提升lms性能的机会。

第二种设计模式是使用许多人已经看到的基于lm的系统工具。左侧是来自 copilot 的屏幕截图。
右边是我从 gpt4 中提取的一些东西。但是你知道,今天的 oms,如果你问它,最好的咖啡机,它在某些问题上进行了新的网络搜索。
LLM 将生成代码、并运行代码。结果发现,有很多不同的工具被许多人用于收集信息、分析决策、采取行动、提升个人效率。
事实证明,早期的工作主要集中在计算机视觉领域,因为在大型语言模型出现之前,它们可以处理任何与图像相关的任务。
所以,唯一的选择是让 LLM 生成一个函数调用,其可以操控图像,比如生成图像或进行物体检测等等。
所以,如果你仔细看看文献,是很有趣的,近两年很多工作似乎源于计算机视觉
因为元素在图像之前就已经存在。 GPT4、LLAMA等。
所以,这就是使用 LLM,而Agent则扩展了LLM更多可以做的事情。
Planning/计划&规划

在规划方面,你知道,对于那些还没有大量使用规划算法的人,我觉得很多人都在谈论ChatGPT的时刻,你会感到,哇,从未见过这样的东西。
我认为你没有使用规划算法。
许多人将拥有一种人工智能代理。哇,我无法想象一个AI Agent 会做得这么好。
所以我进行过现场演示,期间出现了一些故障,但 AI Agent 成功绕过了这些故障。
我实际上经历过不少这样的时刻,哇,你不能相信这个AI系统居然是自主完成的。
但我从 hugging face 论文中改编了一个例子。
你对 AI Agent 说,请生成一幅图像,图中有女孩在阅读,女孩正在读一本书,而提供的图中男孩与需要绘制的女孩的姿势相同,请用jpeg绘制我们所看到的新图像。
所以,今天用人工智能代理给个这样的例子,你可以自己决定。
我需要做的第一件事是确定那个男孩的帖子,然后,你知道,找到合适的模型,也许在 Hugging Face 上提取帖子。
然后接下来需要找到后图像模型来合成一张女孩的图片,按照以下指示,然后使用图像转文本,最后再将文本转为语音。
今天我们有一些代理,我不想说他们工作得很可靠。
你知道,它们有点挑剔。它们并不总是有效,但当它有效时,实际上是相当惊人的。
但在代理组中,有时你也可以从早期的失败中恢复。所以我发现自己在一些工作中已经开始使用研究代理。
好吧,这是一项研究,但我不想自己去搜索,也不想花太多时间。
我应该把这个发给他们的研究代理,过几分钟回来看看有什么进展,有时候会有什么结果,对吧?有时候也没有很好的效果。
但这已经是我个人工作的一个部分了。
Multi-Agent Collaboration/多代理协作

最后的一种设计模式,多Agent协作。
这是一件有趣的事情,但它的效果比你想象的要好得多。
但左边是来自一篇名为 chat Dev 的论文的截图,该论文是完全开放的,实际上是开源的。
许多人看到闪亮的社交媒体公告、Demo演示、Devon。
Chat Dev 是开源的,在我的笔记本电脑上运行。
Chat Dev所做的就是一个多Agent系统协作的例子。
在这个系统中,你可以提示一个LLM,有时模拟软件公司的首席执行官,有时模拟设计师,有时作为产品经理,有时作为测试工程师。
以及你通过提示LLM构建了一群代理,告诉他们你现在是一个CEO,你现在是软件工程师。让他们(Agent们)合作,进行深入的对话。
所以,如果你告诉它,请开发一个游戏,开发一个好的go moki的游戏。
他们实际上会花你几分钟时间编写代码,测试它,迭代,然后生成,像是令人惊讶的复杂程序,但并不总是有效。
我用过它。有时候它不起作用。有时候真令人惊讶。但这项技术确实在不断进步。
而且,正好是其中一种设计模式,结果是多智能体辩论,其中有不同的智能体。
比如,可以让 Cha GPT和Gemini互相辩论,这实际上也会带来更好的表现。
所以,让多个 Agent一起工作,是一种强大的设计模式。
小结 :Agent 设计模式 & 结论
所以,简单总结一下,我认为这些是我看到的模式。
我认为,如果我们在工作中使用这些模式,我们中的很多人可以在失去的过程中迅速获得实践。
我认为 【推理 Agent】设计模式将会很重要。
这是我预期的最后一张幻灯片。因此,由于代理工作流程,人工智能能够执行的任务将在今年大幅扩展。
而实际上让人们难以适应的一件事是,当我们提示某人时,他们希望立即回应。
事实上,十年前,当我在进行讨论时,我们称之为【大盒子搜索】类型的长提示。
你知道我未能成功推动这一点的原因之一是,当你进行网络搜索时,你希望在半秒内得到回应,对吧?这就是人性。
人们都喜欢那种即时抓取、即时反馈。
但对于许多现有的工作流程,我认为我们需要学会将任务交给人工智能代理,并耐心等待几分钟,甚至几个小时的回复。
但就像我见过很多新手经理把某件事交给某人,然后五分钟后就去查看一样,对吧?也是如此。
我们也需要对一些我们的人工智能代理进行这样的操作。
我觉得我总是听到一些lauand。
然后,一个重要的trenfast hocongenerators很重要,因为有了这些代理,我们可以反复进行工作。
所以这个元素正在生成令牌,以便能够生成令牌的速度比任何人阅读都要快,这真是太棒了。
我认为,即使是稍微低质量的语言模型快速生成更多的标记,可能会比更好的语言模型慢速生成的标记产生更好的结果。
也许这有点争议,因为它可能让你在这个循环中多转几次,就像我在第一张幻灯片上展示的gpc和代理架构的结果以及candidellee一样。
我真的很期待cfive、clock 4、gpt5、Gemini I 2.0以及所有这些其他的one、four型号在架构中的表现。
我感觉如果你期待在gpt5零样本上运行你的项目,你可能会发现某些应用的性能实际上比你想象的更接近那个水平,尤其是在进行推理时。
但在早期的模型上,我认为这是一个重要的趋势。
老实说,通往AGI的道路感觉像是一段有明确目的地的旅程。但我认为这种代理工作队伍可以帮助我们在这段漫长的旅程中迈出小小的一步。


AI Agent的设计模式 := 反思 + 规划 + 工具使用 + 多智能体协作 + 记忆 | 个人观点
AI Agent 设计模式的分类与案例实践
AI Ahent 反思模式


适用场景
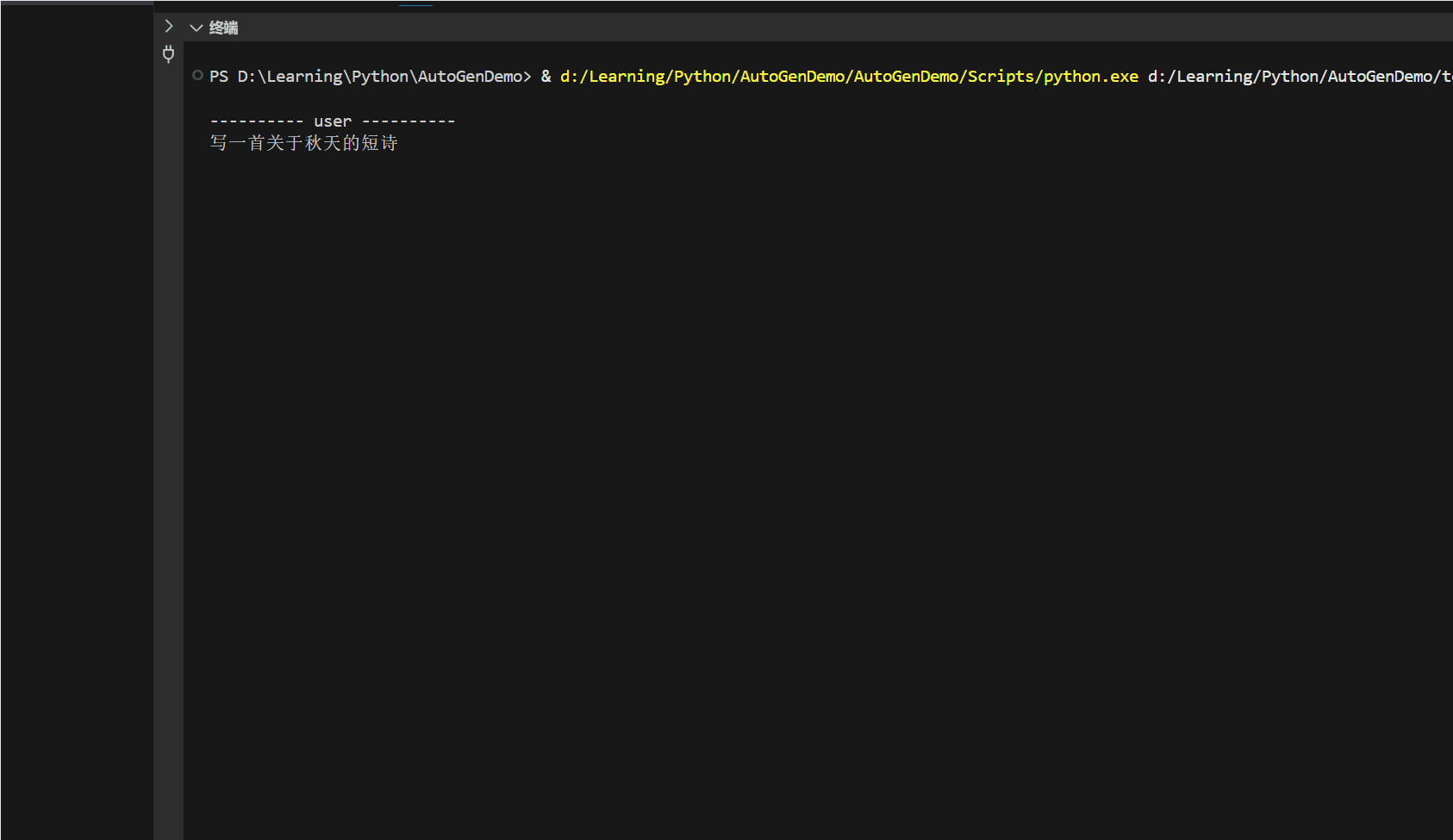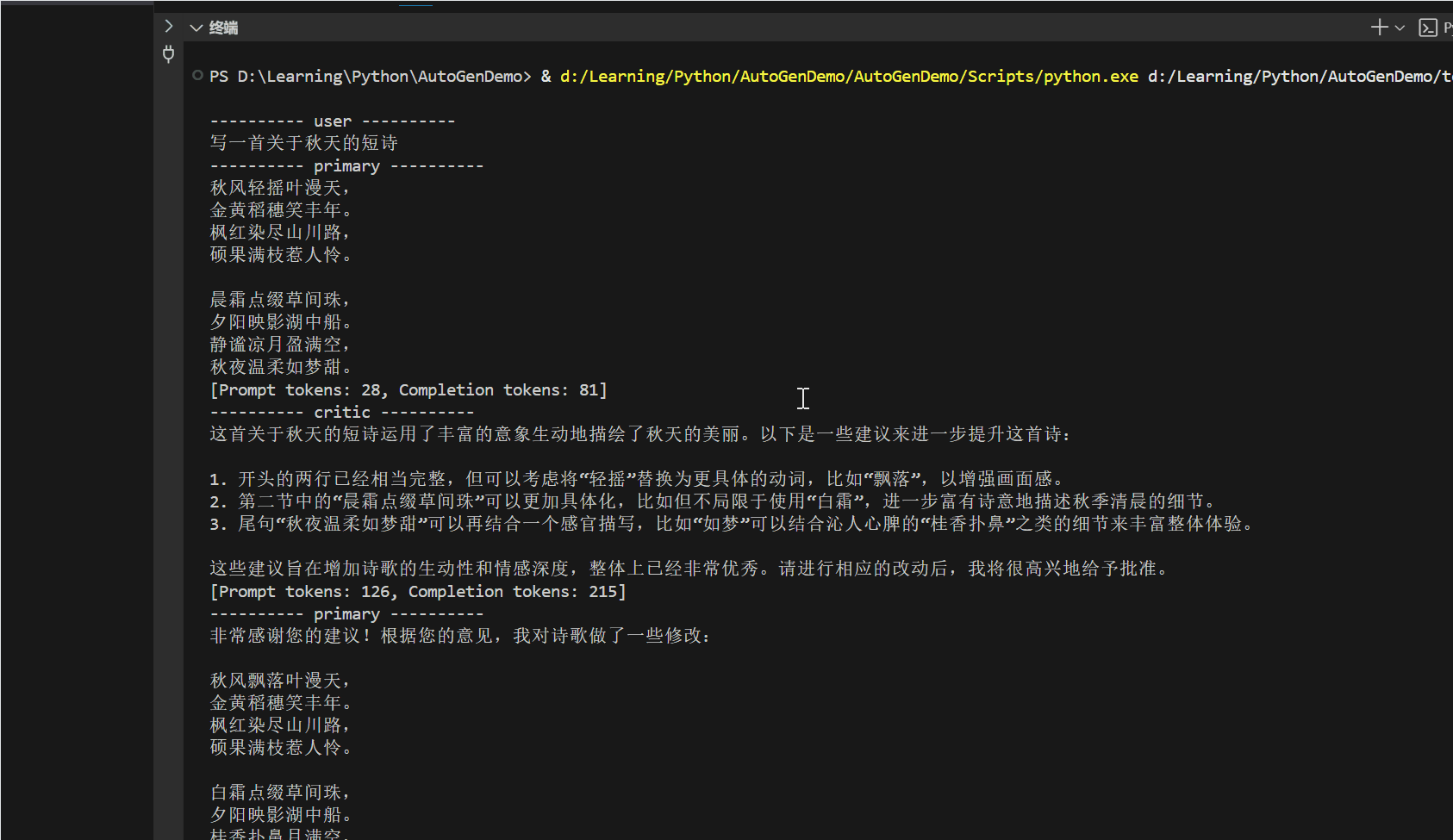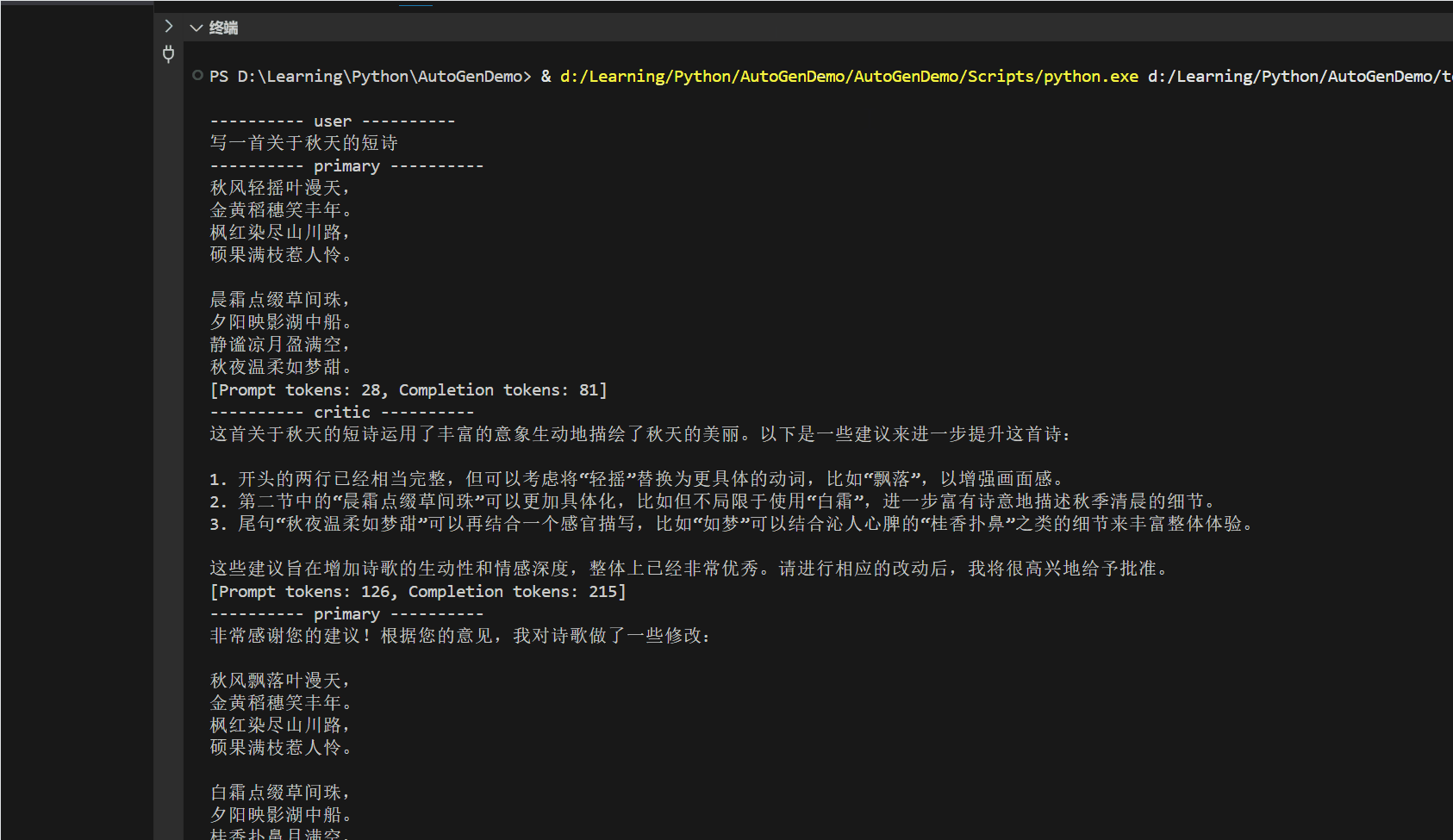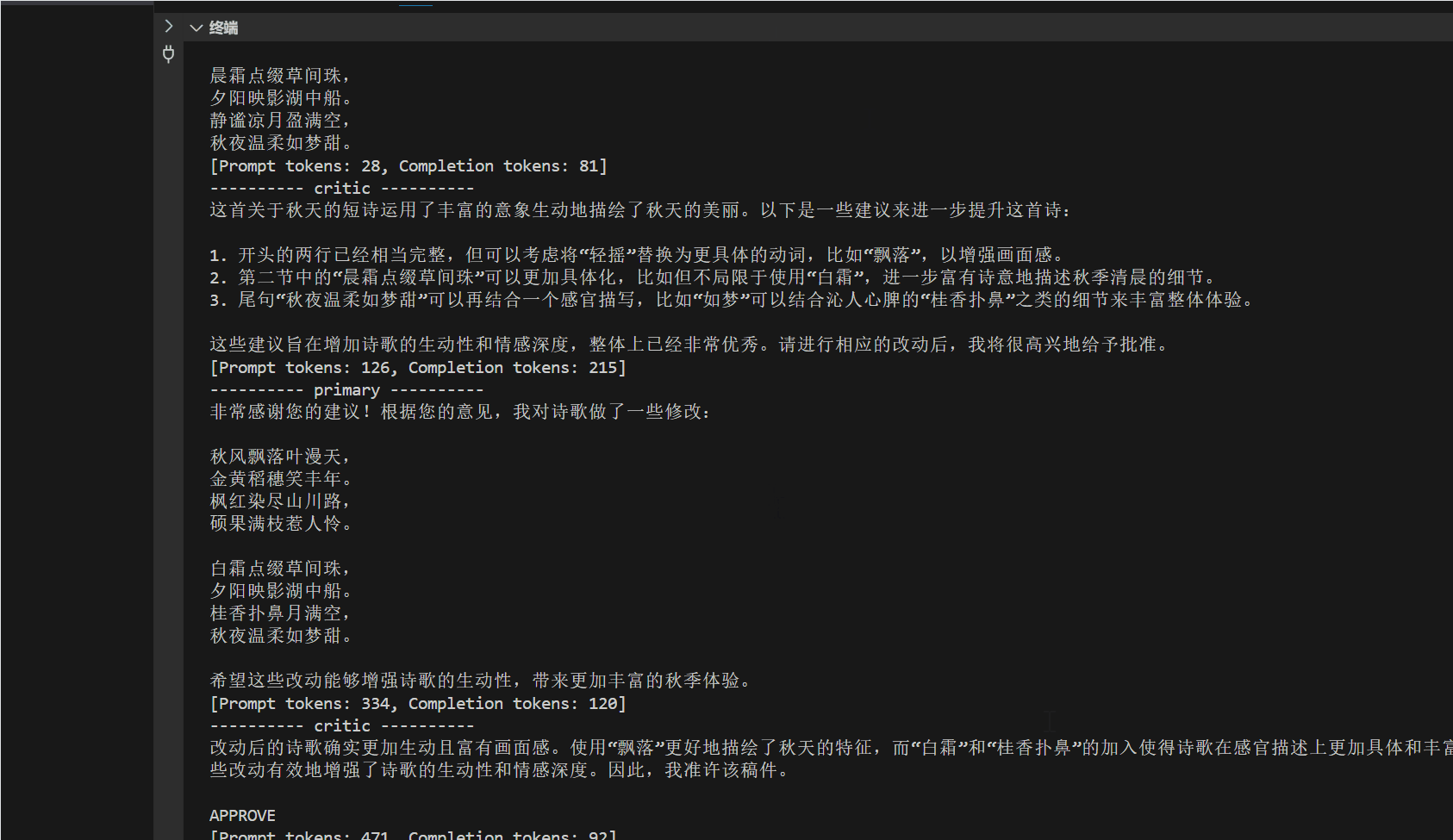
案例:AI 写一篇电商产品文案
“这款新上市的智能手表功能强大,续航持久,性价比高,喜欢的朋友赶快下单吧!”
- 开始反思过程
自我检查 1:信息具体度
❌ “功能强大” – 太空泛
❌ “续航持久” – 没有数据
❌ “性价比高” – 缺乏对比
❌ “赶快下单” – 硬推销
改进方向:
- 需要具体功能点
- 需要实际数据
- 需要价格信息
- 需要柔性表达
“这款智能手表配备心率监测、睡眠分析、运动记录等健康功能,
1600mAh 电池可持续使用 7 天,售价 899 元比同类产品低 20%,欢迎体验。”
用户自我检查 2:
❓ 用户真正关心什么?
“无论是清晨跑步还是夜间睡眠,这款智能手表都能 24 小时守护您的健康。心率异常自动提醒、专业运动指导、深度睡眠分析,让您对身体状态了如指掌。7 天续航无需频繁充电,899 元的亲民价格,让健康管理不再是负担。”
自我检查 3:完整性
✓ 场景具体
✓ 功能明确
✓ 数据支撑
✓ 情感共鸣
✓ 价值主张
AI Agent 工具使用模式
LLM 拥有网络搜索、代码执行或任何其他功能
来帮助其收集信息、采取行动或处理数据。


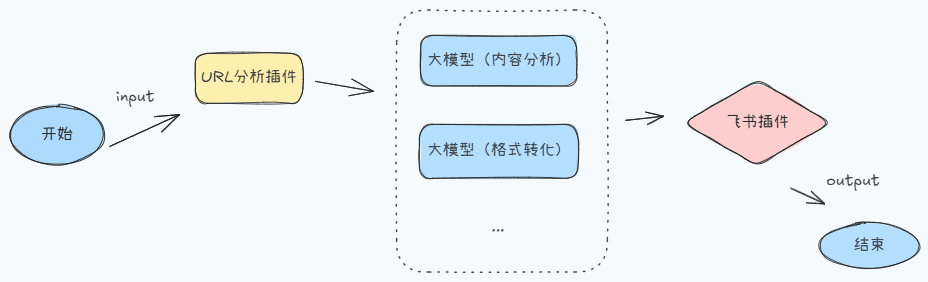
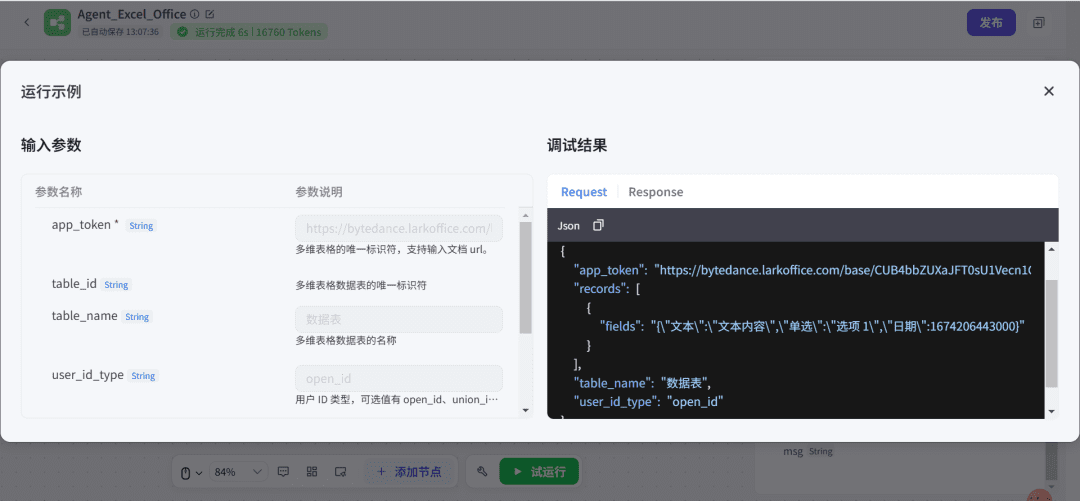
案例:帮用户分析一家公司的财务状况
1 数据收集阶段
- 1.2 原始数据获取
↓ 抓取最新财报 PDF
↓ 提取关键财务数据
↓ 获取实时股价信息
↓ 采集行业对标数据
2 数据处理阶段
- 2.2 处理流程:
↓ 格式标准化
↓ 异常值处理
↓ 计算财务指标
↓ 生成对比图表
3 分析输出阶段
可视化工具
报告生成器
格式转换器
- 3.2 输出内容:
↓ 关键指标图表
↓ 同业对比分析
↓ 风险提示报告
↓ 投资建议生成

AI Agent 规划模式
LLM 提出并执行一个多步骤计划来实现目标(例如,撰写论文大纲、进行在线研究,然后撰写草稿……) .


案例:春节旅游规划








AI Agent 多智能体模式
- 多智能体协作(Multi-agent collaboration):
多个 AI 智能代理一起工作,分配任务并讨论和辩论想法,以提出比单个智能体更好的解决方案。


案例:小红书旅游博主创作多智能体协作

主题规划师思考过程
目标受众:25-35岁,追求品质生活,向往慢生活
热门话题:#小众不密旅行 #摄影打卡 #文艺复古风
关键痛点:想拍出高级感/避开旅游团/体验本地生活
差异化:避开传统攻略,突出体验和氛围感
内容采集员数据分析
热门元素分析:
- "绝绝子"打卡点提及频率:38%
- "人少但惊艳"景点互动率:+45%
- "复古风"相关内容点赞:+67%
- "本地人带逛"内容转发率:+89%
爆款标题关键词:
- 高情绪词:绝绝子/神仙/震撼/绝美
- 独特性词:隐藏/私藏/绝版/神秘
- 感官词:治愈/温柔/浪漫/惊艳
文案创作师初稿
标题方案1:
「我在大理当了3年民宿房东 这些绝绝子景点90%游客都不知道」
标题方案2:
「大理|偷偷藏着10个绝美秘境 随手拍都是天青色」
标题方案3:
「震撼!大理隐藏版民宿景点首曝光 天天对着洱海发呆」
团队讨论优化后,最终敲定
标题:
「大理绝美古城|本地人才知道的8个隐藏款小众景点 邂逅最惊艳的天青色」
开头:
"去过25次大理,这次的晴天率100%🌞
分享8个绝绝子纯净景点,人少景美还能拍出ins风
附赠:民宿老板的秘藏咖啡店打卡地图🗺️"
内容框架:
1️⃣ 私藏景点TOP8(每个配10秒竖屏视频)
- 无人机视角下的洱海日落
- 小众观景台取景
- 绝美日出机位分享
- 本地人遛弯路线
2️⃣ 拍照机位详解
- 绝美光线时间点
- 构图示意图
- 小红书爆款pose
3️⃣ 深度体验路线
- 文艺咖啡店路线
- 复古银饰工作室
- 私房美食地图
4️⃣ 实用贴士
- 交通住宿攻略
- 花费参考
- 行程建议
结尾互动:
"你最爱大理的哪个瞬间?评论告诉我,抽个宝子送洱海日落拍摄绝佳位置!"
视觉设计师补充
封面设计:
- 主图:清晨洱海蓝色渐变天空
- 构图:上下三分法,留白突出天空
- 滤镜:低饱和柔和色调
- 字体:搭配手写风格
9宫格规划:
1⃣️ 洱海日出全景
2⃣️ 人物背影剪影
3⃣️ 古城街巷细节
4⃣️ 文艺咖啡店一角
5⃣️ 绝美观景台取景
6⃣️ 银饰工作室匠人
7⃣️ 隐藏餐厅美食
8⃣️ 民宿阳台视角
9⃣️ 日落延时视频
合规审核意见
建议优化:
1. 添加"景区需提前预约"提醒
2. 标注价格区间,避免虚标
3. 补充旅游旺季提示
4. 添加安全提示信息
AI Agent 设计模式的分类与案例实践2
本章节,是以上一章节作为总的指导思想,对细分的 AI Aegnt 设计模式相关论文的总结、归纳。
ReAct 模式
ReAct模式是最早出现的Agent设计模式,目前也是应用最广泛的。- 从ReAct出发,有两条发展路线:
- 一条更偏重Agent的规划能力,包括: REWOO、Plan & Execute、LLM Compiler。
- 另一条更偏重反思能力,包括: Basic Reflection、Reflexion、Self Discover、LATS。

Intro
通过结合语言模型中的推理(reasoning)和行动(acting)来解决多样化的语言推理和决策任务。
ReAct 提供了一种更易于人类理解、诊断和控制的决策和推理过程。
- 它的典型流程如下图所示,可以用一个有趣的循环来描述:
思考(Thought)→ 行动(Action)→ 观察(Observation) | 简称TAO循环
- 思考(Thought):面对一个问题,我们需要进行深入的思考。这个思考过程是关于如何定义问题、确定解决问题所需的关键信息和推理步骤。
- 行动(Action):确定了思考的方向后,接下来就是行动的时刻。根据我们的思考,采取相应的措施或执行特定的任务,以期望推动问题向解决的方向发展。
- 观察(Observation):行动之后,我们必须仔细观察结果。这一步是检验我们的行动是否有效,是否接近了问题的答案。
- 循环迭代

- 如果观察到的结果并不匹配我们的预期答案,那么:就需要回到思考阶段,重新审视问题和行动计划。
这样,我们就开始了新一轮的TAO循环,直到找到问题的解决方案。
- 和
ReAct相对应的是Reasoning-Only和Action-Only。
在Reasoning-Only的模式下,大模型会基于任务进行逐步思考,并且不管有没有获得结果,都会把思考的每一步都执行一遍。
在Action-Only的模式下,大模型就会处于完全没有规划的状态下,先进行行动再进行观察,基于观察再调整行动,导致最终结果不可控。

reason-only模式 vs. action-only模式
- 假设我们正在构建一个智能助手,用于管理我们的日程安排。
- 在
reason-only模式中,智能助手专注于分析和推理,但不直接采取行动。
智能助手分析这句话,确定明天的会议时间、地点等细节。
它可能会提醒你:“明天下午3点有个会议,在公司会议室。”
- 在
action-only模式中,智能助手专注于执行任务,但不做深入的推理或分析。
- 你告诉智能助手:“把我明天的会议改到上午10点。”
智能助手立即执行这个任务,将会议时间修改为上午10点。
它可能会简单确认:“您的会议已改到明天上午10点。”
- 在
ReAct模式中,智能助手结合推理和行动,形成一个循环的感知-动作循环。不仅分析了你的需求(推理),还实际修改了日程安排(行动)。
- 你告诉智能助手:“我明天有个会议,但我想提前到上午10点。”
智能助手首先分析这句话,确定会议的原始时间和地点(感知阶段)。
然后,它更新你的日程安排,将会议时间改为上午10点(决策和动作执行阶段)。
最后,智能助手确认修改,并提供额外的信息:“您的会议已成功改到明天上午10点。提醒您,会议地点不变。
ReAct 的实现过程
下面通过实际的源码,详细介绍ReAct模式的实现方法。
step1 准备Prompt模板
在实现ReAct模式的时候,首先需要设计一个清晰的Prompt模板,主要包含以下几个元素:
- 思考(Thought):这是推理过程的文字展示,阐明我们想要LLM帮我们做什么,为了达成目标的前置条件是什么
- 行动(Action):根据思考的结果,生成与外部交互的指令文字,比如需要LLM进行外部搜索
- 行动参数(Action Input):用于展示LLM进行下一步行动的参数,比如LLM要进行外部搜索的话,行动参数就是搜索的关键词。主要是为了验证LLM是否能提取准确的行动参数
- 观察(Observation):和外部行动交互之后得到的结果,比如LLM进行外部搜索的话,那么观察就是搜索的结果。
Prompt模板示例:
Answer the following questions as best you can. You have access to the following tools:
{tool_names}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {query}
step2 构建Agent
一个ReAct Agent需要定义好以下元素:
- llm:背后使用的LLM大模型
- tools:后续会用到的Tools集合
- stop:什么情况下ReAct Agent停止循环
class LLMSingleActionAgent {
llm: AzureLLM
tools: StructuredTool[]
stop: string[]
private _prompt: string = '{input}'
constructor({ llm, tools = [], stop = [] }: LLMSingleActionAgentParams) {
this.llm = llm
this.tools = tools
if (stop.length > 4)
throw new Error('up to 4 stop sequences')
this.stop = stop
}
}
Tools有2个最重要的参数: name和description。
Name就是函数名description是工具的自然语言描述
LLM 根据description来决定是否需要使用该工具。
工具的描述应该非常明确,说明工具的功能、使用的时机以及不适用的情况。
export abstract class StructuredTool {
name: string
description: string
constructor(name: string, description: string) {
this.name = name
this.description = description
}
abstract call(arg: string, config?: Record<string, any>): Promise<string>
getSchema(): string {
return `${this.declaration} | ${this.name} | ${this.description}`
}
abstract get declaration(): string
}
我们先简单地将两个描述信息拼接一下,为Agent提供4个算数工具:
1. Addition Tool: A tool for adding two numbers
2. Subtraction Tool: A tool for subtracting two numbers
3. Division Tool: A tool for dividing two numbers
4. Multiplication Tool: A tool for multiplying two numbers
一个很有意思的事情是,这几个算数工具函数并不需要实际的代码,大模型可以仅靠自身的推理能力就完成实际的算数运算。
当然,对于更复杂的工具函数,还是需要进行详细的代码构建。
step4 循环执行
- 执行器
executor是在Agent的运行时,协调各个组件并指导操作。还记得ReAct模式的流程吗?Thought、Action、Observation、循环,Executor的作用就是执行这个循环。
class AgentExecutor {
agent: LLMSingleActionAgent
tools: StructuredTool[] = []
maxIterations: number = 15
constructor(agent: LLMSingleActionAgent) {
this.agent = agent
}
addTool(tools: StructuredTool | StructuredTool[]) {
const _tools = Array.isArray(tools) ? tools : [tools]
this.tools.push(..._tools)
}
}
executor会始终进行如下事件循环直到目标被解决了或者思考迭代次数超过了最大次数:
- 根据之前已经完成的所有步骤(Thought、Action、Observation)和 目标(用户的问题),规划出接下来的Action(使用什么工具以及工具的输入)
- 检测是否已经达成目标,即Action是不是ActionFinish。是的话就返回结果,不是的话说明还有行动要完成
- 根据Action,执行具体的工具,等待工具返回结果。工具返回的结果就是这一轮步骤的Observation
- 保存当前步骤到记忆上下文,如此反复
async call(input: promptInputs): Promise<AgentFinish> {
const toolsByName = Object.fromEntries(
this.tools.map(t => [t.name, t]),
)
const steps: AgentStep[] = []
let iterations = 0
while (this.shouldContinue(iterations)) {
const output = await this.agent.plan(steps, input)
console.log(iterations, output)
// Check if the agent has finished
if ('returnValues' in output)
return output
const actions = Array.isArray(output)
? output as AgentAction[]
: [output as AgentAction]
const newSteps = await Promise.all(
actions.map(async (action) => {
const tool = toolsByName[action.tool]
if (!tool)
throw new Error(`${action.tool} is not a valid tool, try another one.`)
const observation = await tool.call(action.toolInput)
return { action, observation: observation ?? '' }
}),
)
steps.push(...newSteps)
iterations++
}
return {
returnValues: { output: 'Agent stopped due to max iterations.' },
log: '',
}
}
step5 实际运行
我们提出一个问题,看看Agent怎么通过ReAct方式进行解决。
“一种减速机的价格是750元,一家企业需要购买12台。每台减速机运行一小时的电费是0.5元,企业每天运行这些减速机8小时。请计算企业购买及一周运行这些减速机的总花费。”
describe('agent', () => {
const llm = new AzureLLM({
apiKey: Config.apiKey,
model: Config.model,
})
const agent = new LLMSingleActionAgent({ llm })
agent.setPrompt(REACT_PROMPT)
agent.addStop(agent.observationPrefix)
agent.addTool([new AdditionTool(), new SubtractionTool(), new DivisionTool(), new MultiplicationTool()])
const executor = new AgentExecutor(agent)
executor.addTool([new AdditionTool(), new SubtractionTool(), new DivisionTool(), new MultiplicationTool()])
it('test', async () => {
const res = await executor.call({ input: '一种减速机的价格是750元,一家企业需要购买12台。每台减速机运行一小时的电费是0.5元,企业每天运行这些减速机8小时。请计算企业购买及一周运行这些减速机的总花费。' })
expect(res).toMatchInlineSnapshot(`
{
"log": "Final Answer: The total cost of purchasing and operating the gearboxes for a week is 9336 yuan.",
"returnValues": {
"output": "The total cost of purchasing and operating the gearboxes for a week is 9336 yuan.",
},
}
`)
}, { timeout: 50000 })
})
我们来看一下Agent的输出,以及Agent在这个过程,是如何思考和行动的。
可以看到,通过Thought、Action、Observation的循环,AI Agent很好地一步步完成最终答案的输出。
Question:一种减速机的价格是750元,一家企业需要购买12台。每台减速机运行一小时的电费是0.5元,企业每天运行这些减速机8小时。请计算企业购买及一周运行这些减速机的总花费
Thought:I need to calculate the total cost of purchasing and operating the gearboxes for a week.
Action: Multiplication Tool
Action Input: [750, 12]
Observation: 9000
Thought: Now I need to calculate the cost of operating the gearboxes for a day.
Action: Multiplication Tool
Action Input: [0.5, 8, 12]
Observation: 48
Thought: Now I need to calculate the cost of operating the gearboxes for a week.
Action: Multiplication Tool
Action Input: [48, 7]
Observation: 336
Thought: Now I need to calculate the total cost of purchasing and operating the gearboxes for a week.
Action: Addition Tool
Action Input: [9000, 336]
Observation: 9336
总结
- 在
AI Agent的多种实现模式中,ReAct模式是最早出现、也是目前使用最广泛的模式。
ReAct的核心思想就是模拟人思考和行动的过程,通过Thought、Action、Observation的循环,一步步解决目标问题。ReAct模式也存在很多的不足:
- 首先,LLM大模型的通病,即产出内容不稳定,不仅仅是输出内容存在波动,也体现在对复杂问题的分析,解决上存在一定的波动
- 然后,成本,采用
ReAct方式,我们是无法控制输入内容的。因为在任务提交给LLM后,LLM对任务的拆解、循环次数是不可控的。因此存在一种可能性,过于复杂的任务导致Token过量消耗。
- 最后,响应时间,比起大部分API接口毫秒级的响应,LLM响应时间是秒级以上。在ReAct模式下,这个时间变得更加不可控。因为无法确定需要拆分多少步骤,需要访问多少次LLM模型。因此在在秒级接口响应的背景下,做成同步接口显然是不合适的,需要采用异步的方式。而异步方式,又会影响用户体验,对应用场景的选择又造成了限制。
- 但是无论如何,ReAct框架提出了一种非常好的思路,让现有的应用得到一次智能化的进化机会。现在很多场景已经有了非常成熟的ReAct Agent应用,比如智能客服、知识助手、个性化营销、智能销售助理等等。
推荐文献
Plan and Solve/PS 模式
出处与概要
PlanandSolve模式适用于需要详细规划和可能需要调整的任务。
这种模式通过先制定计划再执行的方式,允许AI在面对任务变化时灵活调整策略,类似于烹饪过程中根据食材的实际情况调整菜谱。
Plan-and-Solve (PS) 设计模式是一种旨在提升大型语言模型(LLMs)在多步推理任务上表现的新策略。
它改进了零样本链式思维(Zero-shot-CoT)提示方法,增强了模型的推理能力。
与一次只处理一步的 ReACT 设计模式不同,PS 更加注重长期计划。
该方法由论文《Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models》提出。

github : https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting
- 大型语言模型(LLMs)最近在各种自然语言处理(NLP)任务中表现出色。
- 为了解决多步推理任务,少量示例链式思考(
CoT)提示包括一些手动制作的逐步推理演示,这使得LLMs能够明确生成推理步骤并提高其推理任务的准确性。
- 为了消除手动努力,零次示例CoT将目标问题陈述与“让我们一步一步地思考”作为输入提示连接起来,提供给
LLMs。
- 尽管
Zero-shot-CoT取得了成功,但它仍然存在3个缺陷:计算错误、遗漏步骤错误和语义误解错误。
- 为了解决遗漏步骤错误,我们提出了计划与解决(
PS)提示。它包括2个组成部分:
- 首先,制定一个计划将整个任务划分为更小的子任务,然后根据计划执行这些子任务。为了解决计算错误并提高生成推理步骤的质量,我们通过更详细的指令扩展
PS提示,并推导出PS+提示。
- 我们在三个推理问题上的十个数据集上评估了我们提出的提示策略。
GPT-3上的实验结果表明,我们提出的零次示例提示在所有数据集上都显著优于Zero-shot-CoT,与Zero-shot-Program-of-Thought提示相当或更优,并且在数学推理问题上与8次示例CoT提示具有可比的性能。
代码可以在 https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting 找到。
- 制定计划:将任务分解为更小的子任务。
- 执行计划:按照计划一步步完成子任务。
这种方法可以减少因遗漏步骤和计算错误导致的问题,提高推理过程的质量。
工作流程
Step 1: 生成推理过程
- 在这个步骤中,模型会通过一个模板生成推理过程和问题的答案。
模板包含问题描述和指令,例如:
Let’s first understand the problem and devise a plan to solve the problem. Then, let's carry out the plan and solve the problem step by step.
翻译成中文:让我们首先理解这个问题,并制定一个解决问题的计划。然后,按照计划一步步解决问题。

Step 2: 提取答案
- 在这个步骤中,使用另一个提示引导模型从生成的推理文本中提取最终答案。
这个提示包括提取答案的指令,例如:
Therefore, the answer (arabic numerals) is
通过这种方法,模型能返回所需形式的最终答案。
延申:Plan-and-Execute 设计模式
Langchain 实现中改进了 PS 设计模式,提出了 Plan-and-Execute 设计模式。
这个新模式在 PS 的基础上增加了任务执行和重新规划步骤,使流程更接近复杂的代理系统(Complex Agent System)。
详细代码见: langgraph/examples/plan-and-execute/plan-and-execute.ipynb at main · langchain-ai/langgraph · GitHub

这一改进进一步增强了模型处理复杂任务时的【灵活性】和【准确性】。
Reason without Observation (REWOO) : 高效增强语言模型中解偶观测和推理
论文
标题: 高效增强语言模型的解耦推理
https://arxiv.org/pdf/2305.18323
https://github.com/AI-Natural-Language-Processing-Lab/ReWOO-Decoupling-Reasoning-from-Observations-for-Efficient-Augmented-Language-Models

一看名字,除了一个是老外,全是中国人
增强语言模型(ALMs)将大型语言模型(LLMs)的推理能力与允许知识检索和操作执行的工具混合在一起。
现有ALM系统触发LLM思维过程,同时以交错的方式从这些工具中提取观察结果。
具体来说,LLM调用外部工具的原因,暂停以获取工具的响应,然后根据前面的所有响应令牌决定下一个操作。
这种范例虽然简单且易于实现,但由于冗余提示和重复执行,通常会导致巨大的计算复杂性。
本研究首次解决了这些挑战,提出了一种模块化范式ReWOO(无观察推理),将推理过程与外部观察分离,从而显着减少了令牌消耗。
对6个公共NLP基准和一个精心策划的数据集的综合评估显示,我们提出的方法具有一致的性能增强。
值得注意的是,ReWOO在HotpotQA上实现了5×token效率和4%的精度提高,HotpotQA是一个多步骤的测试基准。
此外,ReWOO还展示了工具故障场景下的鲁棒性。
除了快速高效之外,将参数化模块与非参数化工具调用解耦可以使指令微调将llm卸载到更小的语言模型中,从而大大减少模型参数。
我们的示例工作将推理能力从175B GPT3.5转移到7B LLaMA,展示了真正高效和可扩展的ALM系统的巨大潜力。
完整的代码、模型和数据被发布以供复制
- 如图所示,
ReWOO模式将ALM的关键组件(逐步推理、工具调用和摘要)划分为3个独立的模块:Planner、Worker和Solver。
Solver分解一项任务,制定一个相互依存的规划蓝图(blueprint),每个规划都分配给Worker。
Worker从工具中检索外部知识提供证据。
Solver综合所有规划和证据,生成初始任务的最终答案。

- 如图所示,
ReWOO将LLM的推理过程与外部工具分离,避免了观察相关推理中交错提示的冗余,从而显著减少了token使用,提高了提示效率。
图(a)依赖于观察的推理中,用户请求的任务首先用上下文提示和示例进行包装,然后输入LLM启动推理过程。LLM生成一个想法(T)和一个动作(a),然后等待来自工具的观察(O)。观察结果被叠加到提示历史记录中,开始下一个LLM调用。
图(b)在ReWOO中,Planner立即生成一个相互依赖的规划列表(P),并调用Worker从工具中获取证据(E)。P和E与任务相结合,然后输入到Solver中获得最终答案。
注意:在(a)中,上下文和示例被重复输入LLM,从而导致提示冗余。

- 为了全面评估
ReWOO,在6个多步知识密集型NLP基准和一个精心筛选数据集上进行了实验。
ReWOO的评估基线包括两种非ALM的提示方法,直接提示(Direct Prompting)和思想链(CoT)提示[12],以及一种流行的ALM模式ReAct[1],其特征是基于观察的推理。
如图提供了下表中基准的平均性能,证明了ReWOO相对于其依赖观测的对手的一致效率增益。
此外,通过指令调优[13]和特殊化(Specialization)[14]展示了ReWOO在系统参数效率方面的潜力。
在零样本设置中,具有少量epochs的LLaMa 7B微调,可以与GPT3.5相当,这突出了ReWOO促进轻量级和可扩展ALM部署的能力。

ALM的一个常见问题是,绑定参数语言模型和非参数工具调用,会使端到端训练复杂化[2]。
为了缓解这个问题,Toolformer[15]以自监督的方式对工具增强语料库上的语言模型进行了微调。
同样,ReAct试图对从HotpotQA收集的推理痕迹进行推理微调[16]。
然而,这些方法在有限的设置中进行了测试。
具体而言,Toolformer仅限于对工具进行独立采样,因此无法在多步推理任务中发挥作用。
ReAct在微调中完成“思想-行动-观察“轨迹,还是未经证实能很好推广到未见过的任务或工具集。
ReWOO将推理与工具调用解耦,允许在优化Planner模块可预见推理的通用能力,因为在微调过程中不会暴露任何工具响应。
受最近特殊化(Specialization)框架[14]的启发,试图从GPT-3.5中引出可预见的推理,并将其卸载到LLaMa 7B[17]中,如图所示。

- 首先用
text-davinci-003在HotpotQA和TriviaQA的混合训练数据上推断4000个(Plan,#E)蓝图。
按照自举方法[18],对那些给出正确答案的进行采样,产生大约2000个Planner指令数据。
预训练的LLaMa 7B是在52k个自指令数据集上进行微调的指令,产生近似于text-davinci-003的通用能力Alpaca[13]7B。
随后,在Planner指令数据上进一步微调Alpaca-7B,获得专门用于可预见推理的7B Planner模型。
最后,在多个基准上评估专业化的潜力,用GPT-3.5、Alpaca 7B和Planner 7B取代ReWOO Planner。
推荐文献
LLMCompiler
论文/源起

https://github.com/SqueezeAILab/LLMCompiler
LLM Compiler是伯克利大学的Squeeze AI Lab于2023年12月提出的新项目。
这个项目在ReWOO引入的变量分配的基础上,进一步训练大语言模型生成一个有向无环图(Directed Acyclic Graph,DAG,如下图所示)类的规划。
DAG可以明确各步骤任务之间的依赖关系,从而并行执行任务,实现类似处理器“乱序执行”的效果,可以大幅加速AI Agent完成任务的速度。

【论文摘要】
最近llm的推理能力使它们能够执行外部函数调用,以克服其固有的局限性,
例如知识截断、糟糕的算术技能或缺乏对私有数据的访问。
这一发展使法学硕士能够根据上下文选择和协调多种功能,以解决更复杂的问题。
然而,当前的函数调用方法通常需要对每个函数进行顺序推理和操作,
这可能导致高延迟、高成本,有时还会导致不准确的行为。
为了解决这个问题,我们引入了LLMCompiler,它并行执行函数以有效地协调多个函数调用。
从经典编译器的原理中汲取灵感,LLMCompiler通过三个组件实现并行函数调用:
(i)函数调用计划器,为函数调用制定执行计划;
(ii)任务提取单元,调度调用任务的函数;以及(iii)并行执行这些任务的执行人。
LLMCompiler会自动为函数调用生成一个优化的编排,可以用于开源和闭源模型。
我们在一系列具有不同函数调用模式的任务上对LLMCompiler进行了基准测试。
与react相比,我们观察到持续的延迟加速高达3.7倍,成本节省高达6.7倍,精度提高高达9%。
这种模式通过优化任务编排,使得AI能够同时处理多个任务,从而大幅度提升处理速度。

如下图,向Agent提问“微软的市值需要增加多少才能超过苹果的市值?”,Planner并行搜索微软的市值和苹果的市值,然后进行合并计算。

主要组件
LLM Compiler设计模式主要有以下组件:
Planner:输出流式传输任务的DAG,每个任务都包含一个工具、参数和依赖项列表。相比ReWOO的Planner,依赖项列表是最大的不同。Task Fetching Unit:调度并执行任务,一旦满足任务的依赖性,该单元就会安排任务。由于许多工具涉及对搜索引擎或LLM的其他调用,因此额外的并行性可以显著提高速度。Joiner:由LLM根据整个历史记录(包括任务执行结果),决定是否响应最终答案或是否将进度重新传递回Planner。
工作原理
Planner 接收来自用户的输入,输出流式传输任务的DAGTask Fetching Unit从式传输任务DAG中读取任务,通过处理工具并行执行Task Fetching Unit将状态和结果传递给Joiner(或Replanner),Joiner来决定是将结果输出给用户,还是增加更多任务交由Task Fetching Unit处理

推荐文献
An LLM Compiler for Parallel Function Calling – arxiv.org
https://arxiv.org/pdf/2312.04511
Basic Reflection : 基础反思/师生互动/左右互博模式
Basic Reflection,即“基础反思”模式,巧妙地将AI Agent拆分为2个角色:Generator(生成器)与Reflector(反射器)。
可以类比于师生互动、左右互博。
- 左手是
Generator,负责根据用户指令生成结果;
- 右手是
Reflector,来审查Generator的生成结果并给出建议。
在左右互搏的情况下,Generator生成的结果越来越好,Reflector的检查越来越严格,输出的结果也越来越有效。
Basic Reflection模式通过模拟师生互动的方式,让AI在生成答案后能够得到反馈,并据此进行修正。
这种模式提高了Al生成内容的质量和准确性。
原理
- Generator接收来自用户的输入,输出initial response
- Reflector接收来自Generator的response,根据开发者设置的要求,给出Reflections,即评语、特征、建议
- Generator再根据Reflector给出的反馈进行修改和优化,输出下一轮response
- 循环往复,直到循环次数

实现过程
step1 构建Generator
先构建一个能够生成5段话的文章生成器。
- 首先,我们给Generator约定了Prompt,告诉Generator具体的角色和目标,并且要求如果用户给出建议,需要给出修改后的版本
- 然后,选择LLM模型,并构建Generator
- 最后,要求输出Generator生成的内容
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_fireworks import ChatFireworks
prompt = ChatPromptTemplate.from_messages(
[
(
“system”,
“You are an essay assistant tasked with writing excellent 5-paragraph essays.”
” Generate the best essay possible for the user’s request.”
” If the user provides critique, respond with a revised version of your previous attempts.”,
),
MessagesPlaceholder(variable_name=”messages”),
]
)
llm = ChatFireworks(
model=”accounts/fireworks/models/mixtral-8x7b-instruct”,
model_kwargs={“max_tokens”: 32768},
)
generate = prompt | llm
essay = “”
request = HumanMessage(
content=”Write an essay on why the little prince is relevant in modern childhood”
)
for chunk in generate.stream({“messages”: [request]}):
print(chunk.content, end=””)
essay += chunk.content
下面是Generator的Initial Response,可以看出Generator虽然按照我们的要求生成了初始回复,但是回复的整体质量还有很大的提升空间。
Title: The Relevance of The Little Prince in Modern Childhood
The Little Prince, a novella by Antoine de Saint-Exupéry, has been a childhood favorite for generations. Despite being published over seven decades ago, its timeless themes continue to resonate with modern children, making it highly relevant in contemporary childhood.
Firstly, the story explores the complex nature of human relationships, which is particularly relevant for modern children growing up in an increasingly connected yet impersonal world. Through the little prince’s encounters with various grown-ups on different planets, the book highlights the importance of genuine connections and understanding. In an age where digital communication often replaces face-to-face interaction, this message is more pertinent than ever. The Little Prince encourages children to look beyond superficial relationships and seek deeper connections, fostering empathy and emotional intelligence.
Secondly, the book deals with the concept of responsibility and self-discovery, elements that are integral to a child’s growth. The little prince’s journey is essentially a quest for self-discovery, leading him to realize his responsibility towards his beloved rose. This narrative encourages modern children to embrace their individuality while understanding the significance of their actions. In a society that often overlooks the emotional well-being of children, The Little Prince offers a refreshing perspective on personal growth and responsibility.
Thirdly, the book addresses the challenging theme of loss and bereavement. The little prince’s departure from his asteroid and his subsequent encounters with the fox and the snake are profound reflections on the inevitability of loss and the importance of cherishing relationships. In a time when children are exposed to various forms of loss, from the death of loved ones to environmental degradation, The Little Prince provides a gentle yet powerful way to understand and cope with these experiences.
However, some critics argue that the book’s pace and abstract concepts might be challenging for modern children with short attention spans. To address this, a revised version could incorporate more visual elements and interactive activities to engage young readers better. Additionally, supplementary materials explaining the book’s themes in simpler terms could be provided for parents and educators to use in discussions with children.
In conclusion, The Little Prince remains relevant in modern childhood due to its exploration of human relationships, self-discovery, and loss. These themes, wrapped in a captivating narrative, offer valuable lessons for modern children. While some adaptations may be necessary to cater to the preferences of today’s children, the essence of the story remains a powerful tool for teaching emotional intelligence, personal growth, and resilience.
构建Reflector
- 针对Generator,我们构建一个专门的Reflector。
- 同样的,我们要先给Reflector约定Prompt,告诉Reflector“你是一名正在给论文评分的老师。请对用户的论文提出批评和建议,包括长度、深度、风格等要求。”
- 然后,选择LLM模型,并构建Reflector
reflection_prompt = ChatPromptTemplate.from_messages([
(
“system”,
“You are a teacher grading an essay submission. Generate critique and recommendations for the user’s submission.”
” Provide detailed recommendations, including requests for length, depth, style, etc.”,
),
MessagesPlaceholder(variable_name=”messages”),
])
reflect = reflection_prompt | llm
下面是针对Generator的Initial Response,Reflector反馈的评语和建议。Reflector给出了B+的评级,并且按照我们的要求,从文章的长度、深度、风格等维度给出了具体的建议和总结。
Essay Grade: B+
The essay you submitted provides a clear and well-structured argument about the relevance of The Little Prince in modern childhood. You have demonstrated a strong understanding of the text and its themes, and have effectively applied them to the context of contemporary childhood. However, there are some areas where improvement could be made to enhance the depth, style, and overall flow of your essay.
1. Length: While your essay is well-written and informative, it is relatively brief. Expanding on each point with more detailed analysis and examples would strengthen your argument and demonstrate a more comprehensive understanding of the text. Aim for a minimum of 500 words to allow for a more in-depth exploration of your ideas.
2. Depth: Although you have touched upon the relevance of the novel’s themes, further analysis is needed to truly establish its significance in modern childhood. For example, when discussing the complex nature of human relationships, delve into how the digital age affects children’s communication skills, and how The Little Prince addresses this issue. Providing concrete examples from the text and connecting them to real-world scenarios will make your argument more compelling.
3. Style: To engage your readers more effectively, consider varying your sentence structure and length. Using a mix of simple, compound, and complex sentences will improve the flow of your essay and make it more engaging to read. Additionally, watch your tense consistency. Ensure that you maintain the same tense throughout your essay to avoid confusion.
4. Recommendations: While your suggestions for adaptation are a good start, they could be expanded upon to provide more comprehensive recommendations. For example, you may want to discuss different methods of incorporating visual elements and interactive activities, such as illustrations, quizzes, or discussion questions. This will demonstrate that you have thoughtfully considered the needs of modern children and have developed strategies to address these challenges.
5. Conclusion: Your conclusion could benefit from a stronger summarization of your key points and an assertive final statement about the relevance of The Little Prince in modern childhood. Tying all your arguments together in a concise and powerful manner will leave a lasting impression on your readers and solidify your position.
Overall, your essay is well-researched and provides a solid foundation for a compelling argument about the relevance of The Little Prince in modern childhood. With some expansion, deeper analysis, and stylistic improvements, your essay can achieve an even higher level of excellence.
step3 循环执行
- 接下来,我们就可以循环执行这个“生成 – 检查”的过程,重复规定的次数,或者约定当Generator的生成结果达到多少分时,停止循环。
- 大家可以看到,在循环过程中,我们也加入了人类的反馈建议,有助于Generator和Reflector学习迭代。
for chunk in generate.stream(
{“messages”: [request, AIMessage(content=essay), HumanMessage(content=reflection)]}
): print(chunk.content, end=””)
step4 构建流程图
下面,我们构建流程图,将Generator、Reflector等节点添加进来,循环执行并输出结果。
from typing import Annotated, List, Sequence
from langgraph.graph import END, StateGraph, START
from langgraph.graph.message import add_messages
from typing_extensions import TypedDict
class State(TypedDict):
messages: Annotated[list, add_messages]
async def generation_node(state: Sequence[BaseMessage]):
return await generate.ainvoke({“messages”: state})
async def reflection_node(messages: Sequence[BaseMessage]) -> List[BaseMessage]:
cls_map = {“ai”: HumanMessage, “human”: AIMessage}
translated = [messages[0]] + [
cls_map[msg.type](content=msg.content) for msg in messages[1:]
]
res = await reflect.ainvoke({“messages”: translated})
return HumanMessage(content=res.content)
builder = StateGraph(State)
builder.add_node(“generate”, generation_node)
builder.add_node(“reflect”, reflection_node)
builder.add_edge(START, “generate”)
def should_continue(state: List[BaseMessage]):
if len(state) > 6:
return END
return “reflect”
builder.add_conditional_edges(“generate”, should_continue)
builder.add_edge(“reflect”, “generate”)
graph = builder.compile()
async for event in graph.astream(
[
HumanMessage(
content=”Generate an essay on the topicality of The Little Prince and its message in modern life”
)
],
):
print(event)
print(“—“)
至此,Basic Reflection的完整流程就介绍完了,非常简单,相信哪怕是没有AI基础的同学也能看懂。
适用场景与优点
Basic Reflection的架构,非常适合于进行相对比较发散的内容生成类工作
比如:文章写作、图片生成、代码生成等等。
Basic Reflection是一种非常高效的反思类AI Agent设计模式。Basic Reflection 的思路非常朴素,使用成本较低。
局限性与不足
但是在实际应用中,Basic Reflection也面临着一些缺陷:
- 对于一些比较复杂的问题,显然需要
Generator具备更强大的推理能力
Generator生成的结果可能会过于发散,和我们要求的结果相去甚远- 在一些复杂场景下,Generator和Reflector之间的循环次数不太好定义,如果次数太少,生成效果不够理想;如果次数太多,对token的消耗会很大。
有2种方法来优化Basic Reflection,一种是边推理边执行的Self Discover模式,一种是增加了强化学习的Reflexion模式。
Reflexion : 语言强化学习的语言代理
Reflexion模式在Basic Reflection的基础上引入了强化学习的概念,使AI能够根据外部数据评估答案的准确性,并进行更有建设性的反思。
本质上可以看作是BasicReflection的升级版。
该设计模式由两个主要组件组成:Responder和Revisor。
Responder : 负责生成初始的回答,并包含对回答的自我批评;
而Revisor : 则根据Responder的反馈内容进行回答的修正,进而引入外部数据来验证答案的准确性。
论文
主要内容概括:
传统大模型微调所需要成本极高。大模型无法快速从环境交互中进行学习提升。
因此,本文提出了Reflexion框架,使得大模型能够从语言反馈(Verbal Reinforcement)中优化动作执行。
https://github.com/noahshinn024/reflexion

大型语言模型(llm)已经越来越多地用于与外部环境(例如,游戏,编译器,api)作为目标驱动的代理进行交互。
然而,由于传统的强化学习方法需要大量的训练样本和昂贵的模型微调,这些语言智能体快速有效地从试错中学习仍然是一个挑战。
我们提出了一个新的框架反射,它不是通过更新权重,而是通过语言反馈来强化语言代理。
具体来说,反射代理口头反映任务反馈信号,然后在情景记忆缓冲中保持自己的反射文本,从而在随后的试验中诱导更好的决策。
反射足够灵活,可以合并各种类型(标量值或自由形式的语言)和反馈信号的来源(外部或内部模拟),并在不同的任务(顺序决策、编码、语言推理)中获得比基线代理显著的改进。
例如,reflex在HumanEval编码基准上达到了91% pass@1的准确率,超过了之前最先进的GPT-4,后者达到了80%。
我们还使用不同的反馈信号、反馈合并方法和代理类型进行消融和分析研究,并提供它们如何影响性能的见解。
我们在 https://github.com/noahshinn024/reflexion 上发布了所有代码、演示和数据集。

大模型作为 goal-driven agents ,越来越多地用于和外界环境进行交互,
然而,由于传统强化学习需要大量的训练样本和昂贵的模型微调,大模型很难快速有效地从错误经验中学习。
最近涌现了ReAct,HuggingGPT等基于大模型的任务决策框架,
它们利用 In-context learning 的方式快速地指导模型执行任务,
避免了传统微调方式带来的计算成本和时间成本。
受前面工作的启发,本文提出了Reflexion框架,使用语言反馈信号(verbal reinforcement)来帮助agent从先前的失败经验中学习。
具体地,Reflexion将传统梯度更新中的参数信号转变为添加在大模型上下文中的语言总结,
使得agent在下一个episode中能参考上次执行失败的失败经验,从而提高agent的执行效果。
这个过程和人类反思(reflexion)过程十分相似。
最后,作者在决策(AlfWorld)、推理(HotQA)和代码生成(HumanEval)任务上进行了完整的对比实验。
Reflexion在不同的任务上均取得了不错的效果,特别是在代码生成任务上成为了最新的SOTA。
Reflexion框架构成

Reflexion框架
Reflexion框架的组成
- Actor: Actor由LLM担任,主要工作是基于当前环境生成下一步的动作。
- Evaluator: Evlauator主要工作是衡量Actor生成结果的质量。就像强化学习中的Reward函数对Actor的执行结果进行打分。
- Self-reflexion:Self-reflexion一般由LLM担任,是
Reflexion框架中最重要的部分。它能结合离散的reward信号(如success/fail)、trajectory等生成具体且详细语言反馈信号,这种反馈信号会储存在Memory中,启发下一次实验的Actor执行动作。相比reward分数,这种语言反馈信号储存更丰富的信息,例如在代码生成任务中,Reward只会告诉你任务是失败还是成功,但是Self-reflexion会告诉你哪一步错了,错误的原因是什么等。
+Memory:分为短期记忆(short-term)和长期记忆(long-term)。在一次实验中的上下文称为短期记忆,多次试验中Self-reflexion的结果称为长期记忆。类比人类思考过程,在推理阶段Actor会不仅会利用短期记忆,还会结合长期记忆中存储的重要细节,这是Reflexion框架能取得效果的关键。
Reflexion最重要的2个模块是:
- 长期记忆模块:赋予了agent长期记忆的能力
- Self-Reflexion模块:将一些数字化的reward信号转化为细致分析的语言总结,形成重要的长期记忆,能明显提高下一次执行的成功率。
Reflexion执行过程

如上图伪代码所示:
Reflexion是一个迭代过程Actor产生行动
+`Evaluator`对`Actor`的行动做出评价Self-Rflexion基于行动和评价形成反思,并将反思结果存储到长期记忆中,直到Actor执行的结果达到目标效果。
实验结果与分析
决策能力
- 在
AlfWorld任务中,Reflexion框架能够有效解决幻觉(hallucination)和规划不足(inefficinet planning)问题,使得agent的任务完成率明显提升,在10次实验后最多完成130/134个任务。

推理能力
- HotpotQA是一个基于百科知识库的问答任务,主要是测试agent在大量文本中推理的推理能力。
- 在这个任务中,
Reflexion的效果比所有的baseline都高出不少。
- 同时作者还对比了cot+EPM(episodic memory 类似一种长期记忆)和Reflexion框架(下图最右),发现
Reflexion的效果仍要高很多,这说明:
Reflexion框架中长期记忆和Self-Reflexion模块都起到了重要的作用。

代码生成
- 在
HumanEval(PY)代码生成任务中,Reflexion取得了SOTA效果,准确率相比GPT-4提高10.9%。

Language Agent Tree Search (LATS)
LATS模式是多种Agent设计模式的融合,它结合了树搜索ReAct、Plan&Solve以及 反思机制,通过多轮选代来寻找最优解。
Self-Discover
Self- Discover模式鼓励AI在更小的粒度上对任务本身进行反思,从而实现更深层次的任务理解和执行。
Storm
Storm模式专注于从零开始生成内容,如维基百科文章。
它通过先构建大纲,再丰富内容的方式,提供了一种系统化的内容生成方法。
在Agent设计模式的选择上,并没有一成不变的最佳方案。
每种模式都有其独特的使用场景和优势。
产品经理需要根据用户的具体需求和场景特点,选择最合适的设计模式。
随着AI技术的不断发展,新的设计模式将不断涌现,为AI应用带来更多可能性。
Y 推荐文献
20250311 : 138 fork / 1.1k star
20250309 : 45.3k fork / 173k star
- 吴恩达AI大模型系列:使用 Windsurf的AI 编程代理构建应用程序|Build Apps with Windsurf’s AI Coding Agents – Bilibili
代理设计模式目录:基于基础模型的代理的体系结构模式集合
X 参考文献
Agentic Reasoning: Andrew Ng at Sequoia AI Ascent 2024 | Octet Consulting









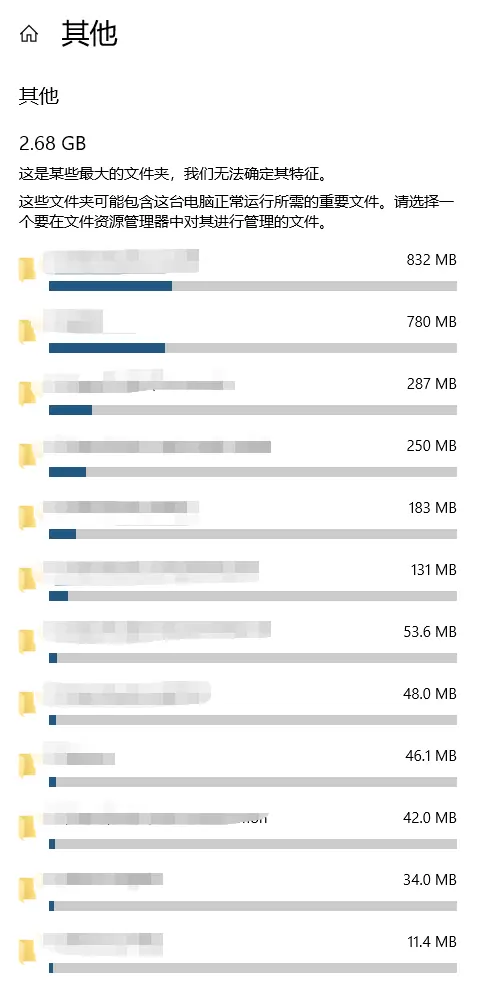
 查看C盘使用情况,可以查看“其他”中情况
查看C盘使用情况,可以查看“其他”中情况