来源: RocketMQ事务消息在订单创建和库存扣减的使用 – Scotyzh – 博客园
前言
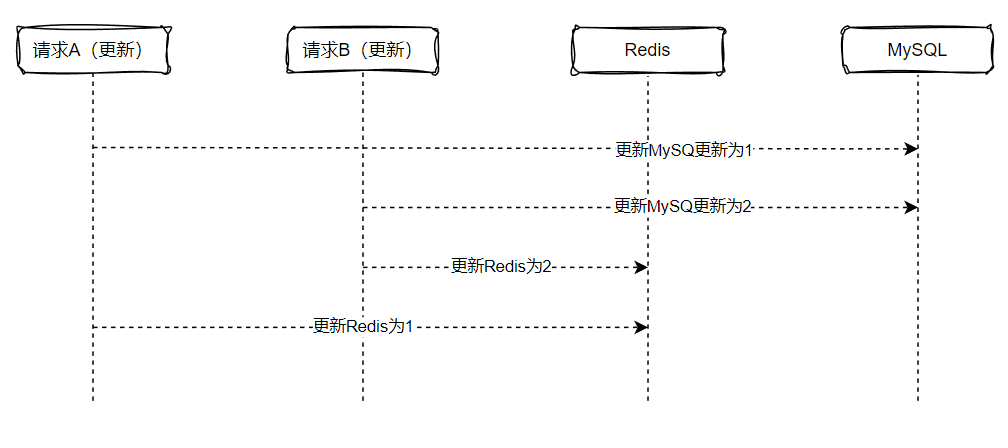
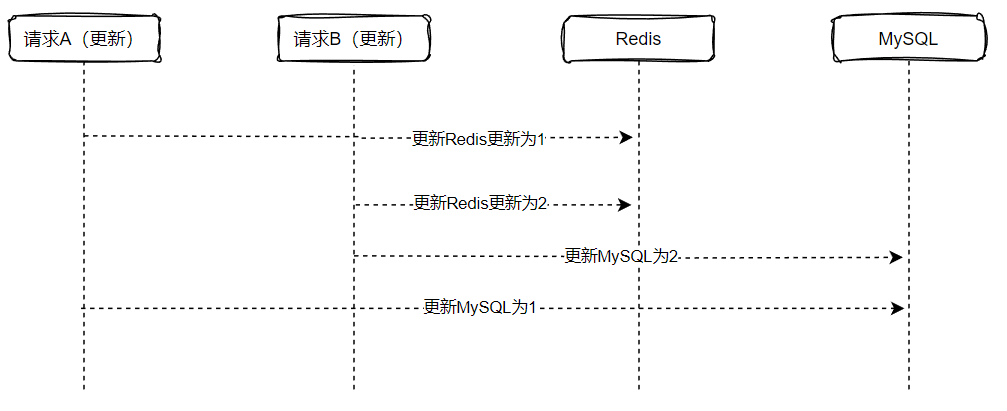
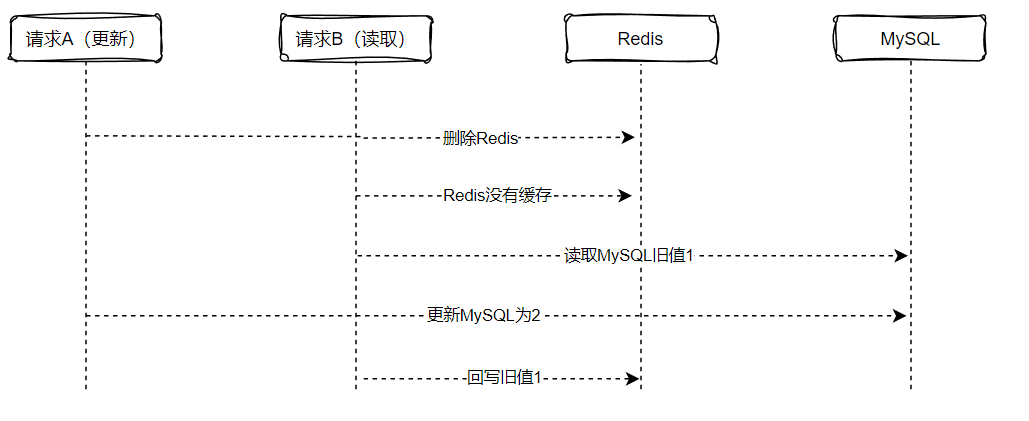
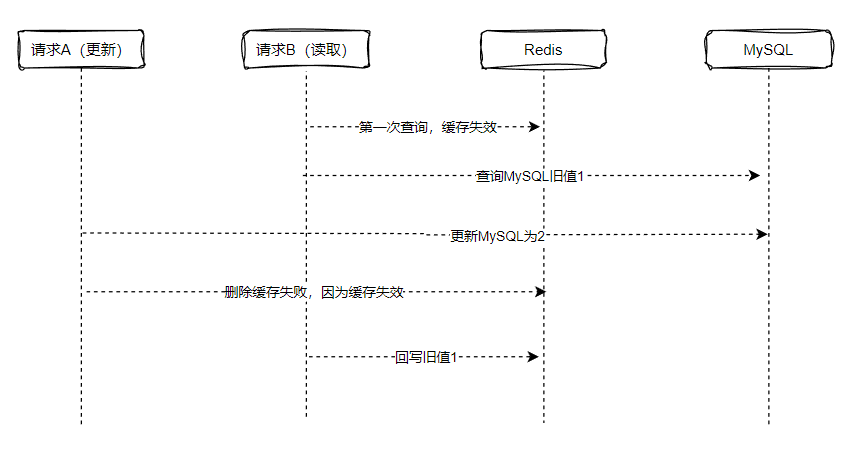
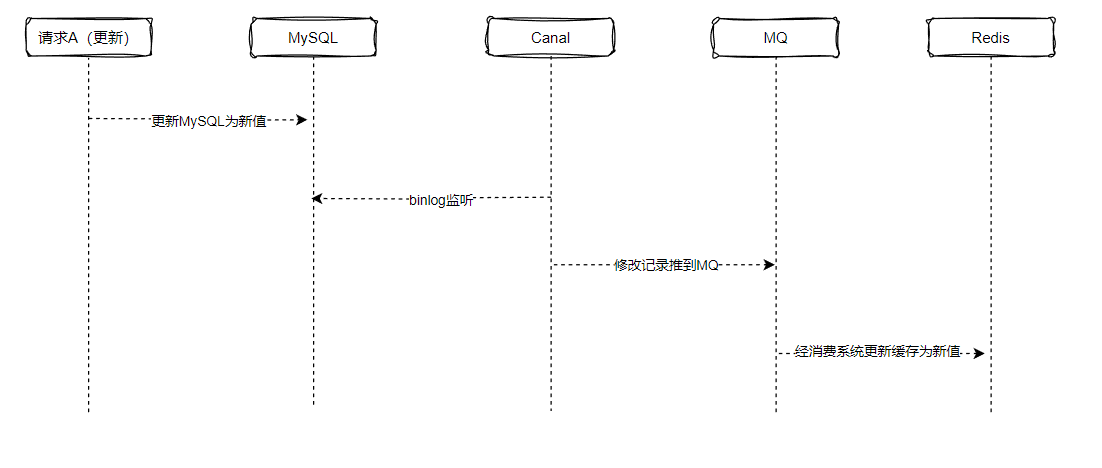
下单的过程包括订单创建,还有库存的扣减,为提高系统的性能,将库存放在redis扣减,则会涉及到MySQL和redis之间的数据同步,其中,这个过程还涉及到,必须是订单创建成功才进行库存的扣减操作。其次,还涉及到库存的同步,需要保证订单创建成功和redis里的库存都扣减成功,再将库存数据同步到Mysql,为了实现上述这里情况,可以借助RocketMQ的事务型消息来实现。
流程图
流程图如下,这里引入了stocklog,即订单流水表,通过判断stocklog的状态来决定是否commite消息去同步mysql,这里stocklog状态为成功的前提是订单入库和redis库存扣减成功。

RocketMQ事务消息
在第五步执行成功返回可能因为网络状况卡住,但是stocklog状态已经得到修改
如果返回成功 MQ事务就会commit这条消息
如果没有返回成功 MQ事务会去轮询stocklog有没有被修改
一直五次轮询发现没有被修改就会回滚这条消息,这个消息相当于被删掉,不会让消费系统消费到
这条消息commit后,就会被MQ的消费者消费,对MySQL的实际库存进行更新
stock_log的意义
这里是为了保证订单的插入和redis库存扣减都成功,才进行后续异步操作MySQL,本身的存在就是为了辅助这个本地事务的成功执行再进行后续的操作,保证一致性。
这里再说一下我之前面试遇到的一个问题:既然先对redis扣减库存再MQ异步是去操作MySQL数据库扣减库存,这样子是为了提高性能,那么这套流程一开始就操作MySQL,性能会有提升吗?答案肯定有的,这里操作数据库是将订单流水入库,并没有涉及到锁,并发下不会因为行锁而影响性能。而针对某个产品的库存扣减,直接操作MySQL进行Update操作,会对这一行加上行锁,其他请求都需要阻塞等待行锁的释放。
需要的SQL表
这里简化一下下单的流程,不涉及用户表,只涉及到库存表,库存流水表,订单表。
order表
CREATE TABLE `order` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '订单id',
`product_id` int(11) DEFAULT NULL COMMENT '产品id',
`product_num` int(11) DEFAULT NULL COMMENT '产品数量',
PRIMARY KEY (`id`),
KEY `product_id_index` (`product_id`) USING BTREE COMMENT '产品id索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
stock表
CREATE TABLE `stock` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '库存id',
`product_id` int(11) DEFAULT NULL COMMENT '产品id',
`product_name` varchar(255) DEFAULT NULL COMMENT '产品名字',
`stock_num` int(11) DEFAULT NULL COMMENT '产品库存',
PRIMARY KEY (`id`),
UNIQUE KEY `product_id_index` (`product_id`) USING BTREE COMMENT '产品Id唯一索引'
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4;
stock_log表
CREATE TABLE `stock_log` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '库存id',
`product_id` int(11) DEFAULT NULL COMMENT '产品id',
`amount` int(11) DEFAULT NULL COMMENT '库存变化数量',
`status` int(11) DEFAULT NULL COMMENT '状态0->初始化,1->成功,2->回滚',
PRIMARY KEY (`id`),
KEY `product_id_index` (`product_id`) USING BTREE COMMENT '产品id索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
关键代码
OrderController类
@Controller
@RequestMapping("/order")
@RequiredArgsConstructor
@Slf4j
public class OrderController {
private final OrderService orderService;
private final StockLogService stockLogService;
private final DecreaseStockProducer decreaseStockProducer;
private final StockService stockService;
private final RedisTemplate redisTemplate;
@PostMapping(value = "/create/{id}")
public ResponseEntity<Object> create(@PathVariable("id") Integer productId) {
if (redisTemplate.hasKey("product_stock_invalid_" + productId)) {
return new ResponseEntity<>("库存不足", HttpStatus.OK);
}
StockLog stockLog = StockLog.builder()
.amount(1)
.productId(productId)
.status(0)
.build();
stockLogService.save(stockLog);
try {
DecreaseStockEvent decreaseStockEvent = DecreaseStockEvent.builder()
.productId(productId)
.stockLogId(stockLog.getId())
.build();
SendResult sendResult = decreaseStockProducer.sendMessageInTransaction(decreaseStockEvent);
if (!Objects.equals(sendResult.getSendStatus(), SendStatus.SEND_OK)) {
log.error("事务消息发送错误,请求参数productId:{}", productId);
}
} catch (Exception e) {
log.error("消息发送错误,请求参数:{}", productId, e);
}
return new ResponseEntity<>("created successfully", HttpStatus.OK);
}
StockStatusCheckerListener类,执行本地事务和检查事务
@Slf4j
@RocketMQTransactionListener
@RequiredArgsConstructor
public class StockStatusCheckerListener implements RocketMQLocalTransactionListener {
private final OrderService orderService;
private final StockLogService stockLogService;
private final TransactionTemplate transactionTemplate;
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message message, Object arg) {
log.info("message: {}, args: {}", message, arg);
TypeReference<MessageWrapper<DecreaseStockEvent>> typeReference = new TypeReference<MessageWrapper<DecreaseStockEvent>>() {};
MessageWrapper<DecreaseStockEvent> messageWrapper = JSON.parseObject(new String((byte[]) message.getPayload()), typeReference);
DecreaseStockEvent decreaseStockEvent = messageWrapper.getMessage();
log.info("decreaseStockEvent info : {}", decreaseStockEvent);
try {
orderService.createOrder(decreaseStockEvent.getProductId(), decreaseStockEvent.getStockLogId());
} catch (Exception e) {
log.error("插入订单失败, decreaseStockEvent info : {}", decreaseStockEvent, e);
StockLog stockLog = stockLogService.getOne(new QueryWrapper<StockLog>().eq("id", decreaseStockEvent.getStockLogId()));
stockLog.setStatus(2);
stockLogService.updateById(stockLog);
return RocketMQLocalTransactionState.ROLLBACK;
}
return RocketMQLocalTransactionState.COMMIT;
}
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message message) {
log.info("message: {}, args: {}", message);
MessageWrapper<DecreaseStockEvent> messageWrapper = (MessageWrapper) message.getPayload();
DecreaseStockEvent decreaseStockEvent = messageWrapper.getMessage();
StockLog stockLog = stockLogService.getOne(new QueryWrapper<StockLog>().eq("id", decreaseStockEvent.getStockLogId()));
if (stockLog == null) {
return RocketMQLocalTransactionState.UNKNOWN;
}
if (stockLog.getStatus().intValue() == 1) {
return RocketMQLocalTransactionState.COMMIT;
} else if (stockLog.getStatus().intValue() == 0) {
return RocketMQLocalTransactionState.UNKNOWN;
}
return RocketMQLocalTransactionState.ROLLBACK;
}
}
MQ相关代码,使用模板方法
DecreaseStockProducer,消息生产者,实现了一些指定方法
@Slf4j
@Component
public class DecreaseStockProducer extends AbstractCommonSendProduceTemplate<DecreaseStockEvent> {
private final ConfigurableEnvironment environment;
public DecreaseStockProducer(@Autowired RocketMQTemplate rocketMQTemplate, @Autowired ConfigurableEnvironment environment) {
super(rocketMQTemplate);
this.environment = environment;
}
@Override
protected BaseSendExtendDTO buildBaseSendExtendParam(DecreaseStockEvent messageSendEvent) {
return BaseSendExtendDTO.builder()
.eventName("库存同步到mysql")
.keys(String.valueOf(messageSendEvent.getProductId()))
.topic(environment.resolvePlaceholders(StockMQConstant.STOCK_TOPIC_KEY))
.tag(environment.resolvePlaceholders(StockMQConstant.STOCK_DEREASE_STOCK_TAG_KEY))
.sentTimeout(2000L)
.build();
}
@Override
protected Message<?> buildMessage(DecreaseStockEvent messageSendEvent, BaseSendExtendDTO requestParam) {
String keys = StrUtil.isEmpty(requestParam.getKeys()) ? UUID.randomUUID().toString() : requestParam.getKeys();
return MessageBuilder
.withPayload(new MessageWrapper(requestParam.getKeys(), messageSendEvent))
.setHeader(MessageConst.PROPERTY_KEYS, keys)
.setHeader(MessageConst.PROPERTY_TAGS, requestParam.getTag())
.build();
}
}
AbstractCommonSendProduceTemplate,发送消息的类
@Slf4j
@RequiredArgsConstructor
public abstract class AbstractCommonSendProduceTemplate<T> {
private final RocketMQTemplate rocketMQTemplate;
protected abstract BaseSendExtendDTO buildBaseSendExtendParam(T messageSendEvent);
protected abstract Message<?> buildMessage(T messageSendEvent, BaseSendExtendDTO requestParam);
public SendResult sendMessageInTransaction(T messageSendEvent) {
BaseSendExtendDTO baseSendExtendDTO = buildBaseSendExtendParam(messageSendEvent);
SendResult sendResult;
try {
StringBuilder destinationBuilder = StrUtil.builder().append(baseSendExtendDTO.getTopic());
if (StrUtil.isNotBlank(baseSendExtendDTO.getTag())) {
destinationBuilder.append(":").append(baseSendExtendDTO.getTag());
}
sendResult = rocketMQTemplate.sendMessageInTransaction(
destinationBuilder.toString(),
buildMessage(messageSendEvent, baseSendExtendDTO),
null
);
log.info("[{}] 消息发送结果:{},消息ID:{},消息Keys:{}", baseSendExtendDTO.getEventName(), sendResult.getSendStatus(), sendResult.getMsgId(), baseSendExtendDTO.getKeys());
} catch (Throwable ex) {
log.error("[{}] 消息发送失败,消息体:{}", baseSendExtendDTO.getEventName(), JSON.toJSONString(messageSendEvent), ex);
throw ex;
}
return sendResult;
}
OrderService的createOrder方法:
@Service
@RequiredArgsConstructor
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
private final OrderMapper orderMapper;
private final StockLogMapper stockLogMapper;
private final RedisTemplate redisTemplate;
private final TransactionTemplate transactionTemplate;
private static final String LUA_DECRESE_STOCK_PATH = "lua/decreseStock.lua";
@Override
public void createOrder(Integer productId, Integer stockLogId) {
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource(LUA_DECRESE_STOCK_PATH)));
redisScript.setResultType(Long.class);
Long redisResult = (Long) redisTemplate.execute(redisScript, Collections.singletonList(String.valueOf(productId)));
if (redisResult < 1L) {
throw new RuntimeException("库存售罄");
}
transactionTemplate.executeWithoutResult(status -> {
try {
Order order = Order.builder()
.productId(productId)
.productNum(1)
.build();
orderMapper.insert(order);
StockLog stockLog = stockLogMapper.selectOne(new QueryWrapper<StockLog>().eq("id", stockLogId));
if (stockLog == null) {
throw new RuntimeException("该库存流水不存在");
}
stockLog.setStatus(1);
stockLogMapper.updateById(stockLog);
} catch (Exception e) {
redisTemplate.opsForValue().increment(String.valueOf(productId));
status.setRollbackOnly();
}
});
}
}
redis的lua脚本代码如下,这里只会在库存大于0的时候进行扣减,先检查库存,再扣减。如果库存为0,在redis里面setIfAbsent该商品售罄的标识,这样子在controller查询到售罄就直接return
local key = KEYS[1]
local exists = redis.call('EXISTS', key)
if exists == 1 then
local value = redis.call('GET', key)
if tonumber(value) > 0 then
redis.call('DECR', key)
return 1
else
local prefix = "product_stock_invalid_"
local stock_invalid_tag = prefix .. KEYS[1]
local exists_tag = redis.call('EXISTS', stock_invalid_tag)
if exists_tag == 0 then
redis.call('SET', stock_invalid_tag, "true")
return 0
end
end
else
return -1
end
MQ的consumer:
@Slf4j
@Component
@RequiredArgsConstructor
@RocketMQMessageListener(
topic = StockMQConstant.STOCK_TOPIC_KEY,
selectorExpression = StockMQConstant.STOCK_DEREASE_STOCK_TAG_KEY,
consumerGroup = StockMQConstant.STOCK_DEREASE_STOCK_CG_KEY
)
public class DecreaseStockConsumer implements RocketMQListener<MessageWrapper<DecreaseStockEvent>> {
private final StockService stockService;
@Transactional(rollbackFor = Exception.class)
@Override
public void onMessage(MessageWrapper<DecreaseStockEvent> message) {
DecreaseStockEvent decreaseStockEvent = message.getMessage();
Integer productId = decreaseStockEvent.getProductId();
try {
stockService.decreaseStock(productId);
} catch (Exception e) {
log.error("库存同步到mysql失败,productId:{}", productId, e);
throw e;
}
}
}
stockService.decreaseStock()方法如下
public int decreaseStock(Integer productId) {
return stockMapper.decreaseStock(productId);
}
相关的SQL语句
<update id="decreaseStock">
UPDATE stock
SET stock_num = stock_num - 1
WHERE id = #{id} AND stock_num >= 1
</update>
消息重复消费问题
我们知道,MQ可能会存在重复消费的问题,包括我在压测的时候,就存在了重复消费,导致MySQL的库存最终比redis库存要少,重复扣减了MySQL的库存,针对这种情况,应该解决幂等性问题。
在前面我们用MessageWrapper来包装消息体的时候,每次new一个MessageWrapper都会生成新的UUID,我们将这UUID存到Redis里面来保证幂等性
@Data
@Builder
@NoArgsConstructor(force = true)
@AllArgsConstructor
@RequiredArgsConstructor
public final class MessageWrapper<T> implements Serializable {
private static final long serialVersionUID = 1L;
@NonNull
private String keys;
@NonNull
private T message;
private String uuid = UUID.randomUUID().toString();
private Long timestamp = System.currentTimeMillis();
}
修改后的扣减库存方法,先判断redis里面有没有存在已经扣除了库存的标识,有就直接返回
@Service
@RequiredArgsConstructor
public class StockServiceImpl extends ServiceImpl<StockMapper, Stock> implements StockService {
private final StockMapper stockMapper;
private final RedisTemplate redisTemplate;
@Override
public int decreaseStock(Integer productId, String UUID) {
if(redisTemplate.hasKey("decrease_mark_" + UUID)) {
return 0;
}
redisTemplate.opsForValue().set("decrease_mark_" + UUID, "true", 24, TimeUnit.HOURS);
return stockMapper.decreaseStock(productId);
}
}
下面是上述demo的代码地址,修改数据库和mysql地址即可使用
scottyzh/stock-demo: RocketMQ事务消息在订单生成和扣减库存的应用 (github.com)