来源: Java对接JeePay支付、转账实现以及回调函数-CSDN博客
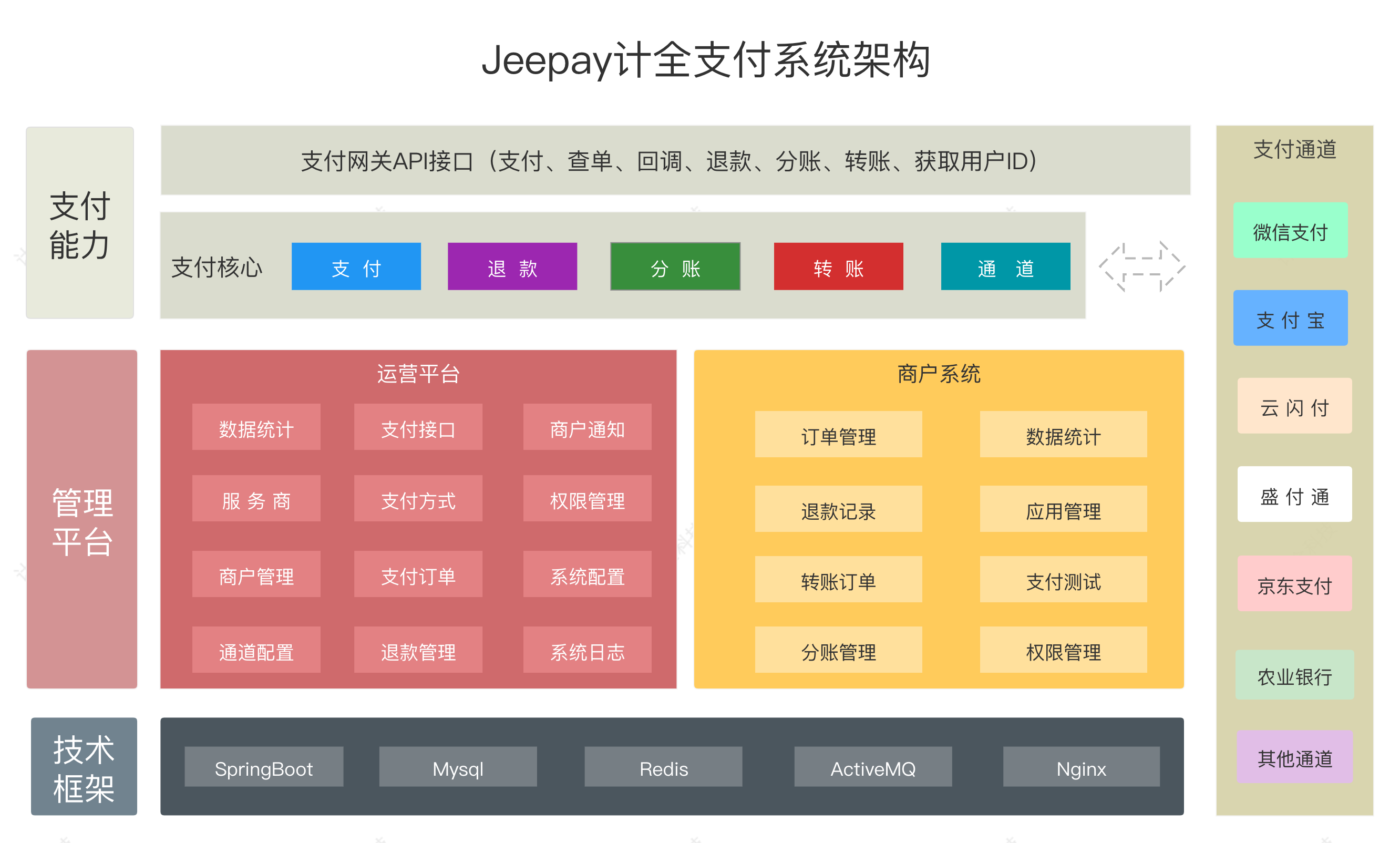
最近公司对接了第三方支付平台JeePay,看到网上文章比较少,给大家发一篇对接微信支付的吧,支付宝也一样,更换里面的参数即可,官方文档地址:系统介绍 – 计全文档,具体的服务需要大家去搭建,并创建里面的应用,我这里只给大家展示出了代码,具体的服务搭建和创建应用大家去看下官网,下面开始实现我们的代码。
首先我们引入两个pom依赖。
<dependency>
<groupId>com.github.wxpay</groupId>
<artifactId>wxpay-sdk</artifactId>
<version>0.0.3</version>
</dependency>
<dependency>
<groupId>com.jeequan</groupId>
<artifactId>jeepay-sdk-java</artifactId>
<version>1.5.0</version>
</dependency>
下面我们需要在配置文件里面加上相关配置,我们可以新建一个 application-jee-pay.properties。
#这个是回调的地址,一定要能访问到我们回调的IP上面,自定义
domain-name=http://120.29.172.100:8500
#这个固定写死
api-base=https://pay.vichel.com.cn/
#商户私钥
api-key=商户的私钥,如何获取看下面截图
#商户号,看下面截图
mch-no=M1670111111
#应用ID
app-id=1111b3f0e4b05e7111111111
#转账回调地址
wx-withdrawal=${domain-name}/wxPay/result/withdrawalCallback
#支付回调地址
wx-recharge=${domain-name}/wxPay/result/wxRechargeCallback
打开jeePay运营平台,点击我们要对接的应用,点击修改,里面有应用ID和商户号,我们直接复制就可以了。随机生成出一个私钥,点击保存就可以了
基础配置类
package com.mart.web.pay;
import com.jeequan.jeepay.Jeepay;
import com.jeequan.jeepay.JeepayClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import org.springframework.core.env.Environment;
/**
* JeePay配置相关
*/
@Configuration
//这里指定我们要读取的配置文件
@PropertySource(“classpath:application-jee-pay.properties”)
public class JeePayClientConfig {
@Autowired
private Environment config;
@Bean
public JeepayClient jeePayConfig(){
//地址
Jeepay.setApiBase(config.getProperty(“api-base”));
//私钥
Jeepay.apiKey = config.getProperty(“api-key”);
//商户号
Jeepay.mchNo = config.getProperty(“mch-no”);
//应用ID
Jeepay.appId = config.getProperty(“app-id”);
JeepayClient jeepayClient = JeepayClient.getInstance(Jeepay.appId, Jeepay.apiKey, Jeepay.getApiBase());
return jeepayClient;
}
}
下面是一些支付转账操作的模块,我给大家出了一个示例,里面的参数需要结合业务需求做相应的调整,我下面只要使用的是微信小程序支付和微信零钱的转账功能。商户可以转账到用户微信的零钱。
package com.mart.web.pay;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.jeequan.jeepay.Jeepay;
import com.jeequan.jeepay.JeepayClient;
import com.jeequan.jeepay.exception.JeepayException;
import com.jeequan.jeepay.model.PayOrderCreateReqModel;
import com.jeequan.jeepay.model.TransferOrderCreateReqModel;
import com.jeequan.jeepay.model.TransferOrderCreateResModel;
import com.jeequan.jeepay.request.PayOrderCreateRequest;
import com.jeequan.jeepay.request.TransferOrderCreateRequest;
import com.jeequan.jeepay.response.PayOrderCreateResponse;
import com.jeequan.jeepay.response.TransferOrderCreateResponse;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.env.Environment;
import org.springframework.stereotype.Service;
import java.math.BigDecimal;
/**
*
* 支付转账核心操作功能模块
*/
@Slf4j
@Service
public class JeePayService {
@Autowired
private JeepayClient jeepayClient;
@Autowired
private Environment config;
/**
* 转账操作,转账到微信零钱(特别注意,下面转账的时候Jeepay一定要使用微信的主商户进行转账,如果使用的是子商户就会出现 {“code”:9999,”msg”:”微信子商户暂不支持转账业务”})
* @param openId 用户的openId
* @param amount 转账金额
* @param numberOn 转账订单号
* @return
*/
public Boolean withdrawal(String openId, BigDecimal amount,String numberOn) {
// 构建请求数据
TransferOrderCreateRequest request = new TransferOrderCreateRequest();
TransferOrderCreateReqModel model = new TransferOrderCreateReqModel();
// 商户号
model.setMchNo(Jeepay.mchNo);
// 应用ID
model.setAppId(Jeepay.appId);
// 商户订单号
model.setMchOrderNo(numberOn);
// 支付方式
model.setIfCode(“wxpay”);
// 入账方式
model.setEntryType(“WX_CASH”);
// 我们传入的是元,这里需要吧金额转成单位分
amount = amount.multiply(new BigDecimal(“100”));
model.setAmount(amount.longValue());
// 币种,目前只支持cny
model.setCurrency(“CNY”);
model.setAccountNo(openId);
// 转账备注
model.setTransferDesc(“测试转账操作”);
// 异步通知地址
model.setNotifyUrl(config.getProperty(“wx-withdrawal”));
// 商户扩展参数,回调时原样返回
model.setExtParam(numberOn);
request.setBizModel(model);
log.info(“jeepay下单参数处理完毕,参数:[{}]”, JSON.toJSONString(request));
try {
TransferOrderCreateResponse response = jeepayClient.execute(request);
// 下单成功
if (response.isSuccess(Jeepay.apiKey)) {
//转账成功
log.warn(“转账成功:{}”);
return true;
}
} catch (JeepayException e) {
log.error(e.getMessage());
}
log.warn(“转账失败:{}”);
return false;
}
/**
* 支付操作,我下面使用的是微信支付的
* @param Subject 商品标题
* @param body 描述
* @param openId 微信的OpenId或者是支付宝的用户ID
* @param amount 支付的金额 CNY
* @param numberOn 平台自己生成的随机订单号
* @return
*/
public String scanPay(String Subject,String body,String openId, BigDecimal amount,String numberOn) {
// 构建请求数据
PayOrderCreateRequest request = new PayOrderCreateRequest();
PayOrderCreateReqModel model = new PayOrderCreateReqModel();
// 商户号
model.setMchNo(Jeepay.mchNo);
// 应用ID
model.setAppId(Jeepay.appId);
// 商户订单号
model.setMchOrderNo(numberOn);
// 支付方式
model.setWayCode(“WX_JSAPI”);
amount = amount.multiply(new BigDecimal(“100”));
// 金额,单位分
model.setAmount(amount.longValue());
// 币种,目前只支持cny
model.setCurrency(“CNY”);
// 发起支付请求客户端的IP地址
model.setClientIp(config.getProperty(“ip-address”));
// 商品标题
model.setSubject(Subject);
// 商品描述
model.setBody(body);
// 异步通知地址
model.setNotifyUrl(config.getProperty(“wx-recharge”));
// 渠道扩展参数 传OpenId
model.setChannelExtra(“{\”openid\”: \””+openId+”\”}”);
// 商户扩展参数,回调时原样返回
model.setExtParam(numberOn);
request.setBizModel(model);
log.info(“jeepay下单参数处理完毕,参数:[{}]”, JSON.toJSONString(request));
try {
PayOrderCreateResponse response = jeepayClient.execute(request);
// 下单成功
if (response.isSuccess(Jeepay.apiKey)) {
String result = response.getData().getString(“payData”);
return result;
}
} catch (JeepayException e) {
log.error(e.getMessage());
}
return null;
}
}
回调函数
package com.mart.web.controller;
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.jeequan.jeepay.util.JeepayKit;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.env.Environment;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletRequest;
import java.math.BigDecimal;
import java.util.*;
/**
* 回调接收
* @author HayDen
* @date 2022-11-15
*/
@RestController
@RequestMapping(“/wxPay/result”)
@SentinelResource(value = “CallbackController”)
public class CallbackController
{
@Autowired
private Environment config;
/**
* 转账回调
* @return
*/
@PostMapping(“/withdrawalCallback”)
public String withdrawalCallback(HttpServletRequest req) throws Exception
{
String result = “failure”;
try {
Map<String, Object> map = getParamsMap(req);
//获取私钥
String apikey = config.getProperty(“api-key”);
//验签
if (chackSgin(map, apikey)) {
return result;
}
//提现成功
//获取订单号
String orderNumber = map.get(“mchOrderNo”).toString();
//提现金额
BigDecimal amount = new BigDecimal(map.get(“amount”).toString()).divide(new BigDecimal(“100”),4,BigDecimal.ROUND_HALF_UP);
}
result = “success”;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 微信支付回调
* @return
*/
@PostMapping(“/wxRechargeCallback”)
public String wxRechargeCallback(HttpServletRequest req) throws Exception
{
String result = “failure”;
try {
Map<String, Object> map = getParamsMap(req);
//获取私钥
String apikey = config.getProperty(“api-key”);
//验签
if (chackSgin(map, apikey)) {
return result;
}
//订单号
String orderNumber = map.get(“mchOrderNo”).toString();
//支付金额
BigDecimal amount = new BigDecimal(map.get(“amount”).toString()).divide(new BigDecimal(“100”),4,BigDecimal.ROUND_HALF_UP);
//返回成功
result = “success”;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 回调验签
* @param map
* @param apikey
* @return
*/
private Boolean chackSgin(Map<String, Object> map, String apikey) {
Object sign = map.remove(“sign”);
String reSign = JeepayKit.getSign(map, apikey);
if (!Objects.equals(reSign, sign)) {
return true;
}
return false;
}
private Map<String, Object> getParamsMap(HttpServletRequest req) {
Map<String, String[]> requestMap = req.getParameterMap();
Map<String, Object> paramsMap = new HashMap<>();
requestMap.forEach((key, values) -> {
String strs = “”;
for (String value : values) {
strs = strs + value;
}
paramsMap.put(key, strs);
});
return paramsMap;
}
}
好了,到这里基本就结束了,如果大家有什么疑问可以给我留言,看到后一定会第一时间回复的,有建议那是最好的,欢迎大家提出来,如果合理我一定第一时间优化代码。
如果这篇文章在你一筹莫展的时候帮助到了你,可以请作者吃个棒棒糖🙂,如果有啥疑问或者需要完善的地方欢迎大家在下面留言或者私信作者优化改进。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_38935605/article/details/128639513