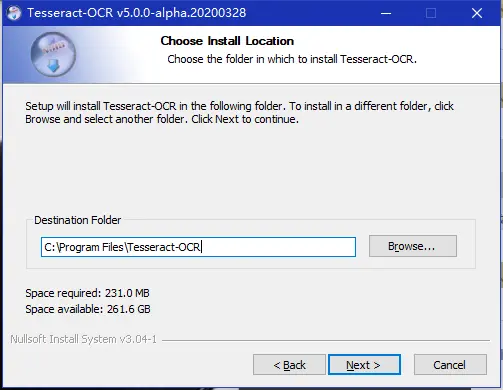
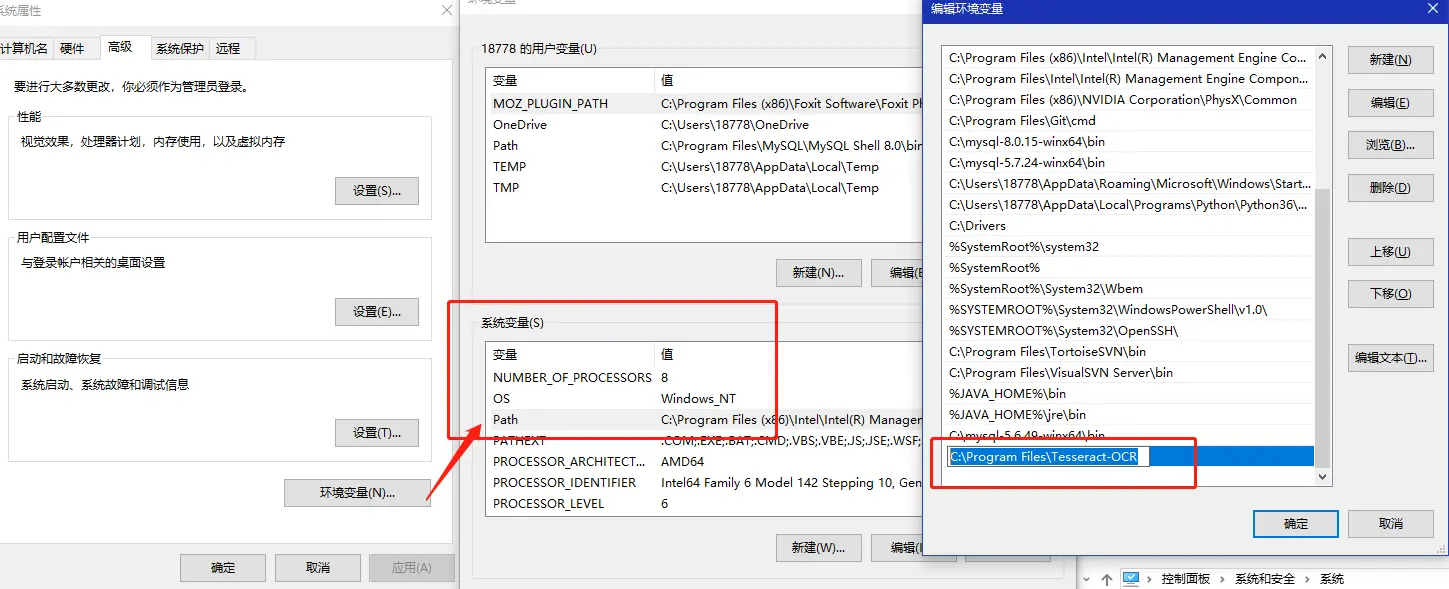
来源: H3-1S、H3-2S 通用型光猫获取超级管理员密码
参考
https://www.right.com.cn/forum/thread-7936266-1-1.html
步骤
电脑启用 telnet 功能
1、输入:win + s,打开搜索;
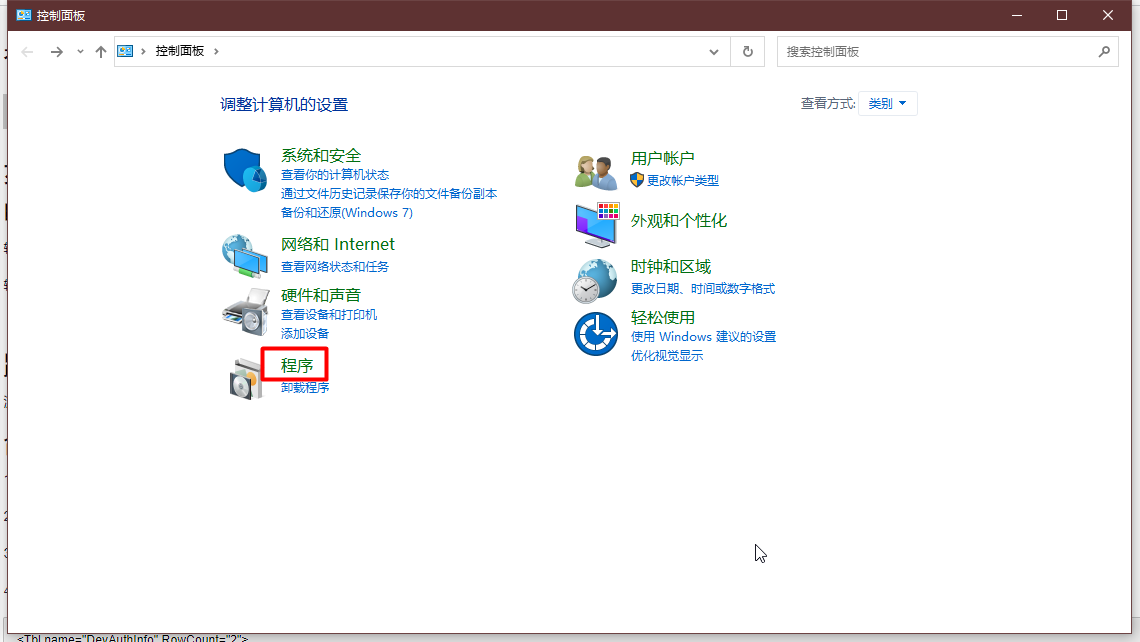
2、输入:控制面板,点击打开;
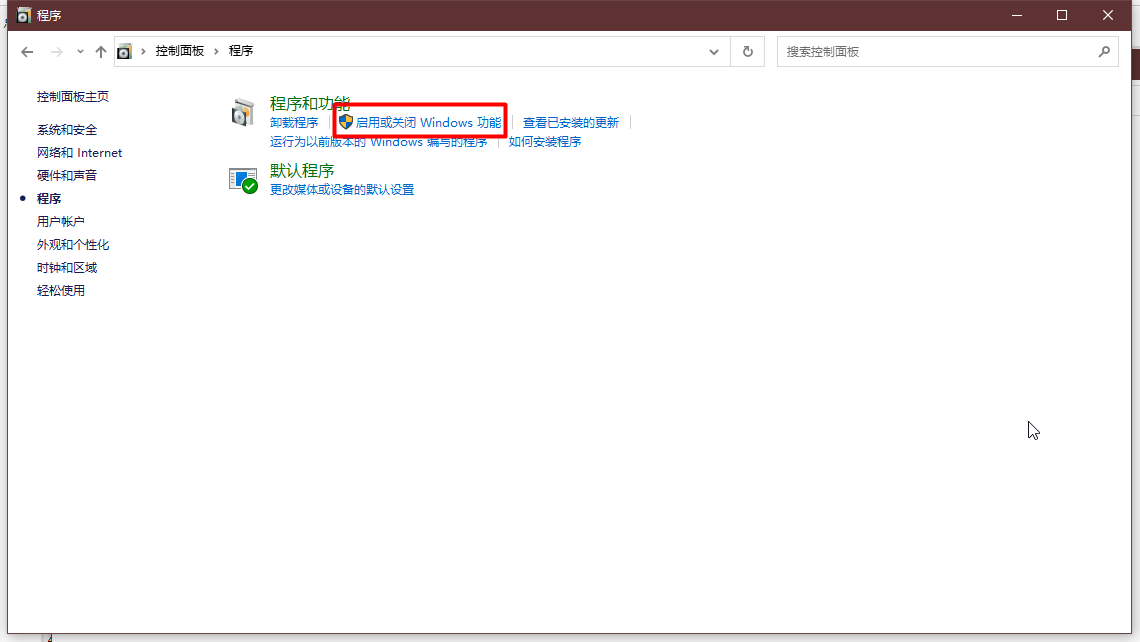
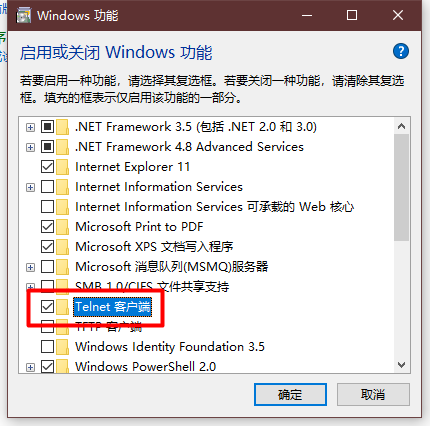
3、点击:程序 → 启用或关闭 Windows 功能 → 勾选 Telnet 客户端 → 点击确定。
路由器开启 telnet
浏览器输入:http://192.168.1.1/usr=CMCCAdmin&psw=aDm8H%25MdA&cmd=1&telnet.gch 后回车。
命令行操作
1、按下 win + r 输入 cmd 打开控制台面板。
2、输入:telnet 192.168.1.1。
3、输入账号:CMCCAdmin,密码:aDm8H%MdA。
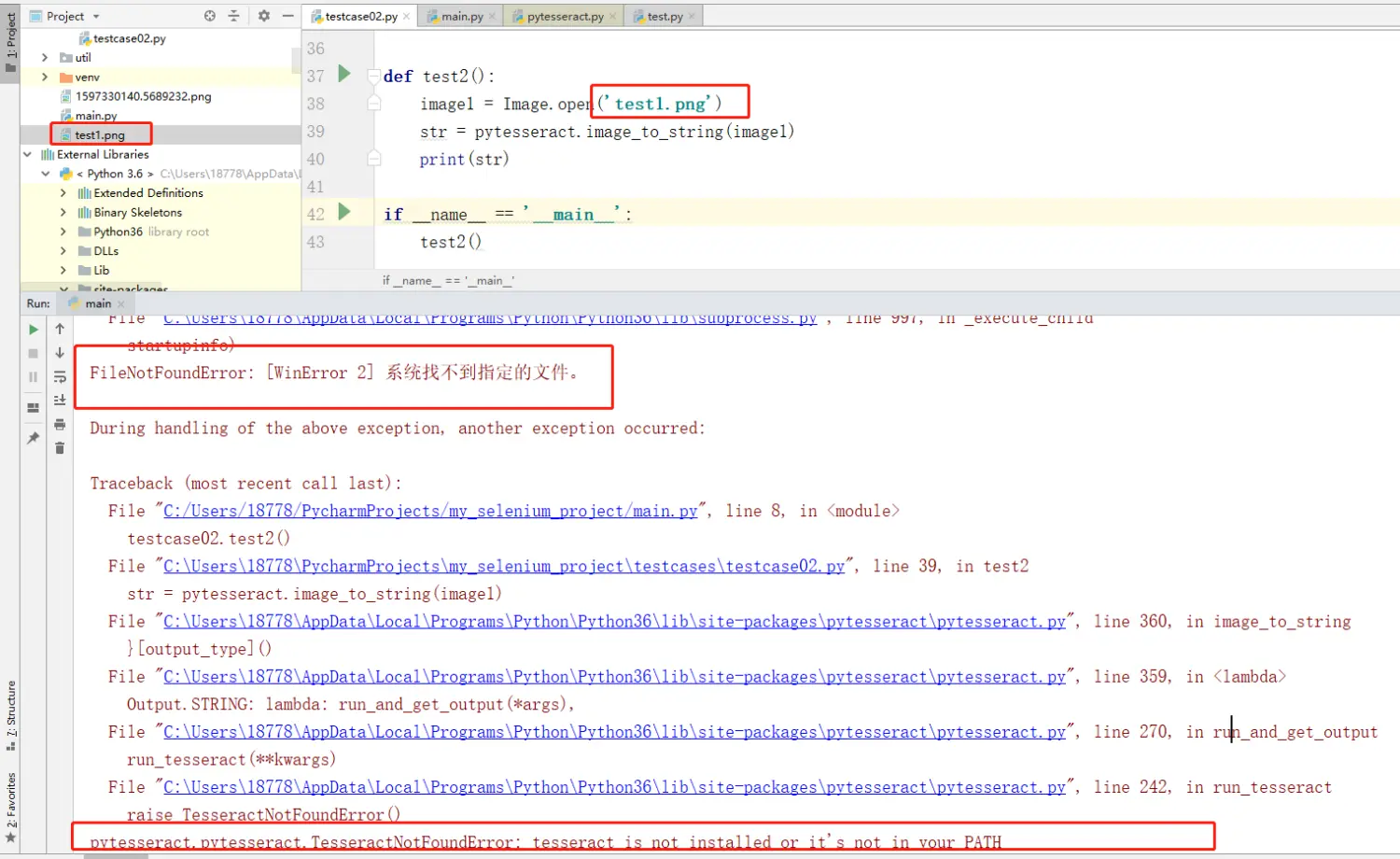
4、输入:sidbg 1 DB p DevAuthInfo 查看信息,结果如下:
<Tbl name="DevAuthInfo" RowCount="2">
<Row No="0">
<DM name="ViewName" val="IGD.AU1"/>
<DM name="Enable" val="1"/>
<DM name="IsOnline" val="0"/>
<DM name="AppID" val="1"/>
<DM name="User" val="******"/>
<DM name="Pass" val="******"/>
<DM name="Level" val="1"/>
<DM name="Extra" val=""/>
<DM name="ExtraInt" val="0"/>
</Row>
<Row No="1">
<DM name="ViewName" val="IGD.AU2"/>
<DM name="Enable" val="1"/>
<DM name="IsOnline" val="0"/>
<DM name="AppID" val="1"/>
<DM name="User" val="******"/>
<DM name="Pass" val="******"/>
<DM name="Level" val="2"/>
<DM name="Extra" val=""/>
<DM name="ExtraInt" val="0"/>
</Row>
</Tbl>5、更改 CMCCAdmin 的密码:
输入:sidbg 1 DB set DevAuthInfo 0 Pass admin,将密码设置为 admin;
输入:sidbg 1 DB save 保存;
输入:exit 退出。
管理员登录
浏览器输入:192.168.1.1,账号:CMCCAdmin,密码:admin。