来源: sqlserver 2012 MSSQLSERVER服务显示正在挂起更改且无法启动_sqlserver服务正在挂起更改-CSDN博客
问题:过了一个周末,本地部署的所有项目突然都登不上去了,项目重新生成,项目的服务重新开启也不行,觉得是数据的问题,果然SQLServer2012无法登陆;
打开服务,看到
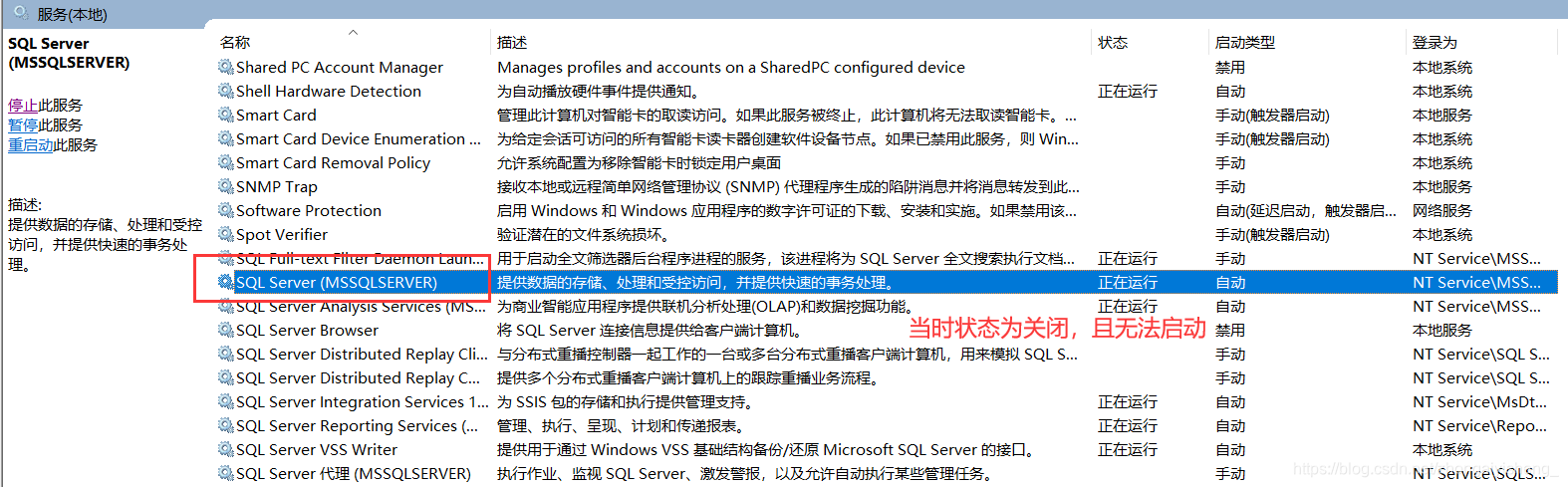
打开SQL2012的配置管理器

在配置管理器中,

O(∩_∩)O哈哈~

来源: sqlserver 2012 MSSQLSERVER服务显示正在挂起更改且无法启动_sqlserver服务正在挂起更改-CSDN博客
问题:过了一个周末,本地部署的所有项目突然都登不上去了,项目重新生成,项目的服务重新开启也不行,觉得是数据的问题,果然SQLServer2012无法登陆;
打开服务,看到
打开SQL2012的配置管理器
在配置管理器中,
O(∩_∩)O哈哈~
来源: 移动友华PT924光猫获取超级用户方法_pt924g超级密码-CSDN博客
一、电脑有线或无线连接到PT924,用光猫背后的User用户登陆。
二、在登陆后的浏览器地址栏输入:
http://192.168.1.1/cgi-bin/abcdidfope94e0934jiewru8ew414.cgi,
返回200OK信息,成功开启Telnet服务。
三、打开电脑命令提示符界面(CMD),输入Telnet,
用户名为yhtcAdmin,密码为Cm1@YHfw
成功登陆后,在#号依次输入:
#cd /usr/local/ct
#vi lastgood.xml
然后查找用户和密码,在vi中,
先输入“:”,进入命令模式,
然后输入“/SUSER_PASSWORD”,查找密码。
如成功,则会看到
这就是超级用户名和密码了,记录下来。
注,退出VI方法,输入“:”号进入命令模式,接着输入“q!”,回车即可退出。
四、然后在浏览器中,输入http://192.168.1.1,用以上查到的信息可以进入超级用户模式了。
五、随后,您就可以根据自己需要改光猫为桥接模式了。
感谢https://blog.csdn.net/gsls200808/article/details/106307953提供的telnet开启信息。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/xeastsun/article/details/119767111
来源: Telnet远程文件传输_telnet 传输文件-CSDN博客
Telnet远程文件传输
前期准备
两台电脑同一网段
电脑A(172.16.40.112)电脑B(172.16.40.24)
解决把电脑A中文件通过telnet传输到电脑B中
1、勾选telnet客户端、打开telnet服务
①右键我的电脑–属性–控制面板–程序–程序和功能–启用/关闭windows功能–勾选Telnet Client-确定
②电脑A使用快捷键windows+R–输入cmd打开命令行–输入telnet进入telnet页面
③输入“open+ip”这里我们输入电脑B的ip即为“open 172.16.40.24”
④输入电脑B用户名、密码和域名(PS:域名输任意值即可),进入之后如下图所示
⑤打开需要共享的文件盘例如D盘即输入命令“net share file=D:\files”
⑥电脑A再次使用快捷键windows+R–输入cmd打开命令行-输入命令“net share file=D:\111”(PS:111即为要分享的文件)
⑦输入命令“net use \172.16.40.24\ipc$ “123456” /user:“administrator””连接到电脑B
⑧输入复制命令“xcopy d:\1.txt \172.16.40.24\D( D (D(D就是上面提到的共享文件的共享名,这个位置可以是任意你需要的并且共享了的共享文件的共享名)”即可完成复制
PS:关掉一切杀毒软件及防火墙,不然会出现复制不成功情况
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_39870603/article/details/114928541
来源: 移动光猫gm228-s超级管理密码获取及桥接 – 哔哩哔哩
强烈建议有一定操作基础的人进行!
强烈建议有一定操作基础的人进行!
强烈建议有一定操作基础的人进行!
否则建议海鲜市场,让人远程操作。
这里只是提供操作思路,有空我在补全一些操作。
如果超级管理密码不是:aDm8H%MdA,那么就是动态密码了。
Telnet的普通用户及密码(此用户没有修改权限)
用户名:CMCCAdmin
光猫背面user的密码+@C1(没有加号)
在这个模式下可以查看宽带的账号密码,应该是/etc/network/….忘是哪里,完了有空补上。
获取root用户的密码
推荐谷歌或者微软edge浏览器:按F12进入开发者模式
地址栏输入:192.168.1.1/webcmcc/telnet.html(会默认打开telnet服务)
在开发者栏中,network(网络)标签中,有一个条请求,点击右边选择playload(参数负载)
包含admin和一个密码,这个密码就是telnet的密码。
这里很坑,我一直以为admin是账号,其实是root
省略telnet操作教程。。。。
登录进去后
cd /config/worka 回车
ls -al 回车
vi lastgood.xml 回车
/TeleAccountName 回车
这里是键值对
超级账户的账号:aucTeleAccountName
密码:aucTeleAccountPassword
我们需要修改后面的Value中的内容
这里的其实可以看见user用户,并且密码是16进制数所对应的ASCII码。但是超级用户的就不是了,只能通过修改超级密码,改成和user用户一样的即可。
鼠标框选 aucUserAccountPassword 后面Value内的十六进制数字,如果是windows命令行进行的telnet操作,单击摁住鼠标左键选中value内的数字,不包含双引号(不用复制后面的00,00),然后单机右键,新建一个记事本,ctrl+v 复制,看下对不对,最后一个数字后面不包含逗号。
按键盘 i 键进入编辑模式
用方向键移动光标删除 aucTeleAccountPassword 后面Value引号内的十六进制数字,很长。。。
鼠标右键粘贴之前复制的内容
按 Esc 退出编辑模式
:wq 回车
reboot 回车
等待2分钟路由重启
登录光猫
输入aucTeleAccountName 后面Value的值,应该是CMCCAdmin
输入光猫背面的默认终端配置密码 作者:24339999341_bili https://www.bilibili.com/read/cv30017987/?jump_opus=1 出处:bilibili
来源: 移动烽火HG6543C4、HG6543C5开telnet教程 – 技术综合版块 – 通信人家园 – Powered by C114
| 本帖最后由 738688013 于 2021-11-16 10:48 编辑
一、开启临时telnet连接到光猫局域网下,浏览器中打开url 二、隐藏页面临时开启1.打开telnetWIN+R唤出Windows运行窗口 注意:需要提前打开Windows telnet服务,打开方式如下 控制面板>所有控制面板项>程序和功能>启动或关闭Windows功能>找到telnet选项打上✔,等待服务加载完成 !控制面板](?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAdWlhbnVp,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center) 2.telnet登录开启隐藏界面服务telnet登录界面 三、登录隐藏界面获得超级密码浏览器中打开隐藏界面登录url:192.168.1.1 四、用超级密码登录并修改网络设置 浏览器中打开隐藏界面登录url:192.168.1.1 用上一步中获取的超密登录 帐号:维护账号 密码:维护密码 进入网络>宽带设置>网络连接 选择连接名称中的INTERNET项 再对设置进行更改 如 连接模式:路由|桥接 IP模式:IPv4|IPv6|IPv4&IPv6 |
来源: 中国移动 烽火HG6543C5光猫 获取超级密码教程
网上关于获取移动烽火HG6543C5型号光猫超级密码的教程参差不一,笔者在查找资料的时候走了不少弯路,现将自己整理的有效办法整理如下,希望能够帮助遇到同样问题的朋友。
注意:
运营商为中国移动福建地区,光猫型号为烽火HG6543C5,操作环境为Windows笔记本,笔者未在其他条件下尝试过,但是方法应该类似。
连接到光猫局域网下,浏览器中打开url
http://192.168.1.1/cgi-bin/telnetenable.cgi?telnetenable=1

Win+R唤出Windows运行窗口
输入telnet 192.168.1.1进入到telnet登录光猫界面
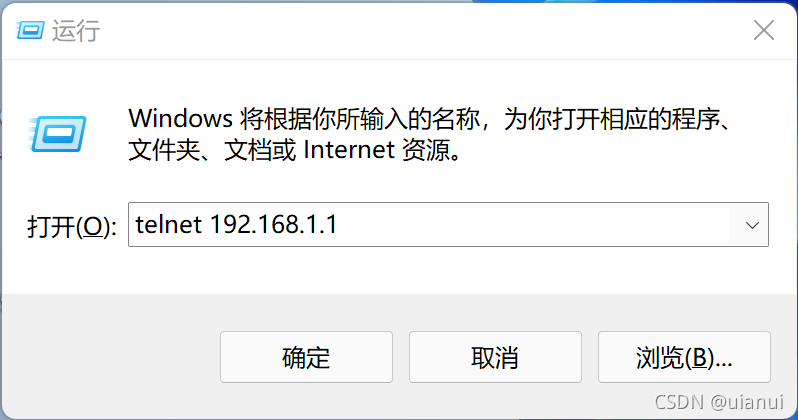
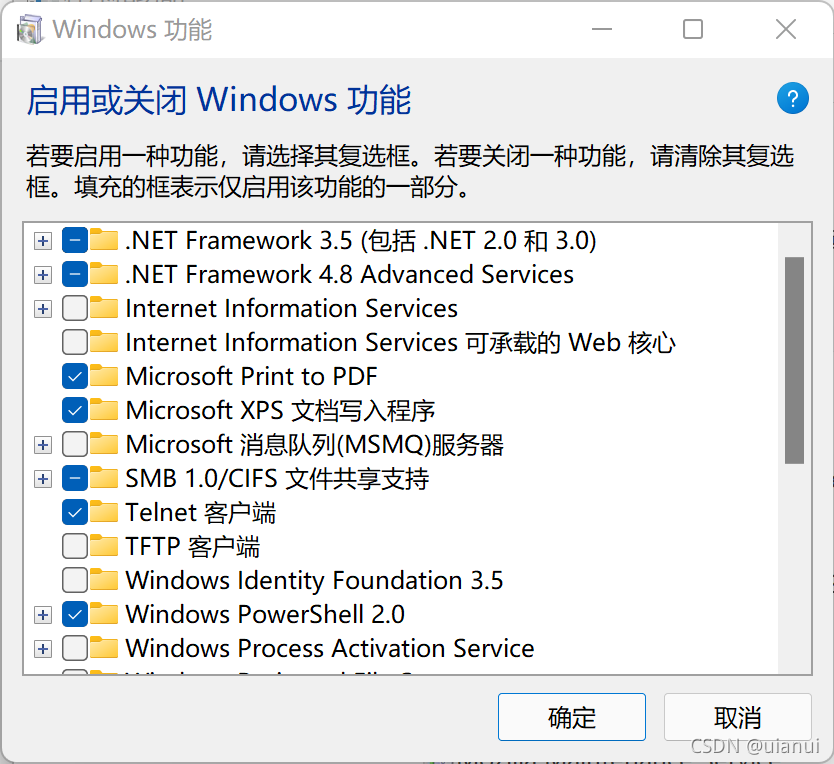
需要提前打开Windows telnet服务,打开方式如下
控制面板>所有控制面板项>程序和功能>启动或关闭Windows功能>找到telnet选项打上✔,等待服务加载完成
!控制面板](https://img-blog.csdnimg.cn/390c468266da41c4b4a5f67140761002.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAdWlhbnVp,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
telnet登录界面
帐号:admin
密码:nE7jA%5m
登录后执行
touch /var/fhconfig
成功后命令行界面为
(none)login:admin
Password:
#touch /var/fhconfig
#

浏览器中打开隐藏界面登录url:192.168.1.1
帐号:fiberhomehg2x0
密码:zgjt
登录成功后,再进入出厂设置>基本设置>账号密码设置
其中的维护账号和维护密码就是我们说的超级密码了
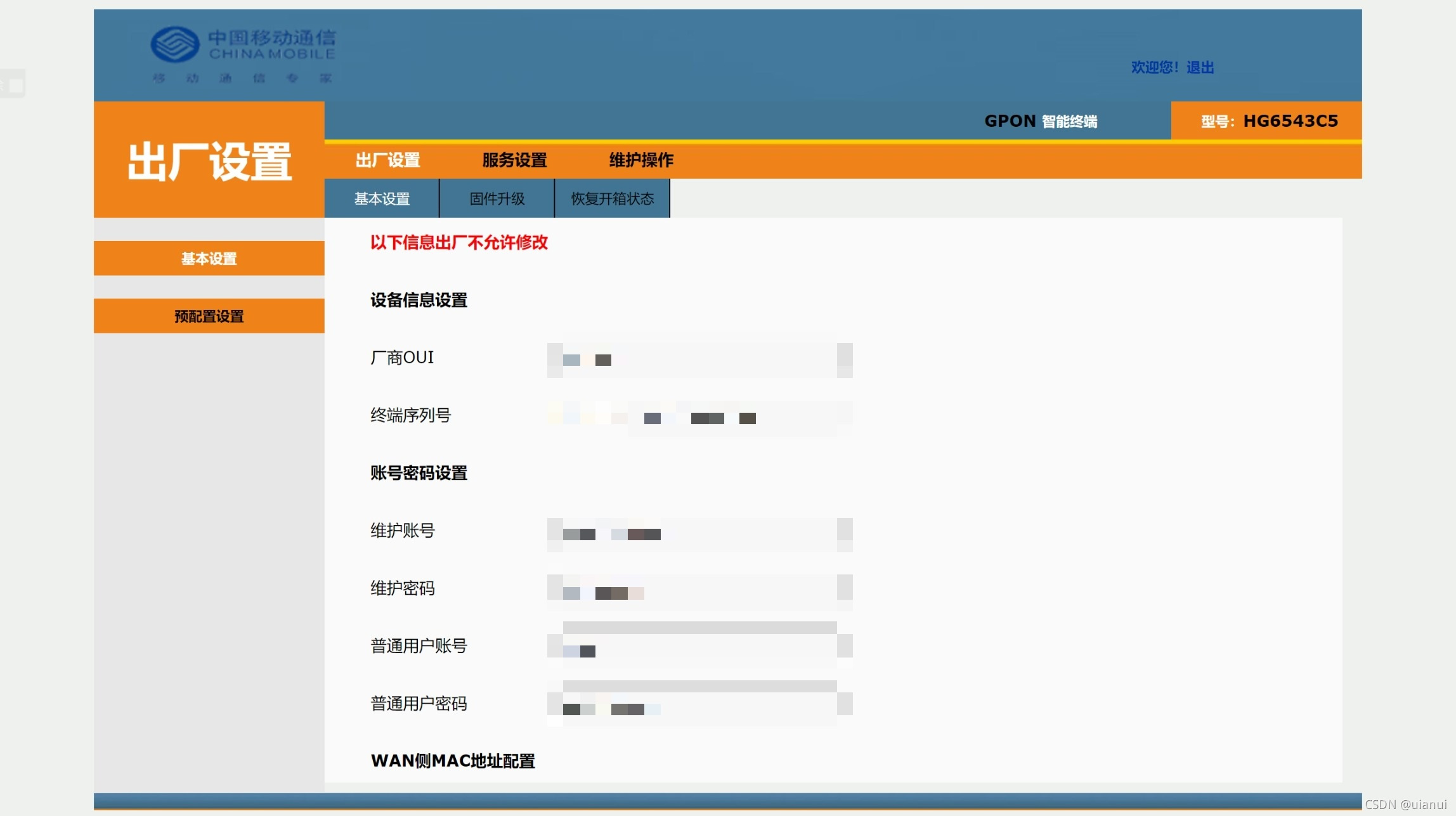
浏览器中打开隐藏界面登录url:192.168.1.1
用上一步中获取的超密登录
帐号:维护账号
密码:维护密码
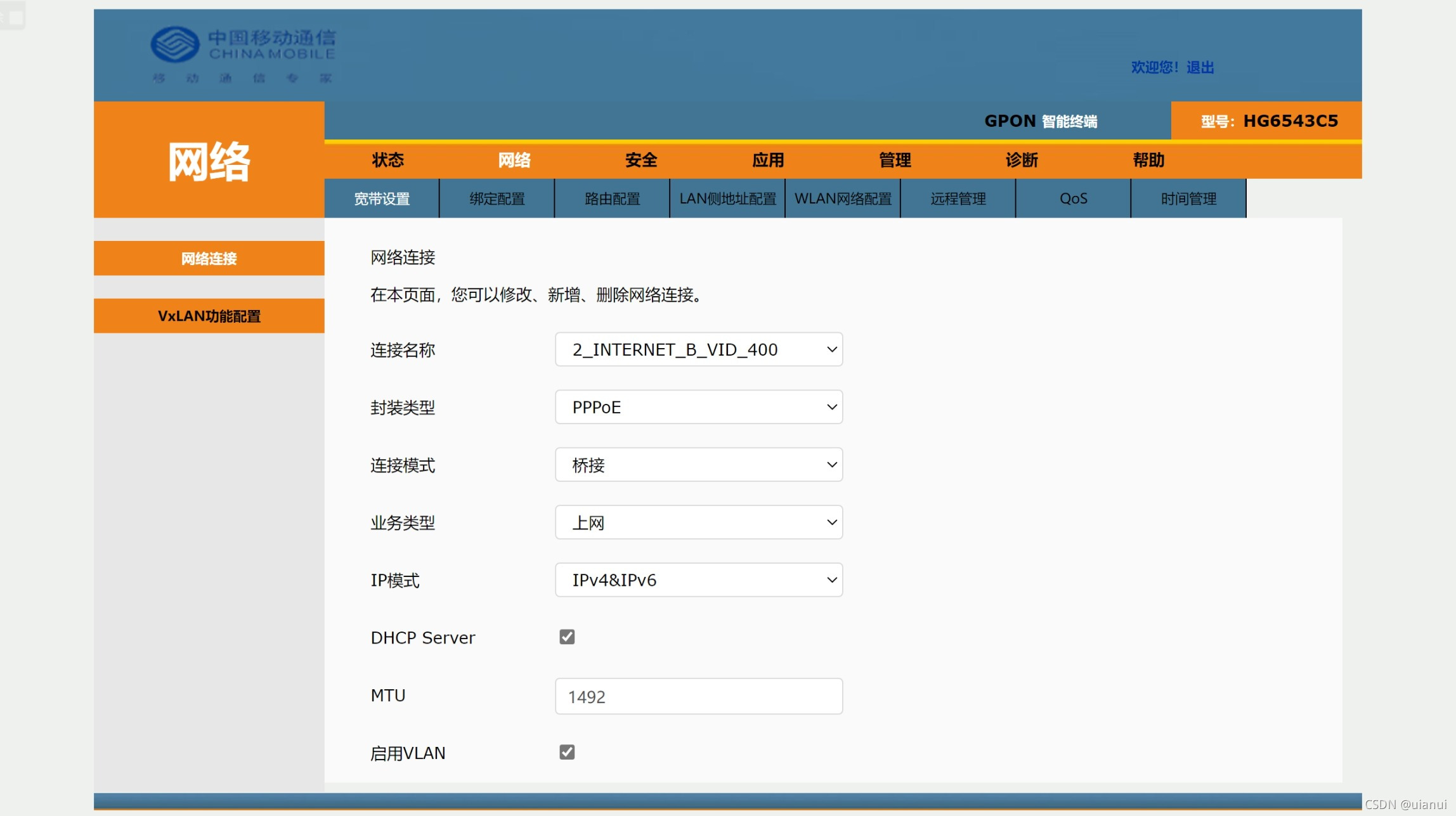
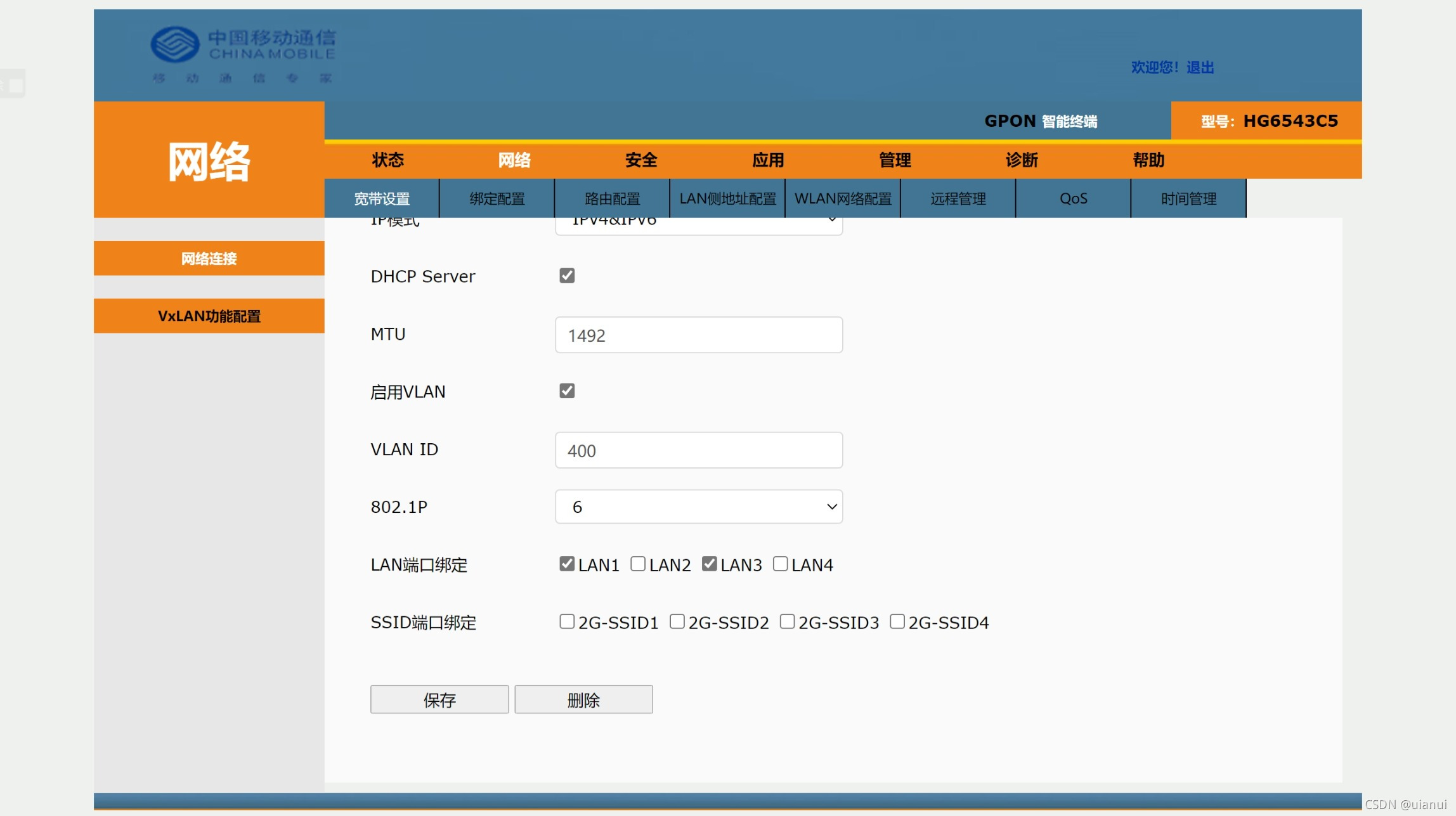
进入网络>宽带设置>网络连接
选择连接名称中的INTERNET项
再对设置进行更改
如
连接模式:路由|桥接
IP模式:IPv4|IPv6|IPv4&IPv6

烽火HG6543C5关闭强弹 – 技术综合版块 – 通信人家园 – Powered by C114
来源: 谷歌跨域插件:Allow CORS: Access-Control-Allow-Origin_allow-control-allow-origin插件-CSDN博客
链接:https://pan.baidu.com/s/13TYc3wn6xOfobFwVjR4IAw
提取码:1234
crx是谷歌chrome插件的扩展格式。谷歌扩展插件安装有两种方式,在线安装和线下安装。在线安装就不多说了,主要说线下安装:
1、从设置->更多工具->扩展程序 打开扩展程序页面
2、打开扩展程序页面的”开发者模式”
3、将crx文件拖拽到扩展程序页面,完成安装
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_48947842/article/details/123877924
来源: 宽带师傅不会主动告诉你:获取光猫超级密码,可开启隐藏模式 – 知乎
光猫大家都知道吧,它就像家庭网络的大脑,负责决定你能够畅通无阻地冲浪互联网的速度。
然而,有一个小秘密,很多人并不知道!
光猫有两种模式,而且你可以在它的”隐藏模式”中享受更畅快的网络体验。那么,怎么开启这个隐藏模式呢?

这就要靠获取光猫的超级密码了~
首先,让我们来了解一下光猫的两种模式:路由模式和桥接模式。就像我们自己的大脑可以在不同模式下工作,光猫也可以选择不同的工作方式。
路由模式:这是默认设置,安装简单,但性能相对较弱。当在线设备过多时,你可能会感到网络变得缓慢。

桥接模式:这个模式相对强大,因为它把拨号和路由任务都交给了你的路由器。信号更强,网络更稳定。
现在,我们来谈谈如何开启这个神秘的桥接模式。你需要获取光猫的超级密码,它是进入光猫设置的大门钥匙,给你更高的权限。
但这里有一个小问题,不同的光猫型号可能有不同的超级密码,而且很多时候,这些密码不再是默认初始密码了。所以,你可能需要做一些功课,找到正确的密码。
现在,让我们探讨一下如何找到这个超级密码。市面上有数不清的不同型号的光猫,即使是相同型号的光猫,也可能有不同版本的软件和不同的运营商,所以默认密码可能不适用。有几种方法可以尝试:

恢复出厂设置:这是一种方法,它有时可以恢复默认密码。就像把手机重置到出厂设置一样,但要小心,因为你可能会丢失其他设置。
联系客服:这是一种最简单最方便的方法。直接打电话找你的运营商客服要密码。他们通常会知道,并愿意提供帮助。
但是,有时候客服也会需要你验证一些信息,以确保你是合法用户。
找之前的师傅:如果你能找到之前安装光猫的师傅,他们可能会帮你查询密码。毕竟,他们是当地的网络大师,通常知道一些窍门。
一旦你拿到了超级密码,恭喜你,你已经走进了开启隐藏模式的大门。现在,你可以准备把光猫设置成桥接模式了。
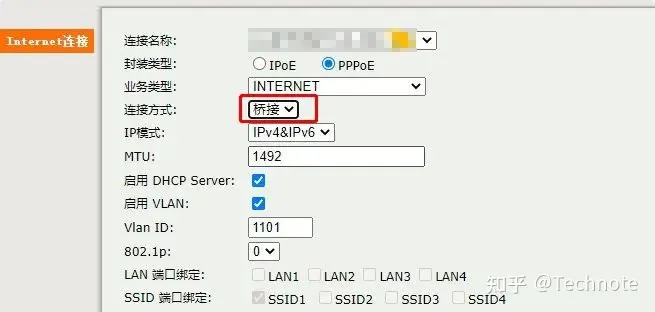
具体的设置方法可能因光猫型号的不同而异,所以最好还是找到与你的光猫型号相对应的教程来参考。
光猫切换到桥接模式后,你将享受到更加稳定的网络连接,改善NAT类型,轻松上网,无论是玩游戏还是看电影都会更加流畅。

最后的建议是,网络在不断发展,光猫型号也是多种多样。
在设置之前,最好找到与你的光猫型号相对应的教程,因为一个教程并不适用于所有光猫,细节上可能会有些差别。

但一旦你开启了隐藏模式,你将成为自己家庭网络的大师,享受更流畅的网络体验。
所以,走出去,获取那个超级密码,让你的网络更强大吧!
来源: 破解移动光猫吉比特UNG220Z超级密码过程方法-破解移动光猫吉比特UNG220Z超级密码过程方法
破解移动光猫吉比特UNG220Z超级密码过程方法

上月电信宽带取消后从新办理0元500兆移动宽带,但是装修师傅不给桥接也不给超级账号密码,然后看光猫型号为UNG220Z,百度恩山都没发现有密码,网上的通用账号密码都不得行,得知网友回复光猫注册后会自动随机更改密码,看恩山发现有两种方法可行,第一种需要光猫复位就没试,就分享下第二种方法
一用光猫背后的普通账号登陆光猫后输入http://192.168.1.1/getpage.gch?pid=1002&nextpage=tele_sec_tserver_t.gch开启telnet,账号为CMCCAdmin密码为aDm8H%MdA
二电脑cmd命令输入telnet 192.168.1.1,登陆账号密码同上,依次输入以下命令即可
sidbg 1 DB decry /userconfig/cfg/db_user_cfg.xml
cat /tmp/Debug-decry-cfg | grep Pass
账号密码就会显示出来
好了,完成不需要其他教程的下载浏览器插件,获取密码文件然后解密 ,一步到位

来源: 重置移动光猫的管理员账号和密码 – Lebenito’s Blog
主要参考两篇帖子
一. 用光猫背后的普通账号登陆光猫后输入 http://192.168.1.1/getpage.gch?pid=1002&nextpage=tele_sec_tserver_t.gch 开启telnet,账号为CMCCAdmin密码为aDm8H%MdA
二. 电脑cmd命令输入telnet 192.168.1.1,登陆账号密码同上,依次输入以下命令即可
sidbg 1 DB decry /userconfig/cfg/db_user_cfg.xml
以下命令来自第二篇帖子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
sidbg 1 DB decry /userconfig/cfg/db_user_cfg.xml
解密后文件在
/tmp/debug-decry-cfg
PS:给出几个常用的
列出所有表
sidbg 1 DB p all
查看 TELNET 信息
sidbg 1 DB p TelnetCfg
查看 查看用户 信息
sidbg 1 DB p DevAuthInfo
修改管理员超级账号为 CMCCAdmin (可自定义)
sidbg 1 DB set DevAuthInfo 0 User CMCCAdmin
修改管理员超级账号的密码 aDm8H%MdA (可自定义)
sidbg 1 DB set DevAuthInfo 0 Pass aDm8H%MdA
修改配置 永久 开启 TELNET
开启TELNET
sidbg 1 DB set TelnetCfg 0 TS_Enable 1
开放TELNET LAN端口
sidbg 1 DB set TelnetCfg 0 Lan_Enable 1
关闭TELNET
sidbg 1 DB set TelnetCfg 0 TS_Enable 0
关闭TELNET LAN端口
sidbg 1 DB set TelnetCfg 0 Lan_Enable 0
修改TELNET账号 改为 root (可自定义)
sidbg 1 DB set TelnetUser 0 Username root
修改TELNET密码 改为 admin (可自定义)
sidbg 1 DB set TelnetUser 0 Password admin
修改TELNET账号 改为 root (可自定义)
sidbg 1 DB set TelnetUser 1 Username root
修改TELNET密码 改为 admin (可自定义)
sidbg 1 DB set TelnetUser 1 Password admin
记得最好保存下配置
sidbg 1 DB save
|