—-收缩数据库日志 DBCC ShrinkFile(‘TestLogFull_Log’, 100)
来源: SQLServer数据库中开启CDC导致事务日志空间被占满的原因_woailyoo0000的博客-CSDN博客_数据库
SQLServer中开启CDC之后,在某些情况下会导致事务日志空间被占满的现象为:
在执行增删改语句(产生事务日志)的过程中提示,
The transaction log for database ‘***’ is full due to ‘REPLICATION’
(数据库“***”的事务日志已满,原因为“REPLICATION”).
解决办法:
EXEC SP_Repldone @xactid=NULL ,
@xact_segno = NULL,
@numtrabs = 0 ,
@time = 0
@reset = 1
CDC以及复制的基本原理粗略地讲,对于日志的使用步骤如下:
1,每当基础表(开启了CDC或者replication的表)产生事务性操作(增删改)之后,对应的事务日志写入日志文件,
2,此时的日志被状态被标记为Replication,也即处于待复制状态,这个活动状态跟数据库的还原模式无关,即便是简单还原模式,
3,然后有后台进程来读取这个日志,根据事务日志的内存写入目标表,
这个目标对于cdc来说是记录数据变化的系统表,
对于replication来说是写入distribution这个库
4,步骤3完成之后,事务日志被标记为正常状态,如果是简单还原模式,被后台进程解析过的事务日志被截断,可以重用如果上述中间的第三个步骤出现问题,也即后台进程无法解析日志后释放可用的日志空间,再次往数据库中写入操作,就会出现:数据库“TestDB”的事务日志已满,原因为“REPLICATION”的情况
本文通过通过演示开启CDC的情况下日志空间被占满的现象,以及对应的处理办法
测试环境搭建
首先建立一个测试数据库
-
USE master
-
GO
-
CREATE DATABASE TestLogFull ON PRIMARY
-
(
-
NAME = N‘TestLogFull’,
-
FILENAME = N‘D:\DBFile\TestLogFull\TestLogFull.mdf’ ,
-
SIZE = 500MB ,
-
MAXSIZE = UNLIMITED,
-
FILEGROWTH = 100MB
-
)
-
LOG ON
-
(
-
NAME = N‘TestLogFull_log’,
-
FILENAME = N‘D:\DBFile\TestLogFull\TestLogFull_Log.ldf’ ,
-
SIZE = 1MB ,
-
MAXSIZE = 512MB
-
)
这里指定日志文件的最大为512M,主要是为了演示日志空间被占满的现象
接着开启新建一个表同时开启CDC来测试
-
USE TestLogFull
-
–启用CDC
-
EXECUTE sys.sp_cdc_enable_db;
-
GO
-
–创建一张测试表
-
create table test_cdc
-
(
-
id int identity(1,1) primary key,
-
name nvarchar(50),
-
mail varchar(50),
-
address nvarchar(50),
-
lastupdatetime datetime
-
)
-
–对表启用CDC
-
EXEC sys.sp_cdc_enable_table
-
@source_schema = ‘dbo’,
-
@source_name = ‘test_cdc’,
-
@role_name = ‘cdc_admin’,
-
@capture_instance = DEFAULT,
-
@supports_net_changes = 1,
-
@index_name = NULL,
-
@filegroup_name = DEFAULT
-
-
–查询数据库是否开启了CDC
-
SELECT name, is_tracked_by_cdc
-
FROM sys.tables
-
WHERE OBJECT_ID = OBJECT_ID(‘dbo.test_cdc’)
-
这里演示对某些表开启CDC的情况下日志文件文件被占满的情况
1. 代理服务器未启动导致日志空间被占满
文中一开始提到的步骤3,对于CDC,进程就是SQL Server Agent中的cdc.***_capture作业或者复制代理作业来读取日志
如果SQL Server Agent在开启了CDC或者复制之后被关闭,或者重启服务器之后SQL Server Agent没有随机自动启动
就有可能造成步骤2中的日志积压,也就是记录数据变化之后的事务日志处于replication状态,无法重用,导致没有可以使用的日志致使发生操作数据库的时候提示The transaction log for database ‘***’ is full due to ‘REPLICATION’.
这里暂时关闭代理服务(仅仅是为了测试演示这一现象)
增删改都可以产生事务日志,这里就演示insert数据的情况,做一个写数据的SQL,往开启了CDC的表中写数据库
在建库的时候日志文件有限制成了512M,因为这个表上开启了CDC,写数据这个过程会产生事务日志,日志有空空间限制在写入数据的过程中,一开始是没有问题的,随着数据的不断写入(Replication状态的日志不断积压),当日志全部使用之后,下面的报错就会产生了
-
while 1=1
-
begin
-
Insert Into test_cdc values(newid(), newid(), getdate())
-
end
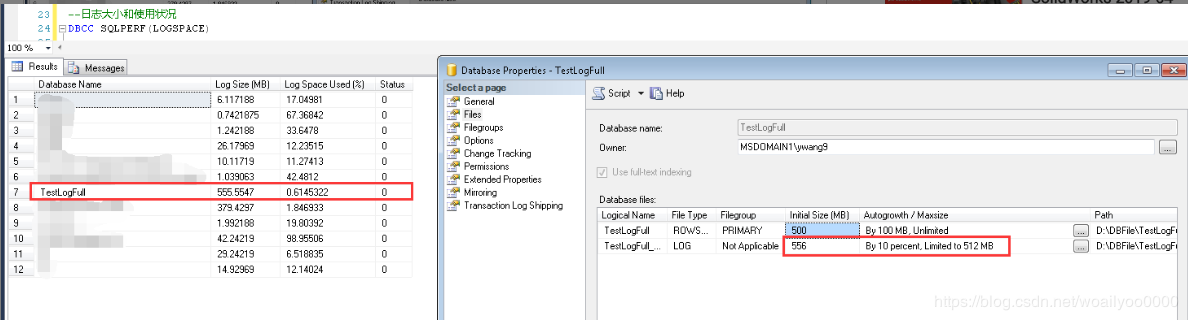
此时观察事务日志的使用情况,发现已经是完全使用了,
-
–查询日志使用率
-
DBCC SQLPERF(LOGSPACE)
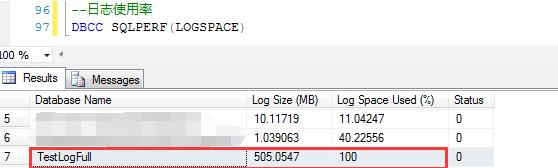
因为日志空间被完全使用了,那么观察一下日志的等待状态,是Replication状态
-
-
—-查询等待日志模式
-
SELECT NAME,DATABASE_ID, LOG_Reuse_Wait, Log_Reuse_Wait_Desc
-
FROM
-
Sys.DATABASES
-
WHERE Name = ‘TestLogFull’
此时尝试收缩也是无效的,因为日志都是出于活动状态,活动状态的日志是无法收缩的
-
—-收缩数据库日志
-
DBCC ShrinkFile(‘TestLogFull_Log’, 100)
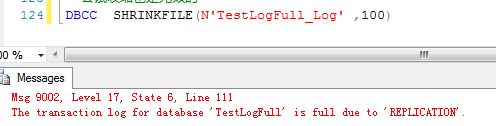
可见,因为代理被关闭,读取日志的作业无法执行,造成日志堵塞,那么开启代理来看看到底行不行?
开启代理,查看CDC作业的执行情况,会发现,此时代理作业也不好使了,作业执行的时候并没有成功,一样提示说事务日志已满
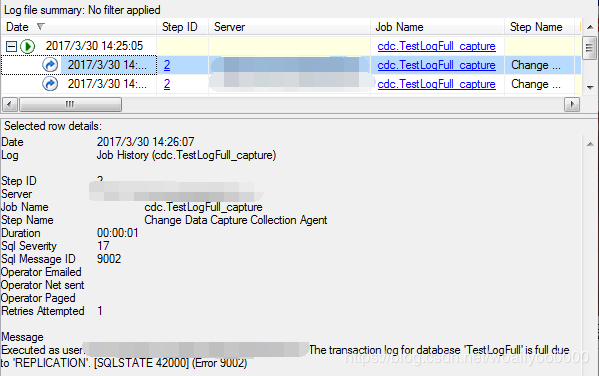
此时观察测试表的cdc目标表没有任何数据,说明此时即便开启了代理,cdc的作业依然没有成功执行
那么这里为什么CDC的代理作业也无法正常执行?
其实也不难理解,cdc的作业也是读取事务日志写数据的,这中间也相当于有事务性操作,必须要借助日志来实现,而此时又没有可用的日志空间,
这个作业当然要失败了。
那么此时怎么办?
既然是日志堵塞了,就想办法清理到这部分活动日志,尝试将事务日志标记为已分发(虽然这里是CDC,但是对于日志的使用应该是跟复制一样的)
-
–将日志中复制的事务标识改为已分发
-
EXEC SP_Repldone @xactid=NULL ,
-
@xact_segno = NULL,
-
@numtrabs = 0 ,
-
@time = 0
-
@reset = 1
据本人的测试,在执行上面的语句,将复制的事物标记为已分发之后,再次查看日志使用率,发现还是100%,但是尝试写入数据的时候是成功的,再次写入数据(一条即可)之后,日志空间开始释放,应该是写入时候的时候触发被标记为已分发的日志截断,也就是将上面占用了100%的日志空间释放出来然后再观察日志的使用率,发现如预期的,这部分日志已被截断,日志空间不再是被完全占用了,日志变成Nothing状态(可重用)
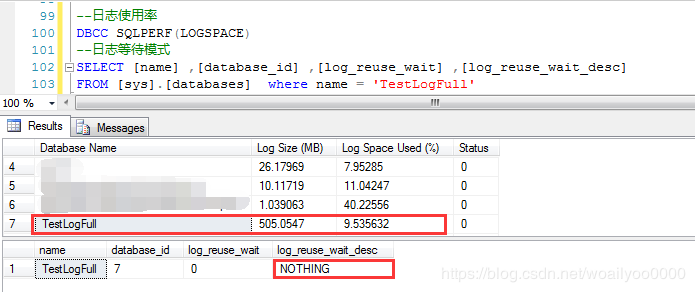
这个测试说明,如果开启了CDC,SQL Server代理没有正常启动或者对应的作业没有正常启动,日志空间会随着不断产生的事物被占满,导致数据库无法进行写入性操作
这里是用过手动标记日志为已分发的方式来释放日志的,这种情况下会导致cdc日志断裂的情况,也就是手动释放的日志无法传递到下游(cdc日志表)
毕竟不是一个太好的办法,下面会说明另外一种办法。
2,短时间内较大的事务性操作导致的日志空间被占满的情况
对去上面所说的代理服务被关闭导致日志堵塞的情况不同,这里直接开启代理服务,依旧拿着下面的脚本往表中写数据(比如实际业务中批量导入数据之类的)
在写入一段时间之后,依然出现了事务日志被填满的情况,这又是为什么?
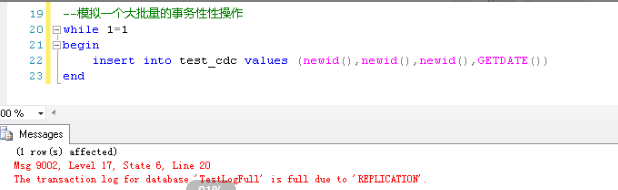
还要从CDC的代理任务说起,这个代理的JOB虽然是连续执行的,但是因为上面写数据的时候也是连续写入的,也就是日志是连续产生的,
因为限制了日志文件的大小(这里为了方便演示,限制为512M),日志文件有最大使用空间的限制。
这里可以认为是一个Session消耗日志空间(Insert操作),一个进程解析日志之后释放日志空间(代理作业),
但是消耗的速度要高于释放的速度,一旦日志空间被使用完,CDC的代理作业也无法完成,
这样就又造成了上面的情况:日志空间被填满,数据库无法执行任何写入操作,CDC作业也无法执行从而释放可重用的日志空间,
上面是通过手动标记事务日志的状态来解决日志文件被填满的,
直接手动标记日志为已分发的做法是有点不合适的,
一旦标记日志状态为已分发,接下来他就不会传递给CDC的系统表或者订阅端了
这里通过另外一种方法来解决此问题:既然当前日志占满了,就在添加一个日志,注意新加日志初始化的空间不要太小。
(有兴趣测试的盆友,这里添加完日志文件后注意耐心等待一两分钟)然后随后的CDC作业会借助新加的这个日志空间会继续执行
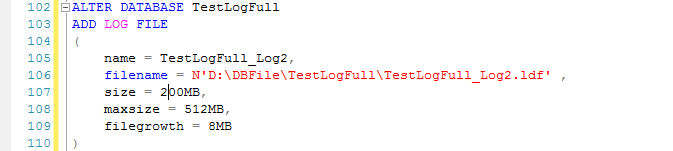
此种情况说明,如果限制了日志的大小(或者存储日志的磁盘空间不足),数据库中开启了CDC或者复制,
一旦数据出现大批量持续性写入操作(增删改),此时会出现SQL Server代理解析并释放日志的速度跟不上,也有可能造成日志被占满的情况
3,不增加日志文件空间或者添加日志文件情况下重启SQLServer服务
这个办法也是本人在重现这一现象并尝试解决的时候试出来的,可行性不是太强,但还是说明一下,那就是重启大法,同时重启之后日志文件也发生了一些有意思的变化
建库的时候日志文件限制为最大512M,同时没有手动标记标记日志为已分发状态,但是重启SQLServer服务之后,如果存放日志的磁盘有空间,这个日志会自动扩充一部分
然后有了这部分扩充出来的日志,代理job就可以解析Replication状态的日志(之后)就可以释放日志空间了(需要一段时间来解析并释放日志,根据待复制的日志量有关)
下图可以明显看到,日志限制为512MB,但是初始化为556MB,明显大过最大日志大小,这个是归功于重启SQLServer服务的结果
一下是在SQL Server 2014 SP2版本下测试的现象,
如果是SQL Server 2014(非SP2补丁版),开启CDC的方式占满日志则不会出现如下的情况,也就是说重启有日志并不会自动扩充一部分,我也是醉了,验证个东西真不容易,这些小细节跟补丁版本也有关系,不过这种偏门的方法不能作为经验!
总结:
当开启了CDC之后,在相关表上的变化会写入事务日志(日志状态为Replication状态),代理任务会解析日志,解析完日之后标记日志为可重建状态(如果是简单还原模式,是可重用,如果是完整还原模式,日志备份也无法截断Replication状态的日志),这种状态下如果限制了日志的最大大小比较小,或者没有限制,存储日志的磁盘空间不足,在大批量写入数据(增删改)的时候,有可能产生的日志占满日志文件的情况,会导致释放日志的代理作业无法进行,代理作业无法进行又无法释放日志,仿佛是死循环。
此时要么新增日志文件或者增加日志文件的最大大小,要么通过执行系统存储过程sp_repldone来标记事务为已分发(标记事务日志可重用)来解决这一问题。
以上所述是小编给大家介绍的SQLServer数据库中开启CDC导致”事务日志空间被占满的原因分析和解决办法(REPLICATION),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!