来源: SQL Server死锁总结 – Silent Void – 博客园
- 死锁原理
根据操作系统中的定义:死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。
死锁的四个必要条件:
互斥条件(Mutual exclusion):资源不能被共享,只能由一个进程使用。
请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。
非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。
循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。
对应到SQL Server中,当在两个或多个任务中,如果每个任务锁定了其他任务试图锁定的资源,此时会造成这些任务永久阻塞,从而出现死锁;这些资源可能是:单行(RID,堆中的单行)、索引中的键(KEY,行锁)、页(PAG,8KB)、区结构(EXT,连续的8页)、堆或B树(HOBT) 、表(TAB,包括数据和索引)、文件(File,数据库文件)、应用程序专用资源(APP)、元数据(METADATA)、分配单元(Allocation_Unit)、整个数据库(DB)。一个死锁示例如下图所示:
说明:T1、T2表示两个任务;R1和R2表示两个资源;由资源指向任务的箭头(如R1->T1,R2->T2)表示该资源被改任务所持有;由任务指向资源的箭头(如T1->S2,T2->S1)表示该任务正在请求对应目标资源;
其满足上面死锁的四个必要条件:
(1).互斥:资源S1和S2不能被共享,同一时间只能由一个任务使用;
(2).请求与保持条件:T1持有S1的同时,请求S2;T2持有S2的同时请求S1;
(3).非剥夺条件:T1无法从T2上剥夺S2,T2也无法从T1上剥夺S1;
(4).循环等待条件:上图中的箭头构成环路,存在循环等待。
- 死锁排查
(1). 使用SQL Server的系统存储过程sp_who和sp_lock,可以查看当前数据库中的锁情况;进而根据objectID(@objID)(SQL Server 2005)/ object_name(@objID)(Sql Server 2000)可以查看哪个资源被锁,用dbcc ld(@blk),可以查看最后一条发生给SQL Server的Sql语句;
CREATE Table #Who(spid int,
ecid int,
status nvarchar(50),
loginname nvarchar(50),
hostname nvarchar(50),
blk int,
dbname nvarchar(50),
cmd nvarchar(50),
request_ID int);
CREATE Table #Lock(spid int,
dpid int,
objid int,
indld int,
[Type] nvarchar(20),
Resource nvarchar(50),
Mode nvarchar(10),
Status nvarchar(10)
);
INSERT INTO #Who
EXEC sp_who active –看哪个引起的阻塞,blk
INSERT INTO #Lock
EXEC sp_lock –看锁住了那个资源id,objid
DECLARE @DBName nvarchar(20);
SET @DBName=’NameOfDataBase’
SELECT #Who.* FROM #Who WHERE dbname=@DBName
SELECT #Lock.* FROM #Lock
JOIN #Who
ON #Who.spid=#Lock.spid
AND dbname=@DBName;
–最后发送到SQL Server的语句
DECLARE crsr Cursor FOR
SELECT blk FROM #Who WHERE dbname=@DBName AND blk<>0;
DECLARE @blk int;
open crsr;
FETCH NEXT FROM crsr INTO @blk;
WHILE (@@FETCH_STATUS = 0)
BEGIN;
dbcc inputbuffer(@blk);
FETCH NEXT FROM crsr INTO @blk;
END;
close crsr;
DEALLOCATE crsr;
–锁定的资源
SELECT #Who.spid,hostname,objid,[type],mode,object_name(objid) as objName FROM #Lock
JOIN #Who
ON #Who.spid=#Lock.spid
AND dbname=@DBName
WHERE objid<>0;
DROP Table #Who;
DROP Table #Lock;
(2). 使用 SQL Server Profiler 分析死锁: 将 Deadlock graph 事件类添加到跟踪。此事件类使用死锁涉及到的进程和对象的 XML 数据填充跟踪中的 TextData 数据列。SQL Server 事件探查器 可以将 XML 文档提取到死锁 XML (.xdl) 文件中,以后可在 SQL Server Management Studio 中查看该文件。
- 避免死锁
上面1中列出了死锁的四个必要条件,我们只要想办法破其中的任意一个或多个条件,就可以避免死锁发生,一般有以下几种方法(FROM Sql Server 2005联机丛书):
(1).按同一顺序访问对象。(注:避免出现循环)
(2).避免事务中的用户交互。(注:减少持有资源的时间,较少锁竞争)
(3).保持事务简短并处于一个批处理中。(注:同(2),减少持有资源的时间)
(4).使用较低的隔离级别。(注:使用较低的隔离级别(例如已提交读)比使用较高的隔离级别(例如可序列化)持有共享锁的时间更短,减少锁竞争)
(5).使用基于行版本控制的隔离级别:2005中支持快照事务隔离和指定READ_COMMITTED隔离级别的事务使用行版本控制,可以将读与写操作之间发生的死锁几率降至最低:
SET ALLOW_SNAPSHOT_ISOLATION ON –事务可以指定 SNAPSHOT 事务隔离级别;
SET READ_COMMITTED_SNAPSHOT ON –指定 READ_COMMITTED 隔离级别的事务将使用行版本控制而不是锁定。默认情况下(没有开启此选项,没有加with nolock提示),SELECT语句会对请求的资源加S锁(共享锁);而开启了此选项后,SELECT不会对请求的资源加S锁。
注意:设置 READ_COMMITTED_SNAPSHOT 选项时,数据库中只允许存在执行 ALTER DATABASE 命令的连接。在 ALTER DATABASE 完成之前,数据库中决不能有其他打开的连接。数据库不必一定要处于单用户模式中。
(6).使用绑定连接。(注:绑定会话有利于在同一台服务器上的多个会话之间协调操作。绑定会话允许一个或多个会话共享相同的事务和锁(但每个回话保留其自己的事务隔离级别),并可以使用同一数据,而不会有锁冲突。可以从同一个应用程序内的多个会话中创建绑定会话,也可以从包含不同会话的多个应用程序中创建绑定会话。在一个会话中开启事务(begin tran)后,调用exec sp_getbindtoken @Token out;来取得Token,然后传入另一个会话并执行EXEC sp_bindsession @Token来进行绑定(最后的示例中演示了绑定连接)。
- 死锁处理方法:
(1). 根据2中提供的sql,查看那个spid处于wait状态,然后用kill spid来干掉(即破坏死锁的第四个必要条件:循环等待);当然这只是一种临时解决方案,我们总不能在遇到死锁就在用户的生产环境上排查死锁、Kill sp,我们应该考虑如何去避免死锁。
(2). 使用SET LOCK_TIMEOUT timeout_period(单位为毫秒)来设定锁请求超时。默认情况下,数据库没有超时期限(timeout_period值为-1,可以用SELECT @@LOCK_TIMEOUT来查看该值,即无限期等待)。当请求锁超过timeout_period时,将返回错误。timeout_period值为0时表示根本不等待,一遇到锁就返回消息。设置锁请求超时,破环了死锁的第二个必要条件(请求与保持条件)。
服务器: 消息 1222,级别 16,状态 50,行 1
已超过了锁请求超时时段。
(3). SQL Server内部有一个锁监视器线程执行死锁检查,锁监视器对特定线程启动死锁搜索时,会标识线程正在等待的资源;然后查找特定资源的所有者,并递归地继续执行对那些线程的死锁搜索,直到找到一个构成死锁条件的循环。检测到死锁后,数据库引擎 选择运行回滚开销最小的事务的会话作为死锁牺牲品,返回1205 错误,回滚死锁牺牲品的事务并释放该事务持有的所有锁,使其他线程的事务可以请求资源并继续运行。
- 两个死锁示例及解决方法
5.1 SQL死锁
(1). 测试用的基础数据:
CREATE TABLE Lock1(C1 int default(0));
CREATE TABLE Lock2(C1 int default(0));
INSERT INTO Lock1 VALUES(1);
INSERT INTO Lock2 VALUES(1);
(2). 开两个查询窗口,分别执行下面两段sql
–Query 1
Begin Tran
Update Lock1 Set C1=C1+1;
WaitFor Delay ’00:01:00′;
SELECT * FROM Lock2
Rollback Tran;
–Query 2
Begin Tran
Update Lock2 Set C1=C1+1;
WaitFor Delay ’00:01:00′;
SELECT * FROM Lock1
Rollback Tran;
上面的SQL中有一句WaitFor Delay ’00:01:00’,用于等待1分钟,以方便查看锁的情况。
(3). 查看锁情况
在执行上面的WaitFor语句期间,执行第二节中提供的语句来查看锁信息:
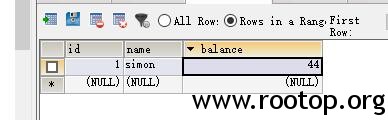
Query1中,持有Lock1中第一行(表中只有一行数据)的行排他锁(RID:X),并持有该行所在页的意向更新锁(PAG:IX)、该表的意向更新锁(TAB:IX);Query2中,持有Lock2中第一行(表中只有一行数据)的行排他锁(RID:X),并持有该行所在页的意向更新锁(PAG:IX)、该表的意向更新锁(TAB:IX);
执行完Waitfor,Query1查询Lock2,请求在资源上加S锁,但该行已经被Query2加上了X锁;Query2查询Lock1,请求在资源上加S锁,但该行已经被Query1加上了X锁;于是两个查询持有资源并互不相让,构成死锁。
(4). 解决办法
a). SQL Server自动选择一条SQL作死锁牺牲品:运行完上面的两个查询后,我们会发现有一条SQL能正常执行完毕,而另一个SQL则报如下错误:
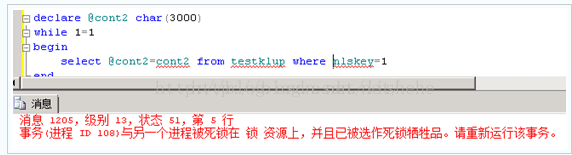
服务器: 消息 1205,级别 13,状态 50,行 1
事务(进程 ID xx)与另一个进程已被死锁在 lock 资源上,且该事务已被选作死锁牺牲品。请重新运行该事务。
这就是上面第四节中介绍的锁监视器干活了。
b). 按同一顺序访问对象:颠倒任意一条SQL中的Update与SELECT语句的顺序。例如修改第二条SQL成如下:
–Query2
Begin Tran
SELECT * FROM Lock1–在Lock1上申请S锁
WaitFor Delay ’00:01:00′;
Update Lock2 Set C1=C1+1;–Lock2:RID:X
Rollback Tran;
当然这样修改也是有代价的,这会导致第一条SQL执行完毕之前,第二条SQL一直处于阻塞状态。单独执行Query1或Query2需要约1分钟,但如果开始执行Query1时,马上同时执行Query2,则Query2需要2分钟才能执行完;这种按顺序请求资源从一定程度上降低了并发性。
c). SELECT语句加With(NoLock)提示:默认情况下SELECT语句会对查询到的资源加S锁(共享锁),S锁与X锁(排他锁)不兼容;但加上With(NoLock)后,SELECT不对查询到的资源加锁(或者加Sch-S锁,Sch-S锁可以与任何锁兼容);从而可以是这两条SQL可以并发地访问同一资源。当然,此方法适合解决读与写并发死锁的情况,但加With(NoLock)可能会导致脏读。
SELECT * FROM Lock2 WITH(NOLock)
SELECT * FROM Lock1 WITH(NOLock)
d). 使用较低的隔离级别。SQL Server 2000支持四种事务处理隔离级别(TIL),分别为:READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZABLE;SQL Server 2005中增加了SNAPSHOT TIL。默认情况下,SQL Server使用READ COMMITTED TIL,我们可以在上面的两条SQL前都加上一句SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED,来降低TIL以避免死锁;事实上,运行在READ UNCOMMITTED TIL的事务,其中的SELECT语句不对结果资源加锁或加Sch-S锁,而不会加S锁;但还有一点需要注意的是:READ UNCOMMITTED TIL允许脏读,虽然加上了降低TIL的语句后,上面两条SQL在执行过程中不会报错,但执行结果是一个返回1,一个返回2,即读到了脏数据,也许这并不是我们所期望的。
e). 在SQL前加SET LOCK_TIMEOUT timeout_period,当请求锁超过设定的timeout_period时间后,就会终止当前SQL的执行,牺牲自己,成全别人。
f). 使用基于行版本控制的隔离级别(SQL Server 2005支持):开启下面的选项后,SELECT不会对请求的资源加S锁,不加锁或者加Sch-S锁,从而将读与写操作之间发生的死锁几率降至最低;而且不会发生脏读。啊
SET ALLOW_SNAPSHOT_ISOLATION ON
SET READ_COMMITTED_SNAPSHOT ON
g). 使用绑定连接(使用方法见下一个示例。)
5.2 程序死锁(SQL阻塞)
看一个例子:一个典型的数据库操作事务死锁分析,按照我自己的理解,我觉得这应该算是C#程序中出现死锁,而不是数据库中的死锁;下面的代码模拟了该文中对数据库的操作过程:
//略去的无关的code
SqlConnection conn = new SqlConnection(connectionString);
conn.Open();
SqlTransaction tran = conn.BeginTransaction();
string sql1 = “Update Lock1 SET C1=C1+1”;
string sql2 = “SELECT * FROM Lock1”;
ExecuteNonQuery(tran, sql1); //使用事务:事务中Lock了Table
ExecuteNonQuery(null, sql2); //新开一个connection来读取Table
public static void ExecuteNonQuery(SqlTransaction tran, string sql)
{
SqlCommand cmd = new SqlCommand(sql);
if (tran != null)
{
cmd.Connection = tran.Connection;
cmd.Transaction = tran;
cmd.ExecuteNonQuery();
}
else
{
using (SqlConnection conn = new SqlConnection(connectionString))
{
conn.Open();
cmd.Connection = conn;
cmd.ExecuteNonQuery();
}
}
}
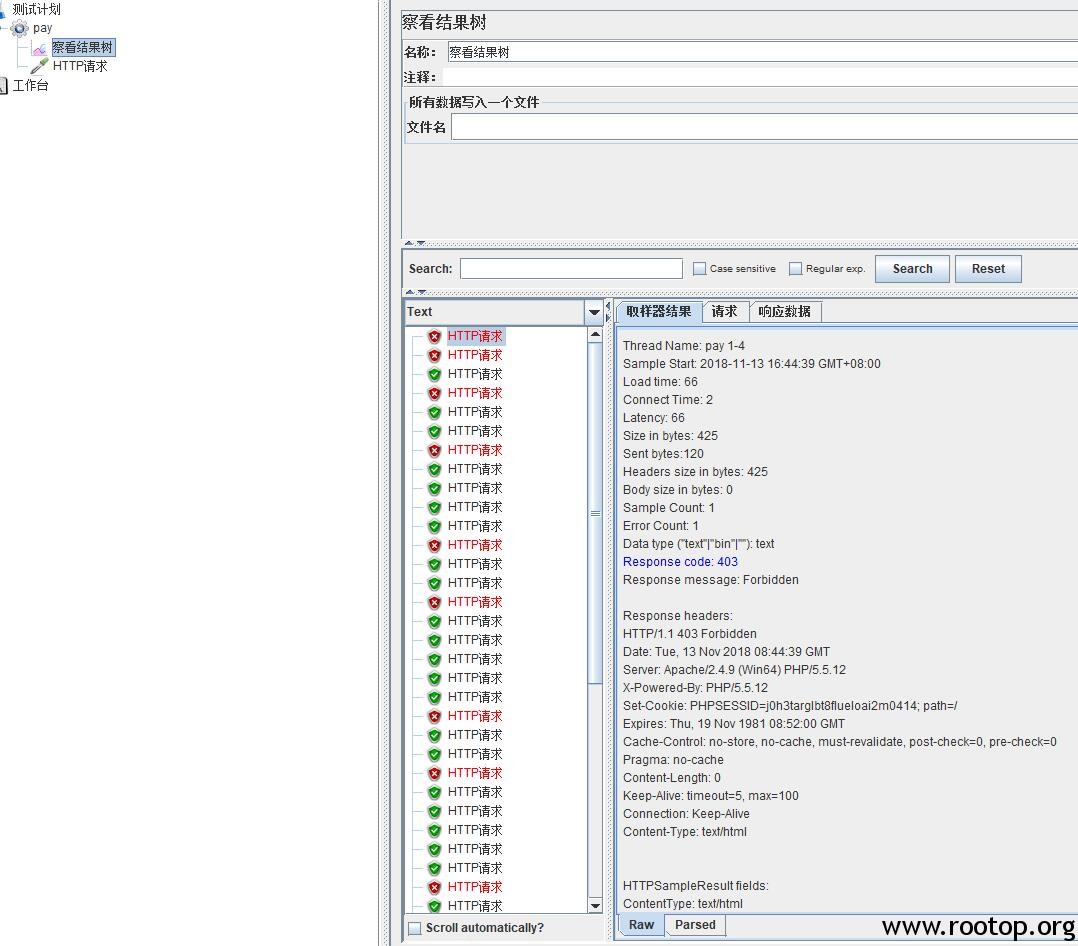
执行到ExecuteNonQuery(null, sql2)时抛出SQL执行超时的异常,下图从数据库的角度来看该问题:
代码从上往下执行,会话1持有了表Lock1的X锁,且事务没有结束,回话1就一直持有X锁不释放;而会话2执行select操作,请求在表Lock1上加S锁,但S锁与X锁是不兼容的,所以回话2的被阻塞等待,不在等待中,就在等待中获得资源,就在等待中超时。。。从中我们可以看到,里面并没有出现死锁,而只是SELECT操作被阻塞了。也正因为不是数据库死锁,所以SQL Server的锁监视器无法检测到死锁。
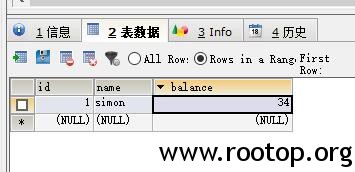
我们再从C#程序的角度来看该问题:
C#程序持有了表Lock1上的X锁,同时开了另一个SqlConnection还想在该表上请求一把S锁,图中已经构成了环路;太贪心了,结果自己把自己给锁死了。。。
虽然这不是一个数据库死锁,但却是因为数据库资源而导致的死锁,上例中提到的解决死锁的方法在这里也基本适用,主要是避免读操作被阻塞,解决方法如下:
a). 把SELECT放在Update语句前:SELECT不在事务中,且执行完毕会释放S锁;
b). 把SELECT也放加入到事务中:ExecuteNonQuery(tran, sql2);
c). SELECT加With(NOLock)提示:可能产生脏读;
d). 降低事务隔离级别:SELECT语句前加SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;同上,可能产生脏读;
e). 使用基于行版本控制的隔离级别(同上例)。
g). 使用绑定连接:取得事务所在会话的token,然后传入新开的connection中;执行EXEC sp_bindsession @Token后绑定了连接,最后执行exec sp_bindsession null;来取消绑定;最后需要注意的四点是:
(1). 使用了绑定连接的多个connection共享同一个事务和相同的锁,但各自保留自己的事务隔离级别;
(2). 如果在sql3字符串的“exec sp_bindsession null”换成“commit tran”或者“rollback tran”,则会提交整个事务,最后一行C#代码tran.Commit()就可以不用执行了(执行会报错,因为事务已经结束了-,-)。
(3). 开启事务(begin tran)后,才可以调用exec sp_getbindtoken @Token out来取得Token;如果不想再新开的connection中结束掉原有的事务,则在这个connection close之前,必须执行“exec sp_bindsession null”来取消绑定连接,或者在新开的connectoin close之前先结束掉事务(commit/tran)。
(4). (Sql server 2005 联机丛书)后续版本的 Microsoft SQL Server 将删除该功能。请避免在新的开发工作中使用该功能,并着手修改当前还在使用该功能的应用程序。 请改用多个活动结果集 (MARS) 或分布式事务。
tran = connection.BeginTransaction();
string sql1 = “Update Lock1 SET C1=C1+1″;
ExecuteNonQuery(tran, sql1); //使用事务:事务中Lock了测试表Lock1
string sql2 = @”DECLARE @Token varchar(255);
exec sp_getbindtoken @Token out;
SELECT @Token;”;
string token = ExecuteScalar(tran, sql2).ToString();
string sql3 = “EXEC sp_bindsession @Token;Update Lock1 SET C1=C1+1;exec sp_bindsession null;”;
SqlParameter parameter = new SqlParameter(“@Token”, SqlDbType.VarChar);
parameter.Value = token;
ExecuteNonQuery(null, sql3, parameter); //新开一个connection来操作测试表Lock1
tran.Commit();
附:锁兼容性(FROM SQL Server 2005 联机丛书)
锁兼容性控制多个事务能否同时获取同一资源上的锁。如果资源已被另一事务锁定,则仅当请求锁的模式与现有锁的模式相兼容时,才会授予新的锁请求。如果请求锁的模式与现有锁的模式不兼容,则请求新锁的事务将等待释放现有锁或等待锁超时间隔过期。

 Redis启动完成
Redis启动完成