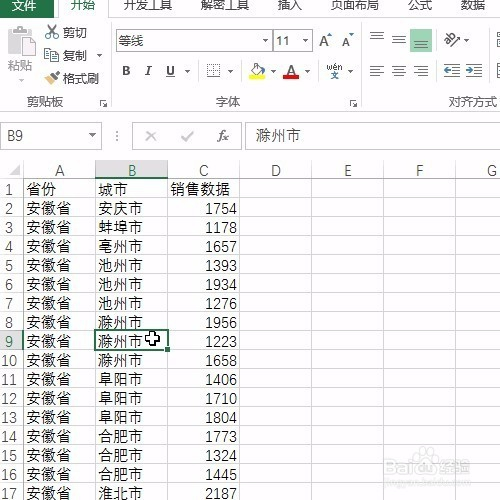
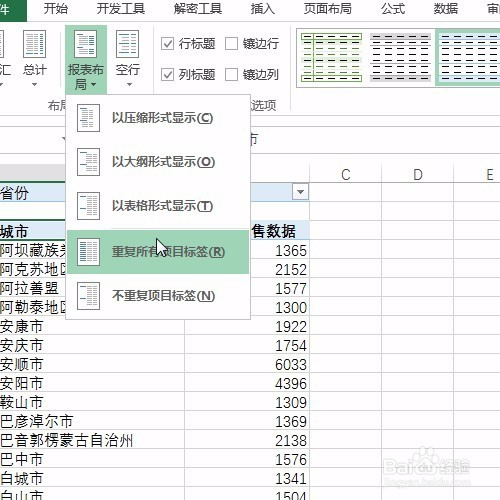
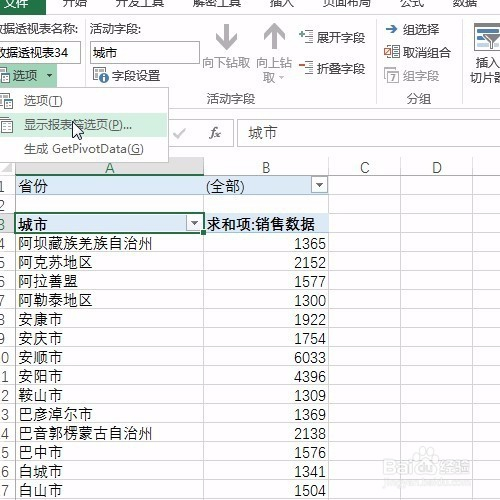
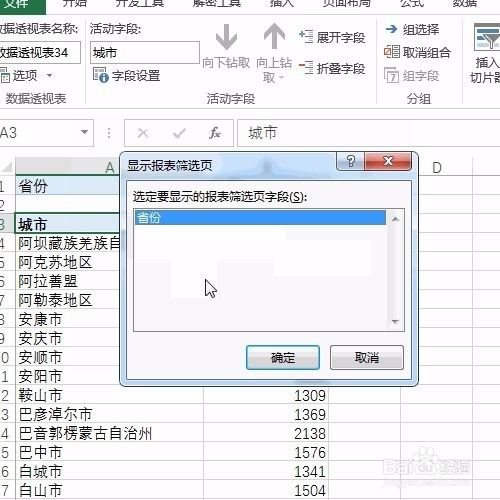
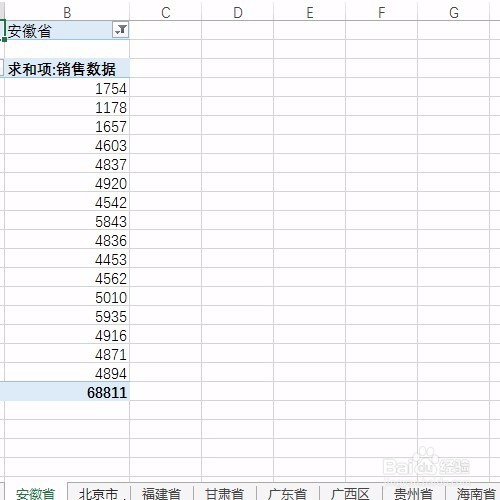
来源: MongoDB 查询$关键字 $in $or $all – minger_lcm – 博客园
属于:$in 满足其中一个元素的数据 把age=13,73 的数据显示
> db.user.find({age: { $in:[13,73]}})
{ "_id" : ObjectId("5ca7a4b0219efd687462f965"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 13, "hobby" : [ "羽毛球", "篮球", "足球" ] }
只要满足$in [] 里面的元素 都可以查询出来
> db.user.find({hobby:{$in:["足球","篮球"] } })
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 34, "hobby" : [ "羽毛球", "篮球", "足球" ] }
> db.user.find({hobby:{$in:["羽毛球"] } })
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 34, "hobby" : [ "羽毛球", "篮球", "足球" ] }
或者:$or 满足其中一个字段的元素数据
OR条件:
MongoDB的OR条件语句使用了操作符$or。如:> db.collection_name.find({$or: [{key1: value1}, {key2: value2}]})
查询 name="mike" 或者 name ="jack",两个条件其中一个条件成立,都返回数据
> db.user.find({$or:[{name:"mike"},{name:"jack"}]} )
{ "_id" : ObjectId("5ca7a4b0219efd687462f965"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("5ca7a4b7219efd687462f966"), "id" : 2, "name" : "mike", "age" : 84, "gender" : "男" }
$all: 满足所有元素的数据 符合列表里面元素条件就可以 显示数据

> db.user.find({hobby:{$all:["足球"] } })
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 34, "hobby" : [ "羽毛球", "篮球", "足球" ] }
> db.user.find({hobby:{$all:["足球","羽毛球"] } })
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 34, "hobby" : [ "羽毛球", "篮球", "足球" ] }
> db.user.find({hobby:{$all:["足球","桌球"] } })
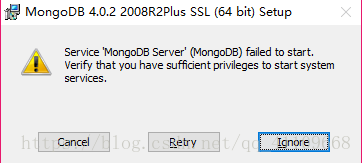
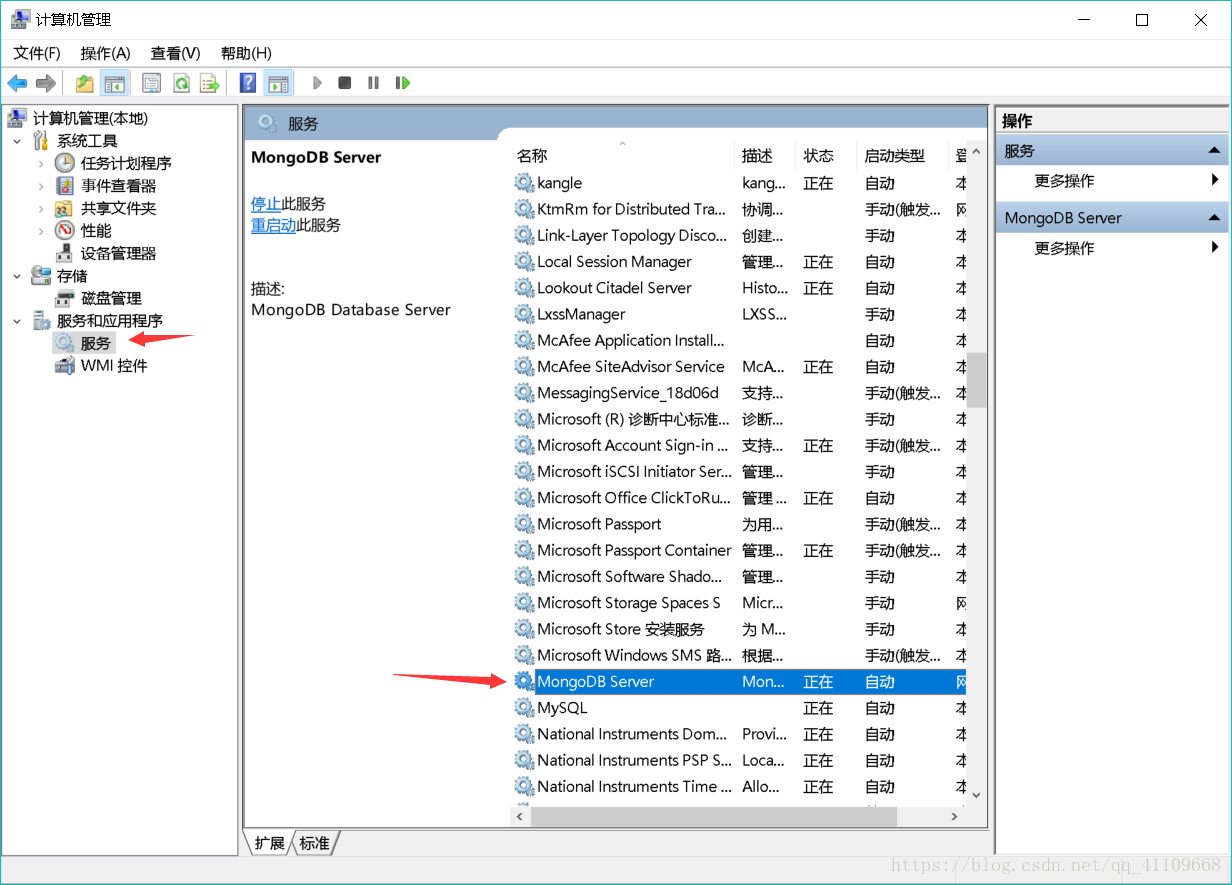
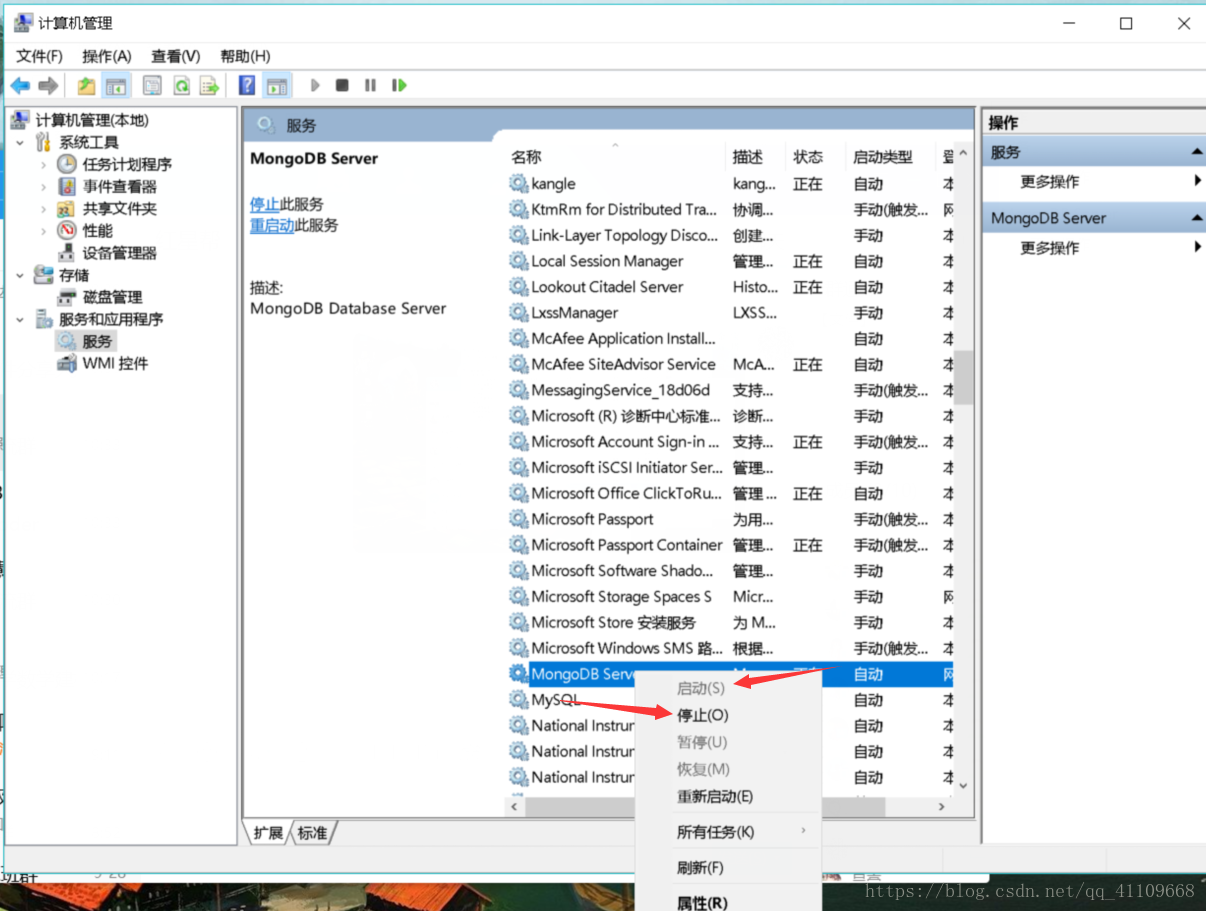
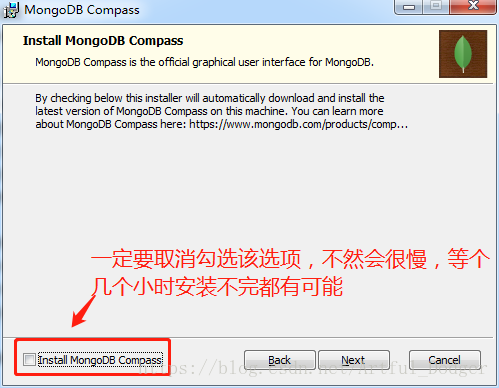
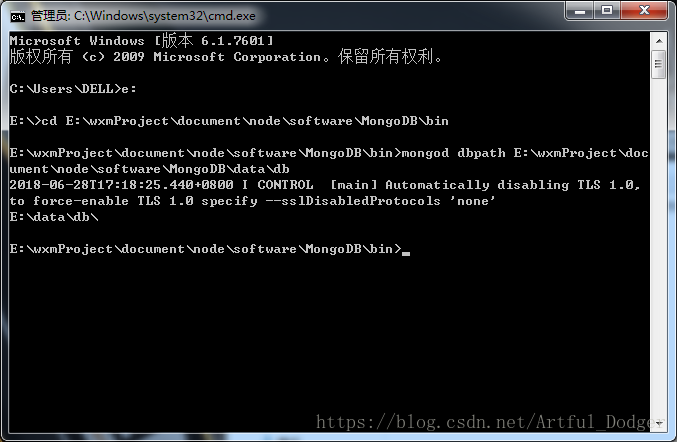
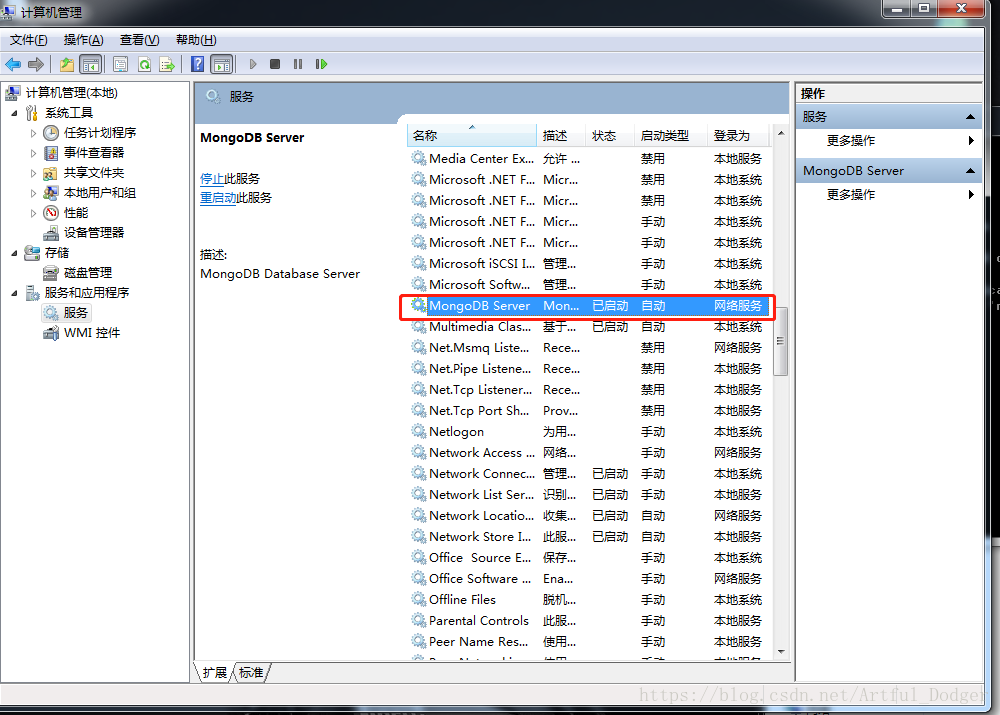
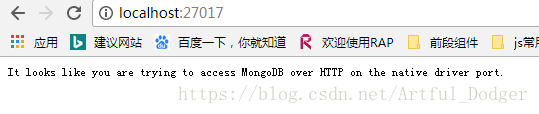
 运行该守护程序需安装Windows服务,点击批处理文档“安装.bat”即可,“安装.bat”具体内容如下:
运行该守护程序需安装Windows服务,点击批处理文档“安装.bat”即可,“安装.bat”具体内容如下: