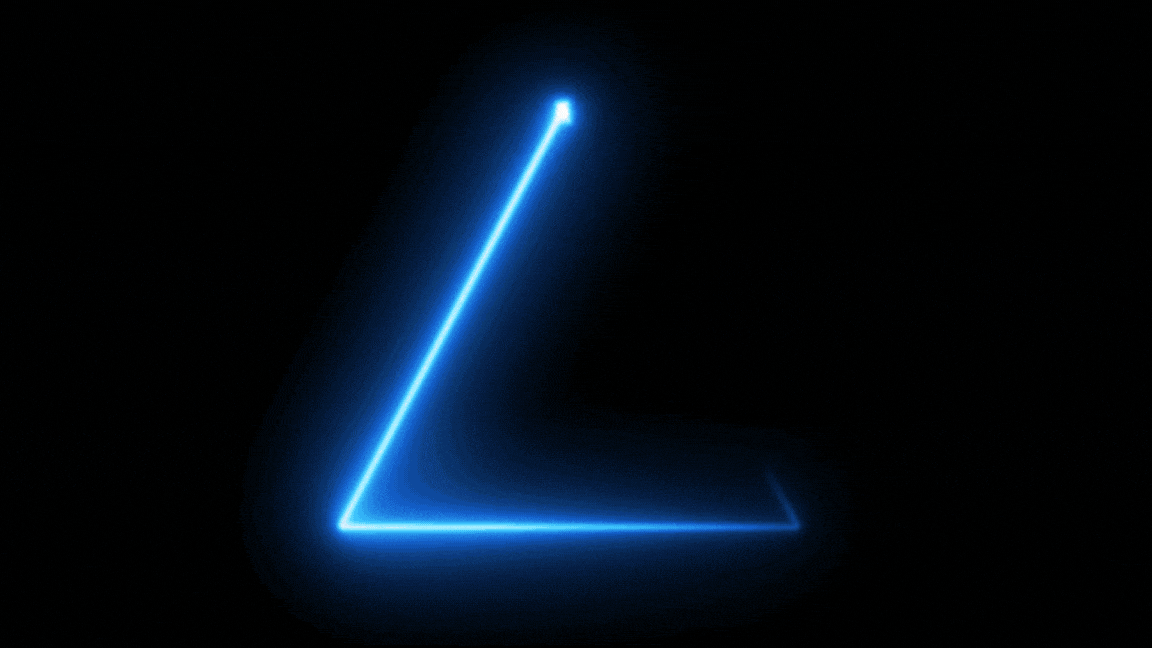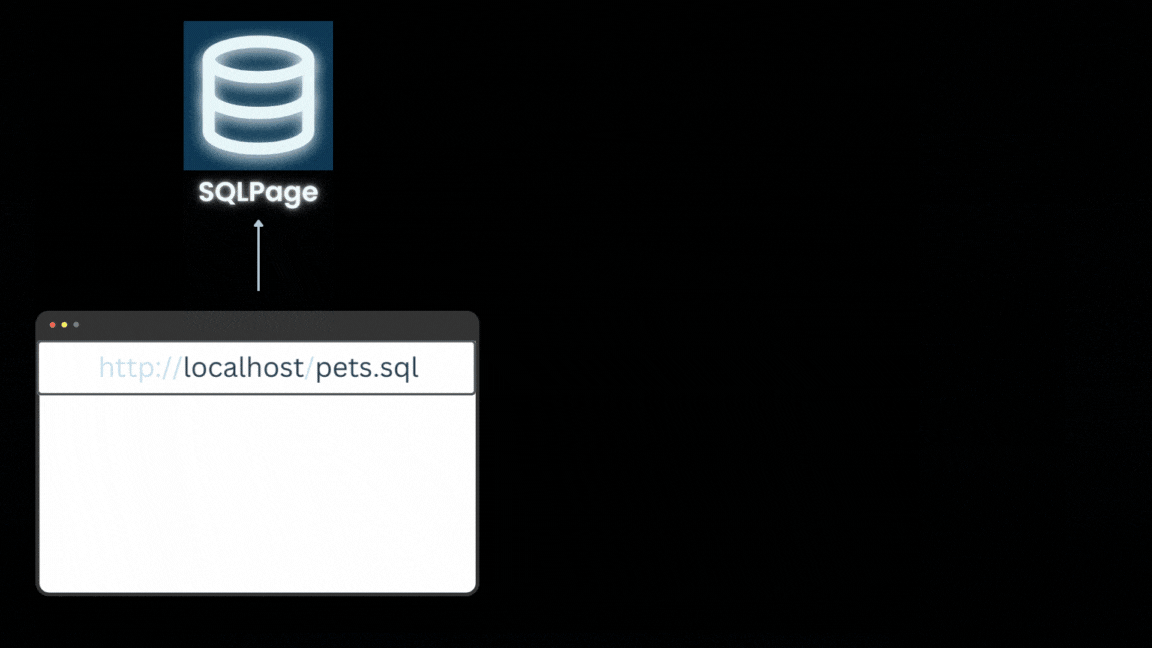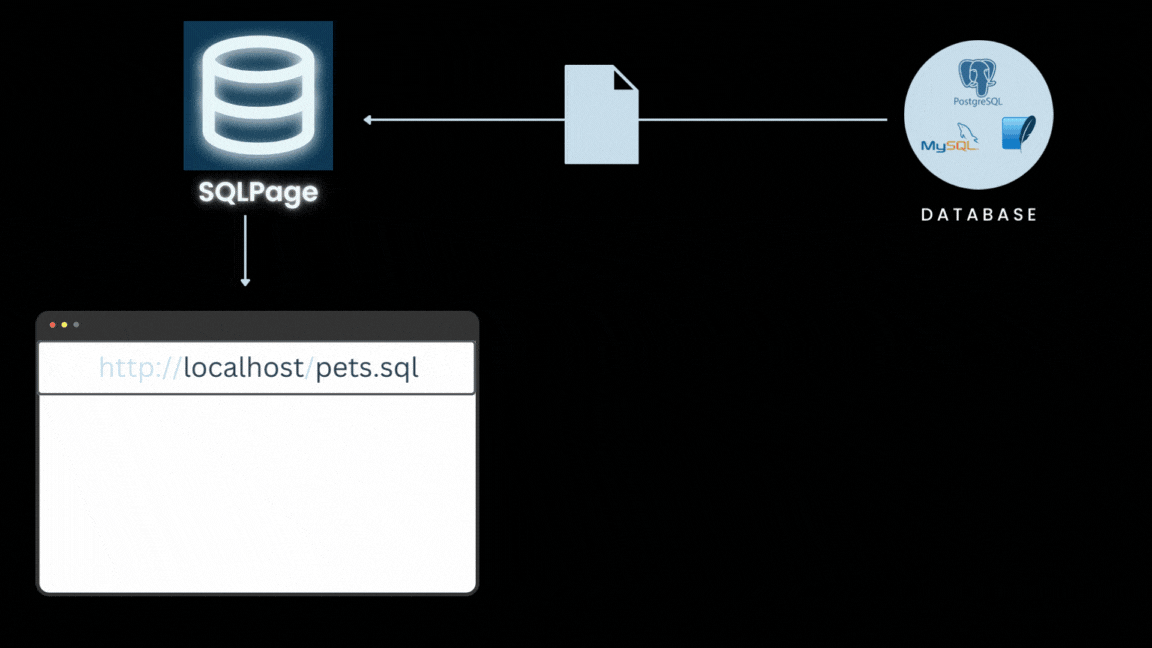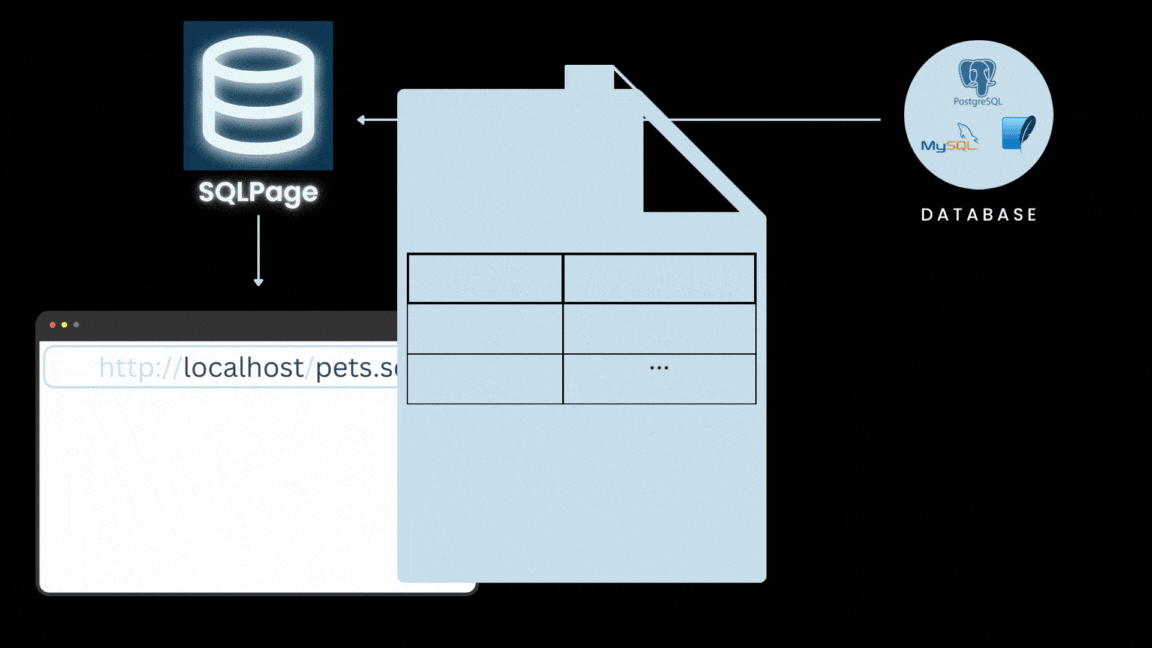string url = "https://www.cnblogs.com/cplemom/?id=15&data={'id':12,'name':'今天天气不错'}";
var uri = new Uri(url);
var collection= HttpUtility.ParseQueryString(uri.Query);//默认采用UTF-8编码,当然也可以传入特定编码进行解析//var collection= HttpUtility.ParseQueryString(uri.Query,Encoding.ASCII);
Console.WriteLine(collection["data"]);//输出结果: {'id':12,'name':'今天天气不错'}
该方法有几个要注意的点
uri.Query是?开头的,但是在转为键值对以后被自动过滤掉了,且只会过滤一个?字符
参数内容会自动使用UTF-8解码
对于传递的数组参数(?ids=1&ids=2),会通过,拼接
在参数字符中通过&划分后,只会把第一个=前的字符串作为key
基于上述一些要求就可以自己写一个解析参数的方式了。
publicstatic Dictionary<string, string> ParseQueryString(string url)
{
if (string.IsNullOrWhiteSpace(url))
{
thrownew ArgumentNullException("url");
}
var uri = new Uri(url);
if (string.IsNullOrWhiteSpace(uri.Query))
{
returnnew Dictionary<string, string>();
}
//1.去除第一个前导?字符var dic = uri.Query.Substring(1)
//2.通过&划分各个参数
.Split(newchar[] { '&' }, StringSplitOptions.RemoveEmptyEntries)
//3.通过=划分参数key和value,且保证只分割第一个=字符
.Select(param => param.Split(newchar[] { '=' }, 2, StringSplitOptions.RemoveEmptyEntries))
//4.通过相同的参数key进行分组
.GroupBy(part => part[0], part => part.Length > 1 ? part[1] : string.Empty)
//5.将相同key的value以,拼接
.ToDictionary(group => group.Key, group => string.Join(",", group));
return dic;
}
# start the video stream threadprint("[INFO] starting video stream thread...")vs = VideoStream(src=args["webcam"]).start()time.sleep(1.0)# loop over frames from the video streamwhile True: # grab the frame from the threaded video file stream, resize # it, and convert it to grayscale # channels) frame = vs.read() frame = imutils.resize(frame, width=450) gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # detect faces in the grayscale frame rects = detector(gray, 0)
实例化 VideoStream。
暂停一秒钟,让相机传感器预热。
开始遍历视频流中的帧。
读取下一帧,然后我们通过将其大小调整为 450 像素的宽度并将其转换为灰度进行预处理。
应用 dlib 的人脸检测器来查找和定位图像中的人脸。
下一步是应用面部标志检测来定位面部的每个重要区域:
plaintext
1234567891011121314151617181920212223242526272829
# loop over the face detectionsfor rect in rects: # determine the facial landmarks for the face region, then # convert the facial landmark (x, y)-coordinates to a NumPy # array shape = predictor(gray, rect) shape = face_utils.shape_to_np(shape) # extract the left and right eye coordinates, then use the # coordinates to compute the eye aspect ratio for both eyes leftEye = shape[lStart:lEnd] rightEye = shape[rStart:rEnd] leftEAR = eye_aspect_ratio(leftEye) rightEAR = eye_aspect_ratio(rightEye) # average the eye aspect ratio together for both eyes ear = (leftEAR + rightEAR) / 2.0
循环遍历检测到的每个人脸——在我们的实现中(特别与司机睡意有关),我们假设只有一张脸——司机——但我把这个 for 循环留在这里以防万一你想应用多张脸视频的技术。
# check to see if the eye aspect ratio is below the blink# threshold, and if so, increment the blink frame counterif ear < EYE_AR_THRESH: COUNTER += 1 # if the eyes were closed for a sufficient number of # then sound the alarm if COUNTER >= EYE_AR_CONSEC_FRAMES: # if the alarm is not on, turn it on if not ALARM_ON: ALARM_ON = True # check to see if an alarm file was supplied, # and if so, start a thread to have the alarm # sound played in the background if args["alarm"] != "": t = Thread(target=sound_alarm, args=(args["alarm"],)) t.deamon = True t.start() # draw an alarm on the frame frame=cv2ImgAddText(frame,"醒醒,别睡!",10,30,(255, 0, 0),30)# otherwise, the eye aspect ratio is not below the blink# threshold, so reset the counter and alarmelse: COUNTER = 0 ALARM_ON = False
[1]刘淇缘,卢树华,兰凌强.遮挡人脸检测方法研究进展[J].计算机工程与应用.2020,(13).33-46.DOI:10.3778/j.issn.1002-8331.2003-0142.
[2]蒋纪威,何明祥,孙凯.基于改进YOLOv3的人脸实时检测方法[J].计算机应用与软件.2020,(5).200-204.DOI:10.3969/j.issn.1000-386x.2020.05.035.
[3]张文超,山世光,张洪明,等.基于局部Gabor变化直方图序列的人脸描述与识别[J].软件学报.2006,(12).2508-2517.
[4]王蕴红,朱勇,谭铁牛.基于虹膜识别的身份鉴别[J].自动化学报.2002,(1).1-10.
[5]梁路宏,艾海舟,徐光档,等.人脸检测研究综述[J].计算机学报.2002,(5).449-458.
[6]尹义龙,宁新宝,张晓梅.自动指纹识别技术的发展与应用[J].南京大学学报(自然科学版).2002,(1).29-35.
[7]孙冬梅,裘正定.生物特征识别技术综述[J].电子学报.2001,(z1).1744-1748.
[8]卢春雨,张长水,闻芳,等.基于区域特征的快速人脸检测法[J].清华大学学报(自然科学版).1999,(1).101-105.
[9]梁路宏,艾海舟,何克忠.基于多模板匹配的单人脸检测[J].中国图象图形学报.1999,(10).825-830.
[10]孙晓玲.人脸识别系统中眼睛定位方法的研究[D].2008
[11]山世光.人脸识别中若干关键问题的研究[D].2004
[12]刘伟强.基于级联卷积神经网络的人脸检测算法的研究[D].2017
[13]Li Liu,Wanli Ouyang,Xiaogang Wang,等.Deep Learning for Generic Object Detection: A Survey[J].International Journal of Computer Vision.2020,128(2).261-318.DOI:10.1007/s11263-019-01247-4.
[14]Lin, Tsung-Yi,Goyal, Priya,Girshick, Ross,等.Focal Loss for Dense Object Detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence.2020,42(2).318-327.DOI:10.1109/TPAMI.2018.2858826.
[15]Yang, Shuo,Luo, Ping,Loy, Chen Change,等.Faceness-Net: Face Detection through Deep Facial Part Responses.[J].IEEE Transactions on Pattern Analysis & Machine Intelligence.2018,40(8).1845-1859.
[16]Xiang,Zhang,Wei,Yang,Xiaolin,Tang,等.A Fast Learning Method for Accurate and Robust Lane Detection Using Two-Stage Feature Extraction with YOLO v3.[J].Sensors (Basel, Switzerland).2018,18(12).DOI:10.3390/s18124308.
[17]Kaipeng Zhang,Zhanpeng Zhang,Zhifeng Li,等.Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J].IEEE signal processing letters.2016,(10).1499-1503.
[18]LeCun, Yann,Bengio, Yoshua,Hinton, Geoffrey.Deep learning[J].Nature.2015,521(May 28 TN.7553).436-444.DOI:10.1038/nature14539.
[19]Xuelong Li,Jing Pan,Yuan Yuan,等.Efficient HOG human detection[J].Signal Processing: The Official Publication of the European Association for Signal Processing.2011,91(4).
[20]Viola P,Jones MJ.Robust real-time face detection[J].International Journal of Computer Vision.2004,57(2).
[21]Giles C.L.,Lawrence S..Face recognition: a convolutional neural-network approach[J].IEEE Transactions on Neural Networks.1997,8(1).
[22]C. Lawrence Zitnick,Piotr Dollar.Edge Boxes: Locating Object Proposals from Edges[C].2014
[23]Sun, Yi,Wang, Xiaogang,Tang, Xiaoou.Deep Convolutional Network Cascade for Facial Point Detection[C].2013
[24]Zhou, Erjin,Fan, Haoqiang,Cao, Zhimin,等.Extensive Facial Landmark Localization with Coarse-to-Fine Convolutional Network Cascade[C].2013
[25]Neubeck, A.,Van Gool, L..Efficient Non-Maximum Suppression[C].2006
[26]T.F.Cootes,G.J.Edwards,C.J.Taylor.Active appearance models[C].1998
[27]Guanglu Song,Yu Liu,Ming Jiang,等.Beyond Trade-Off: Accelerate FCN-Based Face Detector with Higher Accuracy[C].
[28]Hao Wang,Yitong Wang,Zheng Zhou,等.CosFace: Large Margin Cosine Loss for Deep Face Recognition[C].
[29]Ranjan, R.,Patel, V.M.,Chellappa, R..A deep pyramid Deformable Part Model for face detection[C].
[30]Kaipeng Zhang,Zhanpeng Zhang,Zhifeng Li,等.Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[C].
[31]Weiyang Liu,Yandong Wen,Zhiding Yu,等.SphereFace: Deep Hypersphere Embedding for Face Recognition[C].
[32]Taigman, Y.,Ming Yang,Ranzato, M.,等.DeepFace: Closing the Gap to Human-Level Performance in Face Verification[C].
[33]Chenchen Zhu,Ran Tao,Khoa Luu,等.Seeing Small Faces from Robust Anchor’s Perspective[C].
[34]Jiangjing Lv,Xiaohu Shao,Junliang Xing,等.A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection[C].
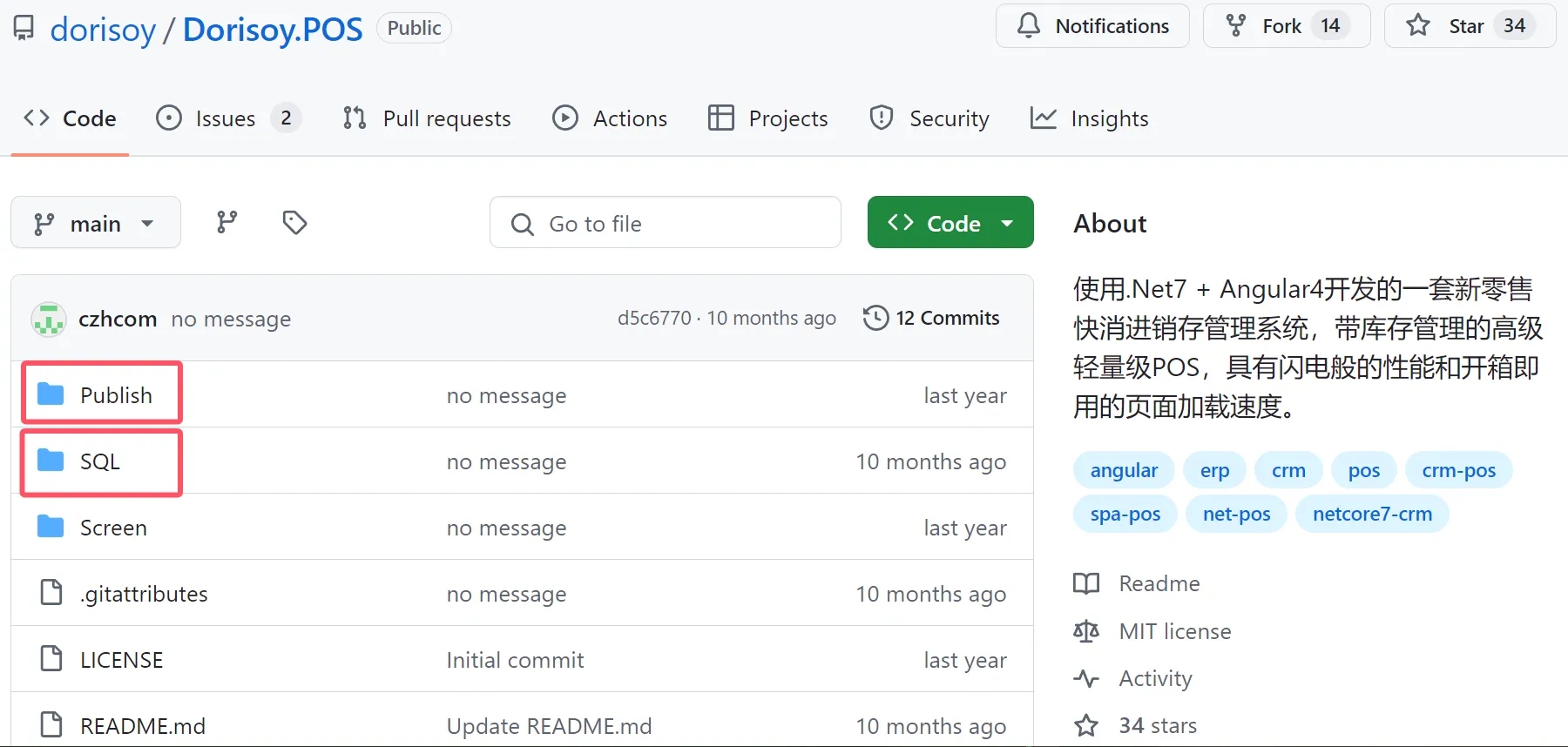
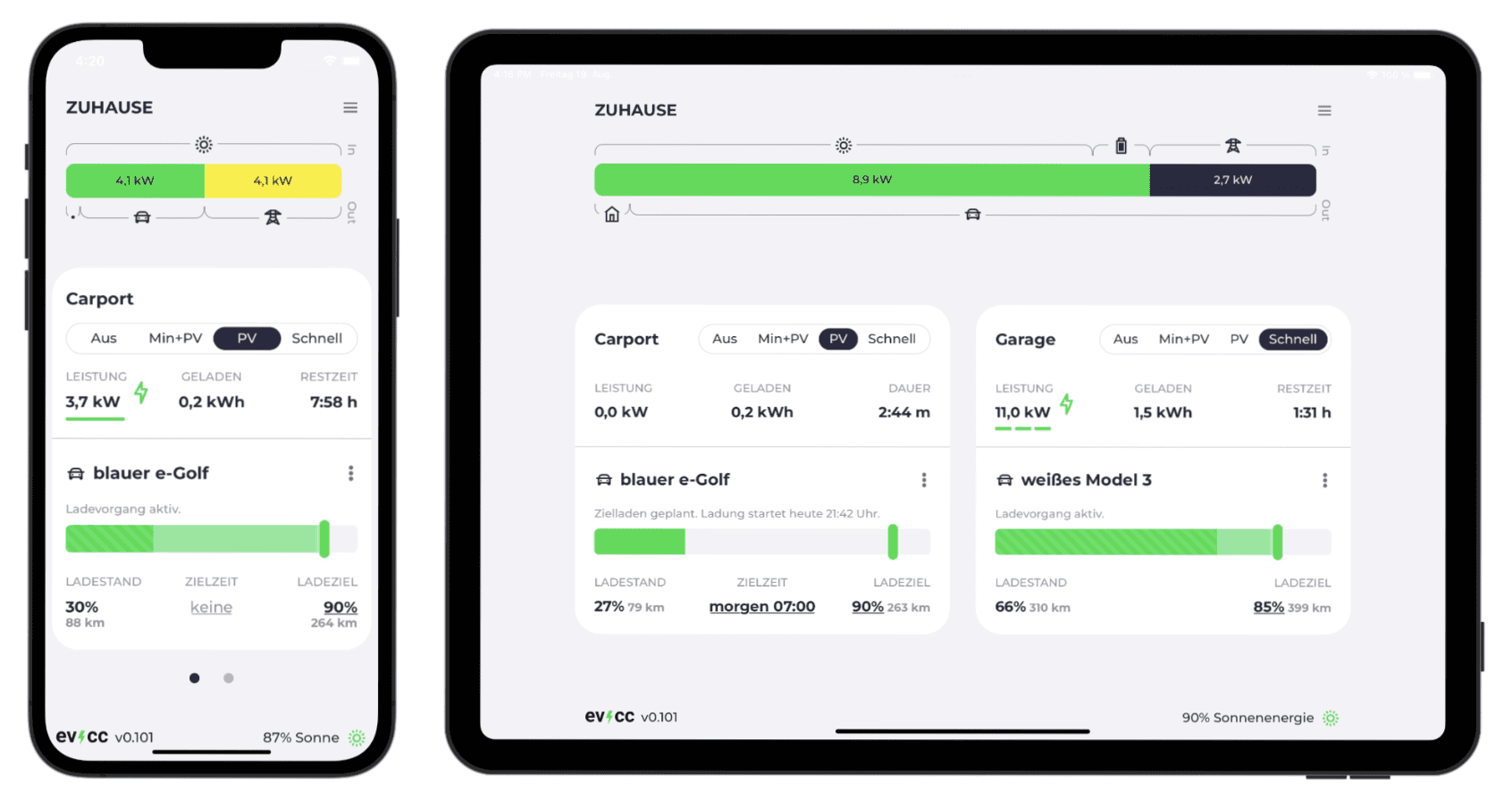
这是一个开源的 EV(电动汽车)充电器控制平台,为电动汽车车主提供灵活且易于安装的充电解决方案。它提供了可视化且适配移动端的 Web 平台,用户可以通过该平台远程启动、停止和监控车辆的充电状态。智能充电功能还可以根据电价、太阳储能和日程安排,智能安排充电时间,从而节约电费。平台支持多种充电设备和车辆型号,为家庭充电桩提供更加智能的控制。