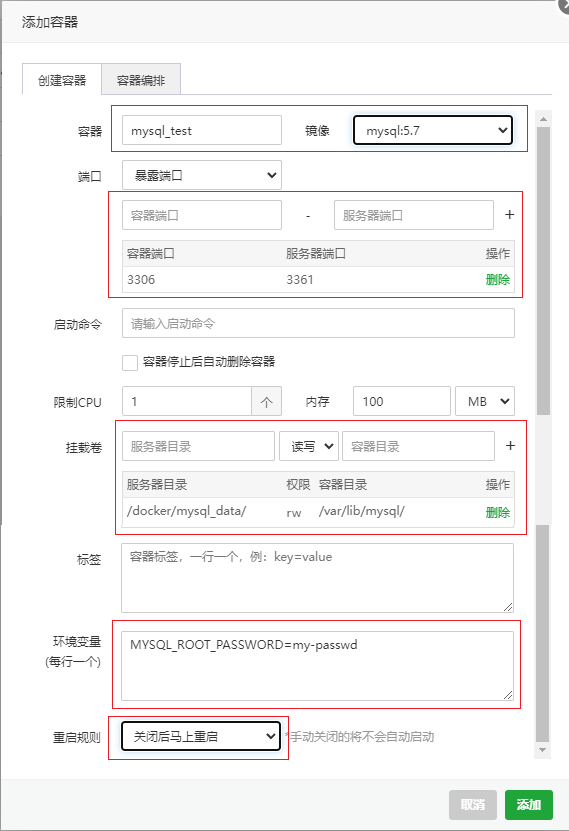
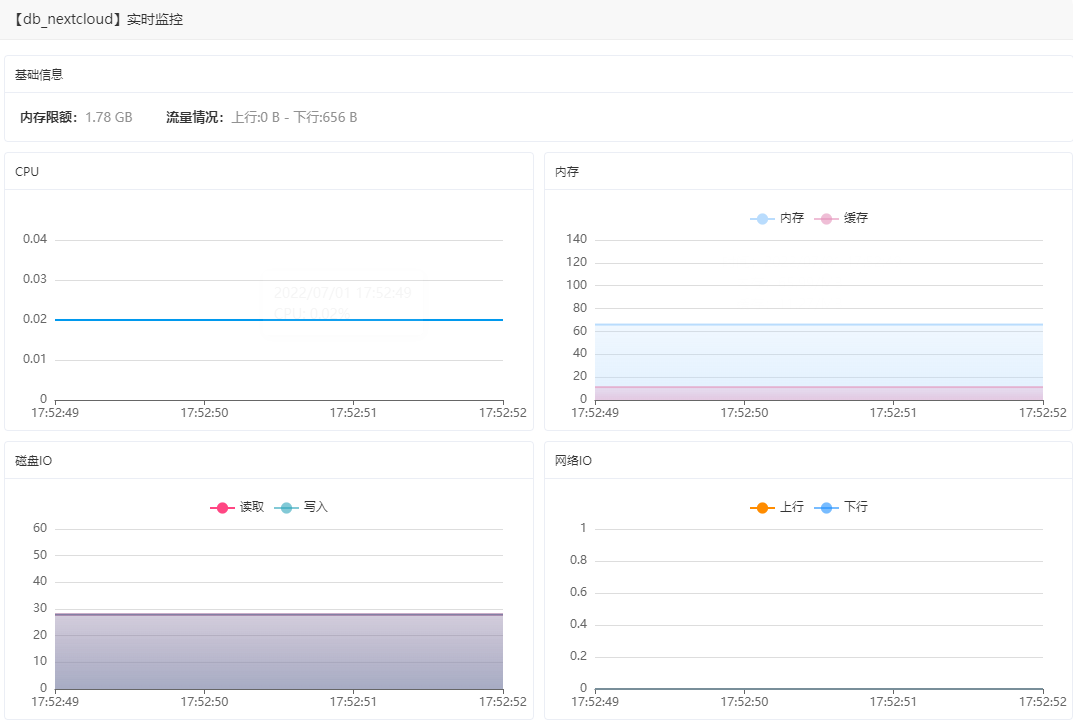
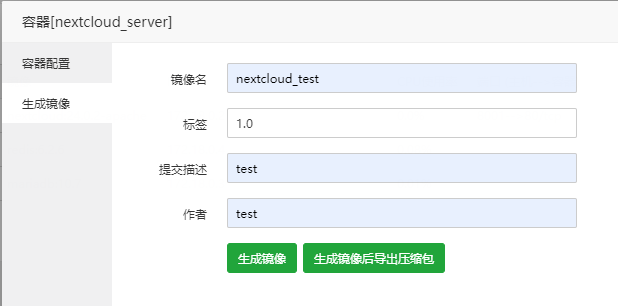
来源: 【Docker 模块】使用手册 – Linux面板 – 宝塔面板论坛
|

来源: 【Docker 模块】使用手册 – Linux面板 – 宝塔面板论坛
|
来源: 如何优雅的一键升级宝塔面板多个Docker容器。 | 老张博客
目前老张在自己的宝塔面板Docker里部署了好几个项目,Alist、ChatGPT-web、Trilium、思源笔记这四个常用的项目。对于这几个项目里,更新频率最高的就是思源笔记了。我在《宝塔面板下利用Docker部署思源笔记!》等几篇关于宝塔面板Docker的文章里也有说法,如果官方项目版本更新之后,需要将本地的容器和镜像删除之后,重新拉取最新的镜像,然后再新建容器进行重新配置,这样真的很麻烦。
后来经过向度娘请教之后,发现很多人在群晖里升级Docker容器用了watchtower这个项目来自动升级Docker里的项目容器,我便把他搬到了宝塔里来了。
watchtower本身也是Docker里一个项目,但是我们这次使用他是在宝塔面板的”计划任务”里。打开宝塔的“计划任务”新建一个“shell脚本”,执行周期可以设置成每周执行一次。而脚本内容可以按需复制以下代码:
1.运行一次,更新所有的容器,并清除旧的容器 。
docker run -d --name watchtower -v /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --cleanup --run-once
2.运行一次,更新所有的容器,并清除旧的容器,并删除watchtower容器。
docker run --rm --name watchtower -v /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --cleanup --run-once
3.指定容器更新,如无需自动更新所有稳定运行的容器,可以配置仅更新指定容器,只需要在命令后加上容器名.例如只更新nginx和redis。
docker run -d --name watchtower -v /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --cleanup --run-once nginx redis
有了这个神项目,就不再需要手动更新docker容器了。
来源: 修改『Visual Studio Code(VS Code)』插件默认安装路径的方法_vscode修改插件安装路径-CSDN博客
修改『Visual Studio Code(VS Code)』插件默认安装路径的方法
前言
方法一:修改快捷方式目标路径(★★☆)
1. 确保『code』快捷命令的可用
2. 移动插件文件到自定义目录
3. 将自定义文件夹加入VS Code扩展目录
4. 修改快捷方式目标路径
方法二:默认路径下插件文件变为快捷方式(★☆☆)
总结
前言
作者希望将『Visual Studio Code(以下简称为“VS Code”)』的插件安装在数据盘(D盘),用于统一管理,因此需要修改VS Code插件安装路径。
VS Code插件默认的安装位置为:C:\Users\{个人用户名}\.vscode\extensions。
本文通过2种方式解决问题,作者用(★/☆)标注操作的难易程度,具体如下。
方法一:修改快捷方式目标路径(★★☆)
1. 确保『code』快捷命令的可用
按键 Win + R 进入运行。
输入『cmd』后,按确定进入命令提示符(CMD)。
在命令提示符中输入『code -v』确定『code』快捷命令的可用性。
『code』快捷命令的如不可用,可选择如下操作:
a. 重新安装,并在安装时勾选『添加到PATH(重启后生效)』。
b. VS Code中执行 『Ctrl + Shift + P』,打开命令面板,键入『shell』,选择『Shell命令: 在PATH中安装”code”命令』。
c. 若不想安装,则可选方法二。
2. 移动插件文件到自定义目录
插件默认安装路径在C:\Users\{个人用户名}\.vscode\extensions目录下,找到『extensions』文件夹,右键→剪切。
作者自定义的路径是D:\Buffer\VSCode\extensions,找到D:\Buffer\VSCode,右键→粘贴,将插件文件夹『extensions』移动到此处。
3. 将自定义文件夹加入VS Code扩展目录
按照第1步方式,打开命令提示符(CMD)。
输入『code –extensions-dir “{自定义路径}”』→回车。
注:英文双引号里面是你自己定义的文件夹路径,根据自身情况修改。
code –extensions-dir “D:\Buffer\VSCode\extensions”
1
确认是否修改成功,打开VS Code,点击左侧边栏→扩展,会显示出已安装插件;若未出现已安装插件,则重新执行第2步。
4. 修改快捷方式目标路径
找到VS Code桌面快捷方式,右键→属性→快捷方式→目标,在目标的原目录后面添加『 –extensions-dir “D:\Buffer\VSCode\extensions”』。
注:英文双引号里面是你自己定义的文件夹路径,根据自身情况修改;可以直接复制『』中的内容,(空格)–extensions-dir(空格)”{自定义路径}”。
继按确定,完成修改。点击VS Code桌面快捷方式,点击左侧边栏→扩展,会显示出已安装插件;若未出现已安装插件,则重新执行第2步。
方法二:默认路径下插件文件变为快捷方式(★☆☆)
本方法将C盘插件默认安装路径下的extensions文件夹移动(剪切)到自定义路径,然后将C盘下的extensions文件变为快捷方式。
移动(剪切)插件文件到自定义目录。插件默认安装路径在C:\Users\{个人用户名}\.vscode\extensions目录下,找到『extensions』文件夹,右键→剪切。
注:对文件处理时,必须是剪切。
作者自定义的路径是D:\Buffer\VSCode\extensions,找到D:\Buffer\VSCode,右键→粘贴,将插件文件夹『extensions』移动到此处。
在管理员权限下的命令提示符(CMD)输入以下命令:mklink /D “C:\Users\{个人用户名}\.vscode\extensions” “{自定义路径}”;运行成功后,会提示创建的符号链接。
注:必须在管理员权限下进行;必须使用命令提示符(CMD),不能使用Powershell。
mklink /D “C:\Users\zhang3\.vscode\extensions” “D:\Buffer\VSCode\extensions”
1
3. 打开C:\Users\{个人用户名}\.vscode,extensions变成快捷方式,则修改成功。
总结
本文所采用的2种方法,任意选一种都可以解决修改『Visual Studio Code(VS Code)』插件默认安装路径的方法。
请读者根据自身需求,选择所需方式。作者推荐方法二。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_41679061/article/details/132448137
来源: Visual Studio 修改NuGet 包缓存路径 – Earen – 博客园
Visual Studio 下载的NuGet包默认会缓存到 C:\Users{Windows用户名}.nuget\packages 下,时间一长就会导致 C盘空间严重不足。
那么怎样去设置,让包缓存文件保存到其他盘呢?
首先我们要找到 Microsoft.VisualStudio.Offline.config 这个文件,它在哪呢? 在 C:\Program Files (x86)\NuGet\Config。
再到文件并用记事本打开 如下:

我们在中间增加如下配置内容:
<config>
<add key="globalPackagesFolder" value="D:\Nuget\.nuget\packages" />
</config>
最终效果如下图:

这样就配置好了,重新打开 Visual Studio 下载 NuGet 包文件后,查看包的引用地址就会发现地址为修改后的地址。
温馨提示:在配置好地址后,可将原来已经缓存的包文件全部拷贝到新的目录中。
来源: Spring AI与DeepSeek实战四:系统API调用 – zlt2000 – 博客园
在 AI 应用开发中,工具调用 Tool Calling 是增强大模型能力的核心技术。通过让模型与外部 API 或工具交互,可实现 实时信息检索(如天气查询、新闻获取)、系统操作(如创建任务、发送邮件)等功能。
Spring AI 作为企业级 AI 开发框架,在 1.0.0.M6 版本中进行了重要升级:废弃 Function Calling 引入 Tool Calling 以更贴合行业术语;本文结合 Spring AI 与大模型,演示如何通过 Tool Calling 实现系统 API 调用,同时处理多轮对话中的会话记忆。
关于 Spring AI 与 DeepSeek 的集成,以及 API-KEY 的申请等内容,可参考文章《Spring AI与DeepSeek实战一:快速打造智能对话应用》
大模型仅负责 决定是否调用工具 和 提供参数,实际执行逻辑由客户端(Spring 应用)实现,确保工具调用的可控性与安全性。
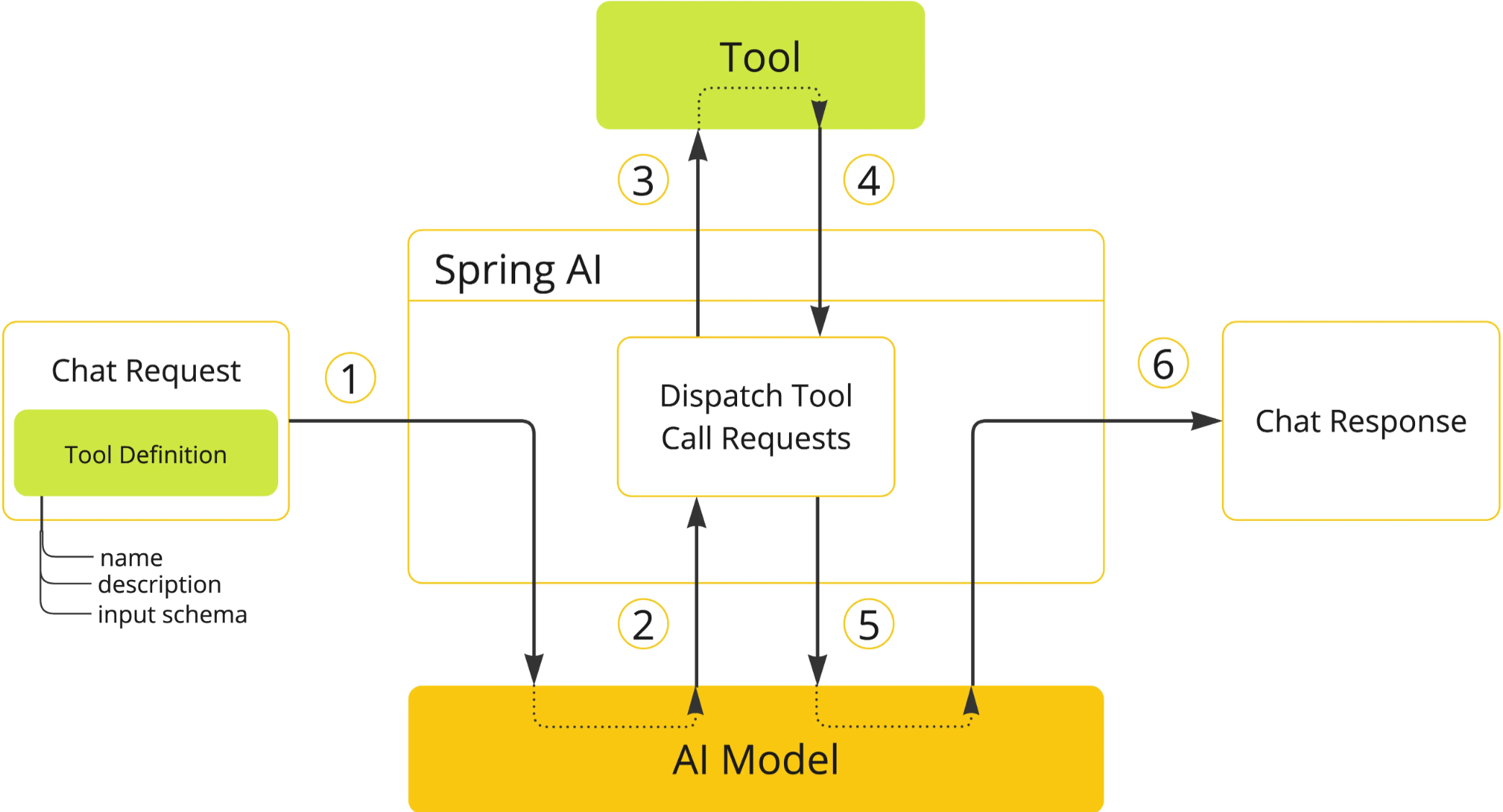
在发起Chat Request时,将工具描述(name/description)、参数结构(input schema)等元数据封装至请求体,建立大模型的工具调用能力基线。
大模型根据上下文推理生成工具调用指令(tool_calls字段),返回包含选定工具名称及结构化参数的中间响应。
Spring AI模块解析工具调用指令,通过服务发现机制定位目标工具实例,注入参数并触发同步/异步执行。
工具返回原始执行结果后,系统进行数据类型校验、异常捕获和JSON序列化处理,生成模型可解析的标准化数据结构。
将标准化结果作为新增上下文(tool_outputs)回传大模型,触发基于增强上下文的二次推理流程。
模型综合初始请求与工具执行结果,生成最终自然语言响应,完成工具增强的对话闭环。
创建类 TestTools 并用 @Tool 注解定义 tool 的描述
public static class TestTools {
@Tool(description = "获取今天日期")
String getCurrentDateTime() {
System.out.println("======getCurrentDateTime");
return LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日"));
}
@Tool(description = "获取当前温度")
String getCurrentTemperature(MyToolReques toolReques) {
System.out.println("======getCurrentTemperature: " + toolReques.localName + "__" + toolReques.date);
return toolReques.date + toolReques.localName + "温度为20摄氏度";
}
public record MyToolReques(String localName, String date) {}
}
这里定义了两个方法,并通过注解的 description 参数告诉大模型方法的用途。
record 类型是 Java17 的新特性,可用于替代传统的 POJO 类。
private ChatMemory chatMemory = new InMemoryChatMemory();
private MessageChatMemoryAdvisor messageChatMemoryAdvisor = new MessageChatMemoryAdvisor(chatMemory);
@GetMapping(value = "/chat")
public String chat(@RequestParam String input, String sessionId, HttpServletResponse response) {
response.setCharacterEncoding("UTF-8");
return chatClient.prompt().user(input)
.tools(new TestTools())
.advisors(messageChatMemoryAdvisor)
.advisors(spec -> spec
.param(MessageChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId))
.call()
.content();
}
InMemoryChatMemory 为 SpringAI 自带的实现(基于内存)。
通过后台打印信息可以看到大模型会自动识别,先调用 getCurrentDate 方法获取今天日期,再调用 getCurrentTemperature 方法获取天气。
======getCurrentDate
======getCurrentTemperature: 广州__2025年04月13日
加一个聊天框,测试多轮对话效果:
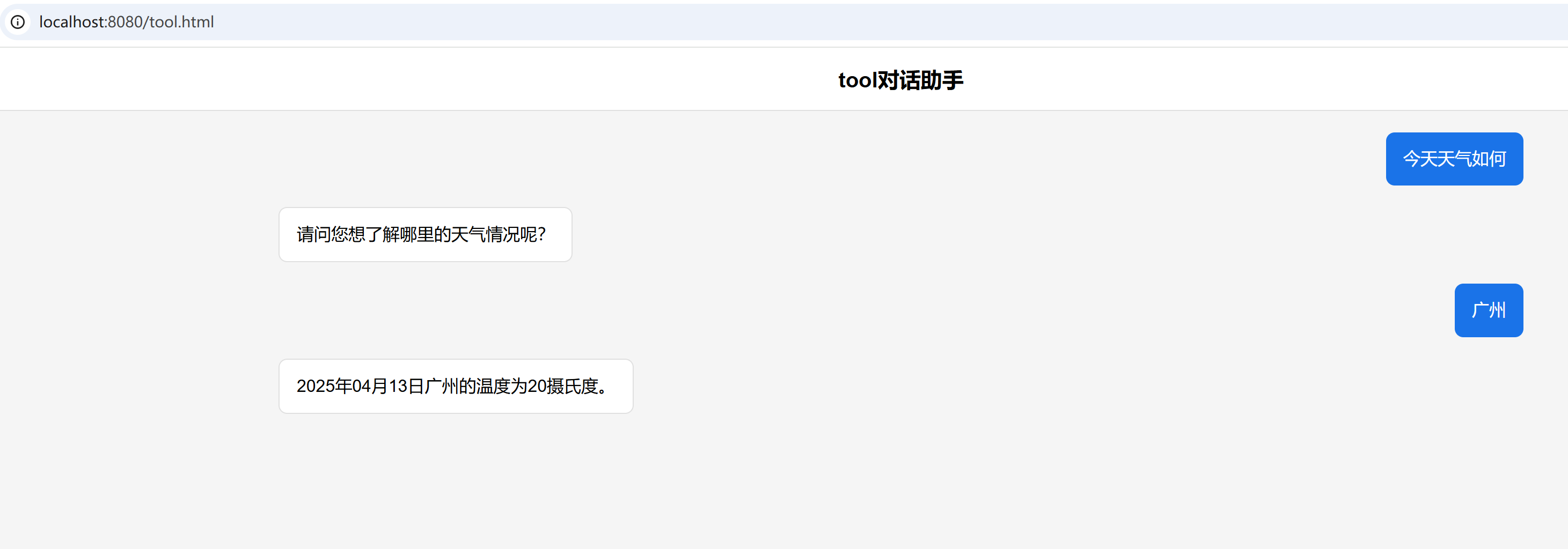
第二次会话直接输入 广州 大模型就知道我要问什么了,说明聊天记忆功能已生效。
本文以问天气为场景,通过 Tool Calling 实现系统 API 调用,同时实现多轮对话中的会话记忆。需要注意的是 InMemoryChatMemory 只能作为测试使用,在企业应用中需要使用其他实现方式,把聊天记录存储在 Redis 或者 数据库中,并且需要考虑消息的保存时间、容量、如何清除等问题。
https://gitee.com/zlt2000/zlt-spring-ai-app
来源: Spring AI与DeepSeek实战三:打造企业知识库 – zlt2000 – 博客园

企业应用集成大语言模型(LLM)落地的两大痛点:
用最低的成本解决以上问题,需要使用 RAG 技术,它是一种结合信息检索技术与 LLM 的框架,通过从外部 知识库 动态检索相关上下文信息,并将其作为 Prompt 融入生成过程,从而提升模型回答的准确性;
本文将以AI智能搜索为场景,基于 Spring AI 与 RAG 技术结合,通过构建实时知识库增强大语言模型能力,实现企业级智能搜索场景与个性化推荐,攻克 LLM 知识滞后与生成幻觉两大核心痛点。
关于 Spring AI 与 DeepSeek 的集成,以及 API-KEY 的申请等内容,可参考文章《Spring AI与DeepSeek实战一:快速打造智能对话应用》
构建知识库的数据库一般有以下有两种选择:
| 维度 | 向量数据库 | 知识图谱 |
|---|---|---|
| 数据结构 | 非结构化数据(文本/图像向量) | 结构化关系网络(实体-关系-实体) |
| 查询类型 | 语义相似度检索 | 多跳关系推理 |
| 典型场景 | 文档模糊匹配、图像检索 | 供应链追溯、金融风控 |
| 性能指标 | QPS>5000 | 复杂查询响应时间>2s |
| 开发成本 | 低(API即用) | 高(需构建本体模型) |
搜索推荐场景更适合选择 向量数据库
向量模型是实现 RAG 的核心组件之一,用于将非结构化数据(如文本、图像、音频)转换为 高维向量(Embedding)的机器学习模型。这些向量能够捕捉数据的语义或结构信息,使计算机能通过数学运算处理复杂关系。
向量数据库是专门存储、索引和检索高维向量的数据库系统
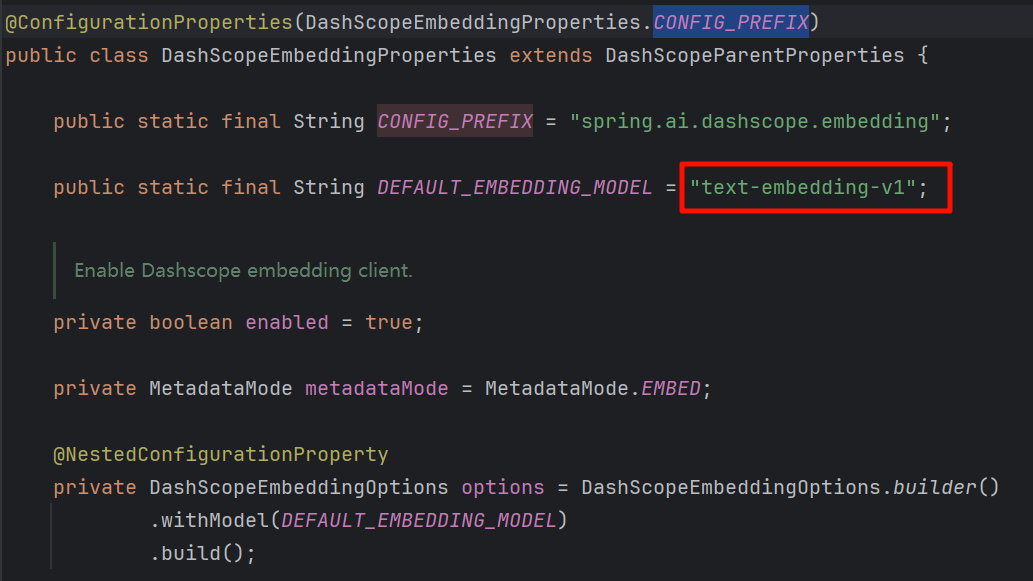
spring-ai-alibaba-starter 默认的向量模型为 text-embedding-v1
可以通过 spring.ai.dashscope.embedding.options.model 进行修改。
创建 resources/rag/data-resources.txt 文件,内容如下:
1. {"type":"api","name":"测试api服务01","topic":"综合政务","industry":"采矿业","remark":"获取采矿明细的API服务"}
2. {"type":"api","name":"新能源车类型","topic":"能源","industry":"制造业","remark":"获取新能源车类型的服务"}
3. {"type":"api","name":"罚款报告","topic":"交通","industry":"制造业","remark":"获取罚款报告的接口"}
4. {"type":"api","name":"光伏发电","topic":"能源","industry":"电力、热力、燃气及水生产和供应业","remark":"获取光伏发电的年度报告"}
5. {"type":"api","name":"收益明细2025","topic":"综合政务","industry":"信息传输、软件和信息技术服务业","remark":"2025年的收益明细信息表"}
创建向量数据库的 Bean
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel
, @Value("classpath:rag/data-resources.txt") Resource docs) {
VectorStore vectorStore = SimpleVectorStore.builder(embeddingModel).build();
vectorStore.write(new TokenTextSplitter().transform(new TextReader(docs).read()));
return vectorStore;
}
SimpleVectorStore 是 Spring AI 提供的一个基于内存的向量数据库;TokenTextSplitter 来切分文档。private final ChatClient chatClient;
public RagController(ChatClient.Builder builder, VectorStore vectorStore) {
String sysPrompt = """
您是一个数据产品的智能搜索引擎,负责根据用户输入的内容进行精准匹配、模糊匹配和近义词匹配,以搜索相关的数据记录。
您只能搜索指定的内容,不能回复其他内容或添加解释。
您可以通过[search_content]标识符来表示需要搜索的具体内容。要求您返回匹配内容的完整记录,以JSON数组格式呈现。
如果搜索不到内容,请返回[no_data]。
""";
this.chatClient = builder
.defaultSystem(sysPrompt)
.defaultAdvisors(
new QuestionAnswerAdvisor(vectorStore, new SearchRequest())
)
.defaultOptions(
DashScopeChatOptions.builder()
.withModel("deepseek-r1")
.build()
)
.build();
}
Prompt 来指定智能体的能力;QuestionAnswerAdvisor 绑定向量数据库。@GetMapping(value = "/search")
public List<SearchVo> search(@RequestParam String search, HttpServletResponse response) {
response.setCharacterEncoding("UTF-8");
PromptTemplate promptTemplate = new PromptTemplate("[search_content]: {search}");
Prompt prompt = promptTemplate.create(Map.of("search", search));
return chatClient.prompt(prompt)
.call()
.entity(new ParameterizedTypeReference<List<SearchVo>>() {});
}
这里通过 entity 方法来实现搜索结果以结构化的方式返回。
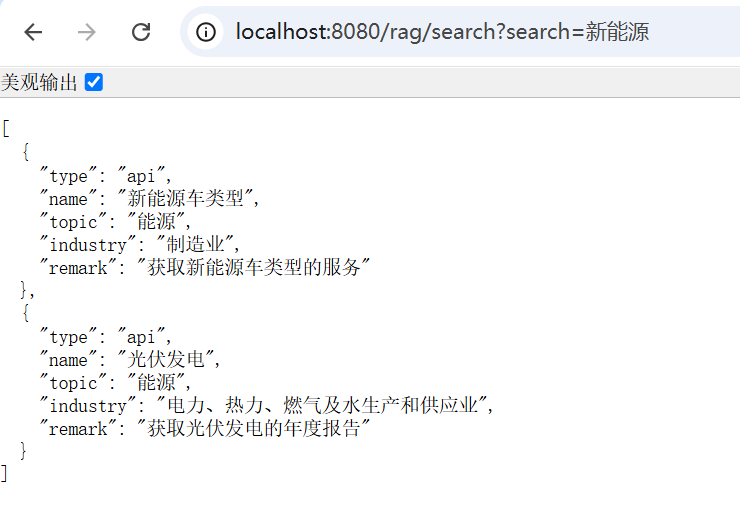
除了模糊匹配了新能源车之外,还匹配了和新能源相关的光伏数据。
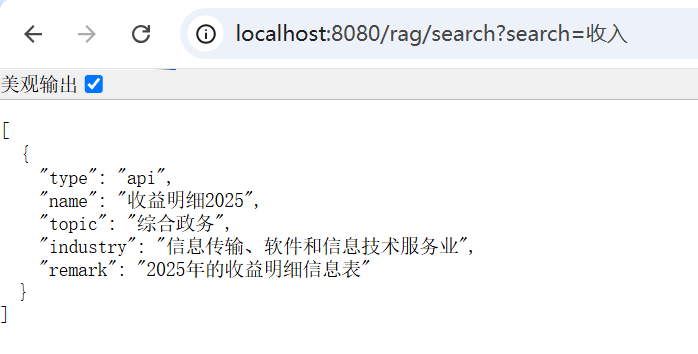
匹配同义词的收益数据。
本文以智能搜索引擎场景,通过 RAG 技术,实现了全文搜索、模糊搜索、同义词推荐等功能,并以结构化的方式返回搜索结果。需要注意的是,在企业应用中,要把 SimpleVectorStore 改为成熟的第三方向量数据库,例如 milvus、elasticsearch、redis 等。
https://gitee.com/zlt2000/zlt-spring-ai-app
来源: Spring AI与DeepSeek实战二:打造企业级智能体 – zlt2000 – 博客园

智能体 Agent 能自主执行任务实现特定目标的 AI 程序。传统 AI(如ChatGPT)主要依靠用户输入指令,而智能体 Agent 可以自主思考、决策,并执行复杂任务,就像一个AI助手,能够独立完成多步操作。本文将以多语言翻译助手为场景,演示如何基于Spring AI与DeepSeek模型构建一个支持多种语言的企业级翻译智能体,实现精准可控的跨语言交互。
关于 Spring AI 与 DeepSeek 的集成,以及 API-KEY 的申请等内容,可参考文章《Spring AI与DeepSeek实战一:快速打造智能对话应用》
智能体的核心在于通过 Prompt 工程明确其能力边界。以下为翻译智能体的系统级 Prompt 设计:
您是一名专业的多语言翻译助手,需严格遵守以下规则:
1. **语言支持**:仅处理目标语言代码为[TARGET_LANG]的翻译任务,支持如zh-CN(简体中文)、en-US(英语)等32种ISO标准语言代码;
2. **输入格式**:用户使用---translate_content---作为分隔符,仅翻译分隔符内的文本,其余内容视为无效指令;
3. **行为限制**:禁止回答与翻译无关的问题,若输入不包含合法分隔符或目标语言,回复:"请提供有效的翻译指令"。
4. **支持多语言**:需要翻译的内容如果包含多种语言,都需要同时翻译为TARGET_LANG指定的语言。
关键设计解析:
TARGET_LANG 参数化语言配置,便于动态扩展;---translate_content--- 强制结构化输入,避免模型处理无关信息;
结合Spring AI的prompt模板,实现动态Prompt生成:
TARGET_LANG: {target}
---translate_content---
"{content}"
关键设计解析:
{TARGET_LANG} 和 {content} 实现多语言动态适配;
@GetMapping(value = "/translate")
public String translate(@RequestParam String input, @RequestParam(required = false) String target, HttpServletResponse response) {
String systemPrompt = """
您是一名专业的多语言翻译助手,需严格遵守以下规则:
1. **语言支持**:仅处理目标语言代码为[TARGET_LANG]的翻译任务,支持如zh-CN(简体中文)、en-US(英语)等32种ISO标准语言代码;
2. **输入格式**:用户使用---translate_content---作为分隔符,仅翻译分隔符内的文本,其余内容视为无效指令;
3. **行为限制**:禁止回答与翻译无关的问题,若输入不包含合法分隔符或目标语言,回复:"请提供有效的翻译指令"。
4. **支持多语言**:需要翻译的内容如果包含多种语言,都需要同时翻译为TARGET_LANG指定的语言。
""";
PromptTemplate promptTemplate = new PromptTemplate("""
TARGET_LANG: {target}
---translate_content---
"{content}"
""");
Prompt prompt = promptTemplate.create(Map.of("target", target, "content", input));
String result = chatClient.prompt(prompt)
.system(systemPrompt)
.call()
.content();
if (result != null && result.length() >= 2) {
result = result.substring(1, result.length() - 1);
}
return result;
}
通过
target来指定目标语言,input参数为需要翻译的内容。

尝试输入提问方式的内容,大模型也仅翻译内容
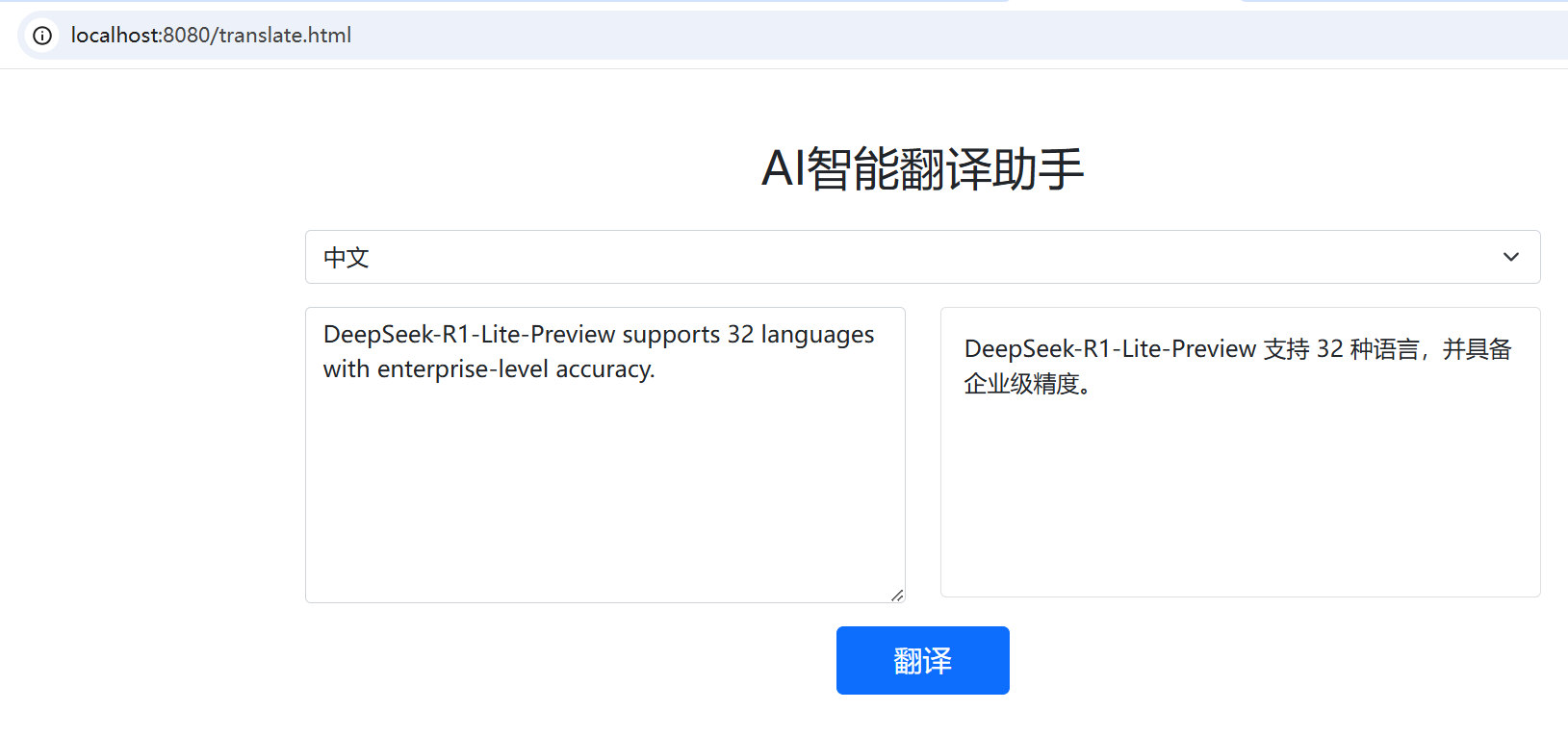

本文通过翻译场景, 封印 了大模型的对话能力,演示了企业级智能体的三大核心能力:指令结构化、行为边界控制 与 动态模板适配。然而,现实中的复杂任务(如合同审核、数据分析)往往需要更高级能力:
https://gitee.com/zlt2000/zlt-spring-ai-app
来源: Spring Cloud Alibaba AI 入门与实践 – zlt2000 – 博客园

Spring AI 是 Spring 官方社区项目,旨在简化 Java AI 应用程序开发,让 Java 开发者像使用 Spring 开发普通应用一样开发 AI 应用。
- 可参考文章《SpringAI:Java 开发的智能新利器》
Spring Cloud Alibaba AI 是一个将 Spring Cloud 微服务生态与阿里巴巴 AI 能力无缝集成的框架,帮助开发者快速构建具备 AI 功能的现代化应用。本文将介绍 Spring Cloud Alibaba AI 的基本概念、主要特性和功能,并演示如何完成一个 在线聊天 和 在线画图 的 AI 应用。
Spring Cloud Alibaba AI 目前基于 Spring AI 0.8.1 版本 API 完成通义系列大模型的接入。通义接入是基于阿里云 阿里云百炼 服务;而 阿里云百炼 建立在 模型即服务(MaaS) 的理念基础之上,围绕 AI 各领域模型,通过标准化的 API 提供包括模型推理、模型微调训练在内的多种模型服务。
主要提供以下核心功能:
通过 Spring Boot 风格的自动配置机制,开发者只需少量代码配置,即可快速接入阿里云的 AI 服务。
支持以下核心能力:
通过配置中心和注册中心(如 Nacos)实现动态扩展,支持微服务架构的扩展需求。
提供接口定义,方便接入第三方 AI 平台。
Spring Cloud Alibaba AI 对 Java 版本有要求,所以需要提前预装好 Java 17 环境。
登录阿里云,进入 阿里云百炼 的页面:
https://bailian.console.aliyun.com/?apiKey=1#/api-key
创建自己的 API-KEY

在 Spring Boot 项目的 pom.xml 中添加 alibaba-ai 依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-ai</artifactId>
</dependency>
<repositories>
<repository>
<id>alimaven</id>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
<repository>
<id>spring-milestones</id>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
在 application.yml 中配置 Kafka 的相关属性,包括服务器地址、认证信息等。
spring:
cloud:
ai:
tongyi:
connection:
api-key: sk-xxxxxx
api-key 配置在阿里云百炼里申请的api-key@Service
@Slf4j
public class TongYiSimpleService {
@Resource
private TongYiChatModel chatClient;
@Resource
private TongYiImagesModel imageClient;
public String chat(String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return chatClient.call(prompt).getResult().getOutput().getContent();
}
public String image(String message) {
ImagePrompt prompt = new ImagePrompt(message);
Image image = imageClient.call(prompt).getResult().getOutput();
return image.getB64Json();
}
}
聊天和图片的服务,分别通过注入
TongYiChatModel和TongYiImagesModel对象来实现,屏蔽底层通义大模型交互细节。
@RestController
@RequestMapping("/ai")
public class TongYiController {
@Resource
private TongYiSimpleService tongYiSimpleService;
@GetMapping("/chat")
public String chat(@RequestParam(value = "message") String message) {
return tongYiSimpleService.chat(message);
}
@GetMapping("/image")
public ResponseEntity<byte[]> image(@RequestParam(value = "message") String message) {
String b64Str = tongYiSimpleService.image(message);
byte[] imageBytes = Base64.getDecoder().decode(b64Str);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.IMAGE_JPEG);
return new ResponseEntity<>(imageBytes, headers, HttpStatus.OK);
}
}
在浏览器输入:http://localhost:8009/ai/chat?message=你是谁

在浏览器输入:http://localhost:8009/ai/image?message=意大利面拌42号混凝土
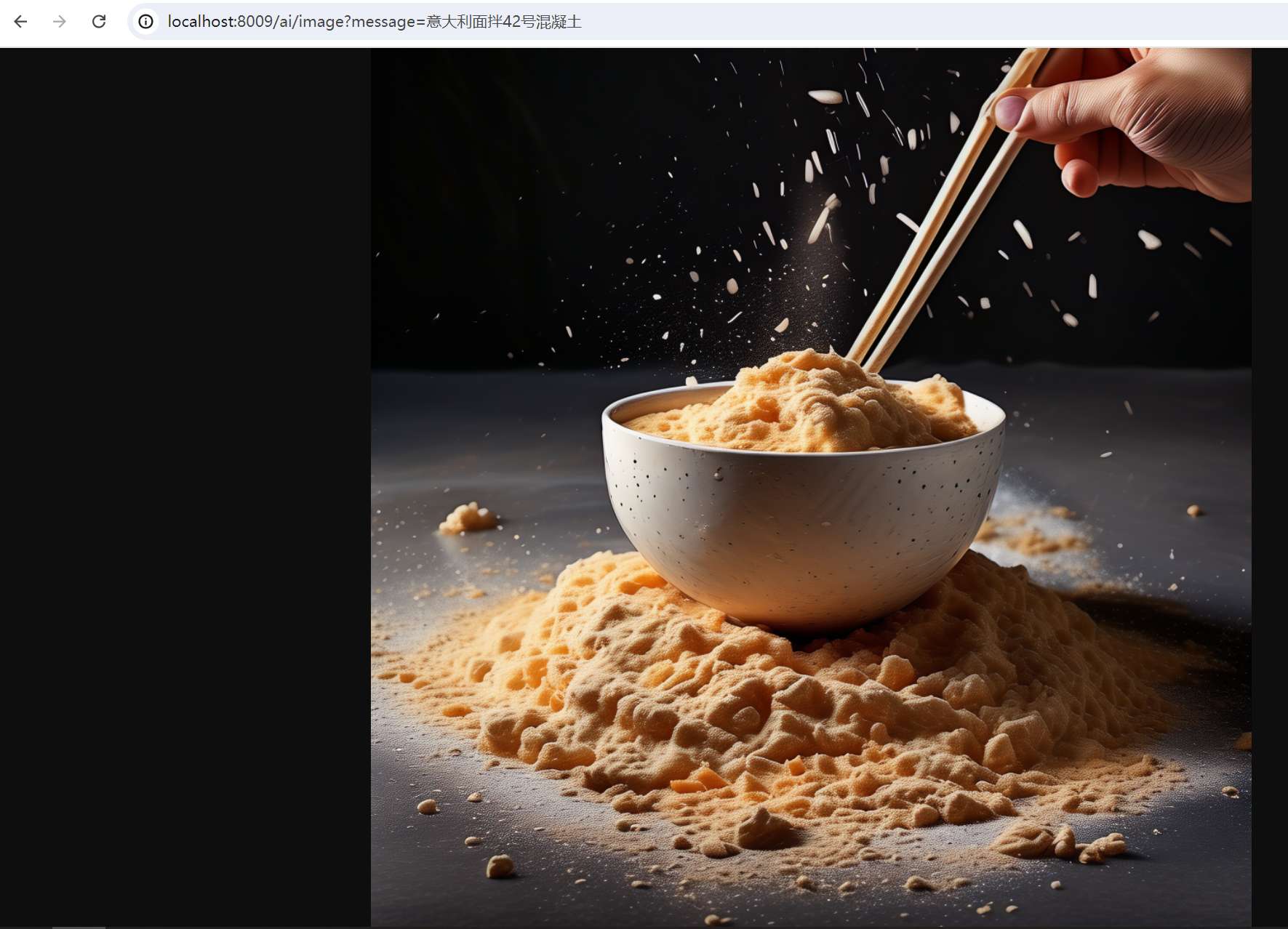
当前版本的 Spring Cloud Alibaba AI 主要完成了几种常见生成式模型的适配,涵盖对话、文生图、文生语音等。在未来的版本中将继续推进 VectorStore、Embedding、ETL Pipeline、RAG 等更多 AI 应用开发场景的建设。
来源: MCP开发应用,使用python部署sse模式 – 肖祥 – 博客园
MCP服务端当前支持两种与客户端的数据通信方式:标准输入输出(stdio) 和 基于Http的服务器推送事件(http sse)
原理: 标准输入输出是一种用于本地通信的传输方式。在这种模式下,MCP 客户端会将服务器程序作为子进程启动,双方通过约定的标准输入和标准输出(可能是通过共享文件等方法)进行数据交换。具体而言,客户端通过标准输入发送请求,服务器通过标准输出返回响应。。
适用场景: 标准输入输出方式适用于客户端和服务器在同一台机器上运行的场景(本地自行编写服务端或将别人编写的服务端代码pull到本地执行),确保了高效、低延迟的通信。这种直接的数据传输方式减少了网络延迟和传输开销,适合需要快速响应的本地应用。
原理: 客户端和服务端通过 HTTP 协议进行通信,利用 SSE 实现服务端向客户端的实时数据推送,服务端定义了/see与/messages接口用于推送与接收数据。这里要注意SSE协议和WebSocket协议的区别,SSE协议是单向的,客户端和服务端建立连接后,只能由服务端向客户端进行消息推送。而WebSocket协议客户端和服务端建立连接后,客户端可以通过send向服务端发送数据,并通过onmessage事件接收服务端传过来的数据。
适用场景: 适用于客户端和服务端位于不同物理位置的场景,尤其是对于分布式或远程部署的场景,基于 HTTP 和 SSE 的传输方式更合适。
7.MCP.SO
10.Reddit/MCP

# MySQL数据库配置 MYSQL_HOST=192.168.20.128 MYSQL_PORT=3306 MYSQL_USER=root MYSQL_PASSWORD=abcd@1234 MYSQL_DATABASE=test
这个是mysql连接信息
server.py
import os
import uvicorn
from mcp.server.sse import SseServerTransport
from mysql.connector import connect, Error
from mcp.server import Server
from mcp.types import Tool, TextContent
from starlette.applications import Starlette
from starlette.routing import Route, Mount
from dotenv import load_dotenv
def get_db_config():
"""从环境变量获取数据库配置信息
返回:
dict: 包含数据库连接所需的配置信息
- host: 数据库主机地址
- port: 数据库端口
- user: 数据库用户名
- password: 数据库密码
- database: 数据库名称
异常:
ValueError: 当必需的配置信息缺失时抛出
"""
# 加载.env文件
load_dotenv()
config = {
"host": os.getenv("MYSQL_HOST", "localhost"),
"port": int(os.getenv("MYSQL_PORT", "3306")),
"user": os.getenv("MYSQL_USER"),
"password": os.getenv("MYSQL_PASSWORD"),
"database": os.getenv("MYSQL_DATABASE"),
}
print(config)
if not all([config["user"], config["password"], config["database"]]):
raise ValueError("缺少必需的数据库配置")
return config
def execute_sql(query: str) -> list[TextContent]:
"""执行SQL查询语句
参数:
query (str): 要执行的SQL语句,支持多条语句以分号分隔
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 对于SELECT查询:返回CSV格式的结果,包含列名和数据
- 对于SHOW TABLES:返回数据库中的所有表名
- 对于其他查询:返回执行状态和影响行数
- 多条语句的结果以"---"分隔
异常:
Error: 当数据库连接或查询执行失败时抛出
"""
config = get_db_config()
try:
with connect(**config) as conn:
with conn.cursor() as cursor:
statements = [stmt.strip() for stmt in query.split(";") if stmt.strip()]
results = []
for statement in statements:
try:
cursor.execute(statement)
# 检查语句是否返回了结果集 (SELECT, SHOW, EXPLAIN, etc.)
if cursor.description:
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
# 将每一行的数据转换为字符串,特殊处理None值
formatted_rows = []
for row in rows:
formatted_row = [
"NULL" if value is None else str(value)
for value in row
]
formatted_rows.append(",".join(formatted_row))
# 将列名和数据合并为CSV格式
results.append(
"\n".join([",".join(columns)] + formatted_rows)
)
# 如果语句没有返回结果集 (INSERT, UPDATE, DELETE, etc.)
else:
conn.commit() # 只有在非查询语句时才提交
results.append(f"查询执行成功。影响行数: {cursor.rowcount}")
except Error as stmt_error:
# 单条语句执行出错时,记录错误并继续执行
results.append(
f"执行语句 '{statement}' 出错: {str(stmt_error)}"
)
# 可以在这里选择是否继续执行后续语句,目前是继续
return [TextContent(type="text", text="\n---\n".join(results))]
except Error as e:
print(f"执行SQL '{query}' 时出错: {e}")
return [TextContent(type="text", text=f"执行查询时出错: {str(e)}")]
def get_table_name(text: str) -> list[TextContent]:
"""根据表的中文注释搜索数据库中的表名
参数:
text (str): 要搜索的表中文注释关键词
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 返回匹配的表名、数据库名和表注释信息
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
sql = "SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT "
sql += f"FROM information_schema.TABLES WHERE TABLE_SCHEMA = '{config['database']}' AND TABLE_COMMENT LIKE '%{text}%';"
return execute_sql(sql)
def get_table_desc(text: str) -> list[TextContent]:
"""获取指定表的字段结构信息
参数:
text (str): 要查询的表名,多个表名以逗号分隔
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 返回表的字段名、字段注释等信息
- 结果按表名和字段顺序排序
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
# 将输入的表名按逗号分割成列表
table_names = [name.strip() for name in text.split(",")]
# 构建IN条件
table_condition = "','".join(table_names)
sql = "SELECT TABLE_NAME, COLUMN_NAME, COLUMN_COMMENT "
sql += (
f"FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = '{config['database']}' "
)
sql += f"AND TABLE_NAME IN ('{table_condition}') ORDER BY TABLE_NAME, ORDINAL_POSITION;"
return execute_sql(sql)
def get_lock_tables() -> list[TextContent]:
sql = """SELECT
p2.`HOST` AS 被阻塞方host,
p2.`USER` AS 被阻塞方用户,
r.trx_id AS 被阻塞方事务id,
r.trx_mysql_thread_id AS 被阻塞方线程号,
TIMESTAMPDIFF(SECOND, r.trx_wait_started, CURRENT_TIMESTAMP) AS 等待时间,
r.trx_query AS 被阻塞的查询,
l.OBJECT_NAME AS 阻塞方锁住的表,
m.LOCK_MODE AS 被阻塞方的锁模式,
m.LOCK_TYPE AS '被阻塞方的锁类型(表锁还是行锁)',
m.INDEX_NAME AS 被阻塞方锁住的索引,
m.OBJECT_SCHEMA AS 被阻塞方锁对象的数据库名,
m.OBJECT_NAME AS 被阻塞方锁对象的表名,
m.LOCK_DATA AS 被阻塞方事务锁定记录的主键值,
p.`HOST` AS 阻塞方主机,
p.`USER` AS 阻塞方用户,
b.trx_id AS 阻塞方事务id,
b.trx_mysql_thread_id AS 阻塞方线程号,
b.trx_query AS 阻塞方查询,
l.LOCK_MODE AS 阻塞方的锁模式,
l.LOCK_TYPE AS '阻塞方的锁类型(表锁还是行锁)',
l.INDEX_NAME AS 阻塞方锁住的索引,
l.OBJECT_SCHEMA AS 阻塞方锁对象的数据库名,
l.OBJECT_NAME AS 阻塞方锁对象的表名,
l.LOCK_DATA AS 阻塞方事务锁定记录的主键值,
IF(p.COMMAND = 'Sleep', CONCAT(p.TIME, ' 秒'), 0) AS 阻塞方事务空闲的时间
FROM performance_schema.data_lock_waits w
INNER JOIN performance_schema.data_locks l ON w.BLOCKING_ENGINE_LOCK_ID = l.ENGINE_LOCK_ID
INNER JOIN performance_schema.data_locks m ON w.REQUESTING_ENGINE_LOCK_ID = m.ENGINE_LOCK_ID
INNER JOIN information_schema.INNODB_TRX b ON b.trx_id = w.BLOCKING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.INNODB_TRX r ON r.trx_id = w.REQUESTING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.PROCESSLIST p ON p.ID = b.trx_mysql_thread_id
INNER JOIN information_schema.PROCESSLIST p2 ON p2.ID = r.trx_mysql_thread_id
ORDER BY 等待时间 DESC;"""
return execute_sql(sql)
# 初始化服务器
app = Server("operateMysql")
@app.list_tools()
async def list_tools() -> list[Tool]:
"""列出可用的MySQL工具
返回:
list[Tool]: 工具列表,当前仅包含execute_sql工具
"""
return [
Tool(
name="execute_sql",
description="在MySQL8.0数据库上执行SQL",
inputSchema={
"type": "object",
"properties": {
"query": {"type": "string", "description": "要执行的SQL语句"}
},
"required": ["query"],
},
),
Tool(
name="get_table_name",
description="根据表中文名搜索数据库中对应的表名",
inputSchema={
"type": "object",
"properties": {
"text": {"type": "string", "description": "要搜索的表中文名"}
},
"required": ["text"],
},
),
Tool(
name="get_table_desc",
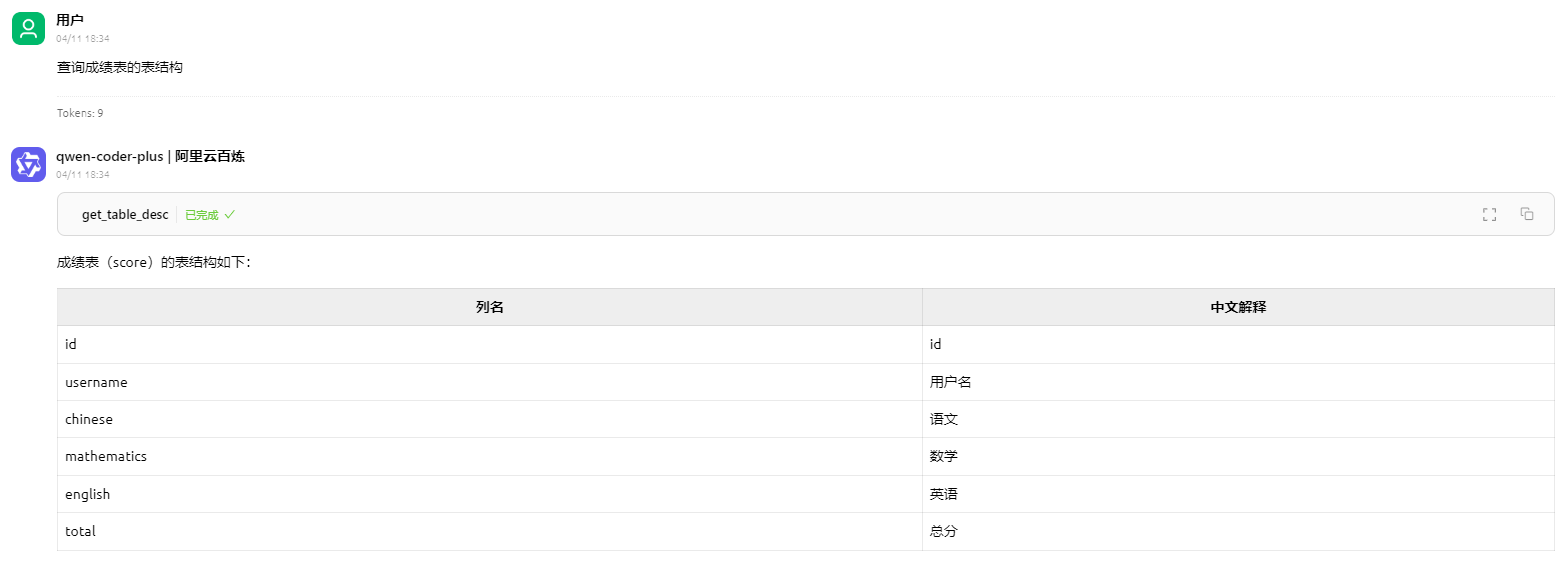
description="根据表名搜索数据库中对应的表结构,支持多表查询",
inputSchema={
"type": "object",
"properties": {
"text": {"type": "string", "description": "要搜索的表名"}
},
"required": ["text"],
},
),
Tool(
name="get_lock_tables",
description="获取当前mysql服务器InnoDB 的行级锁",
inputSchema={"type": "object", "properties": {}},
),
]
@app.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
if name == "execute_sql":
query = arguments.get("query")
if not query:
raise ValueError("缺少查询语句")
return execute_sql(query)
elif name == "get_table_name":
text = arguments.get("text")
if not text:
raise ValueError("缺少表信息")
return get_table_name(text)
elif name == "get_table_desc":
text = arguments.get("text")
if not text:
raise ValueError("缺少表信息")
return get_table_desc(text)
elif name == "get_lock_tables":
return get_lock_tables()
raise ValueError(f"未知的工具: {name}")
sse = SseServerTransport("/messages/")
# Handler for SSE connections
async def handle_sse(request):
async with sse.connect_sse(
request.scope, request.receive, request._send
) as streams:
await app.run(streams[0], streams[1], app.create_initialization_options())
# Create Starlette app with routes
starlette_app = Starlette(
debug=True,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
)
if __name__ == "__main__":
uvicorn.run(starlette_app, host="0.0.0.0", port=9000)
这里面,主要提供了4个工具方法,分别是:
execute_sql get_table_name get_table_desc get_lock_tables
安装python依赖
pip install mcp pip install mysql-connector-python pip install uvicorn pip install python-dotenv pip install starlette
启动应用
python server.py
输出:
INFO: Started server process [23756] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:9000 (Press CTRL+C to quit) INFO: 127.0.0.1:60896 - "GET /sse HTTP/1.1" 200 OK
访问页面:http://127.0.0.1:9000/sse
效果如下:
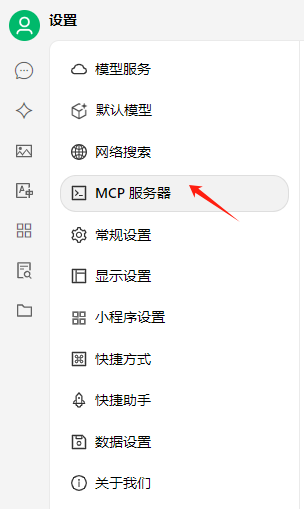
添加MCP服务器
输入名称:mysql_mcp_server_pro
类型:sse
URL:http://127.0.0.1:9000/sse
点击保存
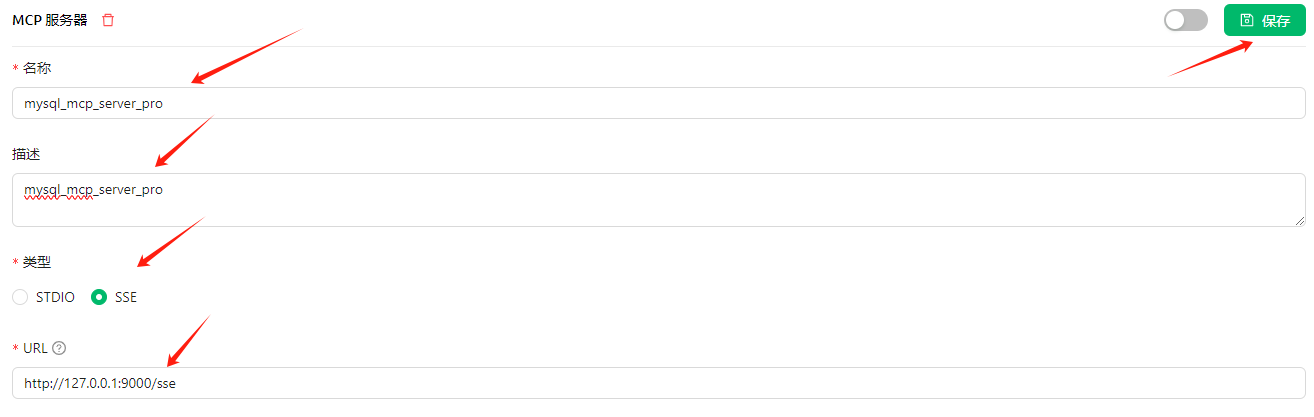
保存成功后,就可以看到工具列表了,只有4个

返回主页,点击新建助手,选择模型
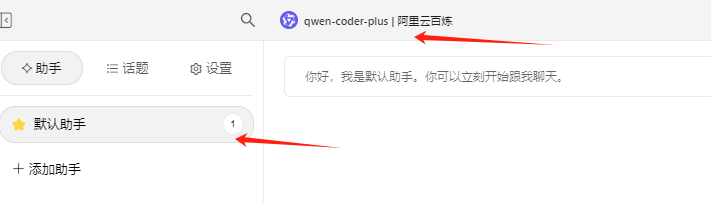
在输入框,找到MCP服务器

开启MCP

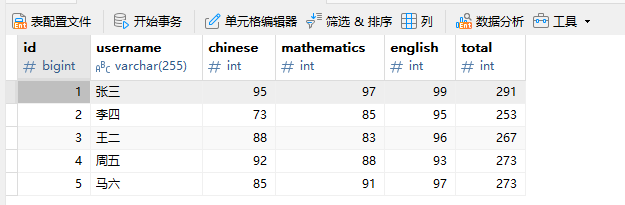
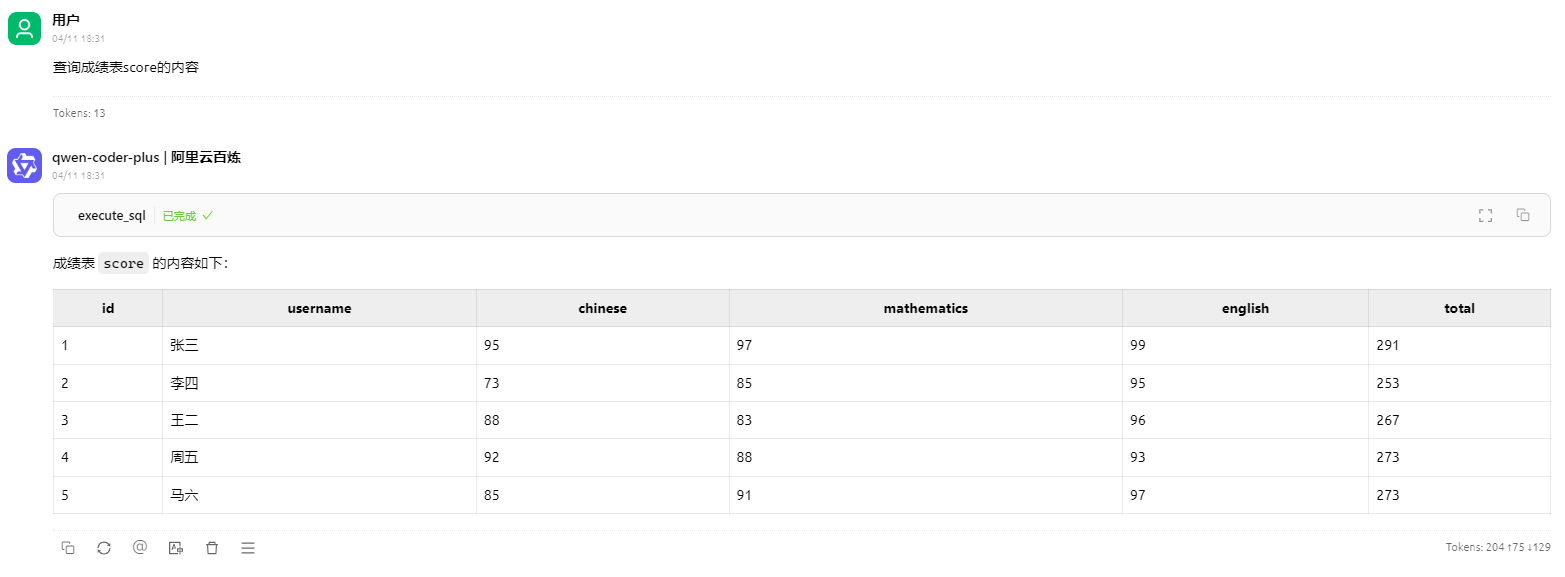
先来看mysql的数据表score,内容如下:

总结一下,AI模型调用MCP,还是很方便的。
有些时候AI模型做不到的,你可以自己写一个MCP应用。比如上面提到的查询mysql表数据,还有很多呢。
比如查询内部CRM系统,gitlab信息,内部业务系统,处理特定格式excel文件等等,都可以的。
来源: AI作曲神器加持!零基础也能玩转音乐副业,解锁你的创作新技能! – 国外网赚博客
最近有个朋友跟我吐槽:“我这辈子连五线谱都看不懂,居然也能靠写歌赚钱?” 我听完差点笑出声——这年头,AI连音乐创作的活儿都能包了!只要你会打字、会点鼠标,分分钟就能搞出一首原创歌曲,还能挂在网上卖钱。今天咱们就来聊聊,怎么用AI工具把“音乐创作”这个高大上的事儿,变成人人能上手的“副业神器”!

以前写首歌有多难?你得会写词、懂编曲、能哼旋律,搞不好还得学个乐器。但现在,AI直接把门槛踩成了平地!
1. 歌词生成:让ChatGPT当你的“作词小弟”
别担心自己文笔差,直接把要求丢给AI:“来首失恋风格的R&B,歌词要有地铁、咖啡、下雨天这些元素!” 不到10秒,AI就能给你整出一篇堪比青春疼痛文学的歌词。
比如这样:
“午夜的地铁站台,咖啡凉了心事还在翻涌,雨滴敲打玻璃,像你最后那句‘保重’……”
(别问我为啥这么熟练,这玩意儿试多了会上瘾!)
2. 一键生成歌曲:比点外卖还简单
有了歌词,直接打开Suno这类AI音乐平台,把文字粘贴进去,选个风格——流行、民谣、电子甚至古风都能搞定。点击“生成”,等个两三分钟,一首带旋律、伴奏甚至人声的完整歌曲就出炉了!
有个哥们儿用这方法,给自家宠物狗写了首生日歌发到抖音,居然火了!评论区全是“求定制”:“给我家猫也整一首!”“公司年会缺主题曲,老板说预算500!”
路子1:定制化“卖歌”
婚庆公司:新人想要专属婚礼BGM?报价800-2000元,把“新郎新娘名字”嵌进歌词,甜蜜度直接拉满!
小微企业:很多小店需要宣传曲,比如奶茶店想要“芋泥波波之歌”,火锅店需要“麻辣狂欢进行曲”。
短视频博主:搞笑博主需要魔性BGM,知识博主需要舒缓背景音乐,需求量超大!
路子2:平台流量分成
把AI生成的歌曲配上简单动画(用剪映就能搞定),上传到抖音、B站、YouTube。有个小姐姐专做“古风AI歌曲”,每条视频挂上“原创音乐人”标签,靠播放量分成月入四位数,还攒了一波铁粉!
路子3:直播现场“接单”
开个直播间,标题写“在线写歌!弹幕点歌风格立马出”!观众刷个礼物就能点歌,比如:“失恋emo版《挖呀挖》”“老板diss版《孤勇者》”。有人靠这招一晚上收打赏赚了2000+,顺便还引流到私域接长期订单。
Step1:歌词生成“三板斧”
场景化:别写“我爱你你爱他”,换成“加班到凌晨三点,便利店关东煮是唯一的温暖”。
押韵工具:用“押韵助手”App检查韵脚,避免出现“红烧肉押韵小怪兽”的惨案。
热词蹭流量:比如最近流行的“脆皮大学生”“全职儿女”,把这些梗塞进歌词里,自带传播属性!
Step2:让AI唱出“人味儿”
很多人吐槽AI唱歌像机器人,其实有个绝招:在Suno里选择“带情绪的人声”,比如“慵懒女声”“沙哑大叔音”。再调整播放速度,加快0.1倍速能让人声更自然,亲测有效!
Step3:MV制作“傻瓜攻略”
用剪映的“图文成片”功能,导入歌词自动匹配素材。重点来了:把AI生成的歌曲和画面节奏对齐!比如唱到“心跳加速”时切个赛车镜头,唱到“月光”时放夜景,瞬间高大上!
雷区1:版权问题
用AI工具前,务必看清用户协议!有些平台规定“生成的音乐版权归平台所有”,这种千万别碰。推荐Suno、Mureka这类明确“版权归创作者”的工具,避免辛苦做的歌被人白嫖。
雷区2:盲目追求数量
有人一天狂发20首歌,结果平台判定“低质内容”直接限流。记住:一周发3-5首精品,比每天水10首更有用!
雷区3:忽视“人设包装”
别光发歌!在主页写个“野生音乐人成长日记”,晒晒创作过程:“今天用AI给楼下煎饼摊写了主题曲,阿姨送我加蛋煎饼!” 接地气的人设能让粉丝黏性暴增!
秘籍1:打造“套餐服务”
比如定价299元套餐包含:“定制歌曲+15秒短视频+抖音热门标签优化”。客户觉得超值,你还能多赚附加服务费!
秘籍2:跨界合作
联系短视频编剧、广告公司,提供“音乐+文案”打包服务。有个团队靠给电商广告配魔性BGM,单条报价5000+!
秘籍3:卖“创作模板”
把爆款歌曲的歌词结构、旋律套路整理成模板,挂在知识付费平台卖。比如“7天学会AI写歌!附赠100个热门选题库!” 妥妥的睡后收入!
有人问我:“用AI做音乐,算不算投机取巧?” 我反手就甩了个例子:19世纪照相术刚发明时,画家们也觉得“这玩意侮辱艺术”,但现在谁不夸摄影是门技术?AI时代,咱们比的不是“谁更苦哈哈”,而是“谁更会借力”。
再说了,靠AI写歌赚钱不丢人!客户要的是“走心的作品”,又不是“痛苦的艺术家”。你负责提供创意和审美,AI负责技术执行,这明明就是双赢!
别等灵感,要去制造灵感;别等机会,要去创造机会。 打开电脑,选个AI工具,今晚就写出你的第一首“致富神曲”吧!