
来源: 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书) – hsm_computer – 博客园
最近我出了一本书,《基于股票大数据分析的Python入门实战 视频教学版》,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Python爬虫、数据分析和机器学习的技术,大家看了我的书,不仅能很快用比较热门的案例学好Python,更能了解些股票知识,不至于一入市就拍脑袋买卖。
在本文里,将给出若干精彩范例,包括用爬虫获取股市数据,用matplotlib可视化控件绘制K线和均线,以及用sklean库里的方法,通过机器学习预测股价的走势。
1 通过pandas_datareader库的方法爬取股市数据
pandas_datareader是一个能读取各种金融数据的库,在下面的getDataByPandasDatareader.py范例程序中演示了通过这个库获取股市数据的常规方法。

1 # coding=utf-8
2 from pandas_datareader import data as pdr
3 import yfinance as yf
4 yf.pdr_override()
5 code='600895.ss'
6 stock = pdr.get_data_yahoo(code,'2019-01-02','2019-02-01')
7 print(stock) # 输出内容
8 # 保存为excel和csv文件
9 stock.to_excel('D:\\stockData\\ch5\\'+code+'.xlsx')
10 stock.to_csv('D:\\stockData\ch5\\'+code+'.csv')
从这个范例程序的代码上来看,不算复杂,从中没有见到爬取网站之类的代码。关键的是第6行,通过调用pdr.get_data_yahoo方法从雅虎网站获取数据,这个方法的参数分别是股票代码,开始日期和结束日期。第4行使用yf.pdr_override方法是为了防止雅虎网站修改获取历史数据的API接口而导致get_data_yahoo方法不可用。
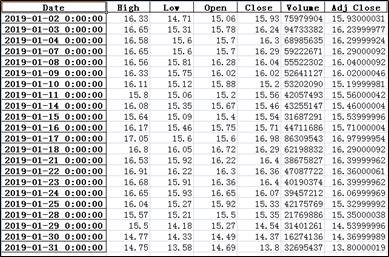
在这个范例程序中获取了600895(张江高科)2019-01-02到2019-01-31的数据,可以看出,获取的数据并不包括结束日期参数当天的数据。
在第7行和第8行分别调用了to_excel和to_csv方法,把结果存入了指定目录下的文件中。这个范例程序运行后,我们首先能在控制台中看到输出,其次会在D:\stockData\ch5\目录中,看到600895.ss.xlsx和600895.ss.csv这两个保存股票数据的文件。打开600895.ss.xlsx文件,能看到如图5-4所示的数据内容,其实在控制台中和另一个csv文件中,可以看到一样的数据。
在上述范例程序中,在调用get_data_yahoo方法时,传入的股票代码带有.ss的后缀,这表示该代码是沪股的。此外,还能通过.sz的后缀来表示深股,通过.hk的后缀表示港股。如果要获取美股的数据,则直接用美股的股票代码即可。在下面的printDataByPandasDatareader.py范例程序中演示了获取美股,港股和深股相关数据的方式。
1 # coding=utf-8
2 from pandas_datareader import data as pdr
3 import yfinance as yf
4 yf.pdr_override()
5 stockCodeList = []
6 stockCodeList.append('600007.ss') # 沪股“中国国贸”
7 stockCodeList.append('000001.sz') # 深股“平安银行”
8 stockCodeList.append('2318.hk') # 港股“中国平安”
9 stockCodeList.append('IBM') # 美股,IBM,直接输入股票代码不带后缀
10 for code in stockCodeList:
11 # 为了演示,只取一天(2019-01-02)的交易数据
12 stock = pandas_datareader.get_data_yahoo(code,'2019-01-02','2019-01-03')
13 print(stock)
这个范例程序运行后,就能从控制台中看到输出的4个股票在指定日期内的交易情况,由于数据量比较多,本书就不罗列具体的数据了。
2 用matplotlib绘制k线和均线
K线是由开盘价、收盘价、最高价和最低价这四个要素构成。在得到上述四个值之后,首先用开盘价和收盘价绘制成一个长方形实体。随后根据最高价和最低价,把它们垂直地同长方形实体连成一条直线,这条直线就叫影线。如果再细分一下,长方形实体上方的就叫上影线,下方的就叫下影线。通过K线可以形象地记录价格变动的情况,常用的有日K线,周K线和月K线。
均线也叫移动平均线(Moving Average,简称MA),是指某段时间内的平均股价(或指数)连成的曲线,均线一般分为三类:短期、中期和长期。通常把5日和10日移动平均线称为短期均线,一般把20日、30日和60日移动平均线作为中期均线,一般120日和250日(甚至更长)移动平均线称为长期均线。
在如下的drawKAndMAMore.py范例程序中,将用到上文提到的爬取股票数据的代码,从网络接口里获取股票数据,并绘制k线和均线,请大家不仅注意k线和均线的含义,还要重视matplotlib库里绘制图形、图例和坐标轴的做法,在这本书里,对应的知识点都有详细的说明。
1 # !/usr/bin/env python
2 # coding=utf-8
3 from pandas_datareader import data as pdr
4 import pandas as pd
5 import matplotlib.pyplot as plt
6 from mpl_finance import candlestick2_ochl
7 from matplotlib.ticker import MultipleLocator
8 import yfinance as yf
9 yf.pdr_override()
10 # 根据指定代码和时间范围获取股票数据
11 code='600895.ss'
12 stock.drop(stock.index[len(stock)-1],inplace=True)
13 # 保存在本地
14 stock.to_csv('D:\\stockData\ch7\\600895.csv')
15 df = pd.read_csv('D:/stockData/ch7/600895.csv',encoding='gbk',index_col=0)
16 # 设置窗口大小
17 fig, ax = plt.subplots(figsize=(10, 8))
18 xmajorLocator = MultipleLocator(5) # 将x轴主刻度设置为5的倍数
19 ax.xaxis.set_major_locator(xmajorLocator)
20 # 调用方法绘制K线图
21 candlestick2_ochl(ax = ax, opens=df["Open"].values,closes=df["Close"].values, highs=df["High"].values, lows=df["Low"].values,width=0.75, colorup='red', colordown='green')
22 # 如下是绘制3种均线
23 df['Close'].rolling(window=3).mean().plot(color="red",label='3日均线')
24 df['Close'].rolling(window=5).mean().plot(color="blue",label='5日均线')
25 df['Close'].rolling(window=10).mean().plot(color="green",label='10日均线')
26 plt.legend(loc='best') # 绘制图例
27 ax.grid(True) # 带网格线
28 plt.title("600895张江高科的K线图")
29 plt.rcParams['font.sans-serif']=['SimHei']
30 plt.setp(plt.gca().get_xticklabels(), rotation=30)
31 plt.show()
第一,从第9行到第15行通过调用之前介绍过的get_data_yahoo方法,传入股票代码、开始时间和结束时间这三个参数,从雅虎网站中获得股票交易的数据。
第二,在第17行中调用figsize方法设置了窗口的大小。
第三,第18行和第19行的程序代码设置了主刻度是5的倍数。之所以设置成5的倍数,是因为一般一周的交易日是5天。但这里不能简单地把主刻度设置成每周一,因为某些周一有可能是股市休市的法定假日。
第四,由于无需在x轴上设置每天的日期,因此这里无需再调用plt.xticks方法,但是要调用如第30行所示的代码,设置x轴刻度的旋转角度,否则x轴显示的时间依然有可能会相互重叠。
至于绘制K线的candlestick2_ochl方法和绘制均线的rolling方法与之前drawKAndMA.py范例程序中的代码是完全一致的。
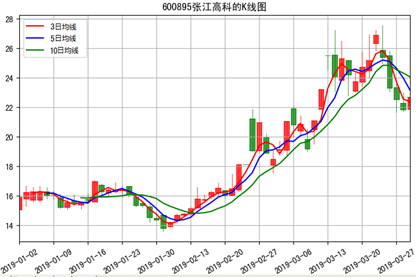
这个范例程序的运行结果如图7-5所示,从中可以看到改进后的效果。由于本次显示的股票时间段变长了(是3个月),因此与drawKAndMA.py范例程序相比,这个范例程序均线的效果更为明显,尤其是3日均线,几乎贯穿于整个时间段的各个交易日。
另外,由于在第26行通过调用plt.legend(loc=’best’)方法指定了图例将“显示在合适的位置”,因此这里的图例显示在效果更加合适的左上方,而不是drawKAndMA.py范例程序中的右上方。
3 用sklearn库的机器学习方法预测股票后市价格
在下面的predictStockByLR.py范例程序中,根据股票历史的开盘价、收盘价和成交量等特征值,从数学角度来预测股票未来的收盘价。
1 # !/usr/bin/env python
2 # coding=utf-8
3 import pandas as pd
4 import numpy as np
5 import math
6 import matplotlib.pyplot as plt
7 from sklearn.linear_model import LinearRegression
8 from sklearn.model_selection import train_test_split
9 # 从文件中获取数据
10 origDf = pd.read_csv('D:/stockData/ch13/6035052018-09-012019-06-01.csv',encoding='gbk')
11 df = origDf[['Close', 'High', 'Low','Open' ,'Volume']]
12 featureData = df[['Open', 'High', 'Volume','Low']]
13 # 划分特征值和目标值
14 feature = featureData.values
15 target = np.array(df['Close'])
第10行的程序语句从包含股票信息的csv文件中读取数据,在第14行设置了特征值是开盘价、最高价、最低价和成交量,同时在第15行设置了要预测的目标列是收盘价。在后续的代码中,需要将计算出开盘价、最高价、最低价和成交量这四个特征值和收盘价的线性关系,并在此基础上预测收盘价。
16 # 划分训练集,测试集 17 feature_train, feature_test, target_train ,target_test = train_test_split(feature,target,test_size=0.05) 18 pridectedDays = int(math.ceil(0.05 * len(origDf))) # 预测天数 19 lrTool = LinearRegression() 20 lrTool.fit(feature_train,target_train) # 训练 21 # 用测试集预测结果 22 predictByTest = lrTool.predict(feature_test)
第17行的程序语句通过调用train_test_split方法把包含在csv文件中的股票数据分成训练集和测试集,这个方法前两个参数分别是特征列和目标列,而第三个参数0.05则表示测试集的大小是总量的0.05。该方法返回的四个参数分别是特征值的训练集、特征值的测试集、要预测目标列的训练集和目标列的测试集。
第18行的程序语句计算了要预测的交易日数,在第19行中构建了一个线性回归预测的对象,在第20行是调用fit方法训练特征值和目标值的线性关系,请注意这里的训练是针对训练集的,在第22行中,则是用特征值的测试集来预测目标值(即收盘价)。也就是说,是用多个交易日的股价来训练lrTool对象,并在此基础上预测后续交易日的收盘价。至此,上面的程序代码完成了相关的计算工作。
23 # 组装数据 24 index=0 25 # 在前95%的交易日中,设置预测结果和收盘价一致 26 while index < len(origDf) - pridectedDays: 27 df.ix[index,'predictedVal']=origDf.ix[index,'Close'] 28 df.ix[index,'Date']=origDf.ix[index,'Date'] 29 index = index+1 30 predictedCnt=0 31 # 在后5%的交易日中,用测试集推算预测股价 32 while predictedCnt<pridectedDays: 33 df.ix[index,'predictedVal']=predictByTest[predictedCnt] 34 df.ix[index,'Date']=origDf.ix[index,'Date'] 35 predictedCnt=predictedCnt+1 36 index=index+1
在第26行到第29行的while循环中,在第27行把训练集部分的预测股价设置成收盘价,并在第28行设置了训练集部分的日期。
在第32行到第36行的while循环中,遍历了测试集,在第33行的程序语句把df中表示测试结果的predictedVal列设置成相应的预测结果,同时也在第34行的程序语句逐行设置了每条记录中的日期。
37 plt.figure() 38 df['predictedVal'].plot(color="red",label='predicted Data') 39 df['Close'].plot(color="blue",label='Real Data') 40 plt.legend(loc='best') # 绘制图例 41 # 设置x坐标的标签 42 major_index=df.index[df.index%10==0] 43 major_xtics=df['Date'][df.index%10==0] 44 plt.xticks(major_index,major_xtics) 45 plt.setp(plt.gca().get_xticklabels(), rotation=30) 46 # 带网格线,且设置了网格样式 47 plt.grid(linestyle='-.') 48 plt.show()
在完成数据计算和数据组装的工作后,从第37行到第48行程序代码的最后,实现了可视化。
第38行和第39行的程序代码分别绘制了预测股价和真实收盘价,在绘制的时候设置了不同的颜色,也设置了不同的label标签值,在第40行通过调用legend方法,根据收盘价和预测股价的标签值,绘制了相应的图例。
从第42行到第45行设置了x轴显示的标签文字是日期,为了不让标签文字显示过密,设置了“每10个日期里只显示1个”的显示方式,并且在第47行设置了网格线的效果,最后在第48行通过调用show方法绘制出整个图形。运行本范例程序,即可看到如图13-7所示的结果。
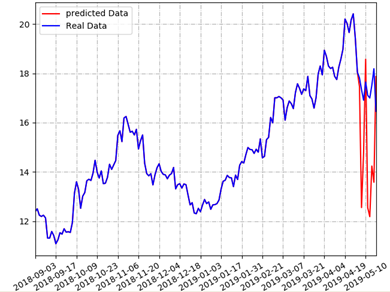
可以看出,蓝线表示真实的收盘价(图中完整的线),红线表示预测股价(图中靠右边的线。因为本书黑白印刷的原因,在书中读者看不到蓝色和红色,请读者在自己的计算机上运行这个范例程序即可看到红蓝两色的线)。虽然预测股价和真实价之间有差距,但涨跌的趋势大致相同。而且在预测时没有考虑到涨跌停的因素,所以预测结果的涨跌幅度比真实数据要大。
股票价格不仅由技术面决定,还受政策面、资金量以及消息面等诸多因素的影响,这也能解释预测结果和真实结果间有差异的原因。
4 对书的介绍和版权说明
本文给出的范例,仅是《基于股票大数据分析的Python入门实战 视频教学版》一书里的部分案例,该书京东链接:https://item.jd.com/69241653952.html。

这本书包括如下的内容,是本入门python的工具书。
1 Python基本语法,集合,面向对象语法,异常处理,读写文件技能。
2 Python操作数据库的技能。
3 通过爬虫从网络接口爬取股票数据的技能。
4 基于Numpy+Pandas+Matplotlib进行数据分析的技能
5 基于TKinter的GUI编程技能+ 发送邮件的技能
6 Django框架的用法
7 线性回归+SVM的机器学习技能
这本书里,像本文那样花花绿绿能吸引人的图真不少,而且还是通过python绘制出来的,用这类比较能吸引人的案例来入门python,一定非常高效。
本文可以转载,转载时请全文转载,别有删节,并用链接的形式给出原文链接。否则的话,可能会遇到出版社的维权。
文本相关链接:

