来源: 如何使用ABP进行软件开发之基础概览 – 溪源More – 博客园
ABP框架简述
1)简介
在.NET众多的技术框架中,ABP框架(本系列中指aspnetboilerplate项目)以其独特的魅力吸引了一群优秀开发者广泛的使用。
在该框架的赋能之下,开发者可根据需求通过官方网站【https://aspnetboilerplate.com/Templates】选择下载例如Vue/AngluarJS/MVC等不同类型的模板项目,轻松加入ABP开发者的队伍中,尽享基于ABP开发带来的乐趣。

ABP开发框架也提供了丰富的文档,能够为开发者带来许多便捷。目前ABP的文档网站为:
官方文档:https://aspnetboilerplate.com/Pages/Documents
文档库不可谓不全,加上国内众多的ABP开发者参与的活跃的技术圈子,使得学习成本只是在第一个项目中比较高,后期将会越来越平滑。
2)现状
当然,目前ABP的框架开发者和社区已经把更多的精力投入到了ABP.VNEXT开发框架,这个新框架以其DDD+微服务+模块化的理念获得了大量拥趸,使ABP框架的开发优先级已经开始逐渐降低。
但这是因为ABP框架的功能已经成熟稳定,且ABP是一种增量式的架构设计,开发者在熟练掌握这种框架后,可以根据自己的需要进行方便的扩展,使其成为小项目架构选型中一种不错的备选方案。
当然,也存在一些弊端。例如由于ABP被称为.NET众多开发框架中面向领域驱动设计的最佳实践,而囿于领域驱动设计本身不低的门槛,使得学习的过程变得看起来非常陡峭;
除此之外,ABP也广泛使用了目前ASP.NET/ASP.NET Core框架的大量比较新的特性,对于不少无法由于各种原因无法享受.NET技术飞速发展红利的传统开发者来说,无形中也提高了技术门槛。
3)综述
在这个系列中,本文计划分成三篇来介绍ABP框架,第一篇介绍ABP的基础概览,介绍基础知识,第二篇介绍ABP的模式实践,第三篇,试图介绍如何从更传统的三层甚至是单层+SQL的单层架构,如何迁移到ABP框架。
(毕竟。。.NET遗留应用实在是太多了,拯救或不拯救?)
代码结构结构
基本文件夹简述
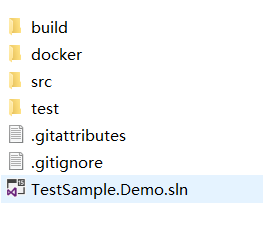
当我们通过ABP模板项目的官方网站下载一个项目后,我们所获得的代码包的结构如下图所示,其中:
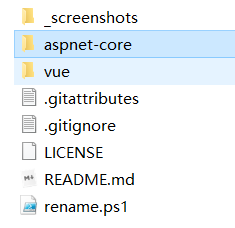
- vue为使用iview框架构建的管理系统基本模板,该脚手架使用了yarn作为包管理器,并集成了vuex/axios等常用框架,并提供了用户,租户,权限三个基本功能的示例代码,开发者只需发挥聪明才智就能快速的通过该框架入手前端项目。
- (当然,该项目广泛使用了typescript+面向对象的设计,似乎前端开发者。。普遍不擅长面向对象开发?)
- aspnet-core则是一个完整的ASP.NETcore项目的快速开发脚手架。该脚手架集成了docker打包于一体,并包含基本的单元测试示例,使用了identity作为权限控制单元,使用swagger作为接口文档管理工具,集成了efcore、jwt等常用组件,对于开发者来说,基本上算是开箱即用了。
前端vue项目
打开vue文件夹之后,该项目的基本目录如下图所示。(src文件夹)
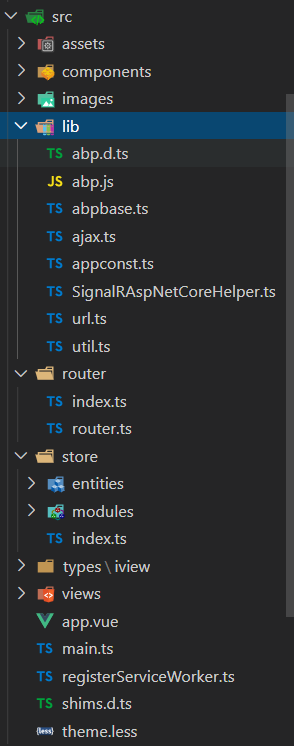
lib文件夹
定义了与abp+vue脚手架项目的基础组件和常见类库,封装了一系列基本方法。例如权限控制,数据请求,菜单操作,SignalR等基础组件的用法。
router文件夹
定义了vue项目的路由规则,其中index.ts文件是项目的入口,router.ts文件定义了vue文件的路由规则。
store文件夹
由于本项目使用了vuex框架,所以我们可以来看看对于store文件夹的介绍。
在vuex框架中:
每一个 Vuex 应用的核心就是 store(仓库)。“store”基本上就是一个容器,它包含着你的应用中大部分的状态 (state)。
Vuex 和单纯的全局对象有以下两点不同:
Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
你不能直接改变 store 中的状态。改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化,从而让我们能够实现一些工具帮助我们更好地了解我们的应用。
即vuex框架中,将原来的请求链路,抽象化为状态的变化,通过维护状态,使得数据的管理更加便捷,也易于扩展。
views文件夹
定义了登录、首页、用户、角色、租户的基本页面,并提供了新增、查看、编辑、删除的代码示例。
综上,该项目是一个结构清晰,逻辑缜密的前端框架,可以作为常见管理系统的脚手架。
后端项目
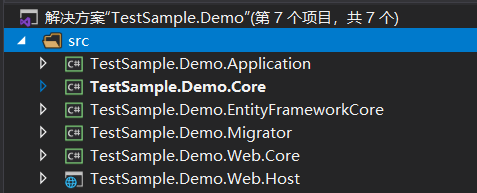
简介
后端项目是一个遵循了领域驱动设计的分层,同时又符合Robert Martin在《代码整洁之道》提出的【整洁架构】。
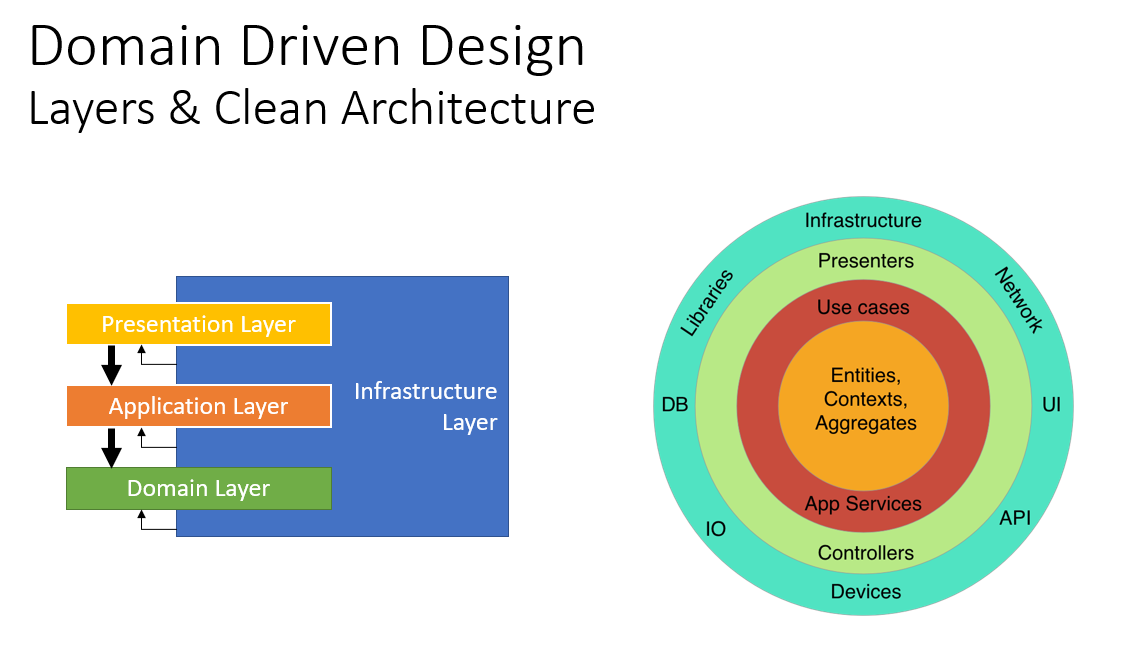
领域驱动设计简介
在领域驱动设计的分层设计中,共有四个功能分层,分别是:
表示层(Presentation Layer):为用户提供接口,使用应用层实现用户交互。
应用层(Application Layer):介于用户层和领域层之间,协调用户对象,完成对应的任务。
领域层(Domain Layer):包含业务对象和规则,是应用程序的心脏。
基础设施层(Infrastructure Layer):提供高层级的通用技术功能,主要使用第三方库完成。
在后文中,基于abp对领域驱动设计的功能分层将进行多次、详细叙述,本小节不再赘述。
整洁架构简介
整洁架构是由Bob大叔提出的一种架构模型,来源于《整洁架构》这本书,顾名思义,其目的并不是为了介绍这一种优秀的架构本身,而是介绍如何设计一种整洁的架构,使得代码结构易于维护。
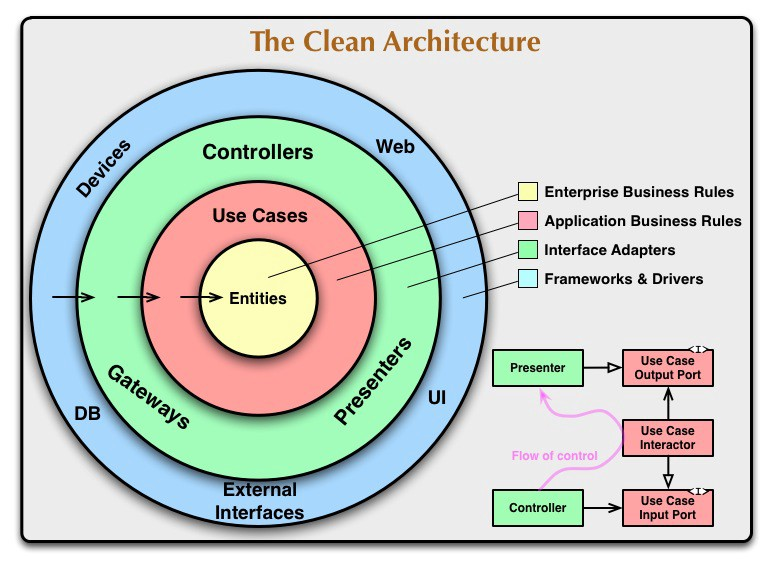
(整洁架构就是这样一个洋葱,所以也有人称它为“洋葱”架构)
- 依赖规则(Dependency Rule)
用一组同心圆来表示软件的不同领域。一般来说,越深入代表你的软件层次越高。外圆是战术是实现机制(mechanisms),内圆的是核心原则(policy)。
Policy means the application logic.
Mechanism means the domain primitives.
使此体系架构能够工作的关键是依赖规则。这条规则规定软件模块只能向内依赖,而里面的部分对外面的模块一无所知,也就是内部不依赖外部,而外部依赖内部。同样,在外面圈中使用的数据格式不应被内圈中使用,特别是如果这些数据格式是由外面一圈的框架生成的。我们不希望任何外圆的东西会影响内圈层
- 实体 (Entities)
实体封装的是整个企业范围内的业务核心原则(policy),一个实体能是一个带有方法的对象,或者是一系列数据结构和函数,只要这个实体能够被不同的应用程序使用即可。
如果你没有编写企业软件,只是编写简单的应用程序,这些实体就是应用的业务对象,它们封装着最普通的高级别业务规则,你不能希望这些实体对象被一个页面的分页导航功能改变,也不能被安全机制改变,操作实现层面的任何改变不能影响实体层,只有业务需求改变了才可以改变实体
- 用例 (Use case)
在这个层的软件包含只和应用相关的业务规则,它封装和实现系统的所有用例,这些用例会混合各种来自实体的各种数据流程,并且指导这些实体使用企业规则来完成用例的功能目标。
我们并不期望改变这层会影响实体层. 我们也不期望这层被更外部如数据库 UI或普通框架影响,而这也正是我们分离出这一层来的原因所在。
然而,应用层面的操作改变将会影响到这个用例层,如果需求中用例发生改变,这个层的代码就会随之发生改变。所以可以看到,这一层是和应用本身紧密相关的
- 接口适配器 (Interface Adapters)
这一层的软件基本都是一些适配器,主要用于将用例和实体中的数据转换为外部系统如数据库或Web使用的数据,在这个层次,可以包含一些GUI的MVC架构,表现视图 控制器都属于这个层,模型Model是从控制器传递到用例或从用例传递到视图的数据结构。
通常在这个层数据被转换,从用例和实体使用的数据格式转换到持久层框架使用的数据,主要是为了存储到数据库中,这个圈层的代码是一点和数据库没有任何关系,如果数据库是一个SQL数据库, 这个层限制使用SQL语句以及任何和数据库打交道的事情。
- 框架和驱动器
最外面一圈通常是由一些框架和工具组成,如数据库Database, Web框架等. 通常你不必在这个层不必写太多代码,而是写些胶水性质的代码与内层进行粘结通讯。
这个层是细节所在,Web技术是细节,数据库是细节,我们将这些实现细节放在外面以免它们对我们的业务规则造成影响伤害
ABP的分层实现
在ABP项目中,层次划分如下。
1. 应用层(Application项目)
在领域驱动设计的分层式架构中,应用层作为应用系统的北向网关,对外提供业务外观的功能。在Abp模板项目中,Application项目也是编写主要用例代码的位置,开发者们在此定义与界面有关的数据行为,实现面向接口的开发实践。
应用服务层包含应用服务,数据传输单元,工作单元等对象。
- Application Service
为面向用户界面层实现业务逻辑代码。例如需要为某些界面对象组装模型,通常会定义ApplicationService,并通过DTO对象,实现与界面表现层的数据交换。
- Data Transfer Object (DTO)
最常见的数据结构为DTO(数据传输对象),这是来源于马丁弗勒在《企业架构应用模式》中提到的名词,其主要作用为:
是一种设计模式之间传输数据的软件应用系统。 数据传输目标往往是数据访问对象从数据库中检索数据。
在ABP的设计中,有两种不同类型的DTO,分别是用于新增、修改、删除的Input DTO,和用于查询的Output DTO。
- Unit of Work:
工作单元。工作单元与事务类似,封装了一系列原子级的数据库操作。
2. 核心层(Core项目)
核心层包含领域实体、值对象、聚合根,以及领域上下文实现。
- Entity(实体):
实体有别于传统意义上大家所理解的与数据库字段一一匹配的实体模型,在领域驱动设计中,虽然实体同样可能持久化到数据库,但实体包含属性和行为两种不同的抽象。
例如,如果有一个实体为User,其中有一个属性为Phone,数据为086-132xxxxxxxx,我们有时需要判断该手机号码的国际代号,可能会添加一个新的判定 GetNationCode(),可以通过从Phone字段中取出086来实现,这就是一种通俗意义上的行为。
- Value Object(值对象):
值对象无需持久化到数据库,往往是从其他实体或聚合中“剥离”出来的与某些聚合具备逻辑相关性或语义相关性的对象,有时值对象甚至只有个别属性。
例如,上述实体,包含Phone字段,我们可以将整个Phone“剥离”为一个Telephone对象,该对象可包含PhoneNumber和NationCode字段。
public class User
{
public Telephone Phone{public get;private set;}
}
public class Telephone
{
public string PhoneNumber {get;set;}
public string NationCode {get;set;}
}
- Aggregate & Aggregate Root(聚合,聚合根):
聚合是业务的最小工作单元,有时,一个实体就是一个小聚合,而为聚合对外提供访问机制的对象,就是聚合根。
在领域驱动设计中,识别聚合也是一件非常重要的工作,有一组系统的方法论可以为我们提供参考。
当然,事实上识别领域对象,包括且不限定于识别聚合、值对象、实体识别该对象的行为或(方法)本身是一件需要经验完成的工作,有时需要UML建模方法的广泛参与。
有时,我们会习惯于通过属性赋值完成梭代码的过程,从而造成领域行为流失在业务逻辑层的问题,那么或许可以采取这样的方法:
1、对象的创建,使用构造函数赋值,或工厂方法创建。
2、将所有对于属性的访问级别都设置为
public string Phone{public get;private set;}
然后再通过一个绑定手机号码的方法,来给这个对象设置手机号码。
public string BindPhone(string phone)
{
}
将所有一切涉及到对Phone的操作,都只能通过规定的方法来赋值,这样可以实现我们开发过程中,无意识的通过属性赋值,可能导致的“领域行为”丢失的现象发生。
这种方式可以使得对对象某些属性的操作,只能通过唯一的入口完成,符合单一职责原则的合理运用,如果要扩展方法,可以使用开闭原则来解决。
但是,采用这种方式,得尽量避免出现:SetPhone(string phone) 这样的方法出现,毕竟这样的方法,其实和直接的属性赋值,没有任何区别。
- Repository(仓储)
仓储封装了一系列对象数据库操作的方法,完成对象从数据库到对象的转换过程。在领域驱动设计中,一个仓储往往会负责一个聚合对象从数据库到创建的全过程。
- Domain Service(领域服务)
领域服务就是“实干家”,那些不适合在领域对象中出现,又不属于对象数据库操作的方法,又与领域对象息息相关的方法,都可以放到领域服务中实现。
- Specification(规格定义)
规范模式是一种特殊的软件设计模式,通过使用布尔逻辑将业务规则链接在一起,可以重新组合业务规则。
实际上,它主要用于为实体或其他业务对象定义可重用的过滤器。
3. 其他基础设施(EntityFrameworkCore,Web.Core,Web.Host项目)
EntityFrameworkCore负责定义数据库上下文和对EFCore操作的一系列规则、例如种子数据的初始化等。
Web.Core:定义了应用程序的外观和接口。虽然从表面上看,Web.Core定义了作为Web访问入口的控制器方法和登录验证的逻辑,看起来像是用户表现层的东西,但是仔细想想,这些东西,何尝不是一种基础设施?
Web.Host:定义WEB应用程序的入口。
总结
本文简述了ABP框架的前后端项目的分层结构,通过了解这些结构,将有助于我们在后续的实战中更快入手,为应用开发插上翅膀。