
来源: sql server 锁与事务拨云见日(上) – 花阴偷移 – 博客园
一.概述
讲到SQL server锁管理时,感觉它是一个大话题,因为它不但重要而且涉及的知识点很多,重点在于要掌握高并发要先要掌握锁与事务,涉及的知识点多它包括各式各样的锁,锁的组合,锁的排斥,锁延伸出来的事务隔离级别, 锁住资源带来的阻塞,锁之间的争用造成的死锁,索引数据与锁等。这次介绍锁和事务,我想分上中下篇,上篇详细介绍锁,中篇介绍事务,下篇总结, 针对锁与事务我想把我掌握的以及参考多方面资料,整合出来尽量说详细。 最后说下,对于高级开发人员或DBA,锁与事务应该是重点关注的,它就像是数据库里的一个大boss,如完全掌握了它,数据库就会像就像庖丁解牛一样游刃有余 哈哈 。
二.锁的产生背景
在关系型数据库里锁是无处不再的。当我们在执行增删改查的SQL语句时,锁也就产生了。锁对应的就的是事务,不去显示加tran就是常说的隐式事务。当我们写个存储过程希望数据一致性时, 要么同时回滚,要么同时提交,这时我们用begin tran 来做显示事务。锁的范围就是事务。在sql server里事务默认是提交读(Read Committed) 。
锁是对目标资源(行、页、区、表..)获取所有权的锁定,是一个逻辑概念,用来保存事务的ACID. 当多用户并发同时操作数据时,为了避免出现不一致的数据,锁定是必须的机制。 但同时如果锁的数量太多,持续时间太长,对系统的并发和性能都没有好处。
三.锁的全面认识
3.1 锁住的资源
我们知道sql server的存储数据单元包括文件组,页,区,行。锁住资源范围从低到高依次对应的是:行(RID/KEY)锁,页(PAGE)锁, 表(OBJECT)锁。可通过sp_lock查看,比如: 当我们操作一条数据时应该是行锁, 大批量操作时是页锁或表锁, 这是大批量操作会使锁的数量越多,锁就会自动升级 将大量行锁合成多个页锁或表锁,来避免资源耗尽。SQL SERVER要锁定资源时,默认是从最底级开始锁起(行) 。锁住的常见资源如下:
| 名称 | 资源 |
说明 |
| 数据行 | RID | 锁住堆中(表没有建聚集索引)的单个行。格式为File:Page:SlotID 如 1:8787:4 |
| 索引键 | KEY | 锁住T-tree(索引)中单个行,是一个哈值值。如:(fb00a499286b) |
| 页 | PAGE | 锁住数据页(一页8kb,除了页头和页尾,页内容存储数据)可在sys.dm_os_buffer_descriptors找到。格式FileID :Page Number 如1:187541 |
| 范围 | extent | 锁住区(一组连续的8个页 64kb)FileID:N页 。如:1:78427 |
| 数据表 | object | 通常是锁整个表。 如:2858747171 |
| 文件 | File | 一般是数据库文件增加或移除时。如:1 |
| 数据库 | database | 锁住整个数据库,比如设置修改库为只读模式时。 database ID如:7 |
下图是通过sp_lock的查看的,显示了锁住的资源类型以及资源

3.2 锁的类型及锁说明
| 锁类型 | 锁说明 |
| 共享锁 (S锁) | 用于不更改或不更新数据的读取操作,如 SELECT 语句。 |
| 更新锁 (U锁) | 它是S与X锁的混合,更新实际操作是先查出所需的数据,为了保护这数据不会被其它事务修改,加上U锁,在真正开始更新时,转成X锁。U锁和S锁兼容, 但X锁和U锁不兼容。 |
| 独占锁(排它锁)(X锁) | 用于数据修改操作,例如 INSERT、UPDATE 或 DELETE。 确保不会同时对同一资源进行多重更新 |
| 意向锁(I锁) | (I)锁也不是单独的锁模式,用于建立锁的层次结构。 意向锁包含三种类型:意向共享 (IS)、意向排他 (IX) 和意向排他共享 (SIX)。意识锁是用来标识一个资源是否已经被锁定,比如一个事务尝试锁住一个表,首先会检查是否已有锁在该表的行或者页上。 |
| 架构锁(Sch-M,Sch-S) | 在执行依赖于表架构操作时使用,例如:添加列或删除列 这个时候使用的架构修改锁(Sch-M),用来防止其它用户对这个表格进行操作。别一种是数据库引擎在编译和执行查询时使用架构性 (Sch-S),它不会阻止其它事务访问表格里的数据,但会阻止对表格做修改性的ddl操作和dml操作。 |
| 大容量更新 (BU) | 是指数据大容量复制到表中时使用BU锁,它允许多个线程将数据并发地大容量加载到同一表,同时防止其它不进行大容量加载数据的进程访问该表。 |
| 键范围 | 当使用可序列化事务隔离级别时(SERIALIZABLE)保护查询读取的行的范围。 确保再次运行查询时其他事务无法插入符合可序列化事务的查询的行。下章介绍的事务时再详细说 |
四 锁的互斥(兼容性)
在sql server里有个表,来维护锁与锁之间的兼容性,这是SQLServer预先定义好的,没有任务参数或配置能够去修改它们。如何提高兼容性呢?那就是在设计数据库结构和处理sql语句时应该考虑,尽量保持锁粒度小,这样产生阻塞的概率就会比较小,如果一个连接经常申请页面级,表级,甚至是数据库级的锁资源,程序产生的阻塞的可能性就越大。假设:事务1要申请锁时,该资源已被事务2锁住,并且事务1要申请的锁与事务2的锁不兼容。事务1申请锁就会出现wait状态,直到事务2的锁释放才能申请到。 可通过sp_lock查看wait等待(也就是常说的阻塞)
下面是最常见的锁模式的兼容性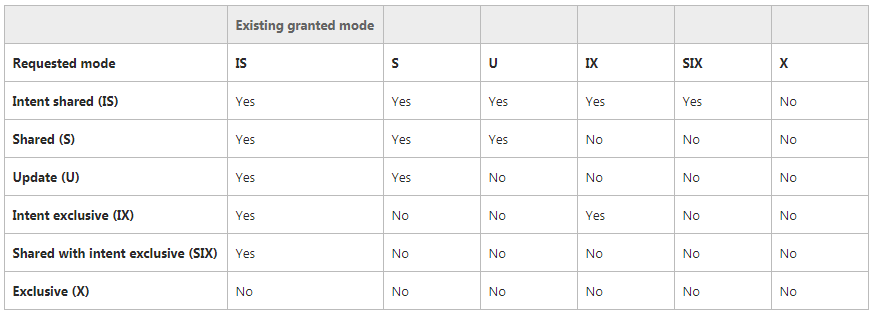
五. 锁与事务关系
如今系统并发现象,引起的资源急用,出现的阻塞死锁一直是技术人员比较关心的。这就涉及到了事务, 事务分五种隔离级别,每个隔离级别有一个特定的并发模式,不同的隔离级别中,事务里锁的作用域,锁持续的时间都不同,后面再详细介绍事务。这里看下客户端并发下的锁与事务的关系, 可以理解事务是对锁的封装,事务就是在并发与锁之间的中间层。如下图:
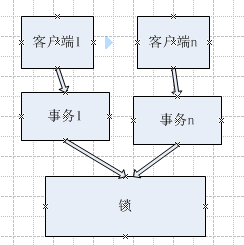
六. 锁的持续时间
下面是锁在不同事务隔离级别里,所持续占用的时间:
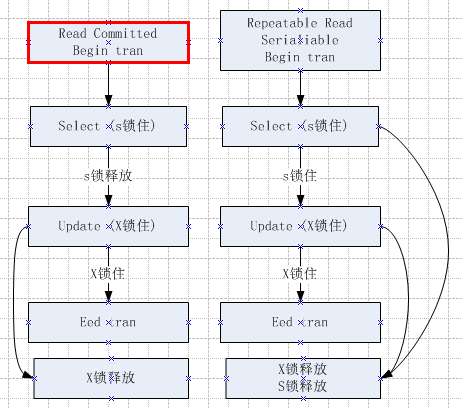
6.1 SELECT动作要申请的锁
我们知道select 会申请到共享锁,下面来演示下共享锁在Repeatable 重复读的级别下,共享锁保留到事件提交时才释放。
具体是1.事务A设置隔离级别为Repeatable重复读,开启事务运行且不提交事务。
2.再打开一个会话窗口,使用sys.dm_tran_locks来分析查看事务的持有锁。
--开启一个事务A, 设置可重复读, 不提交 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ BEGIN TRAN SELECT * FROM dbo.Product WHERE SID=204144
--上面执行完后,打开另一会话查询锁状态 SELECT k.request_session_id,k.resource_type,k.request_status,k.request_mode,k.resource_description, OBJECT_NAME( p.object_id) as objectName,p.index_id FROM SYS.dm_tran_locks k LEFT JOIN SYS.PARTITIONS p ON k.resource_associated_entity_id=p.hobt_id ORDER BY request_session_id,resource_type
先看看查询单条语句的执行计划,再看看锁住的资源

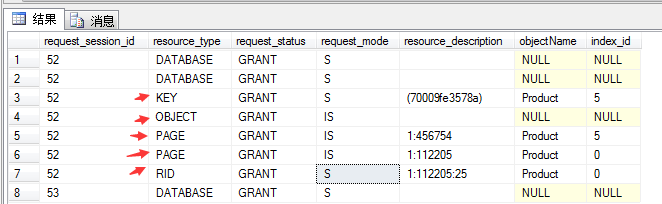
通过DMV查询,我们看到:
(1)首先是锁住DATABASE资源,是数据库级别的共享锁,以防止别人将数据库删除。
(2)锁住OBJECT表资源,在Product表上加了意向共享锁IS,以防止别人修改表的定义。
(3)锁住了二个PAGE页加了意向共享锁IS,通过上面执行计划可以看出来,查询出来的数据是通过索引查询50%,RID堆查询50%。这条数据分布在二个页上,通过where SID来查找没有完全走索引查找。
(4)通过第3点可以看出,数据1个页是对应RID行,另一页对应KEY行 二个共享锁,堆位置1:112205:25 ,KEY的哈希值(70009fe3578a) 。
总结下:通过Repeatable 重复读,直要事务不提交,共享锁一直会存在。针对想减少被别人阻塞或者阻塞别人的概率,能考虑事情有:1. 尽量减少返回的记录,返回的记录越多,需要的锁也就越多,在Repeatable隔离级别及以上,更是容易造成阻塞。2.返回的数据如果是一小部份,尽量使用索引查找,避免全表扫描。3.可以的话,根据业务设计好最合适的几个索引,避免通过多个索引找到结果。
4.2 UPDATE动作要申请的锁
对于UPDATE需要先查询,再修改。具体是查询加S锁,找到将要修改的记录后先加U锁,真正修改时升级成X锁。还是通过上面的product表来演示具体:选用Repeatable级别,运行一个update语句(先kill 掉之前的会放52)
--开启一个事务, 设置可重复读, 不提交 BEGIN TRAN UPDATE dbo.Product SET model='test' WHERE SID IN(10905,119921,204144)
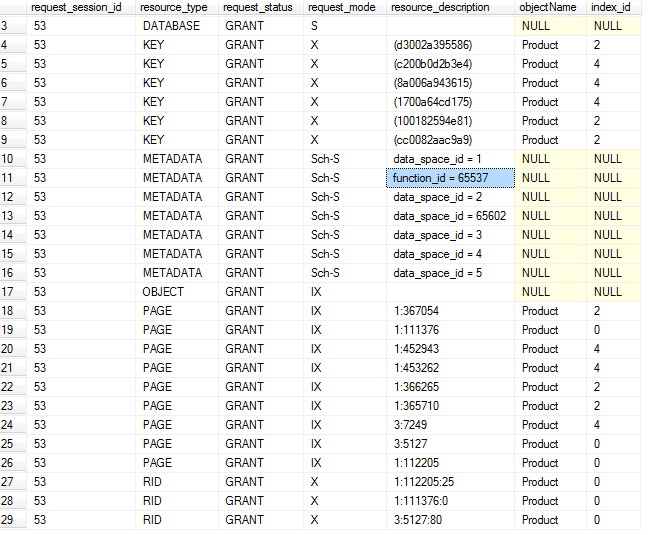
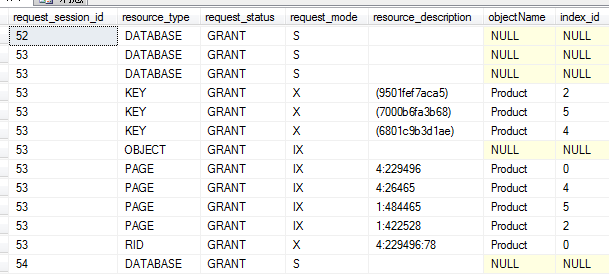
通过 dmv查看,吓一跳没想到锁住了这么多资源,纠结 那下面试着来分析下为什么锁住这么多资源:使用sys.indexes查看index_id 的0,2,4各使用了什么索引
SELECT * FROM sys.indexes WHERE object_id= OBJECT_id('product')

(1)这个product表并没有建聚集索引,是在堆结构上建立的非索聚索引,index_id=0 是堆, index_id=2和4 又是分别二个非索聚索引
(2)同样在DATABASE和OBJECT资源 上都加了共享锁。
(3)意向排它锁IX,锁住的Page共9页 说明数据关联了9页,其中堆上3页,ix_1非索聚索引上3页,ixUpByMemberID非索聚索引上3页。
(4) 排它锁X锁住RID堆上3行,KEY索引上6行。大家可能会觉得奇怪明明只改三行的model值,为什么会涉及到9行呢? 我来解释下这个表是建了三个非聚集索引,其中ix_1索引里有包含列model,xUpByMemberID索引里也同样有包含列model,还有model数据是在堆,当堆上数据修改后,model关联的非聚集索引也要重新维护。如下图
(5) 这里还有架构锁Sch-s ,锁住了元数据。
总结:1.一定要给表做聚集索引,除了特殊情况使用堆结构。2.要修改的数据列越多,锁的数目就会越多,这里model就涉及到了9行维护。3. 描述的页面越多,意向锁就会越多,对扫描的记录也会加锁,哪怕没有修改。所以想减少阻塞要做到:1).尽量修改少的数据集,修改量越多,需要的锁也就越多。2) 尽量减少无谓的索引,索引的数目越多,需要的锁也可能越多。3.严格避免全局扫描,修改表格记录时,尽量使用索引查询来修改。
4.3 DELETE动作要申请的锁
BEGIN TRAN DELETE dbo.Product WHERE SID =10905
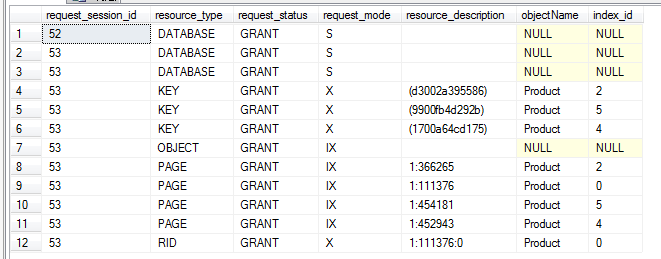
(1) 删除了RID堆的数据,以及关联的非聚集索引三个key的值分别是(2,5,4)
(2) 在要删除的4个page上加了意向排它锁,同样对应一个RID和三个KEY。
(3)在OBJECT资源表上加了意向排它锁。
总结:在DELETE过程中是先找到符合条件的记录,然后再删除, 可以说是先SELECT后DELETE,如果有索引第一步查询申请的锁会比较 少。 对于DELETE不但删除数据本身,还会删除所有相关的索引键,一个表上的索引越多,锁的数目就会越多,也容易阻塞。为了防步阻塞我们不能不建索引,也不能随便就建索引,而是要根据业务建查询绝对有利的索引。
4.4 INSERT动作要申请的锁
BEGIN TRAN
INSERT into dbo.Product VALUES('modeltest','brandtest',GETDATE(),9708,'test')
对于以上三种动作,INSERT相对简单点,只需要对要插入数据本身加上X锁,对应的页加IX锁,同步更新了关联的索引三个key。
这里新增跟删除最终显示的锁一样,但在锁申请的过程中,新增不需要先查询到数据s锁,升级u锁,再升级成X锁。
七. 锁的升级
7.1 使用profiler窗口查看实时的锁升级
以单次批操作受影响的行数超过5000条时(锁数量最大值5000),升级为表锁。在SQLServer里可以选择完全关掉锁升级,虽然可以减少阻塞,但锁内存会增加,降低性能还可能造成更多死锁。
锁升级缺点:会给其它会话带来阻塞和死锁。锁升级优点:减少锁的内存开销。
检测方法:在profiler中查看lock:escalation事件类。通过查看Type列,可查看锁升级的范围,升级成表锁(object是表锁)
如下图:
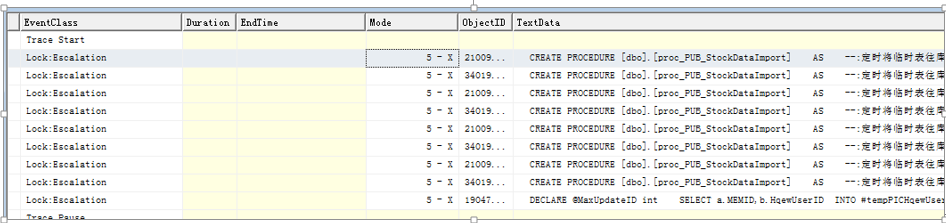
如果减少批操作量,就没有看到升级表锁, 可自行通过 escalation事件查看,下图就是减少了受影响的行数。
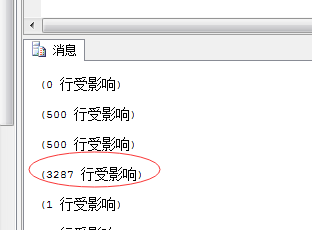
总结:将批操作量受影响行数减少到5000以下,减少锁的升级后,发生了更频繁的死锁,原因是多个page页的争用。后有人指出你先把并行度降下来(删除500一下的数据可以不使用并行) 在语句中设置maxdop = 1 这样应该不会死锁了。具体原因还需具体分析。
7.2 使用dmv查看锁升级
sys.dm_db_index_operational_stats返回数据库中的当前较低级别 I/O、 锁定、 闩锁,和将表或索引的每个分区的访问方法活动。
index_lock_promotion_attempt_count:数据库引擎尝试升级锁的累积次数。
index_lock_promotion_count:数据库引擎升级锁的累积次数。

SELECT OBJECT_NAME(ddios.[object_id], ddios.database_id) AS [object_name] ,
i.name AS index_name ,
ddios.index_id ,
ddios.partition_number ,
ddios.index_lock_promotion_attempt_count ,
ddios.index_lock_promotion_count ,
( ddios.index_lock_promotion_attempt_count
/ ddios.index_lock_promotion_count ) AS percent_success
FROM sys.dm_db_index_operational_stats(DB_ID(), NULL, NULL, NULL) ddios
INNER JOIN sys.indexes i ON ddios.object_id = i.object_id
AND ddios.index_id = i.index_id
WHERE ddios.index_lock_promotion_count > 0
ORDER BY index_lock_promotion_count DESC;
7.3 使用dmv查看页级锁资源争用
page_lock_wait_count:数据库引擎等待页锁的累积次数。
page_lock_wait_in_ms:数据库引擎等待页锁的总毫秒数。
missing_index_identified:缺失索引的表。
SELECT OBJECT_NAME(ddios.object_id, ddios.database_id) AS object_name ,
i.name AS index_name ,
ddios.index_id ,
ddios.partition_number ,
ddios.page_lock_wait_count ,
ddios.page_lock_wait_in_ms ,
CASE WHEN DDMID.database_id IS NULL THEN 'N'
ELSE 'Y'
END AS missing_index_identified
FROM sys.dm_db_index_operational_stats(DB_ID(), NULL, NULL, NULL) ddios
INNER JOIN sys.indexes i ON ddios.object_id = i.object_id
AND ddios.index_id = i.index_id
LEFT OUTER JOIN ( SELECT DISTINCT
database_id ,
object_id
FROM sys.dm_db_missing_index_details
) AS DDMID ON DDMID.database_id = ddios.database_id
AND DDMID.object_id = ddios.object_id
WHERE ddios.page_lock_wait_in_ms > 0
ORDER BY ddios.page_lock_wait_count DESC;
八. 锁的超时
在sql server 里锁默认是不会超时的,是无限的等待。多数客户端编程允许用户连接设置一个超时限制,因此在指定时间内没有反馈,客户端就会自动撤销查询, 但数据库里锁是没有释放的。
可以通 select @@lock_timeout 查看默认值是 ” -1″, 可以修改超时时间 例如5秒超时 set lock_timeout 5000;
下面是查看锁的等待时间, wait_time是当前会话的等待资源的持续时间(毫秒)
select session_id, blocking_session_id,command,sql_handle,database_id,wait_type ,wait_time,wait_resource from sys.dm_exec_requests where blocking_session_id>50

