
小主 | 兰希姑娘
最近参加一次项目的架构评审,一位小哥提到,当前的架构缺少redis,这是不可以的,原因是不符合高可用的原则,他的高可用指的是当mySQL宕机的时候,如果有redis,系统还可以继续提供服务,也就是说他认为一定要有redis,是为了提升系统应对mySQL宕机的风险。
不知道大家怎么看,虽说有一定道理,但是侧重点是不是不太对?之所以有了mysql,系统还要使用redis,主要的原因并非是灾备考虑,而是其他的原因。
今天就来聊聊有了mysql,为什么还要使用redis,redis解决了什么问题?
1 mysql的功能和存在的问题
首先我们先聊下mysql的功能和存在的问题。
mysql数据存储在磁盘里,对数据有强一致需求、持久存储需求的项目需要选择mysql(以及类似的数据库)。
但是mysql支持并发访问的能力有限,当有大量并发请求的时候,mysql会挂掉的。
另外,有时候,我们需要更快的响应速度,而mysql速度有限,不能满足需求。
上面的两个问题,恰好都是redis的强项。
2 为什么要使用redis
实际上,在项目中使用redis,其实主要是从两个角度去考虑: 性能和并发。(以下内容引用自作者:孤独烟的文章)
(一)性能 如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。
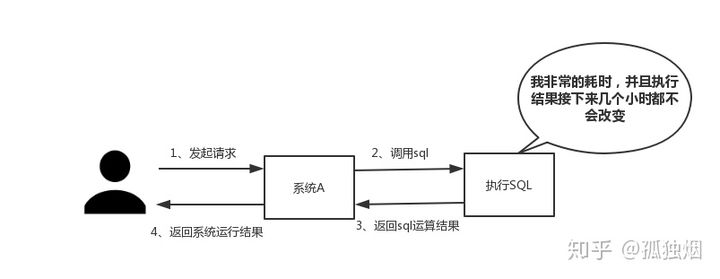
(二)并发 如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问数据库。
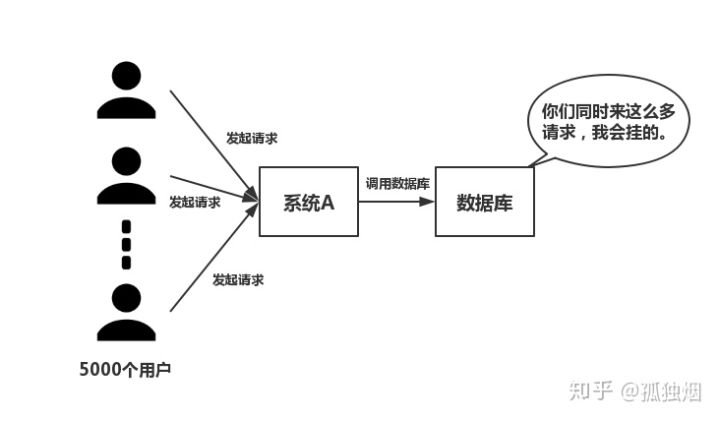
3 redis基础知识介绍
说到这里,再来补充下redis的基础知识。
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言 编写,是一个高性能的key-value存储系统。
为了保证效率,数据都是缓存在内存中,同时redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、sorted set 和hash(哈希类型)。
redis提供多种语言的API,它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
4 常见的redis+mysql设计方案
目前大多数公司的存储都是mysql + redis,mysql作为主存储,redis作为辅助存储被用作缓存,加快访问读取的速度,提高性能。
具体来讲就是,mysql存储着所有的业务数据,根据业务规模会采用相应的分库分表、读写分离、主备容灾、数据库集群等手段。
但是由于mysql是基于磁盘的IO,基于服务响应性能考虑,将业务热数据利用redis缓存,使得高频业务数据可以直接从内存读取,提高系统整体响应速度。
常见的设计方案是:redis+mysql读写分离方案。
具体如下。
业务数据读操作流程:
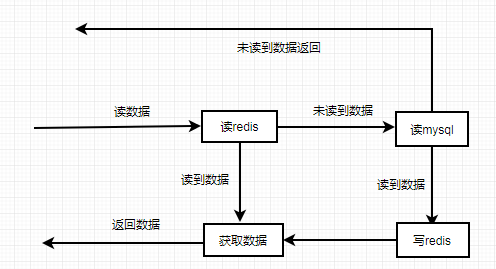
业务数据更新操作流程:
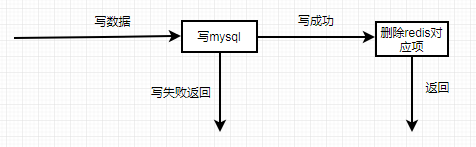
5 redis+mysql结合导致的一致性问题
两者结合最大的问题就是缓存和数据库双写一致性问题。
为了解决这个问题,我们可以对存入缓存的数据设置过期时间,也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
这个方法作为一致性的兜底方案。
更精准的做法是,在写操作上,首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
有的方案在这里采用的是更新完mysql成功后,然后进行相应的更新redis中数据的操作。
这里的问题是,要考虑到更新的操作可能是并发的,而写mysql和写redis是两个步骤,不是原子性的。
例如有线程1和线程2同时进行写操作,执行顺序可能是如下的情况:
线程1写mysql->线程2写mysql->线程2写redis->线程1写redis
这样的话,结果变成了mysql的内容是线程2写入的,而redis的内容是线程1写入的,mysql和redis中的数据就不一致了,后续的数据读取都是错的。
而采用每次写完mysql后就清除redis的方式,就保证了写完后的读取必然会重新从mysql读取数据,然后写入redis。这样就保证了redis里的数据最终和mysql中是一致的,保证了数据的最终一致性。
当然,这些措施并不能保证完全杜绝不一致的发生。
数据库和缓存双写,就必然会存在不一致的问题。
如果对数据有强一致性要求,就不能放缓存,因为我们所做的方案其实从根本上来说,只能降低不一致发生的概率,无法完全避免。
6 redis这么好,那么为什么不直接全部用redis存储呢
聊聊最后一个问题,不知道大家有没有这样的疑问:redis这么好,那么为什么不直接全部用redis存储呢?答案很简单,贵呀。
因为redis存储在内存中,如果存储在内存中,存储容量肯定要比磁盘少很多,那么要存储大量数据,只能花更多的钱去购买内存,造成在一些不需要高性能的地方是相对比较浪费的,所以目前基本都是mysql(主) + redis(辅),在需要性能的地方使用redis,在不需要高性能的地方使用mysql。
技术精进是一场修行,相信自己和时间力量。

