
资料:
(1)分布式系统事务一致性解决方案:
http://www.infoq.com/cn/articles/solution-of-distributed-system-transaction-consistency
(2)MySQL事务隔离级别的实现原理:
https://www.cnblogs.com/cjsblog/p/8365921.html
(3)当前读和快照读:
https://www.cnblogs.com/cat-and-water/p/6427612.html
(4)mySQL处理高并发,防止库存超卖:
https://blog.csdn.net/caomiao2006/article/details/38568825?utm_source=blogxgwz2
(5)Redis和Memcache对比及选择:
https://blog.csdn.net/sunmenggmail/article/details/36176029
(6)高并发下防止商品超卖的Redis实现(通过 jMeter 模拟并发):
https://blog.csdn.net/Allen_jinjie/article/details/79292163?utm_source=blogxgwz0
(7)Redis和请求队列解决高并发:
https://blog.csdn.net/ZHJUNJUN93/article/details/78560700?utm_source=blogxgwz17
(7)redis集群和kafka集群作为消息队列比较(优先考虑kafka):
https://www.2cto.com/kf/201701/587505.html
(8)面试中关于Redis的问题看这篇就够了(业务上避免过度复用一个 redis,它只是一个单线程。既用它做缓存、做计算,还拿它做任务队列,这样不好。):
https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA%3D%3D&idx=1&mid=2247483867&sn=39a06fa3d6d8f09eefaaf3d2b15b40e4
(9)Kafka,Mq和Redis作为消息队列使用时的差异有哪些?
https://www.wukong.com/answer/6527968849956962568/
(10)Redis与RabbitMQ作为消息队列的比较:
https://blog.csdn.net/gb4215287/article/details/79457445
(11)如何设计一个秒杀系统:
https://www.cnblogs.com/wangzhongqiu/p/6557596.html
(12)基于 SpringBoot+Mybatis+Redis+RabbitMQ 秒杀系统:
https://blog.csdn.net/qq_33524158/article/details/81675011
一、事务的四大特性:
1.原子性(Atomicity)(要么不执行,要么全部执行)
2.一致性(Consistency)(假设有多个数据库服务器,当修改了某一个数据库中的某一记录之后,【其他的数据库也要进行同步修改】)
3.隔离性(Isolation)(假设有事务1和事务2,则事务1绝不可以影响到事务2,事务2也绝不可以影响到事务1,即【事务1和事务2是相互独立的事件】)
4.持久性(Durability)(将【某应用服务器】的事务通过事务管理器记录到日志文件中,则当该应用服务器重启时,可以读取这些日志文件)
二、悲观锁和乐观锁的区别:
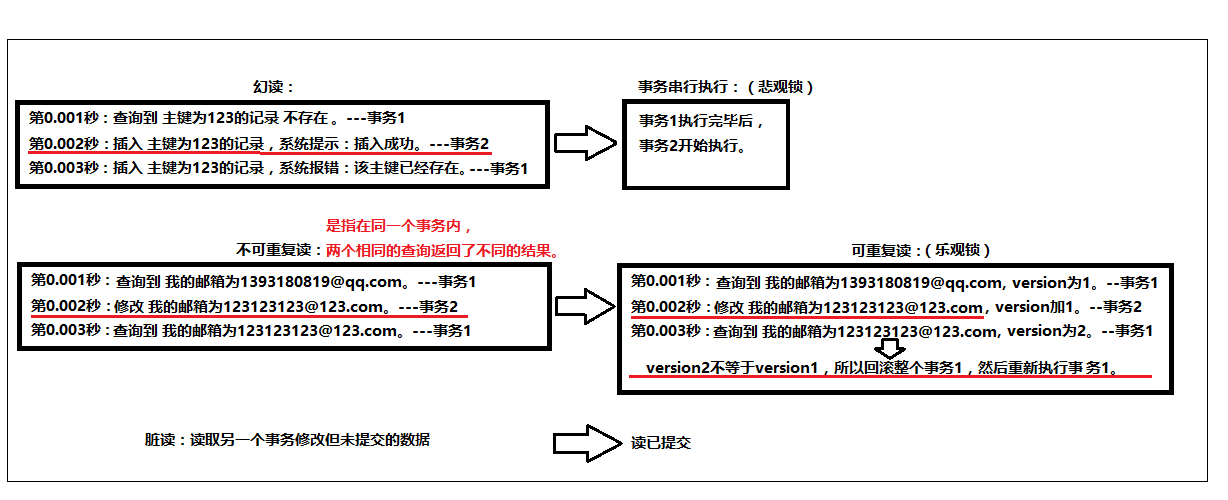
三、MySQL事务隔离级别:
1.读未提交:一个事务可以读取到另一个事务未提交的修改。这会带来脏读、幻读、不可重复读问题。(基本没用)
2.读已提交(Committed-Read):一个事务只能读取另一个事务已经提交的修改。其避免了脏读,但仍然存在不可重复读和幻读问题。
3.可重复读(Repeatable-Read)(乐观锁):同一个事务中多次读取相同的数据返回的结果是一样的。其避免了脏读和不可重复读问题。
4.串行化(Serializable_Read)(悲观锁):事务串行执行。避免了以上所有问题,包括幻读。
MySQL默认的隔离级别是【可重复读】。
四、避免库存超卖
(1)非秒杀的正常的、避免库存超卖的方法(利用关系型数据库的Repeatable-Read事务隔离级别)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
beginTranse(开启事务)try{ //quantity为请求减掉的库存数量 $dbca->query('update s_store set amount = amount - quantity where amount>=quantity and postID = 12345');}catch($e Exception){ rollBack(回滚)}commit(提交事务) |
(2)在秒杀的情况下,肯定不能如方法一那样高频率的去读写数据库,会严重造成性能问题的,
必须使用缓存,将需要秒杀的商品放入缓存中,再为每个缓存商品建立请求队列,以最快的速度缓存请求并响应客户端,最后再悠闲地处理队列中的请求。
五、各个消息队列的比较
1.利用redis实现的消息队列:一个轻量级的消息队列(数据量越大,效率越低,一般用于数据量较小的即时秒杀系统)
2.rabbitmq:一个重量级的、可靠的消息队列(数据量越大,效率越低,一般用于缓存可延迟的操作,比如银行转账)
3.kafka/Jafka:一个追求高吞吐量的、较不可靠的消息队列(一般用于缓存大数据中采集的数据)

