
来源: C# SQL优化 及 Linq 分页 – 天才卧龙 – 博客园
每次写博客,第一句话都是这样的:程序员很苦逼,除了会写程序,还得会写博客!当然,希望将来的一天,某位老板看到此博客,给你的程序员职工加点薪资吧!因为程序员的世界除了苦逼就是沉默。我眼中的程序员大多都不爱说话,默默承受着编程的巨大压力,除了技术上的交流外,他们不愿意也不擅长和别人交流,更不乐意任何人走进他们的内心!
悟出来一个道理,在这儿分享给大家:学历代表你的过去,能力代表你的现在,学习代表你的将来。我们都知道计算机技术发展日新月异,速度惊人的快,你我稍不留神,就会被慢慢淘汰!因此:每日不间断的学习是避免被淘汰的不二法宝。
最近真的是忙的不能再忙了,我一直这样喃喃自语:把自己分成三个也不够用的!还好,一期项目接近尾声,虽说还有些没完成的功能,但也不多了!索性抽点时间写篇博客吧,也希望大家能喜欢这篇博客。
在讲Linq分页之前,首先和大家探讨下SQL,如下:
1)SQL的优化(嘻嘻:因为:我负责公司项目的查询模块,连续做了一个多月的查询及半月多的BUG修改,因此:对SQL的优化还是颇有感悟的,在此分享给大家,希望大家喜欢。谢谢、):
1、要想写出优美的SQL语句,就必须明白索引查询和非索引查询,SQL在执行的过程中,索引查询的效率要大大高于非索引查询,因此:我们在写SQL语句的时候,应尽量避免非索引查询。当然,实在避免不了的情况下,也应尽可能的优化自己的SQL语句。
1.1、索引查询:要想使用索引查询,就必须首先弄清楚数据表中的索引字段,在此以PLSQL和SQLServer为例进行说明:如下(右键一张表,选择编辑/设计)
PLSQL查看索引字段:

SQLServer查看索引字段:
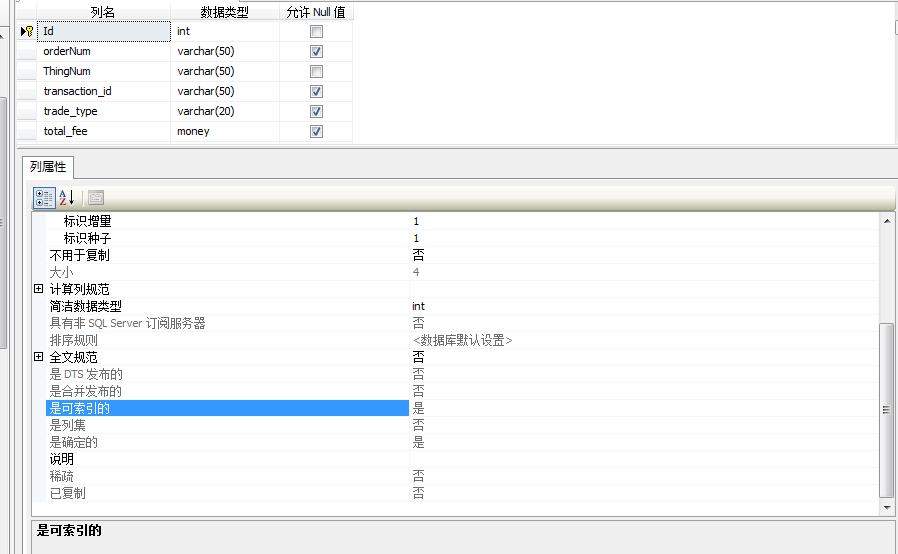
基本原则就是能通过索引字段进行查询的,就通过索引字段进行查询。
索引查询基本都是精确查询,在使用过程中应避免使用Like、in、ont in、EXISTS、DisTinct等关键词,在此关于索引查询不作太多说明,大家只需把下面的非索引查询搞明白就可以了。
1.2、非索引查询:
上文中提高:要尽可能的使用索引字段进行查询,那么,使用索引字段进行的查询都能称之为索引查询吗?
答案是否定的,譬如:主键字段A是通过GUID生成的,A作为主键可能是索引字段,但是如果你针对A进行Like、in、not in 等操作就会造成非索引查询。当然:一般没有人针对GUID进行LIKE查询,因此:此处举的例子不怎么恰当,勿怪。
那么在什么情况下会执行非索引查询呢?我们应当避免使用哪些关键词呢?如下:
1、DisTinct 关键词:使用此关键字会造成全表比对,慎用!
2、Like 关键词:LIKE操作符可以应用通配符查询,里面的通配符组合可能达到几乎是任意的查询,但是如果用得不好则会产生性能上的问题,如LIKE ‘%5400%’ 这种查询不会引用索引,而LIKE ‘X5400%’则会引用全范围比对查找。
3、in 关键词和 not in 关键词:用IN和NOT IN写出来的SQL的优点是比较容易写及清晰易懂,这比较适合现代软件开发的风格。但是用IN的SQL性能总是比较低的,从Oracle执行的步骤来分析用IN的SQL与不用IN的SQL有以下区别:
ORACLE试图将其转换成多个表的连接,如果转换不成功则先执行IN里面的子查询,再查询外层的表记录,如果转换成功则直接采用多个表的连接方式查询。由此可见用IN的SQL至少多了一个转换的过程。一般的SQL都可以转换成功,但对于含有分组统计等方面的SQL就不能转换了。
话说另一个关键词:Exists的执行效率要比in高出很多,因此:在这儿建议大家如果能用Exists解决问题时,就尝试用Exists去解决问题吧!
4、IS NULL关键词和IS NOT NULL关键词:索引是不会索引空值的,因此会全局非索引查询。性能低下。
5、UNION关键词:UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。如:
select * from gc_dfys
union
select * from ls_jg_dfys
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
推荐方案:采用UNION ALL操作符替代UNION,因为UNION ALL操作只是简单的将两个结果合并后就返回。
select * from gc_dfys
union all
select * from ls_jg_dfys
6、>= 及 <= 及 != 关键词:>= 和 <=作用于索引字段时会采取索引查询,但是如果作用于非索引字段,就会全表比对查询,因此,要根据情况而定。
7、Order by group by 关键词:order by group by 谈不上属于非索引关键词的范畴,但是使用order by group by 时,排序/分组的字段要使用索引字段,否则效率大大降低
以上是非索引查询涉及到的关键词,请大家慎重使用;
8、慎重 or 关键字,即使用了,也应该结合索引字段进行查询
2)SQL的书写规则:
1、同一功能同一性能不同写法SQL的影响。
如一个SQL在A程序员写的为 Select * from zl_yhjbqk
B程序员写的为 Select * from dlyx.zl_yhjbqk(带表所有者的前缀)
C程序员写的为 Select * from DLYX.ZLYHJBQK(大写表名)
D程序员写的为 Select * from DLYX.ZLYHJBQK(中间多了空格)
以上四个SQL在ORACLE分析整理之后产生的结果及执行的时间是一样的,但是从ORACLE共享内存SGA的原理,可以得出ORACLE对每个SQL 都会对其进行一次分析,并且占用共享内存,如果将SQL的字符串及格式写得完全相同,则ORACLE只会分析一次,共享内存也只会留下一次的分析结果,这不仅可以减少分析SQL的时间,而且可以减少共享内存重复的信息,ORACLE也可以准确统计SQL的执行频率。
2、WHERE后面的条件顺序影响
SQL1、select * from A where A.Name like ‘%陈%’
SQL2、select * from A where A.Id>30 and A.id<=50 and A.Name like ‘%陈%’
以上两个SQL中,第一个会全局查找,第二个会先执行索引查询(将范围锁定为20条记录),然后在执行非索引查询。因此:SQL1的性能会大大低于SQL2的性能。
3、SQL的执行顺序是先执行子查询,在逐步执行外层的查询,因此:在书写SQL的过程中,应尽可能的针对子查询进行精确查询且应尽可能的缩小子查询的结果集、
4、如果您仅仅只需要查询三个字段,请勿查询所有字段,譬如:select A.Id ,A.Name ,A.Sex from A 和 Select * from A 执行效率绝对是不一样滴。
5、统计查询时:譬如:select Count(1) from A 和 Select Count(*) from A 执行效率绝对是不一样滴。Count(1)的效率要远远大于Count(*)
6、能使用视图的话,就尽可能使用视图,如果你将A,B,C三张表进行连接查询,那么A,B,C三张表将会进行一个笛卡尔积连接,这个过程会大大增加系统的开销,因此:连接查询效率也不会很高。如果做成了视图,就相当于数据库事先做好了三张表的笛卡尔积,这样就省去了这一步骤,因此效率会增加!
7、针对时间字段:如果数据库中时间字段定义成varchar或nvarchar类型,请尽可能的进行数据类型转换,然后使用between and 进行查询,因为between and 执行的是索引查询。
8、批量插入数据时应尽可能的一次执行而非一次一次执行:例如: 插入一千条数据:
程序员A:
for(int i=0;i<1000;i++){
insert into A values(….)
连接数据库,执行插入操作,单独执行1000次插入
}
程序员B:
StringBuilder sb = new StringBuilder();
for(int i=0;i<1000;i++){
sb.Append(“insert into A values(….);”);
}
连接数据库,执行插入操作(将所有的插入语句作为一个整体)
同样是插入一千条数据,程序员B的效率要大大高于程序员A
除了以上的叙述外,我们在设计数据库的时候,也应做到最好,譬如:尽量不用text等类型作为字段类型,关于数据库设计的优化,大家自行学习吧!
讲了这么多,上述都是铺垫,还没有涉及到Linq分页,下面开讲
咱继续哈:话说领导昨天找我谈话了,说我做的部分查询模块效率不错,但是没能做到实时刷新,在这儿透漏给大家一个消息,我用的就是Linq查询和分页,效率高了,但又达不到客户的需求,哎…等着被炒鱿鱼吧,领导就是这样,只看结果,不管你怎么实现的。
嘿嘿,在这儿也要提醒大家,用Linq做的查询和分页,是不和数据库交互的,因此做不到实时刷新的哈。实现的基本方式就是:在数据库中进行查询,把查询的结果转化为一个大的集合,然后通过LINQ操作这个集合,所谓的操作也就是查询和分页。因此,你的查询模块和分页模块都是通过LINQ操作咱们首次查出来的大集合实现的,所以:你做的查询和分页就不会和数据库进行交互了,因此做不到实时刷新。
咱继续吹哈,话说,我今天装一把B,给大家演示一个LINQ查询和分页的案列,实现方式就通过C#控制台应用程序吧。
示例代码如下(通过lambda表达式进行相关查询):

namespace LINQ
{
class Program
{
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
foreach (var P in Lst)
{
Console.WriteLine(P.UserName + "&&" + P.Sex + "&&" + P.Age);
}
Console.Read();
}
/// <summary>
/// 初始化10000条数据
/// </summary>
/// <returns></returns>
public static List<Preson> LoadData()
{
List<Preson> result = new List<Preson>();
for (int i = 0; i < 10000; i++)
{
Preson P = new Preson()
{
UserName = "名字" + i,
Sex = (i % 2) == 0 ? "男" : "女",
Age = i % 100
};
result.Add(P);
}
return result;
}
}
class Preson
{
private string userName;
public string UserName
{
get { return userName; }
set { userName = value; }
}
private string sex;
public string Sex
{
get { return sex; }
set { sex = value; }
}
private int age;
public int Age
{
get { return age; }
set { age = value; }
}
}
}
这样就生成了年龄0~9999岁的男人、女人各5000个,如下
我们提出如下需求:
1、根据人的年龄由大到小排序(类似于SQL语句中的Order BY DESC 、 ORDER BY ASC 关键字)
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
Lst = Lst.OrderBy(p => p.Age).Reverse().ToList();
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
2、基于上述条件、查询年龄介于9000至91000之间的人(类似于SQL语句> < =关键字)
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
Lst = Lst.OrderBy(p => p.Age).Reverse().ToList();
Lst = Lst.Where(p => p.Age >= 9000).Reverse().ToList();
Lst = Lst.Where(p => p.Age <= 9100).Reverse().ToList();
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
3、基于上述条件、查询姓名中带有‘龙’的人(类似于SQL语句Like关键字中的左右%)
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
Lst = Lst.OrderBy(p => p.Age).Reverse().ToList();
Lst = Lst.Where(p => p.Age >= 9000).Reverse().ToList();
Lst = Lst.Where(p => p.Age <= 9100).Reverse().ToList();
Lst = Lst.Where(p => p.UserName.Contains("龙")).ToList();
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
4、基于上述条件、查询姓名以‘天才’开通的人(类似于SQL语句Like关键字中的左%)
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
Lst = Lst.OrderBy(p => p.Age).Reverse().ToList();
Lst = Lst.Where(p => p.Age >= 9000).Reverse().ToList();
Lst = Lst.Where(p => p.Age <= 9100).Reverse().ToList();
Lst = Lst.Where(p => p.UserName.Contains("龙")).ToList();
Lst = Lst.Where(p => p.UserName.StartsWith("天才")).ToList();
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
5、基于上述条件、查询姓名以’卧龙’结尾的人(类似于SQL语句Like关键字中的右%)
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
Lst = Lst.OrderBy(p => p.Age).Reverse().ToList();
Lst = Lst.Where(p => p.Age >= 9000).Reverse().ToList();
Lst = Lst.Where(p => p.Age <= 9100).Reverse().ToList();
Lst = Lst.Where(p => p.UserName.Contains("龙")).ToList();
Lst = Lst.Where(p => p.UserName.StartsWith("天才")).ToList();
Lst = Lst.Where(p => p.UserName.EndsWith("卧龙")).ToList();
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
6、基于上述条件、去除重复元素(类似于SQL语句中的Distinct 关键字)
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
Lst = Lst.OrderBy(p => p.Age).Reverse().ToList();
Lst = Lst.Where(p => p.Age >= 9000).Reverse().ToList();
Lst = Lst.Where(p => p.Age <= 9100).Reverse().ToList();
Lst = Lst.Where(p => p.UserName.Contains("龙")).ToList();
Lst = Lst.Where(p => p.UserName.StartsWith("天才")).ToList();
Lst = Lst.Where(p => p.UserName.EndsWith("卧龙")).ToList();
Lst = Lst.Distinct().ToList();
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
7、查询年龄总和及平均年龄
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
Lst = Lst.OrderBy(p => p.Age).Reverse().ToList();
Lst = Lst.Where(p => p.Age >= 9000).Reverse().ToList();
Lst = Lst.Where(p => p.Age <= 9100).Reverse().ToList();
Lst = Lst.Where(p => p.UserName.Contains("龙")).ToList();
Lst = Lst.Where(p => p.UserName.StartsWith("天才")).ToList();
Lst = Lst.Where(p => p.UserName.EndsWith("卧龙")).ToList();
Lst = Lst.Distinct().ToList();
int A = Lst.Sum(p => p.Age); //查询年龄总和
double B = Lst.Average(p => p.Age);//查询平均年龄
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
上述示例代码中是通过lambda表达式进行相关查询、Lambda表达式简单易用、通俗易懂!当然,我们也可以通过LINQ表达式来写以上查询案例。那么,通过LINQ我们应当怎么去写呢?
代码如下:
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
//--------------------LINQ查询如下--------------------//
var Result = from r in Lst
where r.Age>=9000 && r.Age<=9100 && r.UserName.Contains("龙") &&r.UserName.StartsWith("天才")&&r.UserName.EndsWith("卧龙") orderby r.Age descending
select r;
var Lst_2 = new List<Preson>();
foreach (var A in Result)//需要进行一次Foreach操作哦
{
Lst_2.Add(A);
}
Lst = Lst_2;
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
上述LINQ的查询结果和Lambda表达式查询的结果是一样滴,以上便是Linq和Lambda的查询。LoadData()方法制造的10000条数据可以看作SQL查询得到的结果集。
那么,LINQ实现分页应该怎么写呢?谈到这儿,总算是谈到了LINQ分页,其实LINQ分页只需要用好两个关键字,一个叫做:Skip、另一个叫做:Take
其中Take关键字微软的定义为:
//
// 摘要:
// 从序列的开头返回指定数量的连续元素。
//
// 参数:
// source:
// 要从其返回元素的序列。
//
// count:
// 要返回的元素数量。
//
// 类型参数:
// TSource:
// source 中的元素的类型。
//
// 返回结果:
// 一个 System.Collections.Generic.IEnumerable<T>,包含输入序列开头的指定数量的元素。
//
// 异常:
// System.ArgumentNullException:
// source 为 null。
public static IEnumerable<TSource> Take<TSource>(this IEnumerable<TSource> source, int count);
其中Skip关键字微软的定义为:
//
// 摘要:
// 跳过序列中指定数量的元素,然后返回剩余的元素。
//
// 参数:
// source:
// 一个 System.Collections.Generic.IEnumerable<T>,用于从中返回元素。
//
// count:
// 返回剩余元素前要跳过的元素数量。
//
// 类型参数:
// TSource:
// source 中的元素的类型。
//
// 返回结果:
// 一个 System.Collections.Generic.IEnumerable<T>,包含输入序列中指定索引后出现的元素。
//
// 异常:
// System.ArgumentNullException:
// source 为 null。
public static IEnumerable<TSource> Skip<TSource>(this IEnumerable<TSource> source, int count);
看到上述微软给出的定义,我突然想到一个面试题,在此分享给大家,大家也看看他们之间是不是有类似之处,是不是非常雷同呢?
写出一条Sql语句:取出表A中第31到第40记录(SQLServer,以自动增长的ID
作为主键,注意:ID可能不是连续的。
上述斜线的面试题如果用LINQ中的SKIP和TAKE怎么实现呢?
基于上述查询结果,我们接着来查询第31到第40记录,示例代码如下:
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
//--------------------LINQ查询如下--------------------//
var Result = from r in Lst
where r.Age>=9000 && r.Age<=9100 && r.UserName.Contains("龙") &&r.UserName.StartsWith("天才")&&r.UserName.EndsWith("卧龙") orderby r.Age descending
select r;
var Lst_2 = new List<Preson>();
foreach (var A in Result)//需要进行一次Foreach操作哦
{
Lst_2.Add(A);
}
Lst = Lst_2;
Lst = Lst.Skip(30).Take(10).ToList();
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
Lst.Skip(30)就是跳过前30行记录,Take(10)就是取10行记录,也就是取出31至40之间的记录。 在此我们作个假设:如果PageSize代表页容量(假设每页有十条数据)、PageIndex代表页码,上述面试题无非就是让我们取出第4页的数据。 其示例代码如下:
static void Main(string[] args)
{
List<Preson> Lst = LoadData();
//--------------------LINQ查询如下--------------------//
var Result = from r in Lst
where r.Age>=9000 && r.Age<=9100 && r.UserName.Contains("龙") &&r.UserName.StartsWith("天才")&&r.UserName.EndsWith("卧龙") orderby r.Age descending
select r;
var Lst_2 = new List<Preson>();
foreach (var A in Result)//需要进行一次Foreach操作哦
{
Lst_2.Add(A);
}
Lst = Lst_2;
//Lst = Lst.Skip(30).Take(10).ToList();
int PageSize = 10;//页容量10,每页十条数据
int PageIndex = 1;//假设页码是从1开始的
//根据分析得知:我们现在要取第4页的数据,所以PageIndex=4,作如下赋值
PageIndex = 4;
Lst = Lst.Skip((PageIndex-1)*PageSize).Take(PageSize).ToList();
foreach (var P in Lst)
{
Console.WriteLine("姓名:"+P.UserName + " 性别:" + P.Sex + " 年龄:" + P.Age);
}
Console.Read();
}
上述代码已经作了详细注释,在此不作解读了!
至此:C#SQL优化和LINQ查询、分页就讲完了,感谢您的查阅,谢谢!
我想说的是:我么应当根据需求的不同,灵活选择SQL查询、分页还是LINQ查询分页。如果您的数据量很大,并且系统要求效率高,不需要实时刷新,那么您可以采用LINQ查询。
不管多牛逼的LINQ查询,在有数据库的前提下,其数据源都是通过SQL查询得到的,我们之所以用LINQ查询分页,无非就是为了减少和数据库之间的交互,减少了和数据库之间的交互,性能自然会提升。
怎么用,自己看着办吧!嘿嘿。
最后做一个总结:
#region Linq 分页
/// <summary>
///
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="Source"></param>
/// <param name="PageSize">页容量</param>
/// <param name="CurrentPageIndex">页码索引 0 代表 第一页</param>
/// <returns></returns>
public static IQueryable<T> Pagination<T>(IOrderedQueryable<T> Source, int PageSize, int CurrentPageIndex)
{
return Source.Skip(CurrentPageIndex * PageSize).Take(PageSize);
}
#endregion
@陈卧龙的博客

