
来源: 缓存服务新思路,创建动态查询的缓存 – hubro – 博客园
本方案实现了客户端对服务端缓存数据任意查找,和使用本地缓存效果一样
先看看常用缓存的形式
本地缓存
缓存在当前应用程序内存中,通常以静态变量存储,它可以是任何对象,一个值,一个集合都行
因为是在当前程序中,能很好得到控制,创建,访问都很好办,特别是集合,通过集合查询语法或自已写的算法很好过滤,取出想要的结果
然而这些数据需要多程序共用,那么需要把它集中放在一个地方,供多应用程序调用
分布式缓存
分布式缓存就是为了解决二级缓存不能解决的问题,把数据放在独立的服务器上,提供访问接口,供不同客户端程序调用
一般分为两部份,服务端,客户端接口,通过统一的客户端接口,从服务端获取数据
因为达成了统一访问,没有业务关联,因此,缓存获取方式为KEY值的形式,通过KEY值读写数据,很像一个字典,KEY为唯一,值为object
在获取到这个object后,转换为指定的本地业务对象
然而带来的问题,所有值都为object,在获取到后才能转换为本地业务对象,如果存入的是一个对象集合,要获取其中某个条件的一项
那得每次把整个集合object获取到本地再换为集合再进行查找,这样意味着多了不必要的数据传输,因此一般不会这么做
问题来了,从分布式缓存服务器中,没法按业务要求对这样的数据进行查询,通常这样的需要,替代做法是搜索引擎形式,随之带来的一系列问题…
或还有更简单的方法,对指定业务数据查询写个查询接口,这样也能满足需求,但是每种查询需求都需要写个接口,很是麻烦
能不能直接把查询条件传给缓存服务端,让服务端用条件过滤数据?
理论是可以的,只需要服务端能识别解析就能,要达成这样的条件,服务端必须能识别业务对象
这样意味着,服务端的缓存对象是由业务创建的,需要对服务端进行开发
要实现这样的系统,关键点是在查询条件传输,在本地对集合查询,一般使用Linq扩展方法,使用lambda生成筛选委托
如果能把lambda表达式传过去,服务端再解析成筛选委托就能实现目的了
实现命令解析
由于lambda表达式很复杂,不能直接序列化,是没法直接传输的,需要解析成能传输的对象,那么,要做的过程表示为
客户端:lambda查询=>解析lambda=>转换为命令对象=>序列化发送命令
服务端:接收命令反序列化=>转换为lambda=>创建查询
lambda解析参考 解析lambda实现完整查询
lambda动态创建参考 http://www.cnblogs.com/libbybyron/articles/4134494.html
服务端按业务数据缓存
服务端使用同样的业务模型创建二级缓存,在接收到命令转换为lambda查询后,很轻松就能实现内存查询了
于是整体结构设计为
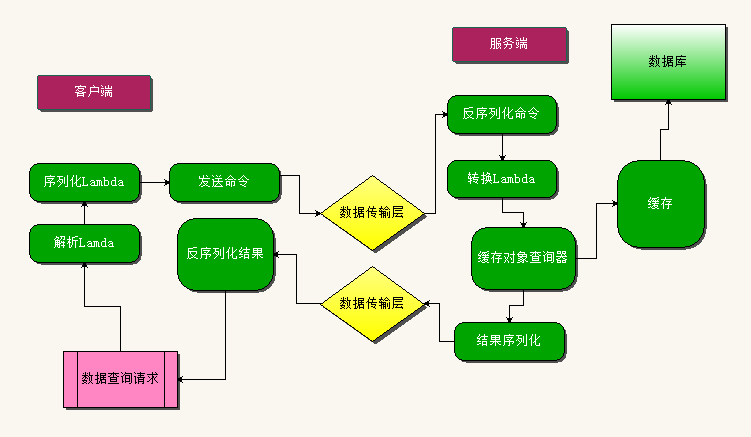
数据传输层
为了增加查询效率,传输层用长TCP连接,使用连接池的概念,启动后保持指定的连接数,有请求时找其中一个连接与服务器通讯,如果都满了,再创建新的连接
同时自动释放长时间不用的连接,通过这样处理,比HTTP接口,SERVICE/WCF连接效率高很多
分布式方案
因为缓存是服务器主动创建的,做成分布式,需要客户端知道服务端有哪些缓存,因此需要做一个缓存类型和服务器映射
查询缓存时,根据映射去指定的服务器查询
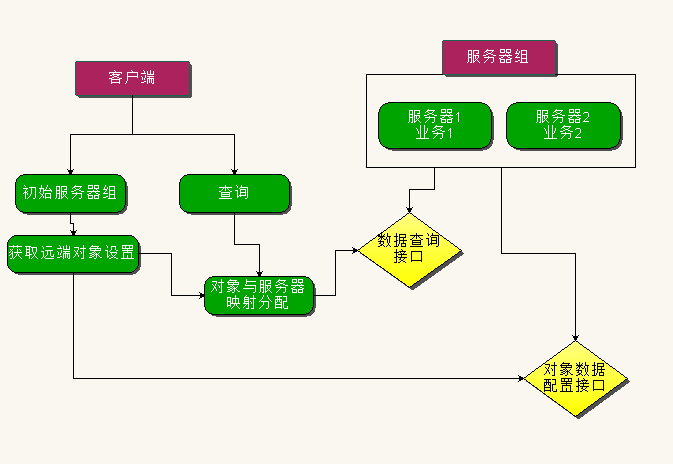
通过这样设计的缓存系统,大大增加了开发效率和使用便捷性,并与业务衔接紧密
整体涉及到的东西比较多也比较复杂,就不在这里写代码实现了,需要框架支持,这里只放上开发完成的测试DEMO
测试DEMO下载:点击下载
调用示例:http://119.10.29.11:8080/page/Cache2.aspx

