
来源: 你真的了解字典(Dictionary)吗? – 码农阿宇 – 博客园
从一道亲身经历的面试题说起
半年前,我参加我现在所在公司的面试,面试官给了一道题,说有一个Y形的链表,知道起始节点,找出交叉节点.
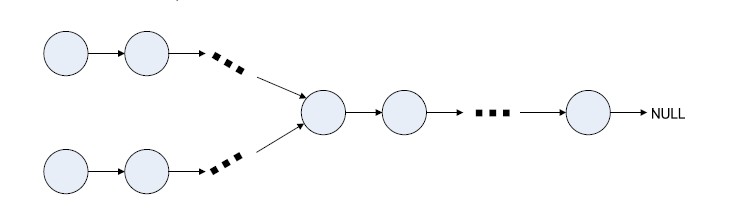
为了便于描述,我把上面的那条线路称为线路1,下面的称为线路2.
思路1#
先判断线路1的第一个节点的下级节点是否是线路2的第一个节点,如果不是,再判断是不是线路2的第二个,如果也不是,判断是不是第三个节点,一直到最后一个.
如果第一轮没找到,再按以上思路处理线路一的第二个节点,第三个,第四个… 找到为止.
时间复杂度n2,相信如果我用的是这种方法,可肯定被Pass了.
思路2#
首先,我遍历线路2的所有节点,把节点的索引作为key,下级节点索引作为value存入字典中.
然后,遍历线路1中节点,判断字典中是否包含该节点的下级节点索引的key,即dic.ContainsKey((node.next) ,如果包含,那么该下级节点就是交叉节点了.
时间复杂度是n.
那么问题来了,面试官问我了,为什么时间复杂度n呢?你有没有研究过字典的ContainsKey这个方法呢?难道它不是通过遍历内部元素来判断Key是否存在的呢?如果是的话,那时间复杂度还是n2才是呀?
我当时支支吾吾,确实不明白字典的工作原理,厚着面皮说 “不是的,它是通过哈希表直接拿出来的,不用遍历”,面试官这边是敷衍过去了,但在我心里却留下了一个谜,已经入职半年多了,欠下的技术债是时候还了.
带着问题来阅读
在看这篇文章前,不知道您使用字典的时候是否有过这样的疑问.
- 字典为什么能无限地Add呢?
- 从字典中取Item速度非常快,为什么呢?
- 初始化字典可以指定字典容量,这是否多余呢?
- 字典的桶
buckets长度为素数,为什么呢?
不管您以前有没有在心里问过自己这些问题,也不管您是否已经有了自己得答案,都让我们带着这几个问题接着往下走.
从哈希函数说起
什么是哈希函数?
哈希函数又称散列函数,是一种从任何一种数据中创建小的数字“指纹”的方法。
下面,我们看看JDK中Sting.GetHashCode()方法.
public int hashCode() {
int h = hash;
//hash default value : 0
if (h == 0 && value.length > 0) {
//value : char storage
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
可以看到,无论多长的字符串,最终都会返回一个int值,当哈希函数确定的情况下,任何一个字符串的哈希值都是唯一且确定的.
当然,这里只是找了一种最简单的字符数哈希值求法,理论上只要能把一个对象转换成唯一且确定值的函数,我们都可以把它称之为哈希函数.
这是哈希函数的示意图.

所以,一个对象的哈希值是确定且唯一的!.
字典
如何把哈希值和在集合中我们要的数据的地址关联起来呢?解开这个疑惑前我来看看一个这样不怎么恰当的例子:
有一天,我不小心干了什么坏事,警察叔叔没有逮到我本人,但是他知道是一个叫阿宇的干的,他要找我肯定先去我家,他怎么知道我家的地址呢?他不可能在全中国的家庭一个个去遍历,敲门,问阿宇是你们家的熊孩子吗?
正常应该是通过我的名字,找到我的身份证号码,然后我的身份证上登记着我的家庭地址(我们假设一个名字只能找到一张身份证).
阿宇—–> 身份证(身份证号码,家庭住址)——>我家
我们就可以把由阿宇找到身份证号码的过程,理解为哈希函数,身份证存储着我的号码的同时,也存储着我家的地址,身份证这个角色在字典中就是 bucket,它起一个桥梁作用,当有人要找阿宇家在哪时,直接问它,准备错的,字典中,bucket存储着数据的内存地址(索引),我们要知道key对应的数据的内存地址,问buckets要就对了.
key—>bucket的过程 ~= 阿宇—–>身份证 的过程.

警察叔叔通过家庭住址找到了我家之后,我家除了住我,还住着我爸,我妈,他敲门的时候,是我爸开门,于是问我爸爸,阿宇在哪,我爸不知道,我爸便问我妈,儿子在哪?我妈告诉警察叔叔,我在书房呢.很好,警察叔叔就这样把我给逮住了.
字典也是这样,因为key的哈希值范围很大的,我们不可能声明一个这么大的数组作为buckets,这样就太浪费了,我们做法时HashCode%BucketSize作为bucket的索引.
假设Bucket的长度3,那么当key1的HashCode为2时,它数据地址就问buckets2要,当key2的HashCode为5时,它的数据地址也是问buckets2要的.
这就导致同一个bucket可能有多个key对应,即下图中的Johon Smith和Sandra Dee,但是bucket只能记录一个内存地址(索引),也就是警察叔叔通过家庭地址找到我家时,正常来说,只有一个人过来开门,那么,如何找到也在这个家里的我的呢?我爸记录这我妈在厨房,我妈记录着我在书房,就这样,我就被揪出来了,我爸,我妈,我 就是字典中的一个entry.

如果有一天,我妈妈老来得子又生了一个小宝宝,怎么办呢?很简单,我妈记录小宝宝的位置,那么我的只能巴结小宝宝,让小宝宝来记录我的位置了.


既然大的原理明白了,是不是要看看源码,来研究研究代码中字典怎么实现的呢?
DictionaryMini
上次在苏州参加苏州微软技术俱乐部成立大会时,有幸参加了蒋金楠 老师讲的Asp .net core框架解密,蒋老师有句话让我印象很深刻,”学好一门技术的最好的方法,就是模仿它的样子,自己造一个出来”于是他弄了个Asp .net core mini,所以我效仿蒋老师,弄了个DictionaryMini
其源代码我放在了Github仓库,有兴趣的可以看看:https://github.com/liuzhenyulive/DictionaryMini
我觉得字典这几个方面值得了解一下:
- 数据存储的最小单元的数据结构
- 字典的初始化
- 添加新元素
- 字典的扩容
- 移除元素
字典中还有其他功能,但我相信,只要弄明白的这几个方面的工作原理,我们也就恰中肯綮,他么问题也就迎刃而解了.
数据存储的最小单元(Entry)的数据结构#
private struct Entry
{
public int HashCode;
public int Next;
public TKey Key;
public TValue Value;
}
一个Entry包括该key的HashCode,以及下个Entry的索引Next,该键值对的Key以及数据Vaule.
字典初始化#
private void Initialize(int capacity)
{
int size = HashHelpersMini.GetPrime(capacity);
_buckets = new int[size];
for (int i = 0; i < _buckets.Length; i++)
{
_buckets[i] = -1;
}
_entries = new Entry[size];
_freeList = -1;
}
字典初始化时,首先要创建int数组,分别作为buckets和entries,其中buckets的index是key的哈希值%size,它的value是数据在entries中的index,我们要取的数据就存在entries中.当某一个bucket没有指向任何entry时,它的value为-1.
另外,很有意思得一点,buckets的数组长度是多少呢?这个我研究了挺久,发现取的是大于capacity的最小质数.
添加新元素#
private void Insert(TKey key, TValue value, bool add)
{
if (key == null)
{
throw new ArgumentNullException();
}
//如果buckets为空,则重新初始化字典.
if (_buckets == null) Initialize(0);
//获取传入key的 哈希值
var hashCode = _comparer.GetHashCode(key);
//把hashCode%size的值作为目标Bucket的Index.
var targetBucket = hashCode % _buckets.Length;
//遍历判断传入的key对应的值是否已经添加字典中
for (int i = _buckets[targetBucket]; i > 0; i = _entries[i].Next)
{
if (_entries[i].HashCode == hashCode && _comparer.Equals(_entries[i].Key, key))
{
//当add为true时,直接抛出异常,告诉给定的值已存在在字典中.
if (add)
{
throw new Exception("给定的关键字已存在!");
}
//当add为false时,重新赋值并退出.
_entries[i].Value = value;
return;
}
}
//表示本次存储数据的数据在Entries中的索引
int index;
//当有数据被Remove时,freeCount会加1
if (_freeCount > 0)
{
//freeList为上一个移除数据的Entries的索引,这样能尽量地让连续的Entries都利用起来.
index = _freeList;
_freeList = _entries[index].Next;
_freeCount--;
}
else
{
//当已使用的Entry的数据等于Entries的长度时,说明字典里的数据已经存满了,需要对字典进行扩容,Resize.
if (_count == _entries.Length)
{
Resize();
targetBucket = hashCode % _buckets.Length;
}
//默认取未使用的第一个
index = _count;
_count++;
}
//对Entries进行赋值
_entries[index].HashCode = hashCode;
_entries[index].Next = _buckets[targetBucket];
_entries[index].Key = key;
_entries[index].Value = value;
//用buckets来登记数据在Entries中的索引.
_buckets[targetBucket] = index;
}
字典的扩容#
private void Resize()
{
//获取大于当前size的最小质数
Resize(HashHelpersMini.GetPrime(_count), false);
}
private void Resize(int newSize, bool foreNewHashCodes)
{
var newBuckets = new int[newSize];
//把所有buckets设置-1
for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1;
var newEntries = new Entry[newSize];
//把旧的的Enties中的数据拷贝到新的Entires数组中.
Array.Copy(_entries, 0, newEntries, 0, _count);
if (foreNewHashCodes)
{
for (int i = 0; i < _count; i++)
{
if (newEntries[i].HashCode != -1)
{
newEntries[i].HashCode = _comparer.GetHashCode(newEntries[i].Key);
}
}
}
//重新对新的bucket赋值.
for (int i = 0; i < _count; i++)
{
if (newEntries[i].HashCode > 0)
{
int bucket = newEntries[i].HashCode % newSize;
newEntries[i].Next = newBuckets[bucket];
newBuckets[bucket] = i;
}
}
_buckets = newBuckets;
_entries = newEntries;
}
移除元素#
//通过key移除指定的item
public bool Remove(TKey key)
{
if (key == null)
throw new Exception();
if (_buckets != null)
{
//获取该key的HashCode
int hashCode = _comparer.GetHashCode(key);
//获取bucket的索引
int bucket = hashCode % _buckets.Length;
int last = -1;
for (int i = _buckets[bucket]; i >= 0; last = i, i = _entries[i].Next)
{
if (_entries[i].HashCode == hashCode && _comparer.Equals(_entries[i].Key, key))
{
if (last < 0)
{
_buckets[bucket] = _entries[i].Next;
}
else
{
_entries[last].Next = _entries[i].Next;
}
//把要移除的元素置空.
_entries[i].HashCode = -1;
_entries[i].Next = _freeList;
_entries[i].Key = default(TKey);
_entries[i].Value = default(TValue);
//把该释放的索引记录在freeList中
_freeList = i;
//把空Entry的数量加1
_freeCount++;
return true;
}
}
}
return false;
}
我对.Net中的Dictionary的源码进行了精简,做了一个DictionaryMini,有兴趣的可以到我的github查看相关代码.
https://github.com/liuzhenyulive/DictionaryMini
答疑时间
字典为什么能无限地Add呢#
向Dictionary中添加元素时,会有一步进行判断字典是否满了,如果满了,会用Resize对字典进行自动地扩容,所以字典不会向数组那样有固定的容量.
为什么从字典中取数据这么快#
Key–>HashCode–>HashCode%Size–>Bucket Index–>Bucket–>Entry Index–>Value
整个过程都没有通过遍历来查找数据,一步到下一步的目的性时非常明确的,所以取数据的过程非常快.
初始化字典可以指定字典容量,这是否多余呢#
前面说过,当向字典中插入数据时,如果字典已满,会自动地给字典Resize扩容.
扩容的标准时会把大于当前前容量的最小质数作为当前字典的容量,比如,当我们的字典最终存储的元素为15个时,会有这样的一个过程.
new Dictionary()——————->size:3
字典添加低3个元素—->Resize—>size:7
字典添加低7个元素—->Resize—>size:11
字典添加低11个元素—>Resize—>size:23
可以看到一共进行了三次次Resize,如果我们预先知道最终字典要存储15个元素,那么我们可以用new Dictionary(15)来创建一个字典.
new Dictionary(15)———->size:23
这样就不需要进行Resize了,可以想象,每次Resize都是消耗一定的时间资源的,需要把OldEnties Copy to NewEntries 所以我们在创建字典时,如果知道字典的中要存储的字典的元素个数,在创建字典时,就传入capacity,免去了中间的Resize进行扩容.
Tips:
即使指定字典容量capacity,后期如果添加的元素超过这个数量,字典也是会自动扩容的.
为什么字典的桶buckets 长度为素数#
我们假设有这样的一系列keys,他们的分布范围时K={ 0, 1,…, 100 },又假设某一个buckets的长度m=12,因为3是12的一个因子,当key时3的倍数时,那么targetBucket也将会是3的倍数.
Keys {0,12,24,36,...}
TargetBucket将会是0.
Keys {3,15,27,39,...}
TargetBucket将会是3.
Keys {6,18,30,42,...}
TargetBucket将会是6.
Keys {9,21,33,45,...}
TargetBucket将会是9.
如果Key的值是均匀分布的(K中的每一个Key中出现的可能性相同),那么Buckets的Length就没有那么重要了,但是如果Key不是均匀分布呢?
想象一下,如果Key在3的倍数时出现的可能性特别大,其他的基本不出现,TargetBucket那些不是3的倍数的索引就基本不会存储什么数据了,这样就可能有2/3的Bucket空着,数据大量第聚集在0,3,6,9中.
这种情况其实时很常见的。 例如,又一种场景,您根据对象存储在内存中的位置来跟踪对象,如果你的计算机的字节大小是4,而且你的Buckets的长度也为4,那么所有的内存地址都会时4的倍数,也就是说key都是4的倍数,它的HashCode也将会时4的倍数,导致所有的数据都会存储在TargetBucket=0(Key%4=0)的bucket中,而剩下的3/4的Buckets都是空的. 这样数据分布就非常不均匀了.
K中的每一个key如果与Buckets的长度m有公因子,那么该数据就会存储在这个公因子的倍数为索引的bucket中.为了让数据尽可能地均匀地分布在Buckets中,我们要尽量减少m和K中的key的有公因子出现的可能性.那么,把Bucket的长度设为质数就是最佳选择了,因为质数的因子时最少的.这就是为什么每次利用Resize给字典扩容时会取大于当前size的最小质数的原因.
确实,这一块可能有点难以理解,我花了好几天才研究明白,如果小伙伴们没有看懂建议看看这里.
https://cs.stackexchange.com/questions/11029/why-is-it-best-to-use-a-prime-number-as-a-mod-in-a-hashing-function/64191#64191
最后,感谢大家耐着性子把这篇文章看完,欢迎fork DictionaryMini进行进一步的研究,谢谢大家的支持.
https://github.com/liuzhenyulive/DictionaryMini

