
[转载]QQ空间日志抓器—我的第一个winform小应用(多线程,附源码) – think_fish – 博客园.
(好几个博友都提到了假死的问题,可能是我之前测试的环境网络状态良好,然后机器配置还可以,所以没有看到假死的现象。刚刚换了个环境,假死比较明显。所以各位敬请期待多线程的版本。)
首先非常感谢各位前辈的指点,将程序改成了多线程版本,假死问题已经解决了。对代码也做了部分优化,之前用单独的一个请求去抓第一页然后再用另外的请求去抓取第一页以后的也做了下修改,突然发现用后面的方法一样可以抓取到第一页的数据,所以第一部就是多此一举了。
忙豁了近两个星期,终于完工了,可能对于多数人来说这个应用没有什么价值也没有什么挑战性,但对于初次接触winform的我来说还算是小有成就感的。
先来两张程序的截图吧
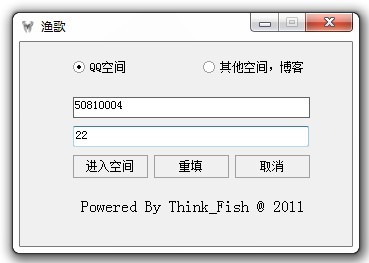
界 面比较简单,现在复杂的也不会。还有一个其他空间的单选按钮,这个功能还没有实现,是准备后面拓展功能的。两个文本框第一个为输入QQ号码的,第二个是输 入日志的总页数的,日志的页数分析了很久实在没有找到,所以只好出此下策让用户自己输入了。这个抓取器不能抓取设置了访问权限的空间,哪怕知道问题的答案 也没有办法获取。之后考虑加一个密码输入框,再模拟一个空间主人的权限去抓取试试。
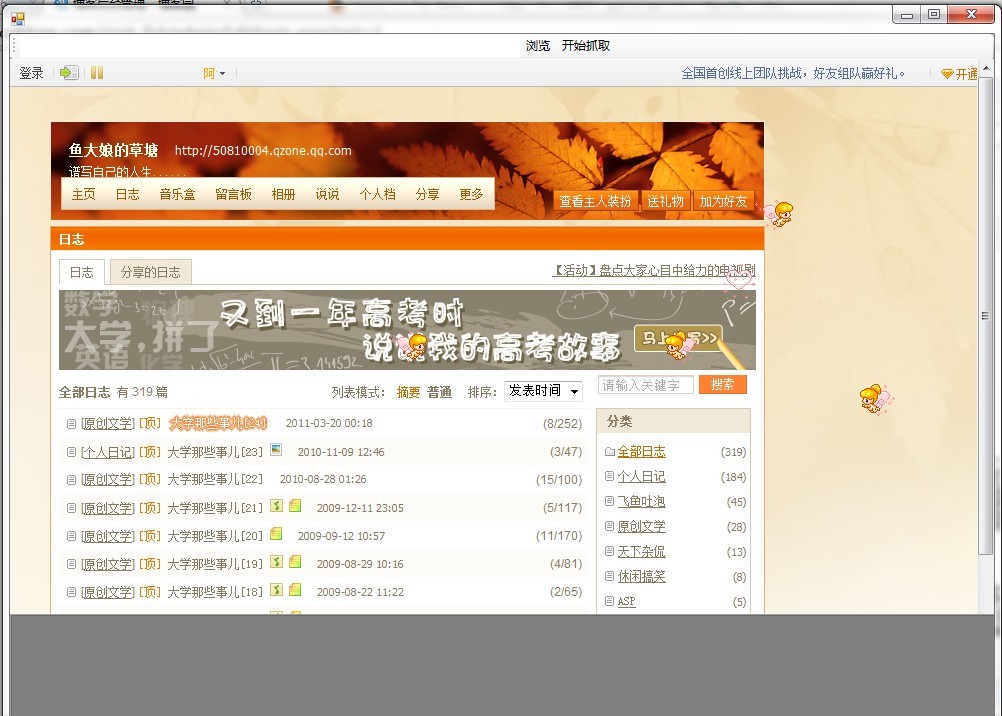
输入QQ号与日志页数(对于QQ号与日志页数都还没有做验证的-_-!!),页面会自动跳转到空间的日志列表页,点击如上图顶端的开始抓取,程序就会自动运行了。 下面的灰色部分是显示日志抓取的进度。
敲代码的时间比较短,基本上大量的时间都花在了分析上面。QQ空间属于比较另类的博客,整个页面就是一个大的母版页中间的日志列表,日志内容以及其他的相 册什么的全部都是用ajax请求动态加载的,所以之前一直觉得奇怪QQ空间上并没有多大的图片或者什么内容为什么那么耗资源。ajax请求动态加载的内容 都是存在内存里面的。
最开始是准备用Console程序来解决这个问题,因为之前因为工作的关系写过一个小蜘蛛,心想改一改应该就差不多了,但因为之前的程序逻辑相对比较复杂,要改也不知道从何改起,然后跟博友交流之后选择了用webBrowser。
WebBrowser的默认属性DocumentText直接就可以把页面中的文本获取到,但是问题来了,这个根本无法获取到动态加载的内容。在 firebug下看,加载的内容都是在一个iframe里面,这时候就一直以为是直接获取iframe的src就可以了。然后想了很多办法想用 webBrowser如何获取iframe里面的内容。就这个耗了两个晚上的时间。这时都还没有想到这边iframe都是ajax动态添加的,所以想要获 取到加载后的iframe也没有办法实现。
再继续在网上寻找方案,偶然间看到一个问题,如果获取动态加载的所有内容,虽然在那个问题中没有获取到答案,但是基本肯定了QQ空间的日志部分就是动态加 载的。这时候就静下心来在firebug下仔细的分析发送的请求,自己试着写了个GET请求,把firebug下看到的参数拼成个字符串,果然获取到了日 志内容,但接着而来的问题就是获取到的内容是加密过的,GZIP加密,继续在网上找方法解密。解密成功后就是N多的正则匹配了。废话不多说,先上一个流程 图。

个人觉得代码中最关键的部分就是发送请求,然后分析HTML用正则匹配出自己想要的部分。
///
/// 发送一个GET请求
///
///请求的url地址 ///请求的参数集合 ///请求的编码格式 ///接收的编码格式 ///
public static string SendGetRequest(string url, NameValueCollection parameters, Encoding reqencode, Encoding resencode)
{
StringBuilder parassb = new StringBuilder();
if (null != parameters)
{
foreach (string key in parameters.Keys)
{
if (parassb.Length > 0)
parassb.Append("&");
parassb.AppendFormat("{0}={1}", HttpUtility.UrlEncode(key), HttpUtility.UrlEncode(parameters[key]));
}
}
if (parassb.Length > 0)
{
url += "?" + parassb;
}
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(url);
req.Method = "GET";
req.Accept = "*/*";
req.Headers.Add("Accept-Encoding: gzip");
req.KeepAlive = true;
req.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)";
req.MaximumAutomaticRedirections = 3;
req.Timeout = 600000;
string result = String.Empty;
//读取回应
HttpWebResponse response = (HttpWebResponse)req.GetResponse();
// 将回应全部读入一个 MemoryStream:
MemoryStream ms = new MemoryStream();
Stream res = response.GetResponseStream();
byte[] buffer = new byte[8192];
while (true)
{
int read = res.Read(buffer, 0, 8192);
if (read == 0)
{
// 如果服务器用的是 gzip 的话,只能靠读不出更多数据来判断是否已经读完
Console.WriteLine("Response is terminated due to zero byte reception.");
break;
}
else
{
ms.Write(buffer, 0, read);
}
}
//ms倒回开头
ms.Seek(0, SeekOrigin.Begin);
// 用 GZipInputStream 包裹:
GZipInputStream gzip = new GZipInputStream(ms);
MemoryStream ms2 = new MemoryStream();
try
{
byte[] buffer1 = new byte[1]; // 一点一点读——因为这个服务器的gzip没有Footer,读到结尾的时候会出错,所以为了把最后一个字节都读出来,只能一点一点读
while (true)
{
int read = gzip.Read(buffer1, 0, 1);
if (read == 0) break;
ms2.Write(buffer1, 0, read);
}
}
catch (Exception sa)
{
Console.WriteLine("Exception! " + sa.ToString());
}
Console.WriteLine("Unzipped.");
// 将 ms2(解压后的内容)保存到文件
//, System.Text.Encoding.GetEncoding("gb2312")
Stream fs;
fs = File.Create("r00000000000.txt");
ms2.Seek(0, SeekOrigin.Begin);
ms2.WriteTo(fs);
fs.Close();
//using (StreamReader reader = new StreamReader(req.GetResponse().GetResponseStream(), resencode))
//{
// result = reader.ReadToEnd();
//}
result = System.Text.Encoding.GetEncoding("GB2312").GetString(ms2.ToArray());
return result;
}
上面的代码就是发送GET请求并获取HTML的一个方法,其中包括了解压的过程。解压的代码部分我没有仔细研究,但是个人认为这样做过于繁琐,有时间会要做进一步的优化。日志列表与日志的主体内容都用的这个方法。解压需要添加如下的引用
using System.IO.Compression; using ICSharpCode.SharpZipLib.Zip; using ICSharpCode.SharpZipLib.Checksums; using ICSharpCode.SharpZipLib.GZip;
这个日志取器有一个问题就是如果对方的空间设置了访问权限,比如需要密码才能访问,或本来就没有该问权限的是没有办法抓取下来的,无法获取到列表页的ID,返回的HTML中提示没有权限。这个问题可能也还需要一段时间来分析。
现 在我把源码放上来,各位要是有兴趣的可以下载看看,有什么问题或者有什么好的建议非常希望大家能反馈给我,我很想得到高手们的一些指点。 对于这个应用其间还存在很多的不足,但是因为时间的关系,先在这里总结一下,主体部分的抓取分析还是出来了。真诚的希望各位能多给意见,希望能从中再学习 到一些更宝贵的经验。小弟先在此谢过了。
渔歌QQ空间日志抓取器源码下载/Files/think_fish/QQZoneApplicantionThread.rar
渔歌QQ空间日志抓取器源码SP1(新增评论抓取功能)下载/Files/think_fish/QQZoneApplicantionSP1.rar

