
[转载]一种精确从文本中提取URL的思路及实现 – 方亮的专栏 – 博客频道 – CSDN.NET.
在今年三四月份,我接受了一个需求:从文本中提取URL。这样的需求,可能算是非常小众的需求了。大概只有QQ、飞信、阿里旺旺等之类的即时通讯软 件存在这样的需求。在研究这个之前,我测试了这些软件这块功能,发现它们这块的功能还是非常弱的。这类软件往往也是恶意URL传播的媒介,如果不能准确识 别出URL,相应的URL安全检测也无从谈起。而且网上也有很多使用正则表达式的方法,可是我看了下,方法简单但是不够精确,对于要求不高的情况可以胜 任,但是如果“坏人”想绕过这种提取也是很方便的。(转载请指明出处)下面也是我在公司内部做的一次分享的内容:
URL介绍
全称:Uniform Resource Locators。
- 最常见“最”标准的URL
例子:
http://www.g.cn/
衍生出浏览器可以接受的URL(在地址栏输入的URL首先会被浏览器截获,浏览器可更具其对URL的理解进行相关容错)
协议后对斜杠无要求
http:www.g.cn
http:\www.g.cnhttp:\\/\www.g.cn
……
目前主流IM对最常见“最”标准的URL的识别没有问题,但是对衍生出来的URL都是无法正确识别的。
- 比较常见但是“不标准”(无协议头)URL
例子:
无协议头,无二级域名
例子:g.cn
无协议头,有二级域名www
例子:www.g.cn
无协议头,有二级域名,但是不是www
例子:mp3.g.cn
目前国内主流IM对URL的判别上,在没有协议头(http://等)时,寻找有没有“www.”,如果存在“www.”,则认为其后是URL。
- 比较少见的URL
例子:
格式省略或者特殊的URL
顶级域名后包含“点”
www.g.cn.(同www.g.cn)
部分省略
www.g.cn.?wd=3(同www.g.cn./?wd=3、www.g.cn/?wd=3)
包含用户名和密码的URL
密码不为空
username:password@www.g.cn
密码为空
username:@www.g.cn
目前国内主流IM对这类URL判断是不准确的,如上例只能识别为www.g.cn
- 比较特殊的URL
例子:
完全没有分隔符的
g.cnclick this
可以识别为g.cn,但是国内IM都不会去这么识别
比较难以归类的
mailto:@g.cn以mailto协议标准,这个URL不符合RFC规定,因为mailto:后面@之前应该有“用户名”以http或者ftp协议标准,这个URL是合法的,因为这个URL中用户名位mailto,密码为空。囧啊!

看一下国内一些IM的表现:

- URL标准定义
定义于RFC1738,详细请见http://tools.ietf.org/html/rfc1738具有相似的格式(ftp,http,https,wais,nntp……)
<scheme> ://<user>:<password>@<host>:<port>/<url-path>
“<user>:<password>@”, “:<password>”,“:<port>”,和“/<url-path>” 是可选的。
“<user>:<password>@”可以是“<user>@”(不需要密码),也可以是“<user>:@”(密码为空)。
形式多样的(mailto,news)
形式太多样,定义宽松
一些其他特殊协议(afs……)
要么不用了,要么这份RFC没给出定义,要么很少用。
- 格式相似的协议的URL Scheme的BNF范式
HTTP(用来指定互联网资源)
http://<host>:<port>/<path>?<searchpart>
gopher (用来指定互联网资源,已经很少用了)
gopher://<host>:<port>/<gopher-path>
nntp(网络新闻传输协议)
nntp://<host>:<port>/<newsgroup-name>/<article-number>
telnet(Internet远程登陆服务的标准协议和主要方式)
telnet://<user>:<password>@<host>:<port>/
wais(广域信息查询系统)
wais://<host>:<port>/<database> wais://<host>:<port>/<database>?<search> wais://<host>:<port>/<database>/<wtype>/<wpath>
- 格式相似的协议的URL Scheme的BNF范式
file(描述文件资源)
file://<host>/<path>
prospero(Be used to designate resources that are accessed via the Prospero Directory Servic)
prospero://<host>:<port>/<hsoname>;<field>=<value>
- 形式多样的协议的URL Scheme的BNF范式
news
news:<newsgroup-name>
news:<message-id>
例子:
news:msnews.microsoft.com
mailto
mailto:<rfc822-addr-spec>
例子:
mailto:1@g.cn
- 一些其他特殊协议
afs Andrew File System global file names. mid Message identifiers for electronic mail. cid Content identifiers for MIME body parts. nfs Network File System (NFS) file names. tn3270 Interactive 3270 emulation sessions. mailserver Access to data available from mail servers. z39.50 Access to ANSI Z39.50 services.
- URL的RFC文档对提取URL的帮助
提供了所有的协议头,帮助准确找到URL起始位置提供了http、ftp等协议名定义了各种URL的范式,为准确得提取URL有很大的帮助
如ali-inc.com中的ali-inc部分要求“-”是可选的,且在存在“-”时,要求其左右存在数字或者字母。
如user name和password部分(username:password@g.cn)如果出现“:”、 “@”或“/”时要加密,这将帮助寻找到URL的起始位置(@user:pass@g.cn提取的URL是user:pass@g.cn)。
- 基于以上问题,可以有种折中方案:将URL范式和现在已知的toplabel结合,构成一个新的范式。以下是RFC文档中BNF范式结合实际问题被修改成的正则表达式:
- ((((ftp:|https:|http:)([\Q/\\E])*)|())(((%[0-9a-fA-F][0-9a-fA-F])|([a-zA-Z0-9])|([\Q$-_.+!*‘(),;?&=\E]))+(:((%[0-9a-fA-F][0-9a-fA-F])|([a-zA-Z0-9])|([\Q$-_.+!*’(),;?&=\E]))*)?@)?(((((([a-zA-Z0-9]){1}([a-zA-Z0-9\-])*([a-zA-Z0-9]{1}))|([a-zA-Z0-9]))\.)+(biz|com|edu|gov|info|int|mil|name|net|org|pro|aero|cat|coop|jobs|museum|travel|arpa|root|mobi|post|tel|asia|geo|kid|mail|sco|web|xxx|nato|example|invalid|test|bitnet|csnet|onion|uucp|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cx|cy|cz|de|dj|dk|dm|do|dz|ec|ee|eg|eh|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|um|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw))|([0-9]{1,3}(\.[0-9]{1,3}){3}))(\:([0-9]+))?(([\Q/\\E])+((((%[0-9a-fA-F][0-9a-fA-F])|([a-zA-Z0-9])|([\Q$-_.+\!*‘(),;:@&=\E]))*)(([\Q/\\E])*((%[0-9a-fA-F]{2})|([a-zA-Z0-9])|([\Q$-_.+\!*’(),;:@&=\E]))*)*)(\?((%[0-9a-fA-F]{2})|([a-zA-Z0-9])|([\Q$-_.+!*'(),;:@&=<>#”{}[] ^`~|\/\E]))*)*)*)
看着是不是特别复杂?是的!这将导致效率非常低下。(这是很久前一个做实验的版本,不能保证其准确性)利用这个正则表达式中我们可以发现很多域名,这些域名都是我从某款安全辅助软件的二进制文件中扒下来了。可能有人会认为这个正则效率的瓶颈在匹配这些域名上,其实不是,我做个实验,主要的瓶颈在domainlabel(就是.com等之前的那部分)上,所以优化比较困难。而且这个正则还没考虑一些特殊问题,比如将“。”识别成”.”。
- 域名
- biz|com|edu|gov|info|int|mil|name|net|org|pro|aero|cat|coop|jobs|museum|travel|arpa|root|mobi|post|tel|asia|geo|kid|mail|sco|web|xxx|nato|example|invalid|test|bitnet|csnet|onion|uucp|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cx|cy|cz|de|dj|dk|dm|do|dz|ec|ee|eg|eh|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|um|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw
这个域名还是比较全的,我没有全部测试,只是大致看了下,毕竟是别人总结的,不知道别人是否在里面放了“标记”信息。我曾经担心过xxx这个域名,还搜了下,发现很大
- 国内IM对URL提取的处理
- 解读:
目前对URL的提取思路基本上是先考虑是否存在协议部分(http,ftp等),如果存在协议部分,则认为此协议之后URL可以接受的部分都是URL。这 种方式存在很大的缺陷,如http://1也会被识别为一个URL。而http:g.cn则不会识别为一个完整的URL。
对于不存在协议部分的情况,寻找www.,如果存在www.则认为此串为URL,如:www.1就会被识别为URL,而mp3.g.cn则不会识别为 URL。以mp3.g.cn和www.g.cn为例,.cn为顶级域名,g.cn为一级域名,而mp3.g.cn和www.g.cn都是二级域名。由于一 开始时,人们习惯将二级域名www.g.cn指向了一级域名g.cn,久而久之,人们就认为www.开头的URL为一级域名。我想可能这个是造成目前这种 判断URL的逻辑的原因。 - 上述方法的优缺点
优点:
逻辑简单
效率高
缺点:
判断不准确产生以上优缺点的原因只是寻找http,https,ftp,file,mailto,www这几个关键词。因为关键词少,所以逻辑简单也高效。有利有弊,因为关键词少,也一定程度上影响了URL判断的不准确性。
- 再次对URL进行分析和思考
常见的URL分类:
IP形式: 192.168.1.1,10.20.11.1
Domain形式:g.cn、www.g.cn,mp3.g.cn
观察可以见得:IP形式的URL结构最为简单:4个小于255的数字被.分割;domain形式比较复杂,但是它们有共性:都具有顶级域名.cn。提取URL的大致思路
通过以上的规律,可以发现,使用顶级域名来识别URL比使用协议或者www二级域名的方式要准确,同时辅助以IP鉴别,以求达到最大覆盖。
对前人做了总结和分析后,以下是我设计的提取逻辑
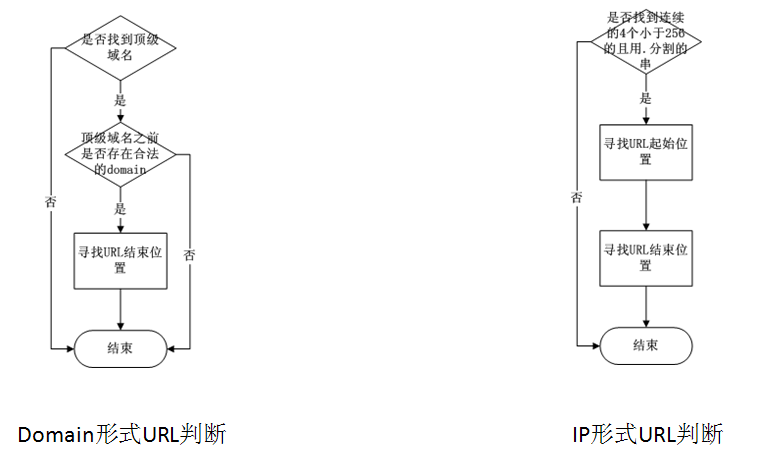

- 提取URL的基本逻辑
- 案例:
| 原始文字 | 提取结果 |
| 这个是g.cn | g.cng.co |
| g.com/index.htm? | g.com/index.htm?s=g.cn |
| s=g.cn1.2.3.456 | 1.2.3.45 |
| g.cn和g.com | g.cn g.com |
| 1.2.3.4.5 | 1.2.3.4 2.3.4.5 |

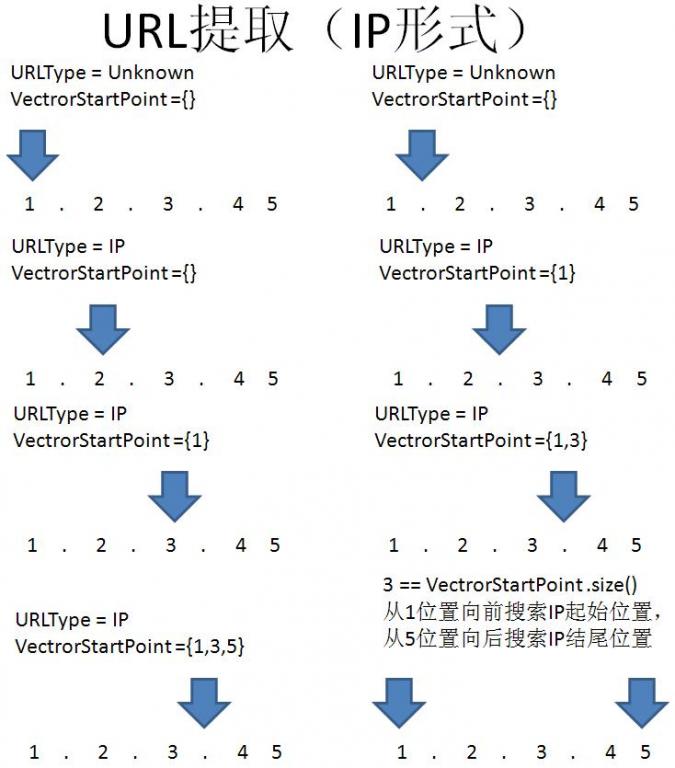
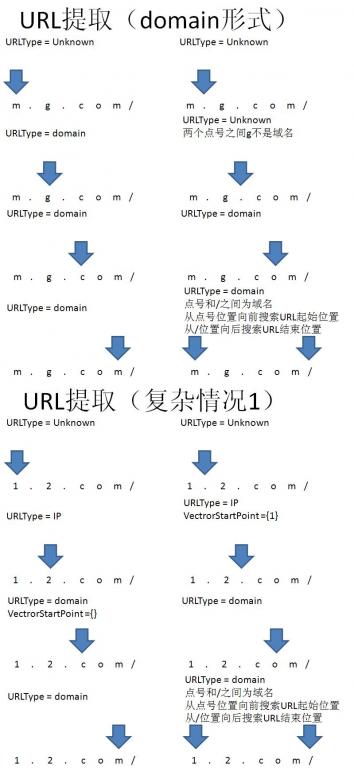
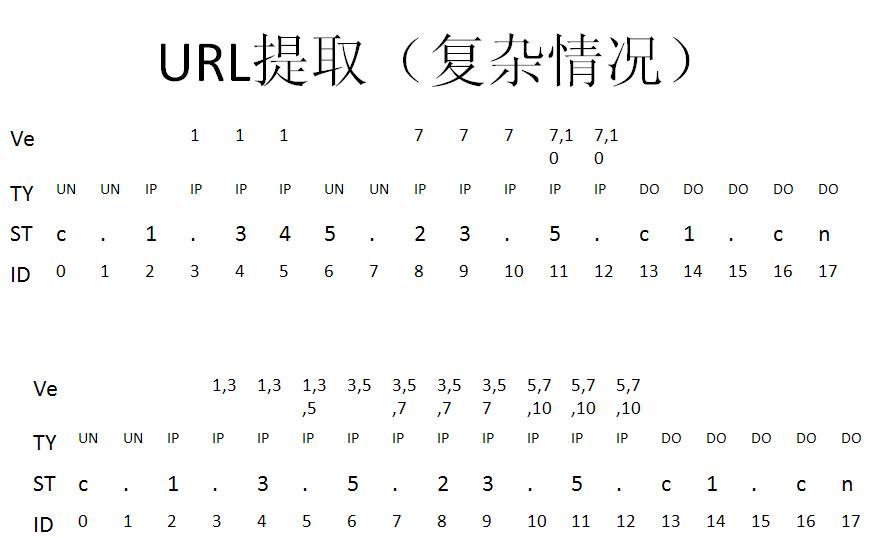
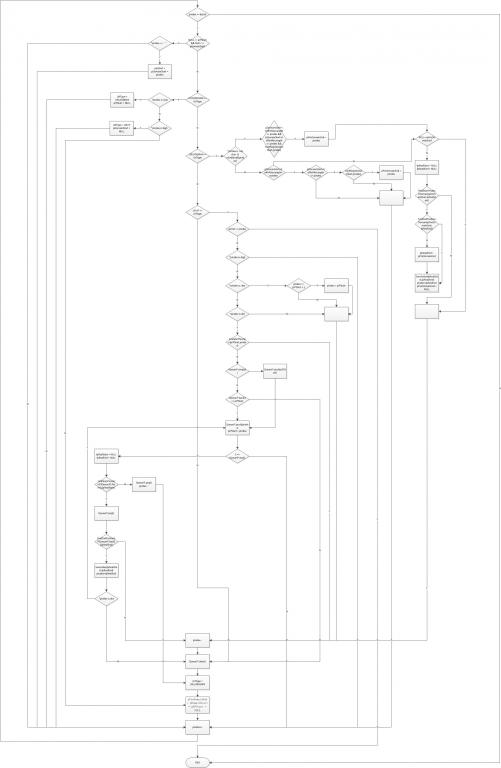
以上是设计的相关逻辑
- 以下是我写的一个demo的提取结果
- 效率
| 最差URL形式 | 最优URL形式 | |
| URL形式 | g.com.12.com.12.com.…… | g.com/1111111111111…… |
| 遍历次数 | 约 (n+1)*n/2(O(n^2)) | 约n(O(1)) |
| URL长度 | 最差耗时(ms/10,000次查找) | 最优耗时(ms/100,000次查找) |
| 200 | 1529 | 400 |
| 410 | 3921 | 578 |
| 810 | 11703 | 953 |
| 1620 | 39463 | 1719 |
| 2450 | 82980 | 2453 |
| 3270 | 143151 | 3219 |
| 4300 | 266341 | 4141 |
- 优化
目前的代码还是存在很多可以优化的地方:因为我采用的递归调用,所以在最差情况下,执行效率大概是26ms一条,所以可以将递归改成循环来解决。我使用的是C++类写的,如果改成C并_fastcall调用约定也会快些。目前这个逻辑大致思路是从头到尾走一遍(不包括回溯),提取出以domain形式和IP形式的URL。在此之前,我设计成以domain形式从头到尾检测一次,和以IP形式从头到尾检测一次,然后综合两个结果的方法,这样的设计会比我目前这样的设计快一个数量级(已测)。

