
来源: SQL-乐观锁,悲观锁之于并发 – 天才卧龙 – 博客园
每次写博客,第一句话都是这样的:程序员很苦逼,除了会写程序,还得会写博客!当然,希望将来的一天,某位老板看到此博客,给你的程序员职工加点薪资吧!因为程序员的世界除了苦逼就是沉默。我眼中的程序员大多都不爱说话,默默承受着编程的巨大压力,除了技术上的交流外,他们不愿意也不擅长和别人交流,更不乐意任何人走进他们的内心!
最近悟出来一个道理,在这儿分享给大家:学历代表你的过去,能力代表你的现在,学习代表你的将来。我们都知道计算机技术发展日新月异,速度惊人的快,你我稍不留神,就会被慢慢淘汰!因此:每日不间断的学习是避免被淘汰的不二法宝。
当然,题外话说多了,咱进入正题!
在多用户环境中,在同一时间可能会有多个用户更新相同的记录,这会产生冲突。这就是著名的并发性问题。
典型的冲突有:
- 丢失更新:一个事务的更新覆盖了其它事务的更新结果,就是所谓的更新丢失。例如:用户A把值从6改为2,用户B把值从2改为6,则用户A丢失了他的更新。
- 脏读:当一个事务读取其它完成一半事务的记录时,就会发生脏读取。例如:用户A,B看到的值都是6,用户B把值改为2,用户A读到的值仍为6。
为了解决这些并发带来的问题。 我们需要引入并发控制机制。
并发控制机制
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。[1]
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。[1] 乐观锁不能解决脏读的问题。
最常用的处理多用户并发访问的方法是加锁。当一个用户锁住数据库中的某个对象时,其他用户就不能再访问该对象。加锁对并发访问的影响体现在锁的粒度上。比如,放在一个表上的锁限制对整个表的并发访问;放在数据页上的锁限制了对整个数据页的访问;放在行上的锁只限制对该行的并发访问。可见行锁粒度最小,并发访问最好,页锁粒度最大,并发访问性能就会越低。
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。[1] 悲观锁假定其他用户企图访问或者改变你正在访问、更改的对象的概率是很高的,因此在悲观锁的环境中,在你开始改变此对象之前就将该对象锁住,并且直到你提交了所作的更改之后才释放锁。悲观的缺陷是不论是页锁还是行锁,加锁的时间可能会很长,这样可能会长时间的锁定一个对象,限制其他用户的访问,也就是说悲观锁的并发访问性不好。
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。[1] 乐观锁不能解决脏读的问题。 乐观锁则认为其他用户企图改变你正在更改的对象的概率是很小的,因此乐观锁直到你准备提交所作的更改时才将对象锁住,当你读取以及改变该对象时并不加锁。可见乐观锁加锁的时间要比悲观锁短,乐观锁可以用较大的锁粒度获得较好的并发访问性能。但是如果第二个用户恰好在第一个用户提交更改之前读取了该对象,那么当他完成了自己的更改进行提交时,数据库就会发现该对象已经变化了,这样,第二个用户不得不重新读取该对象并作出更改。这说明在乐观锁环境中,会增加并发用户读取对象的次数。
从数据库厂商的角度看,使用乐观的页锁是比较好的,尤其在影响很多行的批量操作中可以放比较少的锁,从而降低对资源的需求提高数据库的性能。再考虑聚集索引。在数据库中记录是按照聚集索引的物理顺序存放的。如果使用页锁,当两个用户同时访问更改位于同一数据页上的相邻两行时,其中一个用户必须等待另一个用户释放锁,这会明显地降低系统的性能。interbase和大多数关系数据库一样,采用的是乐观锁,而且读锁是共享的,写锁是排他的。可以在一个读锁上再放置读锁,但不能再放置写锁;你不能在写锁上再放置任何锁。锁是目前解决多用户并发访问的有效手段。
综上所述:在实际生产环境里边,如果并发量不大且不允许脏读,可以使用悲观锁解决并发问题;但如果系统的并发非常大的话,悲观锁定会带来非常大的性能问题,所以我们就要选择乐观锁定的方法.
悲观锁应用
需要使用数据库的锁机制,比如SQL SERVER 的TABLOCKX(排它表锁) 此选项被选中时,SQL Server 将在整个表上置排它锁直至该命令或事务结束。这将防止其他进程读取或修改表中的数据。
SQLServer中使用
Begin Tran
select top 1 @TrainNo=T_NO
from Train_ticket with (UPDLOCK) where S_Flag=0
update Train_ticket
set T_Name=user,
T_Time=getdate(),
S_Flag=1
where T_NO=@TrainNo
commit
我们在查询的时候使用了with (UPDLOCK)选项,在查询记录的时候我们就对记录加上了更新锁,表示我们即将对此记录进行更新. 注意更新锁和共享锁是不冲突的,也就是其他用户还可以查询此表的内容,但是和更新锁和排它锁是冲突的.所以其他的更新用户就会阻塞.
在此:举个简单的例子来说明悲观锁的应用,我们以SQLServer为例进行说明:
假如两个线程同时修改数据库同一条记录,就会导致后一条记录覆盖前一条,从而引发一些问题。
例如:
一个售票系统有一个余票数,客户端每调用一次出票方法,余票数就减一。
情景:
总共300张票,假设两个售票点,恰好在同一时间出票,它们做的操作都是先查询余票数,然后减一。
一般的sql语句:
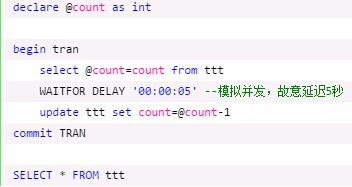
问题就在于,同一时间获取的余票都为300,每个售票点都做了一次更新为299的操作,导致余票少了1,而实际出了两张票。
打开两个查询窗口,分别快速运行以上代码即可看到效果。
因此:在此我们可以采用悲观锁进行解决
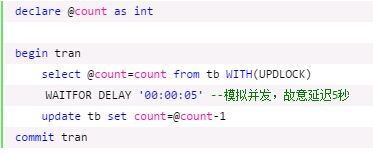
在查询的时候加了一个更新锁,保证自查询起直到事务结束不会被其他事务读取修改,避免产生脏数据。
从而可以解决上述问题。
如果这个售票系统并发太高(例如:春节售票,十月一国庆售票等买票人员并发操作很高),我们采用上述的悲观锁方案就会是系统性能大大降低。譬如:售票员A锁定了这个操作,售票员A在处理这个业务的过程中,又去喝了杯咖啡,在此期间,其他业务员是无法进行订票的,所以…
乐观锁解决方案:
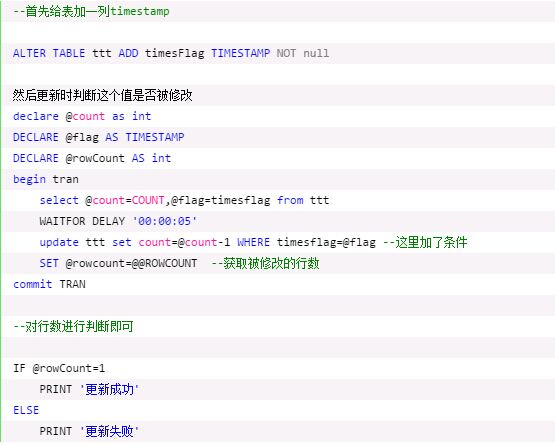
这便是乐观锁的解决方案,可以解决并发带来的数据错误问题,但不保证每一次调用更新都成功,可能会返回’更新失败’
悲观锁和乐观锁
悲观锁一定成功,但在并发量特别大的时候会造成很长堵塞甚至超时,仅适合小并发的情况。
乐观锁不一定每次都修改成功,但能充分利用系统的并发处理机制,在大并发量的时候效率要高很多。
下面以SQLSERVER为例,详情说明悲观锁和乐观锁(请务必看懂关于乐观锁的实现,因为:在实际的系统中,乐观锁应用较为广泛)
锁( locking )
业务逻辑的实现过程中,往往需要保证数据访问的排他性。如在金融系统的日终结算处理中,我们希望针对某个 cut-off 时间点的数据进行处理,而不希望在结算进行过程中(可能是几秒种,也可能是几个小时),数据再发生变化。此时,我们就需要通过一些机制来保证这些数据在某个操作过程中不会被外界修改,这样的机制,在这里,也就是所谓的 “ 锁 ” ,即给我们选定的目标数据上锁,使其无法被其他程序修改。
Hibernate 支持两种锁机制:即通常所说的 “ 悲观锁( Pessimistic Locking ) ”和 “ 乐观锁( Optimistic Locking ) ” 。
悲观锁( Pessimistic Locking )
悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
一个典型的倚赖数据库的悲观锁调用:
select * from account where name=”Erica” for update
这条 sql 语句锁定了 account 表中所有符合检索条件( name=”Erica” )的记录。
本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。
Hibernate 的悲观锁,也是基于数据库的锁机制实现。
Hibernate 的加锁模式有:
Ø LockMode.NONE : 无锁机制。
Ø LockMode.WRITE : Hibernate 在 Insert 和 Update 记录的时候会自动获取。
Ø LockMode.READ : Hibernate 在读取记录的时候会自动获取。
乐观锁( Optimistic Locking )
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依 靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。
如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进 行修改时(如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过 程中(从操作员读出数据、开始修改直至提交修改结果的全过程,甚至还包括操作员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对几百上千个并发,这样的情况将导致怎样的后果。
乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本 Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于(数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
对于上面修改用户帐户信息的例子而言,假设数据库中帐户信息表中有一个version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
1 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
2 在操作员 A 操作的过程中,操作员 B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
3 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
4 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员 A 的操作结果的可能。
从上面的例子可以看出,乐观锁机制避免了长事务中的数据库加锁开销(操作员 A和操作员 B 操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系统整体性能表现.
需要注意的是,乐观锁机制往往基于系统中的数据存储逻辑,因此也具备一定的局限性,如在上例中,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户余额更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。在系统设计阶段,我们应该充分考虑到这些情况出现的可能性,并进行相应调整(如将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途径,而不是将数据库表直接对外公开)。
当然:除了SQL上的锁可以解决数据并发外,我们也可以结合编程语言来实现并发的控制。
在此:以C#为例,我们可以通过代码临界区的定义来实现并发的控制。在C#语言中,定义一个代码临界区使用的关键字是LOCK,在此,小弟不作详细介绍,仅仅作为提示大家,有兴趣的小伙伴可以自行查阅关于C#临界区代码关键字LOCK的使用,本人系列博客:模拟并发/C# 并发处理 锁OR线程
中对LOCK关键字作了部分讲解,有兴趣的小虎斑可以参考下,谢谢、
@陈卧龙的博客

