
来源: 你没见过的分库分表原理解析和解决方案(一) – 薛家明 – 博客园
你没见过的分库分表原理解析和解决方案(一)
高并发三驾马车:分库分表、MQ、缓存。今天给大家带来的就是分库分表的干货解决方案,哪怕你不用我的框架也可以从中听到不一样的结局方案和实现。
一款支持自动分表分库的orm框架easy-query 帮助您解脱跨库带来的复杂业务代码,并且提供多种结局方案和自定义路由来实现比中间件更高性能的数据库访问。
- GITHUB github地址 https://github.com/xuejmnet/easy-query
- GITEE gitee地址 https://gitee.com/xuejm/easy-query
上篇文章简单的带大家了解了框架如何使用分片本章将会以理论为主加实践的方式呈现不一样的分表分库。
介绍
分库分表一直是老生常谈的问题,市面上也有很多人侃侃而谈,但是大部分的说辞都是一样,甚至给不出一个实际的解决方案,本人经过多年的深耕在其他语言里面多年的维护和实践下来秉着happy coding的原则希望更多的人可以了解和认识到该框架并且给大家一个全新的针对分库分表的认识。
我们也经常戏称项目一开始就用了分库分表结果上线没多少数据,并且整个开发体验来说非常繁琐,对于业务而言也是极其不友好,大大拉长开发周期不说,bug也是更加容易产生,针对上述问题该框架给出了一个非常完美的实现来极大程度上的给用户完美的体验
分片存储
分库分表简单的实现目前大部分框架已经都可以实现了,就是动态表名来实现分表下的简单存储,如果是分库下面的那么就使用动态数据源来切换实现,如果是分库加分表就用动态数据源加动态表名来实现,听上去是不是很完美,但是实际情况下你需要表写非常繁多的业务代码,并且会让整个开发精力全部集中在分库分表下,针对后期的维护也是非常麻烦的一件事。
但是分库分表的分片规则又是和具体业务耦合的所以合理的解耦分片路由是一件非常重要的事情。
插入
假设我们按订单id进行分表存储
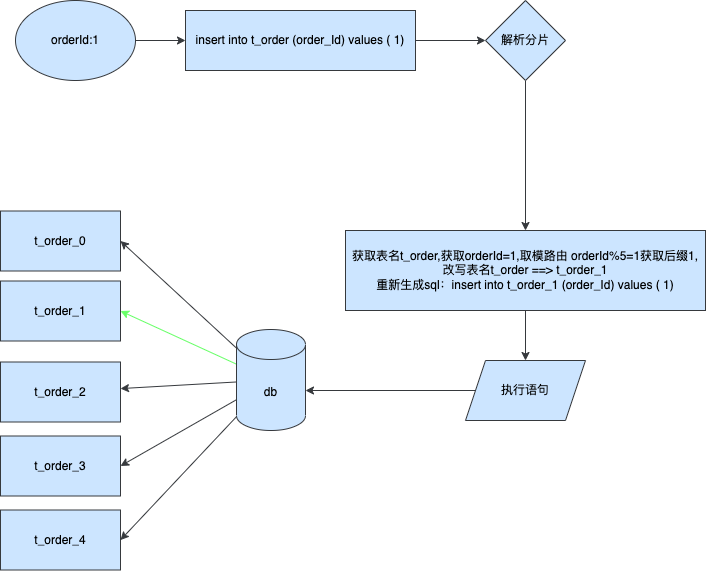
通过上述图片我们可以很清晰的了解到分片插入的执行原理,通过拦截执行SQL分析对应的值计算出所属表名,然后改写表名进行插入。该实现方法有一个弊端就是如果插入数据是increment的自增类型,那么这种方法将不适合,因为自增主键只有在插入数据库后才会正真的被确定是什么值,可以通过拦截器设置自定义自增拨号器来实现伪自增,这样也可以实现“自增”列。
更新删除)
这边假设我们也是按照订单id进行分表更新
更新分片键
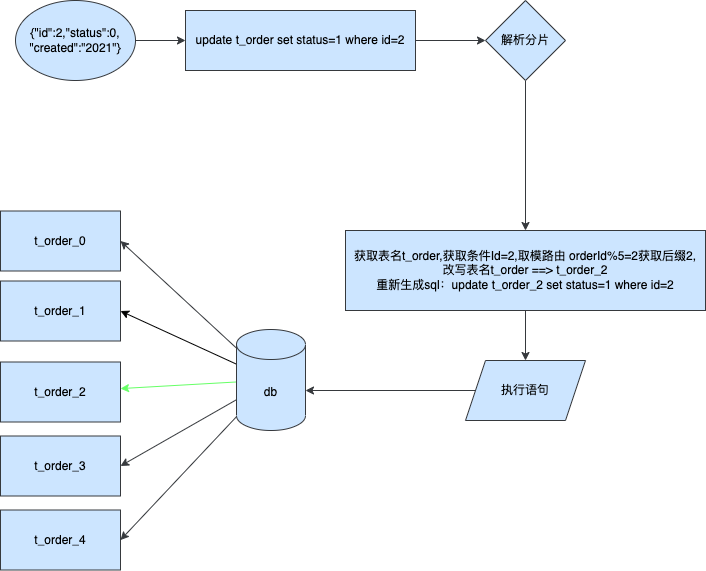
一模一样的处理,将SQL进行拦截后解析where和分片字段id然后计算后将结果发送到对应路由的表中进行执行。
那么如果我们没办法进行路由确定呢,如果我们使用created字段来更新的那么会发生生呢
更新非分片键
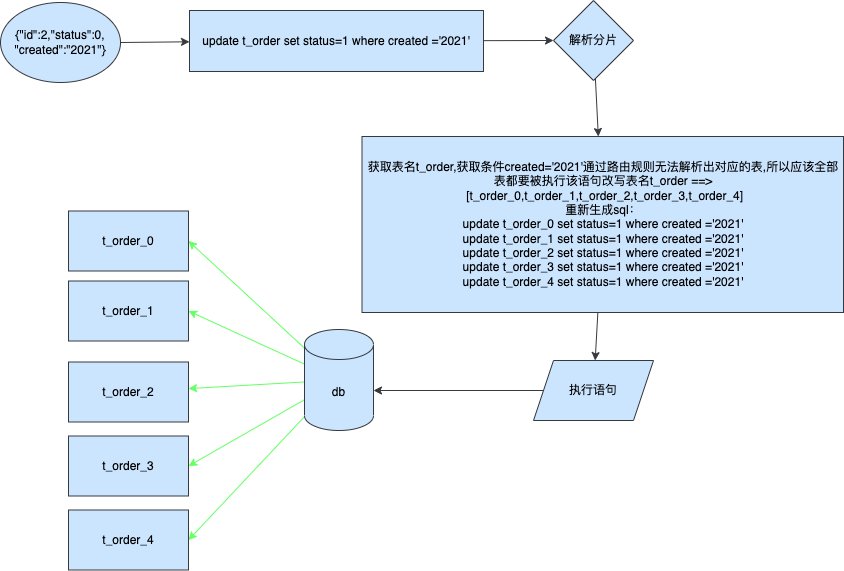
为了得到正确的结果需要将每条SQL进行改写分别发送到对应的表中,然后将各自表的执行结果进行聚合返回最终受影响行数
分片查询
众所周知分库分表的难点并不在如何存储数据到对应的db,也不在于如何更新指定实体数据,因为他们都可以通过分片键的计算来重新路由,可以让分片的操作降为单表操作,所以orm只需要支持动态表名那么以上所有功能都是支持的,
但是实际情况缺是如果orm或者中间件只支持到了这个级别那么对于稍微复杂一点的业务你必须要编写大量的业务代码来实现业务需要的查询,并且会浪费大量的重复工作和精力
单分片表查询
加下来我来讲解单分片表查询,其实原理和上面的insert一样
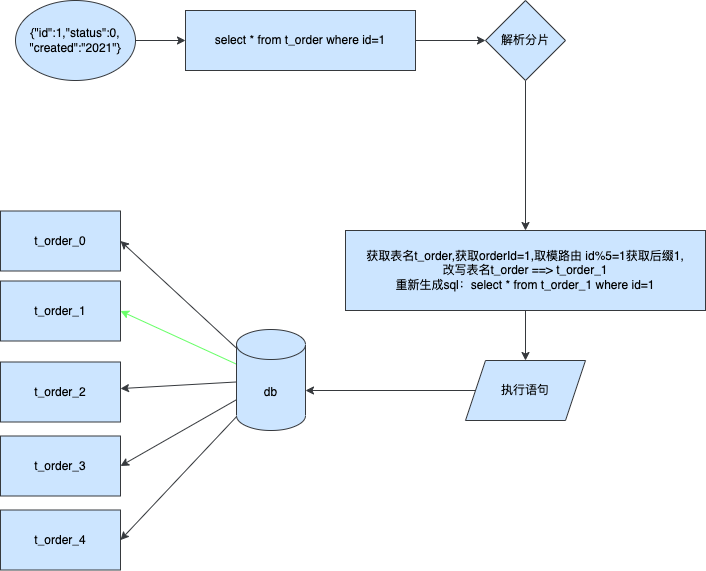
到这里为止其实都是ok的并没有什么问题.但是如果我们的本次查询需要跨分片呢比如跨两个分片那么应该如何处理
跨分片表查询
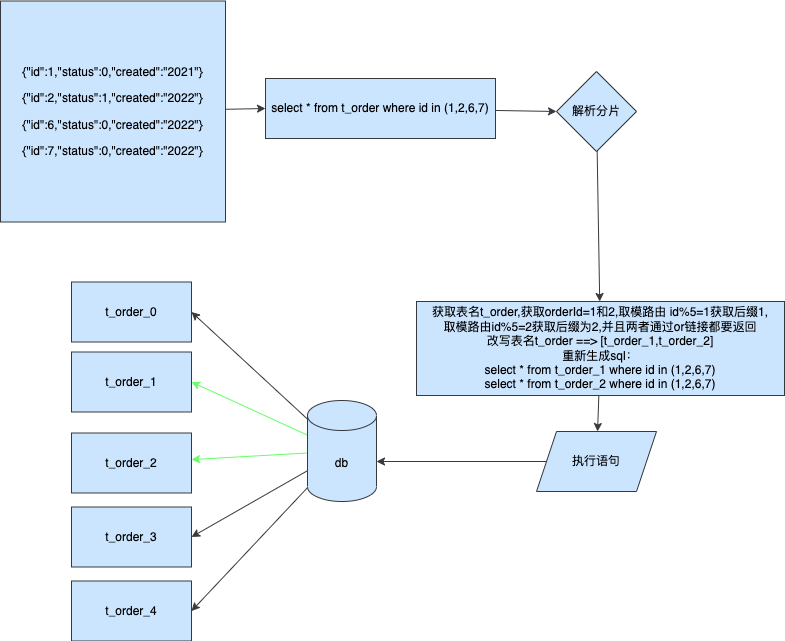
到这一步我们已经将对应的数据路由到对应的数据库了,那么我们应该如何获取自己想要的结果呢
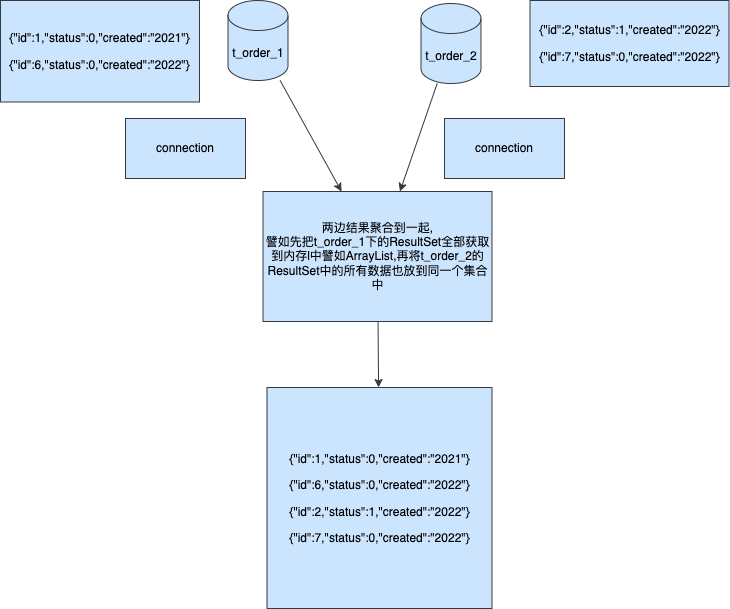
通过上图我们可以了解到在跨分片的聚合下我们可以分表通过对a,b两张表进行查询可以并行可以串行,最终将结果汇聚到同一个集合那么返回给用户端就是一个完整的数据包,并没有缺少任何数据
跨分片排序
基于上述分片聚合方式我们清晰的了解到如何可以进行跨分片下降数据获取到内存中,但是通过图中结果可以清晰的了解到返回的数据并不像我们预期的那样有序,那是因为各个节点下的所有数据都是仅遵循各自节点的数据库排序而不受其他节点分片影响。
那么如果我们对数据进行分片聚合+排序那么又会是什么样的场景呢
方案一内存排序
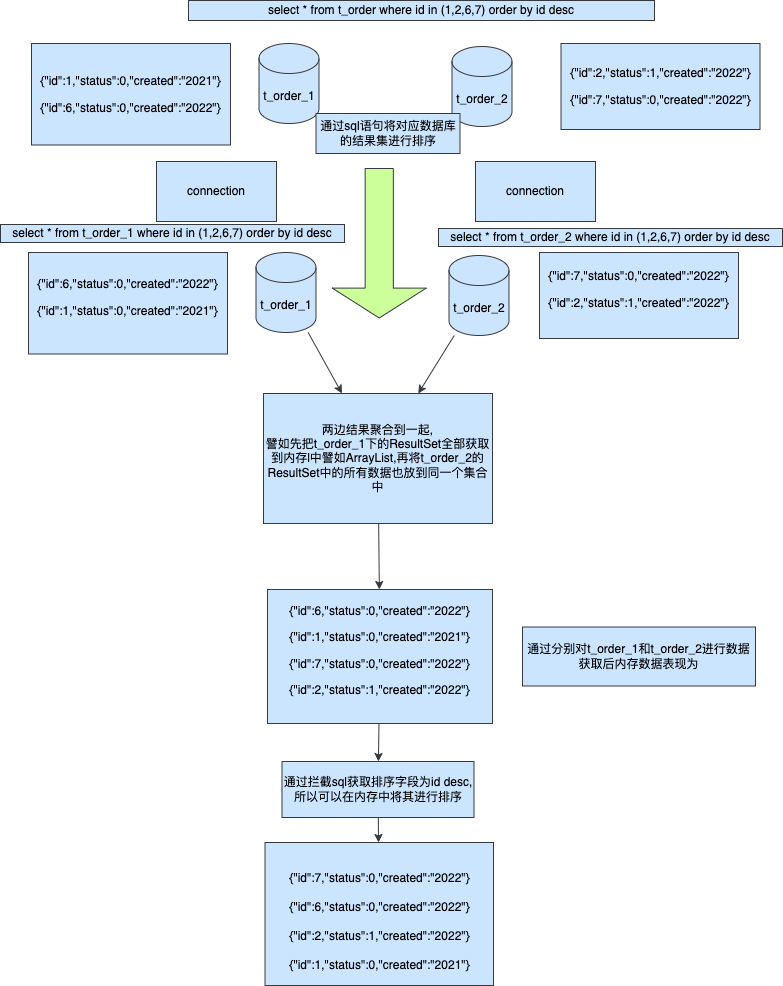
首先我们将执行sql分别路由到t_order_1和t_order_2两张表,并且执行order by id desc将其数据id大的排在前面这样可以保证单个Connection的ResultSet肯定是大的先被返回
所以在单个Connection下结果是正确的但是因为多个分片节点间没有交互所以当取到内存中后数据依然是乱的,所以这边需要对sql进行拦截获取排序字段并且将其在内存中的集合里面实现,这样我们就做到了和排序字段一样的返回结果
方案二流式排序
大部分orm到这边就为止了,毕竟已经实现了完美的节点处理,但是我们来看他需要消耗的性能事多少,假设我们分片命中2个节点,每个节点各自返回2条数据,我们对于整个ResultSet的遍历将是每个链接都是2那么就是4次,然后在内存中在进行排序如果性能差一点还需要多次所以这个是相对比较浪费性能的,因为如果我们有1000条数据返回那么内存中的排序是很高效的但是这个也是我们这次需要讲解的更加高效的排序处理流式排序
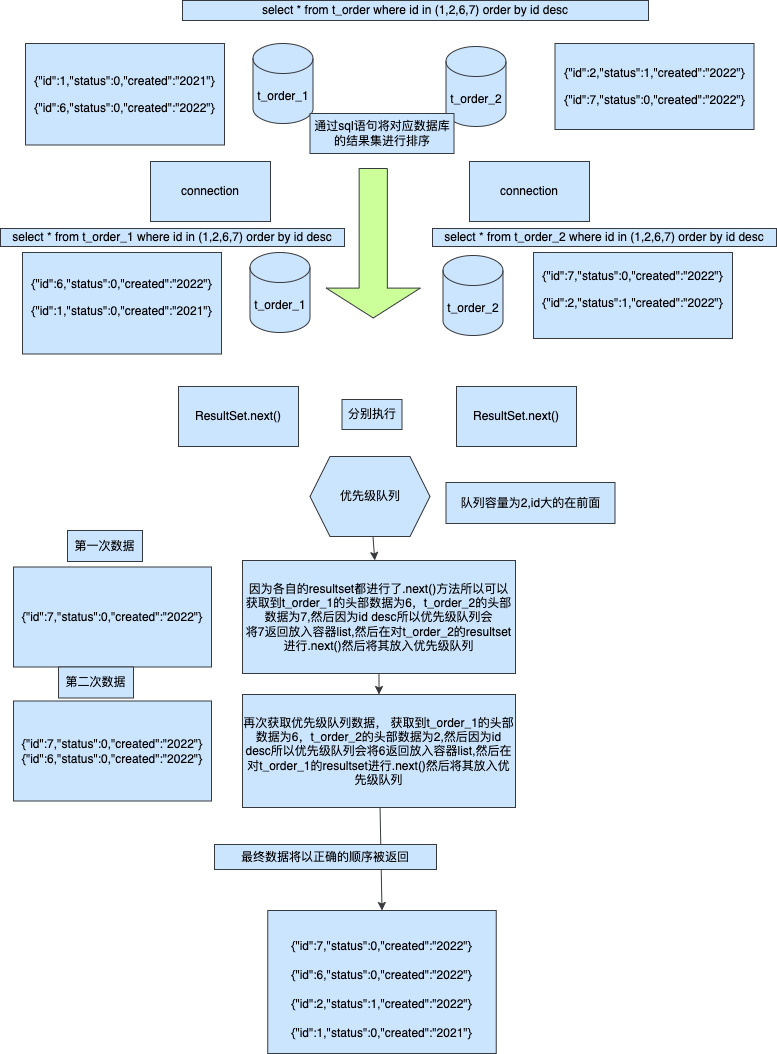
相较于内存排序这种方式十分复杂并且繁琐,而且对于用户也很不好理解,但是如果你获取的数据是分页,那么内存排序进行获取结果将会变得非常危险,有可能导致内存数据过大从而导致程序崩溃
无order字段
到这边不要以为跨分片聚合已经结束了因为当你的sql查询order by了一个select不存在的字段,那么上述两种排序方式都将无法使用,因为程序获取到的结果集并没有排序字段,这个时候一般我们会改写sql让其select的时候必须要带上对应的order by字段这样就可以保证我们数据的正确返回
以下两个问题因为涉及到过多内容本章节无法呈现所以将会在下一章给出具体解决方案
跨分片分组
如果我们程序遇到了这个那么我们该如何处理呢
跨分片分页
业务中常常需要的跨分片分页我们该如何解决,easy-query又如何处理这种情况,如果跨的分片过多我们又该怎么办,
- 如何解决深分页问题
- 如何解决流式瀑布问题
- 如何进行分页缓存高效获取问题
接下来将在下篇文章中一一解答近
最后
我这边将演示easy-query在本次分片理论中的实际应用
这次采用h2数据库作为演示
CREATE TABLE IF NOT EXISTS `t_order_0`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_1`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_2`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_3`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_4`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
安装maven依赖
<dependency>
<groupId>com.easy-query</groupId>
<artifactId>sql-h2</artifactId>
<version>0.9.32</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.easy-query</groupId>
<artifactId>sql-api4j</artifactId>
<version>0.9.32</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.199</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
创建实体对象对应数据库
@Data
@Table(value = "t_order",shardingInitializer = H2OrderShardingInitializer.class)
public class H2Order {
@Column(primaryKey = true)
@ShardingTableKey
private Integer id;
private Integer status;
private String created;
}
// 分片初始化器
public class H2OrderShardingInitializer extends AbstractShardingTableModInitializer<H2Order> {
@Override
protected int mod() {
return 5;//模5
}
@Override
protected int tailLength() {
return 1;//表后缀长度1位
}
}
//分片路由规则
public class H2OrderRule extends AbstractModTableRule<H2Order> {
@Override
protected int mod() {
return 5;
}
@Override
protected int tailLength() {
return 1;
}
}
创建datasource和easyquery
orderShardingDataSource=DataSourceFactory.getDataSource("dsorder","h2-dsorder.sql");
EasyQueryClient easyQueryClientOrder = EasyQueryBootstrapper.defaultBuilderConfiguration()
.setDefaultDataSource(orderShardingDataSource)
.optionConfigure(op -> {
op.setMaxShardingQueryLimit(10);
op.setDefaultDataSourceName("ds2020");
op.setDefaultDataSourceMergePoolSize(20);
})
.build();
EasyQuery easyQueryOrder = new DefaultEasyQuery(easyQueryClientOrder);
QueryRuntimeContext runtimeContext = easyQueryOrder.getRuntimeContext();
QueryConfiguration queryConfiguration = runtimeContext.getQueryConfiguration();
queryConfiguration.applyShardingInitializer(new H2OrderShardingInitializer());//添加分片初始化器
TableRouteManager tableRouteManager = runtimeContext.getTableRouteManager();
tableRouteManager.addRouteRule(new H2OrderRule());//添加分片路由规则
插入代码
ArrayList<H2Order> h2Orders = new ArrayList<>();
for (int i = 0; i < 100; i++) {
H2Order h2Order = new H2Order();
h2Order.setId(i);
h2Order.setStatus(i%3);
h2Order.setCreated(String.valueOf(i));
h2Orders.add(h2Order);
}
easyQueryOrder.insertable(h2Orders).executeRows();
==> main, name:ds2020, Preparing: INSERT INTO t_order_3 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 0(Integer),0(Integer),0(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_4 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 1(Integer),1(Integer),1(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_0 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 2(Integer),2(Integer),2(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_1 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 3(Integer),0(Integer),3(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_2 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 4(Integer),1(Integer),4(String)
.....省略
List<H2Order> list = easyQueryOrder.queryable(H2Order.class)
.where(o -> o.in(H2Order::getId, Arrays.asList(1, 2, 6, 7)))
.toList();
Assert.assertEquals(4,list.size());
==> SHARDING_EXECUTOR_2, name:ds2020, Preparing: SELECT id,status,created FROM t_order_3 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_4, name:ds2020, Preparing: SELECT id,status,created FROM t_order_0 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_3, name:ds2020, Preparing: SELECT id,status,created FROM t_order_4 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_1, name:ds2020, Preparing: SELECT id,status,created FROM t_order_2 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_4, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_5, name:ds2020, Preparing: SELECT id,status,created FROM t_order_1 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_3, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_5, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_1, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
<== SHARDING_EXECUTOR_2, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_5, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_1, name:ds2020, Time Elapsed: 1(ms)
<== SHARDING_EXECUTOR_4, name:ds2020, Time Elapsed: 1(ms)
<== SHARDING_EXECUTOR_3, name:ds2020, Time Elapsed: 1(ms)
<== Total: 4
``
通过上述sql展示我们可以清晰的看到哪个线程执行了哪个数据源(分片下会不一样),执行了什么sql,最终执行消耗多少时间参数是多少,一共返回多少条数据
分片排序
```java
List<H2Order> list = easyQueryOrder.queryable(H2Order.class)
.where(o -> o.in(H2Order::getId, Arrays.asList(1, 2, 6, 7)))
.orderByDesc(o->o.column(H2Order::getId))
.toList();
Assert.assertEquals(4,list.size());
Assert.assertEquals(7,(int)list.get(0).getId());
Assert.assertEquals(6,(int)list.get(1).getId());
Assert.assertEquals(2,(int)list.get(2).getId());
Assert.assertEquals(1,(int)list.get(3).getId());
==> SHARDING_EXECUTOR_1, name:ds2020, Preparing: SELECT id,status,created FROM t_order_1 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_5, name:ds2020, Preparing: SELECT id,status,created FROM t_order_3 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_4, name:ds2020, Preparing: SELECT id,status,created FROM t_order_2 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_3, name:ds2020, Preparing: SELECT id,status,created FROM t_order_4 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_5, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_1, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_4, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Preparing: SELECT id,status,created FROM t_order_0 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_3, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
<== SHARDING_EXECUTOR_1, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_5, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_4, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_2, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_3, name:ds2020, Time Elapsed: 0(ms)
<== Total: 4
最后的最后
附上源码地址,源码中有文档和对应的qq群,如果决定有用请点击star谢谢大家了

