
来源: 表格识别与内容提炼技术理解及研发趋势 – 合合技术团队 – 博客园
引言:
表格是各类文档中常见的对象,其结构化的组织形式方便人们进行信息理解和提取。表格的种类根据有无边框可以划分有线表、少线表、无线表。表格样式复杂多样,如存在背景填充、光照阴影、单元格行列合并等情况。大数据时代存在大量电子文档,应用表格识别技术能够减少表格处理时间,因此表格识别是文档理解领域的重要研究课题,也是合合信息这几年的技术突破点方向之一。
表格识别主要包括表格检测和表格结构识别两个子任务。
表格检测主要检测表格主体,即样本中表格区域。表格结构识别是对表格区域进行分析,提取表格中的数据与结构信息,得到行列分布与逻辑结构。未经特殊说明,以下表格识别专指表格结构识别。
研究现状与解决方案:
近年来,国内外专家学者对表格识别进行了大量研究,取得了丰富的研究成果。下面主要从传统图像处理方法和深度学习这两个方面做具体阐述。
传统方法
传统的表格识别工作是基于一些启发式的规则和图像处理方法,主要利用表格线或者文本块之间的空白分隔区域来确定单元格区域,通过腐蚀、膨胀,找连通区域,检测线段、直线,求交点,合并猜测框等。有自顶向下的方法(先检测表格区域,再不断对表格区域进行切割拆分得到单元格区域);还有自底向上的方法(先检测文本块,找到可能的表格线以及这些线的交点,确定单元格后还原出表格区域)
1、 OpenCV-检测并提取表格[1]
这是一种自顶向下的方法,先对图像进行二值化,然后使用霍夫变换,检测其中的直线,并在直线中,找到围成的一个矩形区域,最后将这块区域提取出来。
作者主要使用了四步操作:
1、处理图像,灰度化,二值化。在灰度图的基础上运用adaptiveThreshold来达成自动阈值的二值化,取代Canny,这个算法在提取直线和文字比Canny有更好的效果
2、利用OpenCV里面的形态学函数,腐蚀erode膨胀dilate
3、交叉横纵线条,对点进行定位,通过bitwise_and函数获得横纵线条的交点,通过交点对表格区域进行提取
4、判断区域是否为表格。
虽然此方法可以相对完整的识别图片中的表格,但也存在几个问题:
1、图片倾斜不易识别
2、图片背景复杂会干扰识别
3、少线表情况,表格只有上下两条线的时候如何判断
2、pdfplumber解析表格[2]
pdfplumber是一款完全用python开发的pdf解析库,对于全线表,pdfminer能够实现较好的抽取效果,但对于少线表和无线表,效果就差了很多。
下面介绍pdfplumber中的表格抽取流程,这是一种自底向上的方法,首先找到可见的或猜测出不可见的候选表格线;然后根据候选表格线确定它们的交点;接着根据得到的交点,找到围成它们的最小单元格;最后把连通的单元格进行整合,生成检测出的表格对象。在表格生成的过程中,利用单元格的bbox坐标(四个角的坐标)判断单元格是否属于当前表格;同时对表格的左上角坐标进行排序,过滤掉小表格。
3、camelot表格抽取[3]
camelot是一个可以从可编辑的pdf文档中抽取表格的开源框架,与pdfplumber相比,其功能完备性差了点,除了表格抽取之外,并不能用它从pdf文档中解析出字符、单词、文本、线等较为低层次的对象。
camelot支持两种表格抽取模式:
一、lattice线框类表格抽取,步骤如下:
1、pdf转图像
2、图像处理算法检测出水平方向和竖直方向可能用于构成表格的直线
3、根据检测出的直线,生成可能表格的bounding box
4、确定表格各行、列的区域
5、根据各行、列的区域,水平、竖直方向的表格线以及页面文本内容,解析出表格结构,填充单元格内容,最终形成表格对象。
二、stream少线框类表格抽取,步骤如下:
1、通过pdfminer获取连续字符串
2、通过文本对齐的方式确定可能表格的bounding box
3、确定表格各行、列的区域
4、根据各行、列的区域以及页面上的文本字符串,解析表格结构,填充单元格内容,最终形成表格对象。
4、T-recs[4]
这是一种自底向上的方法,核心思想是对文本块区域进行聚类。
步骤如下:
1、从文本块中选择种子点
2、在种子点上下各一行分别去找与该种子点文本块之间是否水平方向有重合,如果有重合则将相应文本块和种子点块归到一起,并作为新的种子点
3、重复第1、2步,不断找与之水平方向有重合的文本块,直到所有的文本块都不能再合并下去。
此方法也存在诸多局限:
1、表头是跨单元格的,表头下面的文本块会被全部合并到一起
2、有时候上下几行文本确确实实是对齐的,但是和左右文本区域比较近,这种本不能分开的区域被错误的分开了
3、孤立的文本块会被切分成单独块。
因此,本方法后面大部分工作是针对这三种局限设定后处理规则,该方法认为表格之所以是表格是由文本块的分布决定的,而与分割带无关。加入后处理规则之后该方法方法具有较好的通用性,无论是对与PDF文档还是OCR的结果,都有比较好的效果。
深度学习方法
近年来人工智能技术飞速发展,研究人员将CV,NLP和图神经等成熟方法应用在表格识别任务中,取得很多不错的成果。深度学习表格识别主流方法包括语义分割,目标检测,序列预测和图神经等,下面我们对这些工作分别进行介绍。
1. 语义分割方法:
1.1 Rethinking Semantic Segmentation for Table Structure Recognition in Documents[5]
本文将表格结构的识别定义为语义分割问题,使用FCN网络框架,对表格的行和列分别进行预测。主要介绍了一种对预测结果进行切片的方法,降低了表格识别的复杂度。使用了FCN的Encoder和Decoder的结构,并加载了在ImageNet预训练好的模型。图片经过模型生成了与原图大小相同的特征,切片过程将特征按照行和列进行平均,将H*W*C(高*宽*Channel)的特征合并成了H*C和W*C大小特征;对这些特征进行卷积后,再进行复制,扩展为H*W*C的大小,再通过卷积层得到每个像素点的标签;最后进行后处理得到最终的结果。本文pipeline如图1所示。本文方法的局限在于本文所处理的表格对象中所有的单元格不存在跨行跨列,每行每列都从表格的最左侧和最上端开始,到最右侧和最下端结束。
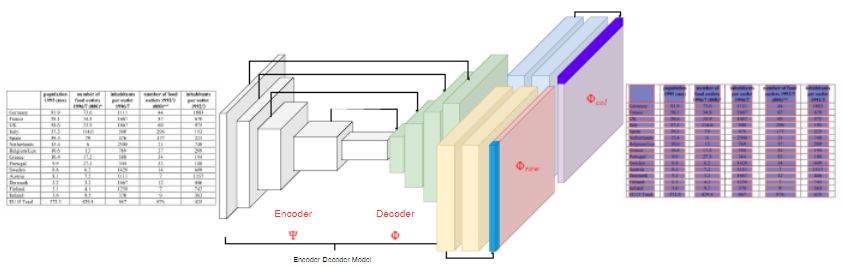
图1
1.2 腾讯表格识别技术方案[6]
图像分割是对图像的每个像素点赋予标签,在表格识别任务中,每个像素可能属于横线、竖线、不可见横线、不可见竖线这几个标签。
解决方案流程如图2所示:
1、表格线标注:横向的线,竖向的线,横向的不可见线,竖向的不可见线。类别不互斥,考虑到单元格交点问题,即交点处的像素属于多个类别
2、几何分析提取连通区域,对连通区域拟合折线,合并形成框线;考虑图片弯曲、表格倾斜的情况,利用投影变换对原图矫正
3、调用ocr,识别文本内容,确定字符坐标
4、根据第二步的框线计算行列信息,判断单元格合并情况,得到每个单元格在途中的位置
5、根据单元格坐标和字符坐标,将字符嵌入到单元格,还原表格。
此方案专注于将页面拍照后进行表格识别,对于一般的表格效果还好,但现实场景太过纷杂,仍有很多问题亟待解决。

图2
2. 物体检测方法:
2.1 海康LGPMA方案[7]
此方案是ICDAR21比赛Table Recognition赛道的冠军,LGPMA将表格识别分为文本行检测、文字识别和表格结构识别三部分。文本检测模块是一个单行文本检测器,文字识别模块是一个基于attention 的识别器,这两部分用来获取表格图像中的文本信息。表格结构识别部分采用的是一种LGPMA的方案,基于Mask-RCNN同时出两个分割头,一个LPMA学习局部对齐边界,一个GPMA学习全局对齐边界,融合了自顶向下和自底向上两种思想。
如图3所示。在得到两路的soft mask之后,将LPMA和GPMA的对齐mask融合,之后对每个单元格边框进行精修。最后经过cell matching , empty cell searching 和 empty cell merging三个后处理步骤得到最终的表格结构。原方案采用较大的基础网络,训练推理对硬件及输出尺寸有一定约束,实际落地较为困难。
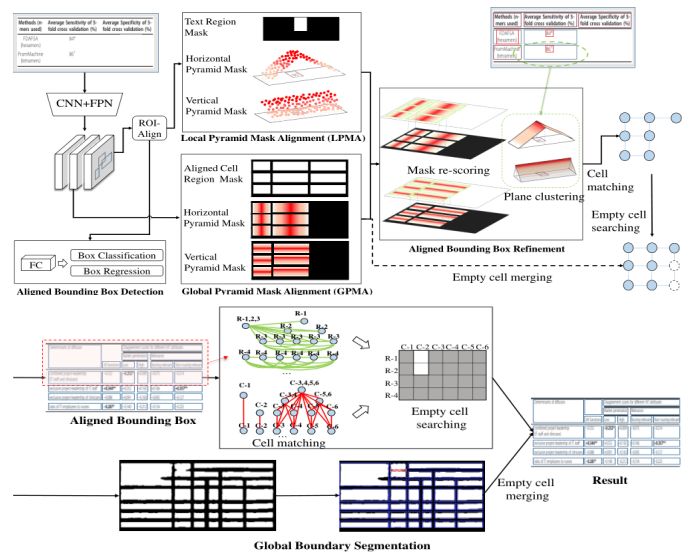
图3
2.2 角点表格检测法[8]
针对表格检测本文使用了“角点”来提升表格检测的精确度,对比基本模型在检测结果上能够得到进一步的检测与提升。
首先引入角点的概念,如图4所示:角点是表格四个顶点周围的一部份区域,这些区域大小相同,同一个表格的所有角点构成一个角点组,角点的检测与表格检测一样,可以使用目标检测模型来解决,作者使用Faster R-CNN模型,同时进行角点和表格的检测,检测结构如图5所示,使用角点组对对应的表格检测的横坐标进行校准,得到最终的表格区域。该方法与未加入角点的Faster R-CNN模型相比,结果有了较大的提升。
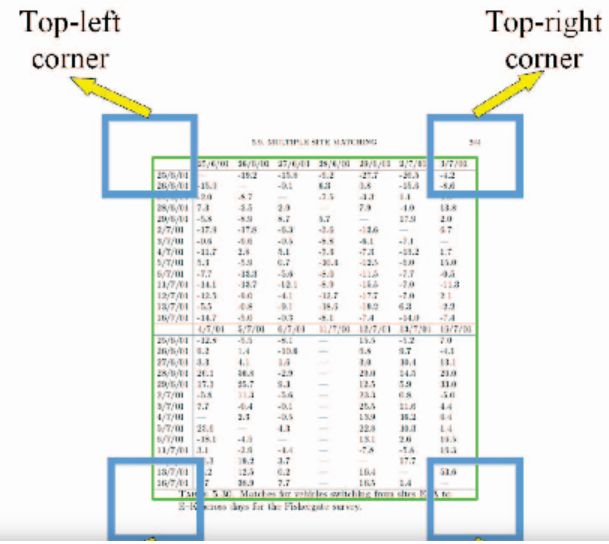
图4
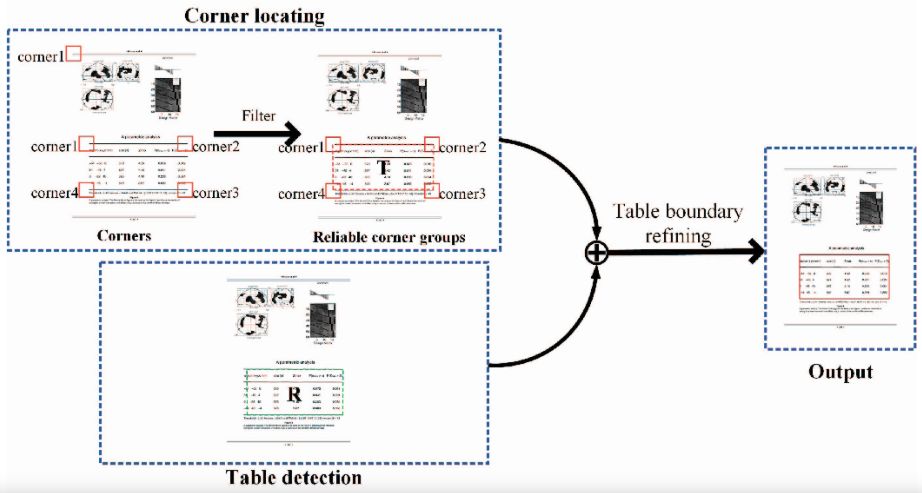
图5
基于CenterNet的端到端表格识别方案[9]
目标检测识别往往是在图像上将目标用矩形框的形式框出,目标检测器都先穷举出潜在目标位置,然后对该位置进行分类,这种做法浪费时间,低效,还需要做额外的后处理。
CenterNet是将目标作为一个点(BBOX中心点),利用中心点回归其他目标属性,比如尺寸、位置、方向等。本文提出了一种基于CenterNet的表格识别方法,网络结构如图6所示,利用Cycle_Pairing模块和Pairing损失去学习相邻单元格的公共顶点信息,然后通过连结单元格获取一个完整的表格结构,最后使用相同的解析过程去获取行列信息。这篇文章解决户外场景图像的表格解析问题(TSP:table structure parsing),局限在于此方法仅适用于有线表格,无线表角点定义的歧义性使得本文方法不一定work。从本文的思路我们或许可以探索角点法在处理复杂场景的情况下是否比anchor-based的方法表现更优。
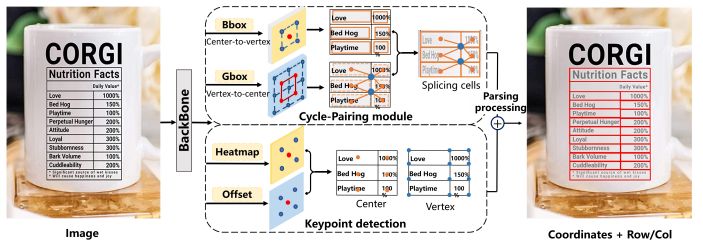
图6
3. 序列预测方法:
3.1 Latex标签序列预测[10]
基于图像的表格分析优势在于,它对表格类型具有鲁棒性,并不要求格式是页面扫描图像还是纯数字文档,它可用于多数文档类型,包括PDF、HTML、PowerPoint格式等。然而,非结构化数字文档中的表格数据,由于其结构和样式的复杂性及多样性,很难解析为结构化的机器可读格式。
在实践中,手工标注用于训练的数据集的成本和不灵活性是实际部署深度学习模型的关键瓶颈。本文是微软的一篇文章,利用互联网中存在大量的Word和Latex源文档,对这些在线文档应用一些弱监督来标注表格,创建TableBank数据集。对于word文档,可以修改内部的office xml代码,指定每个表格的边界线;对于latex文档,可以修改tex代码,代码已识别表格的边界框。表格检测使用基于不同配置的Faster R-CNN的架构,表格结构识别模型基于image-to-text的编码器-解码器架构。
本文的局限在于版式多样对表格分析任务的准确率具有负面影响,模型泛化能力差,某一领域的模型应用到其他领域效果不好,在TableBank数据集上的建模和学习具有很大改进空间。
3.2 HTML标签序列预测[11]
类似地,IBM公司开发并发布了数据集PubTabNet,此数据集中自动为每个表图像加上关于表的结构和每个单元格内的文本信息(HTML格式),如图7(a)所示。
作者等人提出了一种端到端的表格识别方案,是一种基于注意力的编码器-解码器(EDD)架构,它是由编码器、结构解码器和单元格解码器组成,可以将表格图像转化成HTML代码。编码器获得表格图像的视觉特征,两个独立的结构解码器⼀个输出表格结构,⼀个输出单元格内容。
图7(b)所示为EDD架构,不需要复杂的后处理即可得到表格结果。但end2end的方案在中文场景的落地还有很长的路要走,另外缺少表格物理结构的信息,EDD方法的纠错空间不多。同时,本文的另一个贡献是提出了一种新的基于树编辑距离的图像表格识别评价指标TEDS,将表格建模为树形结构,该指标比之前的基于precision、reacll、F1 score的评价指标更为规范。
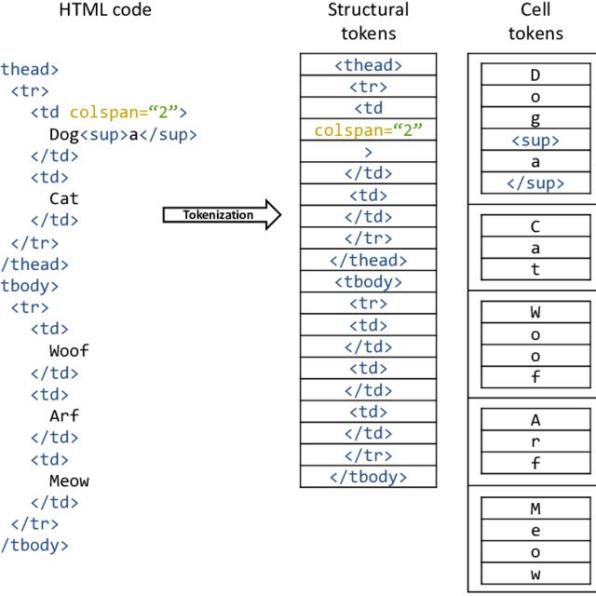
图7(a)
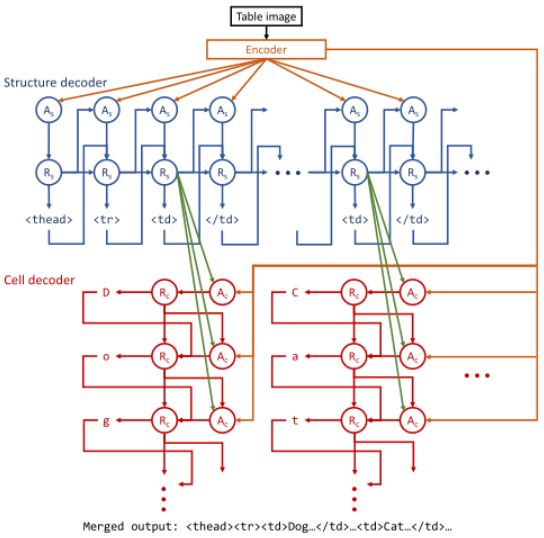
图7(b)
3.3 TableMaster解决方案[12]
平安产险提出的TableMaster方案是ICDAR21比赛Table Recognition赛道的亚军,本方案基于文本识别算法Master[13]。TableMASTER算法采用多任务学习的模式,同时进行表格结构序列预测以及单元格位置回归,最后通过后处理匹配算法,融合表格结构序列和单元格文本内容,得到HTML代码。整个解决方案可以分为4个部分:表格结构序列识别,表格文本行检测,表格文本行识别,以及单元格与表格结构序列匹配。
表格结构序列识别部分,使用改进的文本识别算法MASTER,它与原生的MASTER在结构上的区别如图8所示。他们的特征提取器在结构上是大体一致的,采用的都是改进后的ResNet网络,TableMaster在解码阶段,经过一个TransformerLayer后,会分为两条分支。一条分支进行表格结构序列的监督学习,另一条分支进行表格中单元位置回归的监督学习。
表格文本行检测部分,采用的是经典的文本检测算法PSENet[14],表格文本行识别部分,采用的文本识别算法MASTER。
在单元格与表格结构序列匹配部分,作者团队定义了三种匹配规则,分别是Center Point Rule,IOU Rule,以及Distance Rule。这三种匹配规则的优先级顺序为Center Point Rule>IOU Rule>Distance Rule。
序列预测的表格识别结果受限于序列长度和类别数量,同时transformer结构推理速度有优化空间。
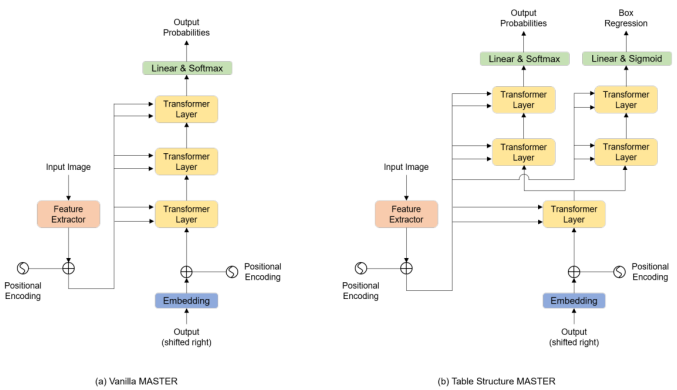
图8
4. 图卷积神经网络方法:
4.1 Rethinking Table Recognition using Graph Neural Networks[15]
近年来,越来越多的学者将深度学习技术应用到图数据领域,本文作者将表格结构识别问题描述为一个与图神经网络兼容的图问题,利用图神经网络解决这一问题。将每一个文本区域作为一个顶点,使用矩阵描述的三个图(单元格、行共享矩阵、列共享矩阵)定义为真值,若顶点共享一行,则对应的文本区域属于同一行,这些顶点视作彼此相邻。
模型分为四个流程:特征提取、信息交互、随机采样和分类,过程如图9所示。利用CNN提取视觉特征,输出端将ocr得到的顶点位置映射到特征图上,将视觉特征与位置特征结合形成聚集特征。得到所有的顶点特征后进行特征交互融合,得到每个顶点的结构特征。在分类部分使用DenseNet分别对定点对进行是否同行、同列、同单元格的结构关系分类。
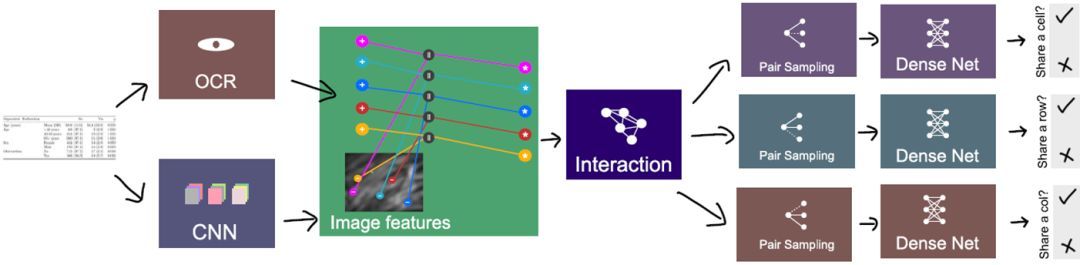
图9
4.2 GFTE: Graph-based Financial Table Extraction[16]
本文[16]主要是为了主要解决金融类的、中文表格识别问题,提出一种新的基于图卷积神经网络的模型GFTE作为表格识别数据集(本文自己发布的中文数据集FinTab)中的基线方法。GFTE通过融合图像特征、位置特征和文本特征,能够对表格进行精确的边缘检测,取得较好的效果。
GFTE可以分为以下几个步骤:
1、构建基本事实,包括表格区域的图像、文本内容、文本位置和结构标签
2、基于单元格构造一个无向图G=<V, R, C>
3、使用GFTE来预测相邻关系,包括垂直和水平关系。
作者将表格中的每个单元格视作节点,每个节点包含三种类型的信息:文本内容、绝对位置和图像,节点与它的邻域理解成边,那么表格结构完全可以用一个图来表示,图结构如图10所示。
图11是GFTE的基本结构,首先将绝对位置转换成相对位置,然后使用这些位置生成图。然后将纯文本嵌入预先定义好的特征空间,使用LSTM获取语义特征。接着将位置特征与文本特征进行拼接,将他们传入两层的图卷积网络(GCN)。最后,利用节点的相对位置,计算网格,利用网格中国输入的像素位置计算输出,得到某一节点在某一点的图像特征。获得这三种不同的特征后,将生成图的一条边上的两个节点配对,并与三种不同的特征集合在一起,使用MLP预测这两个节点处于同行还是同列。
图神经网络通过合理建模,将表格中的不同特征进行融合,并取得了不错的效果,这种表格结构识别方法,为未来的工作提供了一些可能的发展道路。
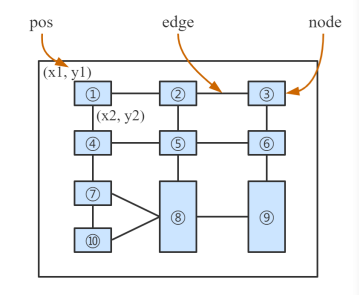
图10
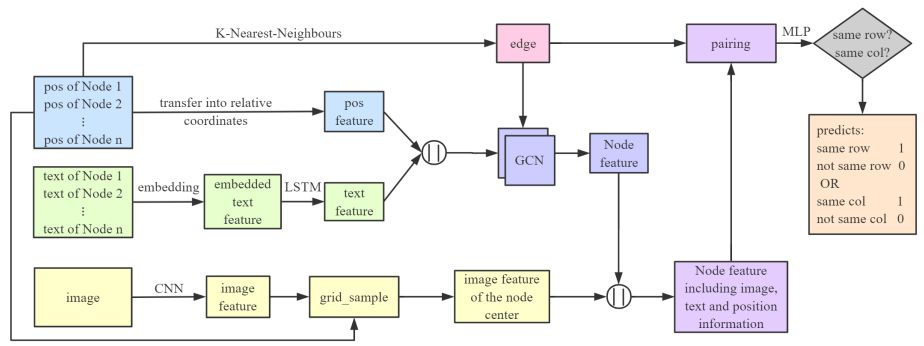
图11
————
结语:
目前,表格识别任务逐渐受到工业界和学术界的关注。表格识别对象从PDF文档,到文档图片,再到自然场景图片,复杂场景表格识越来越被重视。随着人工智能应用的成熟,表格识别方法已从传统图像算法转向到深度学习算法。目标检测、语义分割、序列预测、图神经网络等是目前表格识别的主要技术方向,它们各有优劣。作为文档理解的重要一环,一套在复杂场景中鲁棒性很强的表格识别方案仍有待探索。
对于表格识别及相关内容提炼,合合信息认为传统的表格识别方法设计起来较为复杂,对于版面布局分析和表格结构的提取,图像处理的方法依赖各种阈值和参数的选择,难以满足现实生活中复杂多样的表格场景,鲁棒性也相对较差。目前业界常用的表格识别方法多为深度学习算法,比较依赖算法工程师对于神经网络的精心设计,可以不用依赖阈值和参数,鲁棒性较强。
从公司角度来讲,算法落地的关键因素大致可分为计算力、数据、算法模型、业务场景等。计算力是人工智能技术的生产力,数据的价值在于给予解决某一场景问题足够的特征,算法模型是项目落地的承载体,业务场景是落地的关键。在技术落地中,应当一切以业务场景为核心,以最少的数据,最简单的模型,最少的计算力解决最实际的问题,达到最好的效果。对于表格识别这一技术来讲,一款推理速度快且在少样本情况下表现优异的表格识别算法会备受青睐。
参考文献:
[1] OpenCV-检测并提取表格:https://blog.csdn.net/yomo127/article/details/52045146
[2] pdfplumber解析表格:pdfplumber是怎么做表格抽取的(三) – 知乎
[3] camelot表格抽取:camelot是怎么做表格抽取的(三)—— 非线框类表格抽取 – 知乎
[4] T-recs:T. Kieninger and A. Dengel, “The T-Recs table recognition and analysis system,” in Document Analysis Systems: Theory and Practice, pp. 255–270, 1999.
[5] Siddiqui S A , Khan P I , Dengel A , et al. Rethinking Semantic Segmentation for Table Structure Recognition in Documents[C]// 2019 International Conference on Document Analysis and Recognition (ICDAR). 2019.
[6] 走进AI时代的文档识别技术之表格图像识别 – 云+社区 – 腾讯云 (tencent.com)
[7] LGPMA: Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment (arxiv.org)
[8] Sun N , Zhu Y , Hu X . Faster R-CNN Based Table Detection Combining Corner Locating[C]// 2019 International Conference on Document Analysis and Recognition (ICDAR). 2019.
[9] Long R , Wang W , Xue N , et al. Parsing Table Structures in the Wild. 2021.
[10] Zhong X , Shafieibavani E , Yepes A J . Image-based table recognition: data, model, and evaluation[J]. 2019.
[11] Li M , Cui L , Huang S , et al. TableBank: Table Benchmark for Image-based Table Detection and Recognition[J]. 2019.
[12] Ye J , Qi X , He Y , et al. PingAn-VCGroup’s Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. 2021.
[13] Lu N , Yu W , Qi X , et al. MASTER: Multi-Aspect Non-local Network for Scene Text Recognition[J]. 2019.
[14]Li X , Wang W , Hou W , et al. Shape Robust Text Detection with Progressive Scale Expansion Network[J]. 2018.
[15] Qasim S R , Mahmood H , F Shafait. Rethinking Table Recognition using Graph Neural Networks. 2019.
[16] Li Y , Huang Z , Yan J , et al. GFTE: Graph-based Financial Table Extraction[J]. 2020.

