
来源: 手语识别_使用深度学习进行手语识别_weixin_26752765的博客-CSDN博客
手语识别
TL;DR It is presented a dual-cam first-vision translation system using convolutional neural networks. A prototype was developed to recognize 24 gestures. The vision system is composed of a head-mounted camera and a chest-mounted camera and the machine learning model is composed of two convolutional neural networks, one for each camera.
TL; DR 提出了一种使用卷积神经网络的双摄像头第一视觉翻译系统。 开发了一个原型来识别24个手势。 视觉系统由头戴式摄像头和胸部安装式摄像头组成,机器学习模型由两个卷积神经网络组成,每个卷积神经网络一个。
介绍 (Introduction)
Sign language recognition is a problem that has been addressed in research for years. However, we are still far from finding a complete solution available in our society.
手语识别是多年来研究中已经解决的问题。 但是,我们离我们的社会还没有找到一个完整的解决方案。
Among the works developed to address this problem, the majority of them have been based on basically two approaches: contact-based systems, such as sensor gloves; or vision-based systems, using only cameras. The latter is way cheaper and the boom of deep learning makes it more appealing.
在为解决这个问题而开发的作品中,大部分都基于两种方法:基于接触的系统,例如传感器手套; 或基于视觉的系统,仅使用摄像头。 后者更便宜,而深度学习的兴起使其更具吸引力。
This post presents a prototype of a dual-cam first-person vision translation system for sign language using convolutional neural networks. The post is divided into three main parts: the system design, the dataset, and the deep learning model training and evaluation.
这篇文章介绍了使用卷积神经网络的双摄像头第一人称视觉翻译系统的原型。 该职位分为三个主要部分:系统设计,数据集以及深度学习模型的训练和评估。
视觉系统 (VISION SYSTEM)
Vision is a key factor in sign language, and every sign language is intended to be understood by one person located in front of the other, from this perspective, a gesture can be completely observable. Viewing a gesture from another perspective makes it difficult or almost impossible to be understood since every finger position and movement will not be observable.
视觉是手语中的一个关键因素,每种手语都应由位于另一人面前的一个人理解,从这个角度来看,手势可以完全观察到。 由于无法观察到每个手指的位置和移动,因此从另一个角度查看手势很难或几乎无法理解。
Trying to understand sign language from a first-vision perspective has the same limitations, some gestures will end up looking the same way. But, this ambiguity can be solved by locating more cameras in different positions. In this way, what a camera can’t see, can be perfectly observable by another camera.
试图从第一视觉的角度理解手语具有相同的局限性,某些手势最终将以相同的方式出现。 但是,可以通过在不同位置放置更多摄像机来解决这种歧义。 这样,一台摄像机看不到的东西可以被另一台摄像机完全观察到。
The vision system is composed of two cameras: a head-mounted camera and a chest-mounted camera. With these two cameras we obtain two different views of a sign, a top-view, and a bottom-view, that works together to identify signs.
视觉系统由两个摄像头组成:头戴式摄像头和胸部安装式摄像头。 使用这两个摄像头,我们可以获得标牌的两种不同视图,即顶视图和底视图,它们可以一起识别标牌。

Another benefit of this design is that the user will gain autonomy. Something that is not achieved in classical approaches, in which the user is not the person with disability but a third person that needs to take out a system with a camera and focus a signer while the signer is performing a sign.
这种设计的另一个好处是用户将获得自主权。 传统方法无法实现的某些功能,在该方法中,用户不是残疾人,而是需要在签名人执行签名时需要带照相机的系统并对准签名人的第三方。
数据集 (DATASET)
To develop the first prototype of this system is was used a dataset of 24 static signs from the Panamanian Manual Alphabet.
为了开发该系统的第一个原型,使用了来自巴拿马手册字母的24个静态符号的数据集。
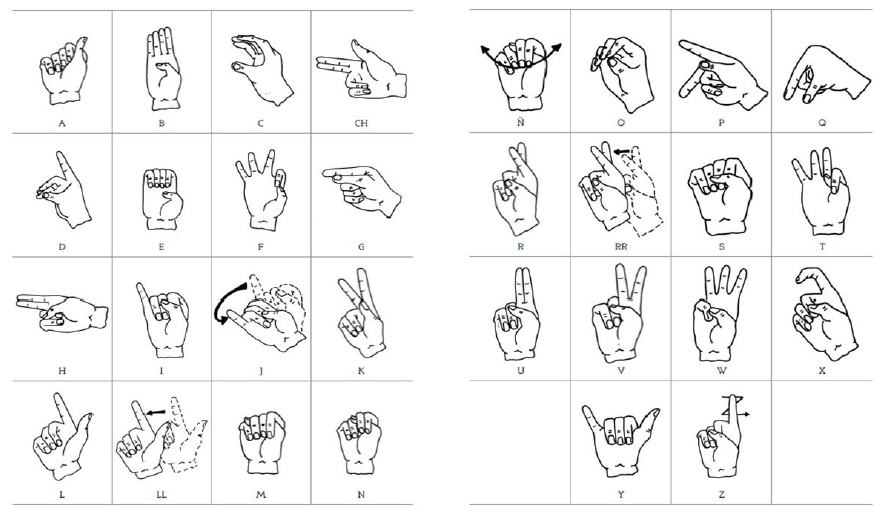
To model this problem as an image recognition problem, dynamic gestures such as letter J, Z, RR, and Ñ were discarded because of the extra complexity they add to the solution.
为了将此问题建模为图像识别问题,由于字母J,Z,RR和Ñ之类的动态手势会增加解决方案的复杂性,因此将其丢弃。
数据收集和预处理 (Data collection and preprocessing)
To collect the dataset it was asked to four users to wear the vision system and perform every gesture for 10 seconds while both cameras were recording in a 640×480 pixel resolution.
为了收集数据集,要求两个用户佩戴视觉系统并在每个相机都以640×480像素分辨率记录的同时执行每个手势10秒钟。
It was requested to the users to perform this process in three different scenarios: indoors, outdoors, and in a green background scenario. For the indoors and outdoors scenarios the users were requested to move around while performing the gestures in order to obtain images with different backgrounds, light sources, and positions. The green background scenario was intended for a data augmentation process, we’ll describe later.
要求用户在三种不同的情况下执行此过程:室内,室外和绿色背景。 对于室内和室外场景,要求用户在执行手势时四处走动,以获取具有不同背景,光源和位置的图像。 绿色背景方案是用于数据增强过程的,我们将在后面介绍。
After obtaining the videos, the frames were extracted and reduced to a 125×125 pixel resolution.
获得视频后,将帧提取并降低到125×125像素分辨率。

资料扩充 (Data augmentation)
Since the preprocessing before going to the convolutional neural networks was simplified to just rescaling, the background will always get passed to the model. In this case, the model needs to be able to recognize a sign despite the different backgrounds it can have.
由于将卷积神经网络之前的预处理简化为仅缩放,因此背景将始终传递给模型。 在这种情况下,尽管模型可能具有不同的背景,但它仍需要能够识别符号。
To improve the generalization capability of the model it was artificially added more images with different backgrounds replacing the green backgrounds. This way it is obtained more data without investing too much time.
为了提高模型的泛化能力,它人为地添加了更多具有不同背景的图像来代替绿色背景。 这样,无需花费太多时间即可获取更多数据。

During the training, it was also added another data augmentation process consisting of performing some transformations, such as some rotations, changes in light intensity, and rescaling.
在训练期间,它还添加了另一个数据增强过程,该过程包括执行一些转换(例如某些旋转,光强度的更改和缩放)。
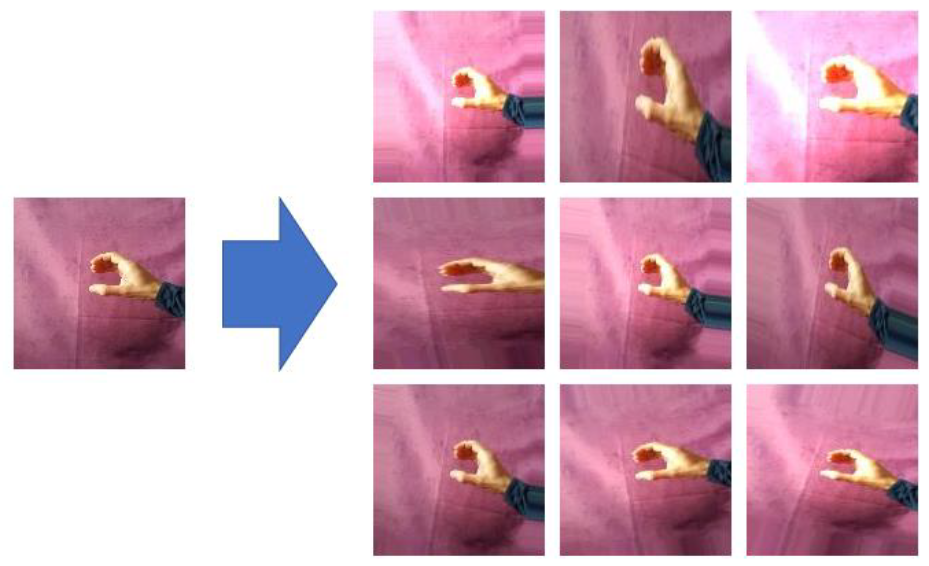
These two data augmentation process were chosen to help improve the generalization capability of the model.
选择这两个数据增强过程可帮助提高模型的泛化能力。
顶视图和底视图数据集 (Top view and bottom view datasets)
This problem was model as a multiclass classification problem with 24 classes, and the problem itself was divided into two smaller multi-class classification problems.
该问题被建模为具有24个类的多类分类问题,并且该问题本身被分为两个较小的多类分类问题。
The approach to decide which gestures would be classified whit the top view model and which ones with the bottom view model was to select all the gestures that were too similar from the bottom view perspective as gestures to be classified from the top view model and the rest of gestures were going to be classified by the bottom view model. So basically, the top view model was used to solved ambiguities.
决定将哪些手势归类为顶视图模型以及哪些手势与底视图模型相结合的方法是选择从底视图角度来看太相似的所有手势作为要从顶视图模型中归类的手势,其余选择为手势将由仰视图模型分类。 因此,基本上,顶视图模型用于解决歧义。
As a result, the dataset was divided into two parts, one for each model as shown in the following table.
结果,数据集分为两部分,每个模型一个,如下表所示。

深度学习模型 (DEEP LEARNING MODEL)
As state-of-the-art technology, convolutional neural networks was the option chosen for facing this problem. It was trained two models: one model for the top view and one for the bottom view.
作为最先进的技术,卷积神经网络是解决这一问题的选择。 它训练了两种模型:一种用于顶视图的模型,一种用于底视图的模型。
建筑 (Architecture)
The same convolutional neural network architecture was used for both, the top view and the bottom view models, the only difference is the number of output units.
顶视图模型和底视图模型都使用了相同的卷积神经网络体系结构,唯一的区别是输出单元的数量。
The architecture of the convolutional neural networks is shown in the following figure.
下图显示了卷积神经网络的体系结构。
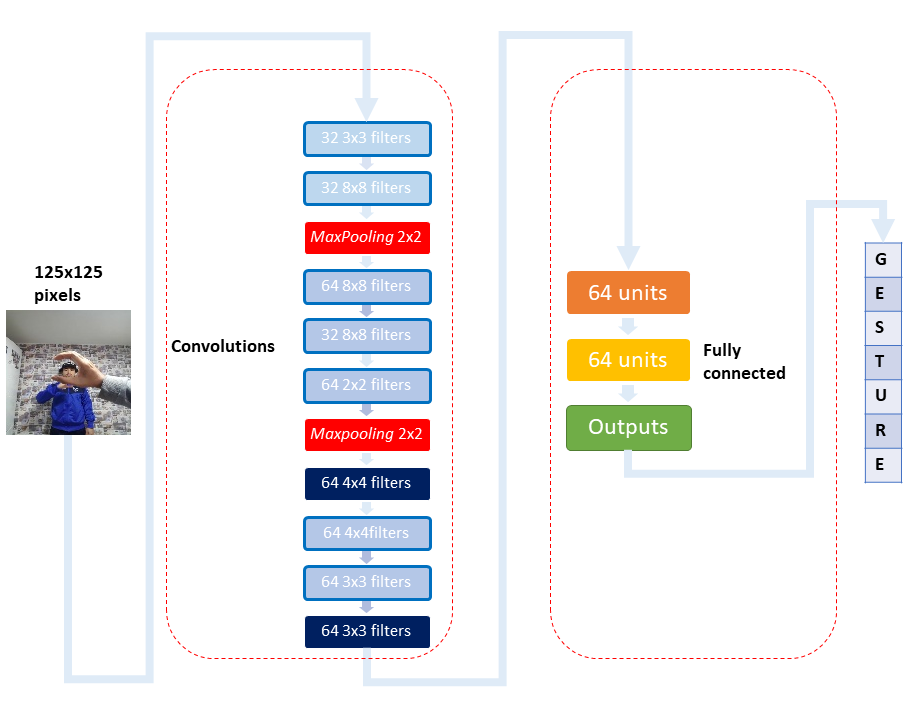
To improve the generalization capability of the models it was used dropout techniques between layers in the fully connected layer to improve model performance.
为了提高模型的泛化能力,在完全连接的层中的层之间使用了丢弃技术来提高模型性能。
评价 (Evaluation)
The models were evaluated in a test set with data corresponding to a normal use of the system in indoors, in other words, in the background it appears a person acting as the observer, similar to the input image in the figure above (Convolutional neural networks architecture). The results are shown below.
在测试集中对模型进行了评估,并使用了与室内正常使用系统相对应的数据,换句话说,在背景中看起来像是人在充当观察者,类似于上图中的输入图像( 卷积神经网络)建筑 )。 结果如下所示。
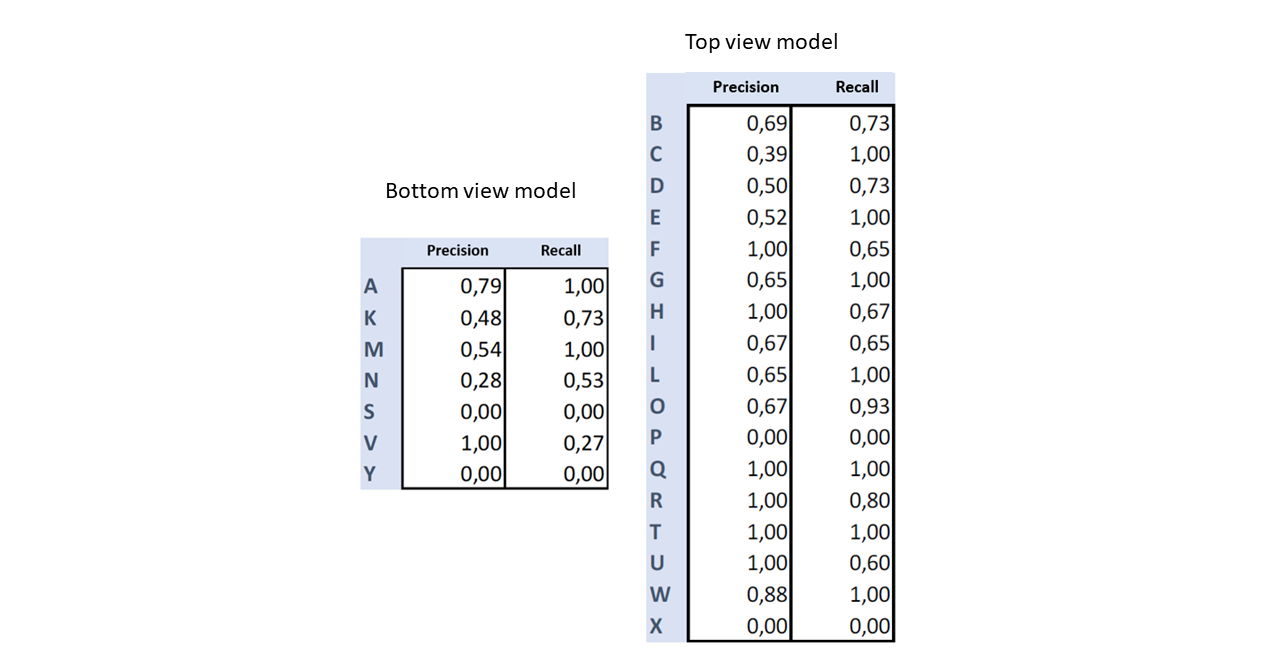
Although the model learned to classify some signs, such as Q, R, H; in general, the results are kind of discouraging. It seems that the generalization capability of the models wasn’t too good. However, the model was also tested with real-time data showing the potential of the system.
尽管模型学会了对一些符号进行分类,例如Q,R,H; 一般来说,结果令人沮丧。 这些模型的泛化能力似乎不太好。 但是,该模型还通过显示系统潜力的实时数据进行了测试。
The bottom view model was tested with real-time video with a green uniform background. I wore the chest-mounted camera capturing video at 5 frames per second while I was running the bottom view model in my laptop and try to fingerspell the word fútbol (my favorite sport in Spanish). The entries for every letter were emulated by a click. The results are shown in the following video.
底视图模型已通过具有绿色统一背景的实时视频进行了测试。 当我在笔记本电脑中运行底视图模型时,我戴着胸部摄像头以每秒5帧的速度捕获视频,并尝试拼写fútbol(我最喜欢的西班牙语运动)一词。 通过单击可以模拟每个字母的条目。 结果显示在以下视频中。
Note: Due to the model performance, I had to repeat it several times until I ended up with a good demo video.
注意:由于模型的性能,我不得不重复几次,直到获得了不错的演示视频。
结论 (Conclusions)
Sign language recognition is a hard problem if we consider all the possible combinations of gestures that a system of this kind needs to understand and translate. That being said, probably the best way to solve this problem is to divide it into simpler problems, and the system presented here would correspond to a possible solution to one of them.
如果我们考虑这类系统需要理解和翻译的手势的所有可能组合,则手语识别将是一个难题。 话虽这么说,解决这个问题的最好方法可能是将其分为更简单的问题,此处介绍的系统将对应于其中一个的可能解决方案。
The system didn’t perform too well but it was demonstrated that it can be built a first-person sign language translation system using only cameras and convolutional neural networks.
该系统的性能不是很好,但是证明了可以仅使用相机和卷积神经网络构建第一人称手语翻译系统。
It was observed that the model tends to confuse several signs with each other, such as U and W. But thinking a bit about it, maybe it doesn’t need to have a perfect performance since using an orthography corrector or a word predictor would increase the translation accuracy.
据观察,该模型倾向于使多个符号相互混淆,例如U和W。但是,仔细考虑一下,也许它不需要具有完美的性能,因为使用正交拼写校正器或单词预测器会增加翻译准确性。
The next step is to analyze the solution and study ways to improve the system. Some improvements could be carrying by collecting more quality data, trying more convolutional neural network architectures, or redesigning the vision system.
下一步是分析解决方案,并研究改进系统的方法。 通过收集更多质量的数据,尝试更多的卷积神经网络体系结构或重新设计视觉系统,可以带来一些改进。
结束语 (End words)
I developed this project as part of my thesis work in university and I was motivated by the feeling of working in something new. Although the results weren’t too great, I think it can be a good starting point to make a better and biggest system.
作为大学论文工作的一部分,我开发了这个项目,并且受到在新事物中工作的感觉的激励。 尽管效果不是很好,但我认为这可能是构建更好,最大的系统的良好起点。
If you are interested in this work, here is the link to my thesis (it is written in Spanish)
如果您对此工作感兴趣,请点击此处链接至我的论文 (用西班牙语撰写)
Thanks for reading!
谢谢阅读!
翻译自: https://towardsdatascience.com/sign-language-recognition-using-deep-learning-6549268c60bd

