
来源: Google机器学习笔记 4-5-6 分类器 – 梦里风林 – 博客园
转载请注明作者:梦里风林
Google Machine Learning Recipes 4
官方中文博客 – 视频地址
Github工程地址 https://github.com/ahangchen/GoogleML
欢迎Star,也欢迎到Issue区讨论
Recipes 4 Let’s Write a Pipeline
复习与强化概念
- 监督学习基础套路
- 例子: 一个用于举报邮件的分类器
关键在于举报新的邮件
- Train vs Test:隔离训练集,测试集以验证训练效果
- f(x) = y
feature: x, label: y, classifier其实就是一个feature到label的函数
- 可以从sklearn中import各种分类器进行训练,各种分类器有类似的接口
这些不同分类器都可以解决类似的问题
- 让算法从数据中学习到底是什么
- 拒绝手工写分类规则代码
- 本质上,是学习feature到label,从输入到输出的函数
- 从一个模型开始,用规则来定义函数
- 根据训练数据调整函数参数
- 从我们发现规律的方法中,找到model
- 比如一条划分两类点的线就是一个分类器的model,调整参数就能得到我们想要的分类器:
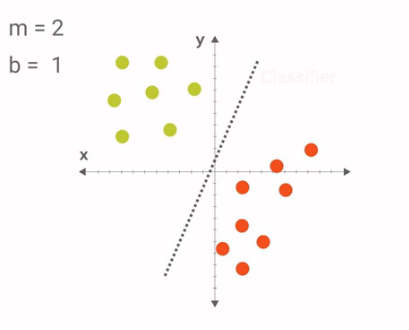
Example of Neural Network
Recipes 5 Writing Our First Classifier
- 从底层实现一个分类器
目标
实现一个K近邻(k-Nearest Neighbour)问题
K Nearest Neighbour
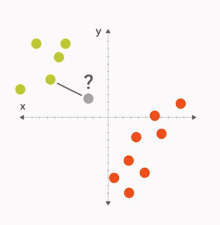
- 对于一个测试点,看它最近的邻居属于那个类别
- 考虑最近邻居的时候,我们可以综合考虑与这个点距离最近的K个点,看它们中有多少输入类别A,多少属于类别B
- 距离:两点间的直线距离(Euclidean Distance)

- 即考虑各个feature之间差异的平方和
实现
- 在Lesson4的基础上进行,我们在lesson4中使用了KNeighborsClassifier()作为分类器,现在我们要实现这个分类器
- ScrappyKNN:最简单的一个K近邻分类器
- 接口:
- fit:用于训练,将训练集的feature和label作为输入
- predict: prediction,将测试集的feature作为输入,输出预测的label
- Random Classifier
- 随机挑一个label作为预测输出,由于我们是在三种花的结果中随机挑取一种花作为结果,所以结果大概在33%
- KNN:
- 设置k=1,也就是我们只考虑最近的那个点属于那个类别
- 用scipy.spatial.distance来计算距离
- 返回测试点最近邻的label
结论
- 准确率:90%以上(这里也可能看出feature选得好的重要性)
- 优点:非常简单
- 缺点:耗时;不能表示复杂的东西;
Recipes 6 Train an Image Classifier with TensorFlow for Poets
目标
区分图片之间的差异
工具
TensorFlow for Poets
- 高度封装
- 效果奇佳
- 只需要目录中的图片和目录名字作为label,不需要预设feature
数据
- 找出图片中五种花的差异
- 下载地址:http://download.tensorflow.org/example_images/flower_photos.tgz
- 如果你想要用其他的图片类型,你只需要创建一个新的文件夹,放入对应类型的100张以上的图片
- 不需要像Iris数据集那样有预设的feature
分类器
- TensorFlow
- TensorFlow擅长于Deep learning
- 由于提取特征很困难,因为世界上的变数太多了,所以深度学习自动提取特征的功能变得很重要
- TFLearn:高阶的机器学习库
- Image Classifier
- 直接从像素级数据提取特征
- 神经网络
- 可以学习更复杂的函数
实现
- 由于官方视频教程中的语法格式使用的是nightly版本tensorflow的格式,因此对代码稍作修改
- 参考Github·TensorFlow·Issue
- 参考Github·TensorFlow·Skflow·Example
- TensorFlow处理Iris问题
- TensorFlow直接识别文件夹图片
- 耗时大概20分钟
- 基于Inception训练分类器retrain
- Transfer Learning:重用Inception的一些参数
后话
- 图像识别关键在于:Diversity and quantity
- Diversity:样本多样性越多,对新事物的预测能力越强
- Quantity:样本数量越多,分类器越强大

